

(弊社デザイナーが作ってくれた私の LGTM 画像です)
Developers Blog に初登場!クラウドファンディングプラットフォーム Makuake の吉田慶章 ( @kakakakakku ) です.Makuake には約1年前に JOIN しました.JOIN した直後はサーバサイド開発をメインに新機能の開発を担当していましたが,2016年3月頃からウェブオペレーションエンジニアも兼務し,インフラ構成やアーキテクチャの改善をしたり,DevOps 文化の推進をしています.
どんなサービスにも「技術的負債(もしくは何かしらの課題)」はあると思います.特に成長期のスタートアップでは,新機能をリリースすることを最優先に開発をする場面も多いですし,またサービスの急激な成長に伴って,今までは問題なく稼働していたアーキテクチャが,突如運用に耐えなくなってしまうこともあります.ある意味で「技術的負債」に向き合えることは,サービスの成長の証でもあり,嬉しい悲鳴とも言えるのではないでしょうか.
私はウェブオペレーションをメインで担当することになって以来,多くの改善を積み重ねてきました.既に本番環境で稼働している部分を修正することの難しさを感じた場面も多くあり,頭を悩ませました.
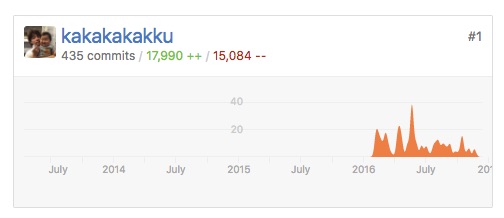
最初に取り組んだのは Chef クックブックのリファクタリングと Serverspec を使ったインフラテストの導入でした.実行するとエラーになるクックブックや冪等性が保証されていないクックブックを修正したり,Chef 化されずに直接サーバ上で変更されていた点を発見しては,クックブックに反映していました.参考までに Chef を管理しているリポジトリのコミット規模を載せておきます.Chef クックブックの大部分を書き直したと思います.
アジェンダ
今回は,特に注力して改善したポイント3点に絞って紹介します.
- Well-Architected を目指して改善をし続けた話
- モニタリングと効果計測をチームの文化として根付かせた話
- 社長を巻き込んで技術的負債の解消に価値を置いた話
Well-Architected を目指して改善をし続けた話
AWS を運用している人なら知っていると思いますが,AWS から公式に “AWS Well-Architected Framework” というホワイトペーパーが公開されています.このホワイトペーパーを読むことで「クラウドネイティブなアーキテクチャのベストプラクティス」を学ぶことができます.CDP (Cloud Design Pattern) よりも抽象的で,原則がまとまっているため,実際の AWS サービスの組み合わせに関しては CDP などの関連資料と合わせて読むことが推奨されています.
さらに「質問集&回答」が含まれている点が素晴らしく,サービスのアーキテクチャが「Well-Architected なのか?」を自問自答することができます.私はこの “AWS Well-Architected Framework” をバイブルとして繰り返し読み,技術的負債の解消に活用しました.
(補足)
“AWS Well-Architected Framework” は,2016年11月に最新版が公開され,一部の原則が更新されていますが,今回は2015年11月の初版をベースにしていますので,ご注意下さい.
4本の柱
“AWS Well-Architected Framework” には,「一般的な設計の原則」と「4本の柱」が定義されています.さらに柱ごとに「設計の原則」と「ベストプラクティス(質問集を含む)が定義されています.
- 一般的な設計の原則
- 必要キャパシティーの推測をやめる
- 本稼働スケールでシステムをテストする
- アーキテクチャ変更のリスクを低減する
- 自動化によってアーキテクチャ実験を簡単にする
- 発展するアーキテクチャの許可
- 4本の柱
- セキュリティ
- 信頼性
- パフォーマンス効率
- コスト最適化
- (運用上の優秀性:2016年11月に第5の柱が追加されました)
4本の柱と改善内容
今回は質問集の一部を引用し,実際にどのように改善したのかを紹介します.
セキュリティの柱
SEC 5. AWS リソースへの自動化されたアクセス (アプリケーション 、スクリプト、サードパーティーツールまたはサービスから のアクセスなど) をどのように制限していますか。
ホワイトペーパーにも非推奨と書かれている通り,認証情報をアプリケーションにハードコーディングすることは避けるべきですが,当時はそのようになっていた部分が多くありました.ベストプラクティスに沿って,IAM ロールを積極的に利用するようにインスタンスを作り直しました.
SEC 10. AWS ログをどのように取得して分析していますか。
当時は稼働している AWS サービスのログが出力されていなく,状況把握のための情報が圧倒的に不足している状況でした.よって,ELB Access Logs / VPC Flow Logs / S3 Access Logs / CloudFront Access Logs を出力できるようにしました.また API 操作に関しては CloudTrail でトラッキングしています.
分析面では,テキストのまま grep で検索することもありますし,場合によっては CloudWatch Logs / Elasticsearch + Kibana を使って可視化しています.最近では Amazon Athena のリリースがありましたので,ELB Access Logs のアドホックな調査などが実施しやすくなったと感じています.
信頼性の柱
REL 2. AWS でのネットワークトポロジをどのように計画していますか。
稼働中のインスタンスに影響しないように慎重に切り替えましたが,VPC 内のサブネットを再設計しました.と言うのも,当時稼働していたプライベートサブネットを調べたところ,NAT の設定が無く,完全に閉鎖されていたため,Chef によるプロビジョニングすらできない状態でした.また AZ の考慮もされていなく,全て同じアベイラビリティゾーンで稼働していたロールもありました.今では NAT Gateway を利用し,AZ にインスタンスを分散し,問題なく稼働しています.
REL 8. システムはコンポーネントの障害にどのように対応しますか。
コンポーネントの障害は起きることを前提に考える必要があります.よって,サービスに求められているのは「コンポーネントの障害をサービスの障害にしないこと」です.様々な障害があり,全てを冗長化することは難しいですが,ベストプラクティスとして挙がっている通り「ウェブサーバの前段にロードバランサを配置して負荷分散をする」という一般的な構成をすぐに適用しました.
当時,社内で使う管理系サービスが「コスト削減のために」1台構成になっていました.1台構成の問題は多くありますが,利用頻度を考慮すると適切な場面もあるとは思います.ただし,管理系サービスは運用上必須であるため,軽微なプロビジョニングを行う場合も,数週間前にアナウンスをしたり,平日夜間にメンテナンスを行うような調整が必要でした.正直言って,これは「コスト削減」ではなく「運用上の障害」だと感じました.重要なのは「運用しやすくコスト最適化(コスト削減ではなく)を実現すること」です.今回はロードバランサを配置して,アーキテクチャを変更することで,信頼性が上がり,運用もしやすくなりました.
さらに,言語やミドルウェアのバージョンアップも並行稼動させることができるようになり,その後の大規模リリースでさっそくメリットを感じることができました(参考).
パフォーマンス効率の柱
PERF 1. システムに対して適切なインスタンスタイプはどのように選択していますか。
EC2 には様々なインスタンスタイプがあります.一般的な用途であれば「M系」,コンピューティング重視なら「C系」,メモリ重視なら「R系」などです(他にも多くありますが).稼働するミドルウェアの特性を考慮した上でメトリクスを日々モニタリングし,過剰な選択にならないよう適切なインスタンスタイプに変更しました.ただしまだ課題は残っていて,一部のインスタンスが PV AMI で稼働しているために最新世代のインスタンスタイプに切り替えられていなかったりもします.まさに今,HVM AMI への切り替えを進めているところです.
PERF 5. システムに最適なストレージソリューションをどのように選択していますか。
インスタンスタイプに留まらず,EBS も積極的にリプレイスしました.多くのインスタンスで Standard (Magnetic) が選択されていて,メトリクスを見ると I/O ボトルネックになっている場合もありました.積極的に gb2 にリプレイスし,さらに IOPS も意識して最適化をしました.
ストレージソリューションの改善は EBS だけではありません.本来インスタンスに残しておく必要のないデータが EBS を逼迫している事象も発見したため,データのライフサイクルを見直すことによって,ハウスキーピングを導入したり,自動的に S3 にアップロードできるようにしました.結果として,必要な EBS のサイズも小さくなりました.
コストの最適化の柱
COST 1. キャパシティーが必要量を満たしているが大幅に超えていないことをどのように実現していますか。
PERF 1. で改善した内容と類似しますが,メトリクスを可視化し,積極的にモニタリングすることによって,リソースの負荷状況を判断できるようになりました.詳しくは次にまとめます.
モニタリングと効果計測をチームの文化として根付かせた話
「全てはモニタリングから始まるんだ!」が私の口癖です.”Well-Architected” を目指すときにも活用した通り,アプリケーション改善,インフラ改善など,何をやるにしても,メトリクスを収集し,モニタリングし,傾向を定量的に把握することは重要だと考えていて,システム全体の様々な部分を可視化しました.
- Zabbix + Grafana : ホストメトリクス
- Mackerel : ホストメトリクス
- Elasticsearch + Kibana : 各種エラーログ
- CloudWatch : ELB メトリクス
- New Relic APM : アプリケーションパフォーマンス
- SpeedCurve : フロントエンドパフォーマンス
- Google Analytics : コンバージョンメトリクス
Zabbix + Grafana
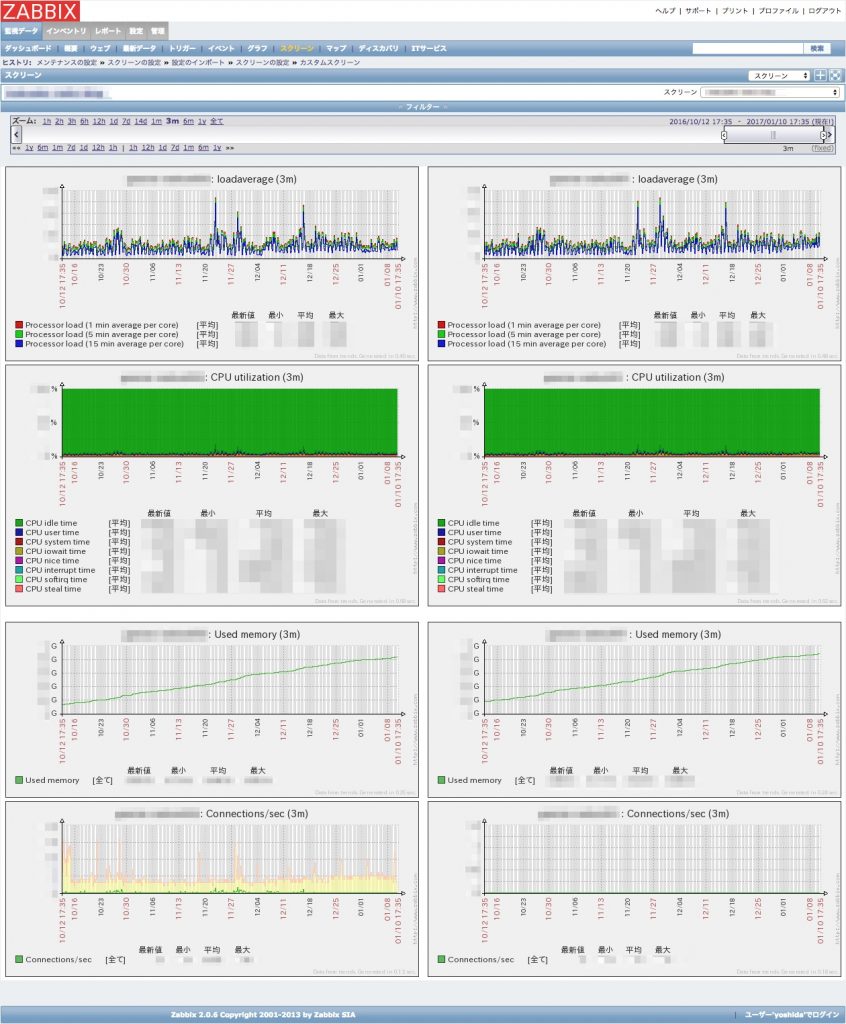
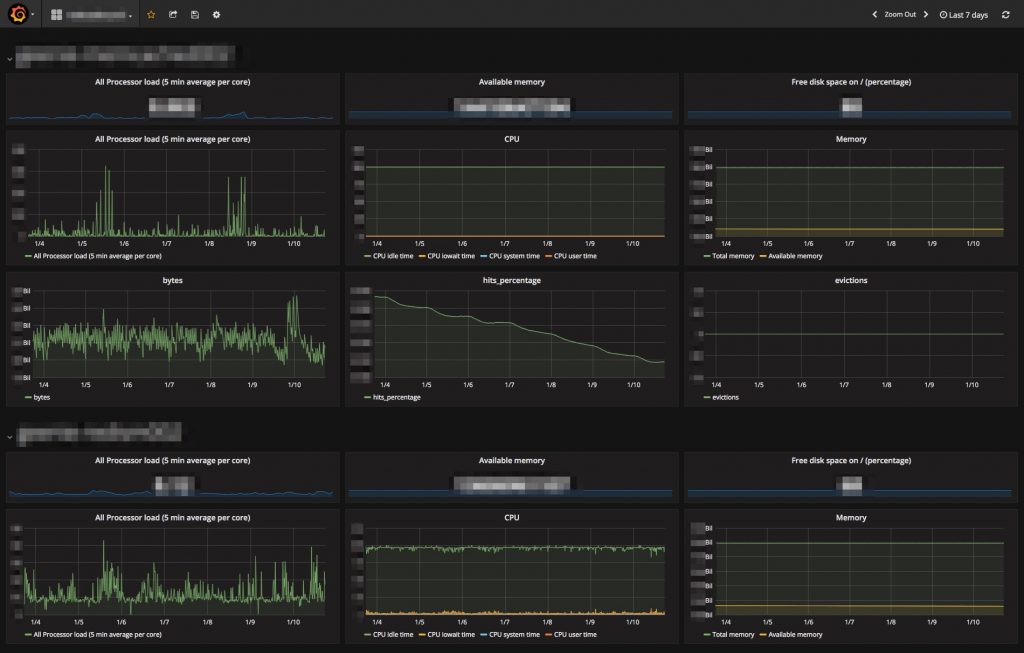
当時から使っていた Zabbix のスクリーンを整備し,全ロールを網羅したダッシュボードを作りました.最近はダッシュボードの部分を Grafana (grafana-zabbix) に移行しました.柔軟なグラフ設定ができますし,何よりも UI がイケてる点が気に入ってます.アラートの部分は引き続き Zabbix を使っています.
(サンプル:Zabbix スクリーン)
(サンプル:Grafana ダッシュボード)
Mackerel
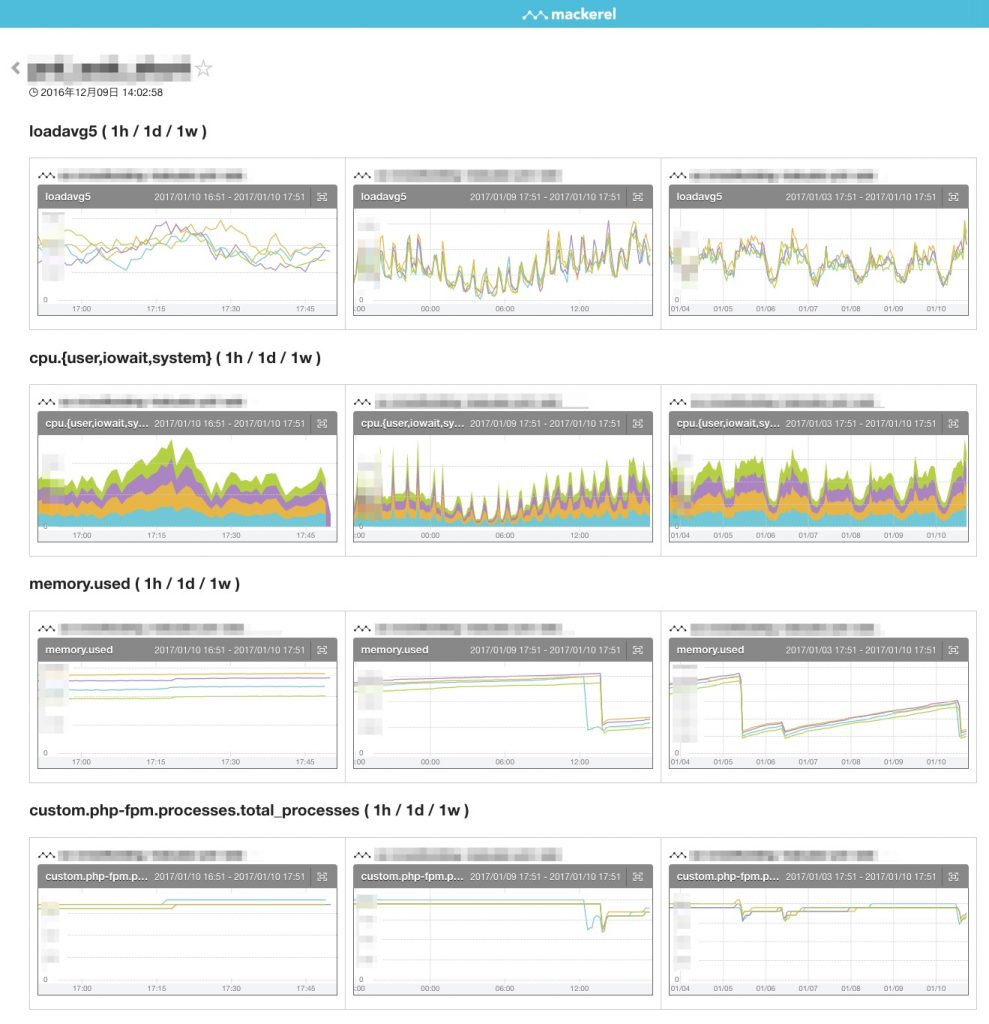
一部のロールは Zabbix から Mackerel にリプレイスをしています.mackerel-agent-plugins を使ってメトリクスを取得したり,go-check-plugins を使ってプロセス監視やログ監視をしています.ダッシュボードも活用しており,特に mkr dashboards CLI を使って .yml から自動生成している点を工夫しています.
(サンプル:Mackerel ダッシュボード)
New Relic APM
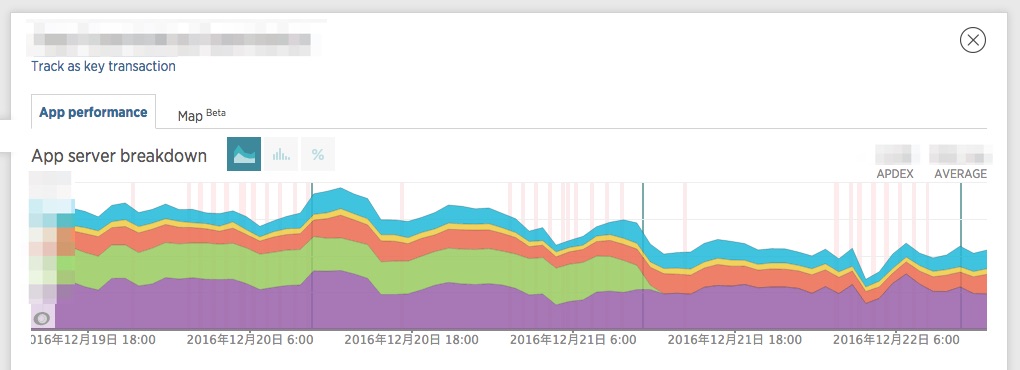
New Relic APM Pro で使える機能に “Deployment Tracking” があります.この機能を使うと New Relic にデプロイ日時を記録することができ,自動的に Before / After のパフォーマンス比較を確認することができます.過去のデプロイを振り返るときに非常に便利です.以下の画像に3本ある「緑色の縦棒」がデプロイ記録です.実際に 12/21 からパフォーマンスが改善されていることが確認できます.
(サンプル:New Relic)
チームへの効果
このように様々な可視化を推進し,メトリクス駆動な改善をし続けた結果,サービスのボトルネックが明確になり,各メンバーが自律的に動き出せるようになりました.また改善後の効果計測も,担当した各メンバーが確認し,チームに共有してくれるようになりました.このように,モニタリングと効果計測がチームの文化として根付いたことは素晴らしい成果だと感じています.
効果を社内勉強会で発表した
インフラ側の成果をチームに共有するために社内勉強会で発表しました.非常に高評価でしたし,発表資料を個人ブログに載せたら,ホッテントリに入り,計100ブクマ以上も頂くことができました.
社長を巻き込んで技術的負債の解消に価値を置いた話
最後はエモい話で締めようと思います.
成長期のスタートアップにおいて,技術的負債の解消にフルコミットするには,組織的にも必要な投資であると社長に理解してもらう必要があり,さらに価値のある成果であると適切に評価できる組織を目指す必要がありました.特に弊社のように経営陣が全員非エンジニアである場合は尚更です.
そこで,社長にもっと技術の楽しさを知ってもらうため,以下のアクションを行いました.
- ウェブ企業の技術ブログで良かった記事を大量に「読みましょう!」とシェアした
- 勉強会の発表動画が公開されていたら「観ましょう!」とシェアした
- 僕が外部の勉強会で LT をするときに「僕の資料どうですか!」とシェアした
- チームで毎週実施している社内勉強会に「参加お願いします!」と頼んだ
- 別プロダクトの開発責任者と話す場を用意して「モダンな開発プロセスはこんな感じなんです!」と聞いてもらった
私が特に良いなと思った “Recruit Technologies Open Lab : Infrastructure as Code” の発表動画も社長に観てもらったところ,ウェブオペレーションのように「効果が見えにくい」分野の改善も理解してもらうことができました.今では社長がエンジニアと共通言語で普通に議論できるようになっています.これには本当に驚かされました.
真面目な話をすると,私は「非エンジニアだから価値を理解してもらえないだろう」と伝えることを諦めるのは間違っていると思います.「価値のある改善であることを理解してもらえるまで繰り返し話す」ことがエンジニアに求められていると思います.私は対話を最重要と考えて,積極的にアクションを行ってきました.
「伝える」ことは思った以上に難しいものです.社長を巻き込んだ話はまた後日詳しく Developers Blog にてお伝えできればと思っています.
まとめ
長くなってしまいましたが,私が取り組んできたポイント3点を紹介しました.「課題 A を修正するためには,課題 B の修正が必要で,実は課題 C も関係していて…」といった日々の繰り返しで,まさに Yak Shaving でした.大変なことも多くありましたが,常に成長でき,楽しく働いています.
- Well-Architected を目指して改善をし続けた話
- モニタリングと効果計測をチームの文化として根付かせた話
- 社長を巻き込んで技術的負債の解消に価値を置いた話
改善前と比べると,障害の発生頻度が激減しましたし,アプリケーションのパフォーマンスも改善しました.全ては日々一緒に奮闘しているメンバーの成果です.
ただし,まだまだ道半ばです.”Well-Architected” ではない部分も多いですし,今後さらにサービスは成長します.私は今後もウェブオペレーションに挑戦し,サービスに貢献します.