
はじめに
AI事業本部Dynalystのエンジニアの加藤です。
2019年4月にサイバーエージェントに入社し、MLエンジニア・データサイエンティスト(以降DS)として主にPythonとSQLを用いて分析業務に携わっています。今回のブログでは既存の機械学習モデルの検証からモデルの精度改善についてのアプローチを通じて、本番環境で動く機械学習モデルの性能を追試することの重要性を伝えるとともに、DSがどういう切り口で問題を分析していくのか、DSはどの程度まで開発サイドに携わるべきか等の考えをお伝えできればと思います。
背景: オンライン広告配信の仕組みとDynalystの立ち位置
まず、オンライン広告業界で日々行われている Real-Time Bidding (RTB) という仕組みと、Dynalystの立ち位置についてざっくり説明します。
webサイトを訪れた際に広告が表示された経験はほとんどの方がお持ちだと思いますが、実はどの広告を出すかは、皆さんが訪れたタイミングで初めて決定されています。webサイトに広告枠がある場合、広告枠を管理している SSP と呼ばれる事業者が、広告自体を持っている DSP と呼ばれる事業者たちに「この広告枠をいくらで買ってくれますか?」という入札リクエスト(Bidリクエスト)を送信します。それぞれのDSPは、webサイトの情報等を元に利益の期待値を予測し、価格を決定して入札を行います。複数のDSPが入札した場合は価格が一番高い入札が採用され、落札したDSPの広告が掲載されます。このような、SSP(出品者)とDSP(落札者)が行う広告枠オークション全体のことをRTBと呼びます。
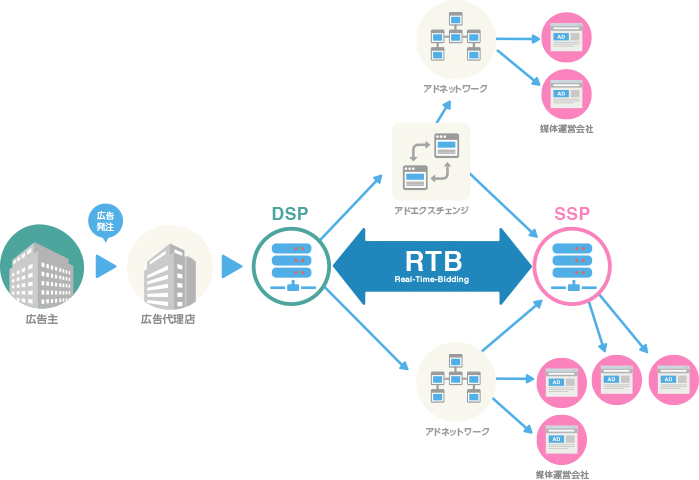
日本一やさしいアドテク教室 – CyberAgent | AI tech studioより引用した図。
実際にはSSP、DSPに加え多くのプレイヤーが存在する。
DynalystはDSPとしてリターゲティング広告を配信しています。ここでは、適切な価格を決定するためにまずは利益の期待値をできる限り正確に予測することが重要視されています。指標としては広告のクリック率 (CTR)やコンバージョン(CV)率(CVR)といったものがよく使用されています。CVは例えばアプリのインストールや商品の購入など、広告主が最終的にユーザーにしてほしい行動を指します。
利益の期待値を見誤ることは、本来広告内容にあまり興味のないユーザーに対して高い価格で広告を配信することによる配信コストの増大や、逆に高確率でCVが発生するユーザーに対して低い価格で入札し、オークションに負けた結果広告を配信できないという機会損失に繋がります。そこでDSの重要なタスクとして、Bidリクエストに対してCTRやCVRを予測するモデルを作成し、配信利益を最大化するということが挙げられます。
予測モデルの性能モニタリング
Dynalystでは機械学習を用いてCTR・CVR予測を行っていますが、継続的に機械学習モデルを運用するためには各種メトリクスを監視し、現Verの予測モデルの精度が想定より悪化していないか常に監視する必要があります(過去に学習元になるログファイルをいじっていたところ、モデル学習時にデータが参照されず予測モデルを暴発させた経験もあります(汗)。幸いアラートが上がりすぐに復旧されましたが……)。Dynalystでは特に最近、様々な予測モデルを用いて複数のA/Bテストを実行しており、手動での監視が難しくなりました。そこでモデル精度や学習データ数などをDatadogで監視して、想定範囲外の値が観測された場合にモデル更新を中断したりSlackに通知したりする仕組みを運用し始めています。
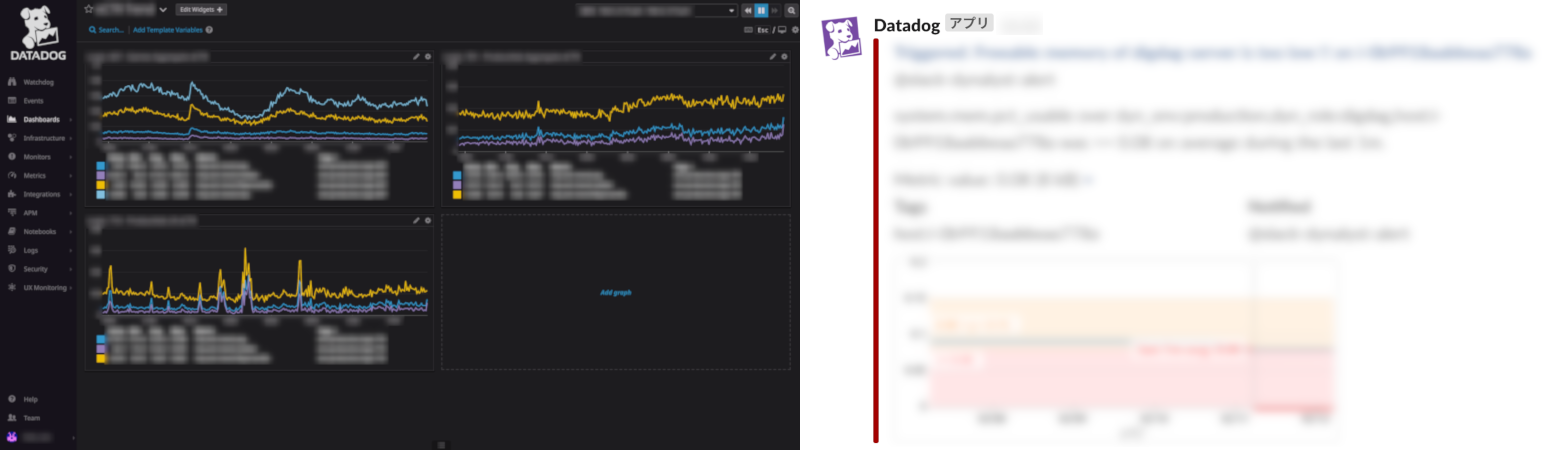
Datadogでメトリクスを監視している様子(左)と、Slackに通知されたアラート例(右)。
どのような指標を監視すればよいのか、アラートを飛ばす閾値はいくらにすればよいのか等に明確な基準はなく、現状は明らかな異常値のみを検知するようにしています。予測精度の監視についても、クリックやCVは広告表示後すぐに発生するとは限らずリアルタイムでの監視が難しいので、とりあえずTableauで実績をグラフ化しておき、手動でモニタリングしておかしければ確認するという運用方法をとっています。このあたりの異常検知システムについてはまだまだ議論が必要だと考えています。
問題の発見
さて、このようなモニタリングにより不慮の事故を概ね防ぐことはできますが、それでは既存の予測モデルは完璧に機能しているのでしょうか。機械学習モデル自体は自分が入社する前から運用されていましたが、本番環境で精度を監視していたのみで、そもそもローカルで実験していたときと同じ性能が出ているのか等についてはあまり深く検証はされていませんでした。
DynalystのDSチームは意思決定を自分たちで持っているので、他所から飛んできた分析タスクをこなすのではなく自分たちで課題を探しながら業務を進めています。なので普段はメインタスクを進めつつも、気になるところがあれば割と自由に分析できる環境にあります。このあたりは開発責任者が元MLエンジニアでDSチームの定例ミーティングに参加していたりと、チーム全体でML・DSに対する理解があるのでうまくワークできているのかなと感じています。
自分もメインタスクを進める中で、どうやら特定の条件のときに予測値が低い傾向にあるようだと気付き、その原因を深堀りしていきました。なんとか条件を特定して予測値と実測値の乖離度合いを確認してみたところ、下図のように大きな乖離が生じていました。
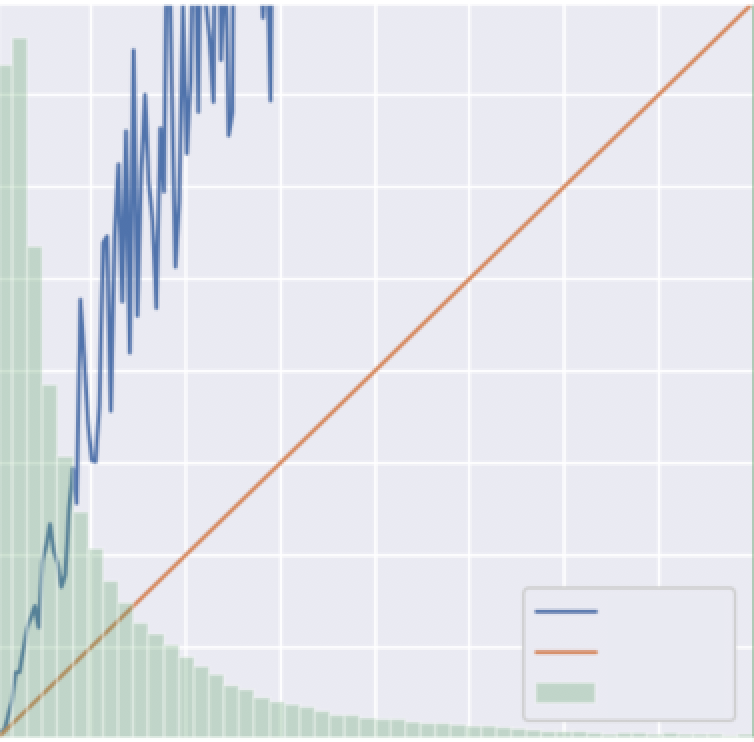
乖離が生じていた条件に絞ってcalibration curveを描いてみた図。calibration curveとは、横軸に予測値、縦軸に実測値を取るグラフで、分類モデルを確率値として利用する際に用いられることが多い。青線がy=x(オレンジ線)に近いほど予測がうまくいっていると言える。本来はy=1を超えることはないが、諸事情により補正を加えているのでこのグラフは超えている。
どこに問題が生じているのか確認するために予測環境をローカルで再現し、実際に過去のデータに対して予測させてみたところ、特定の条件において、ローカルで予測した値と実際に使われた値に乖離が生じていました。予測モデルが正常に学習できていないというよりは学習した予測モデルが適切に使われていないと推測を立ててサーバー側の実装を確認していったところ、特定の値が予測時に取得できておらず全て0として計算されていたことが発覚しました。
修正結果
問題を修正し適切な予測値が使われるようになった結果、calibration curveがかなりまともな図になりました。2ヶ月間ほど分析して実際に修正したコードは2行ほどでしたが、この修正により特定条件での入札が適切に行われるようになり、利益の効率化に大きく貢献しました。
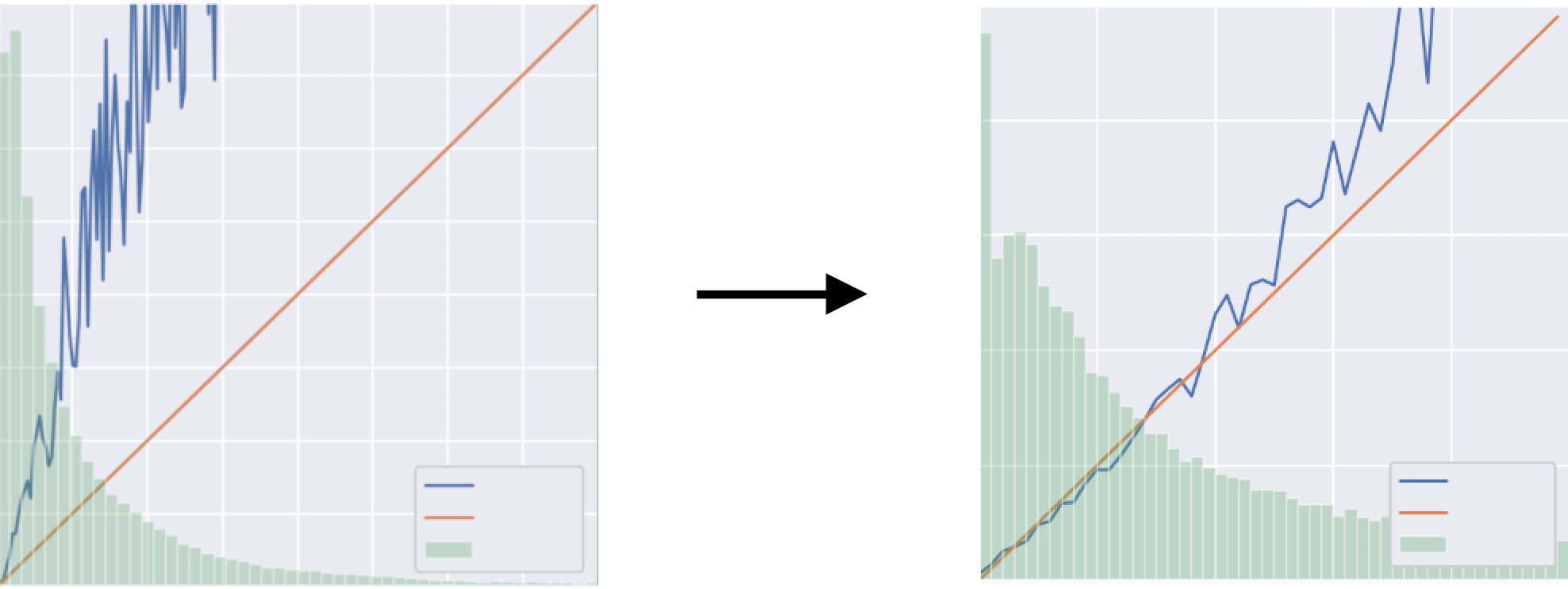
修正前のcalibration curve(左)と、修正後のcalibration curve(右)
さいごに
MLチームのあり方は会社により異なるかと思いますが、DynalystのようにML以外でもデータに関わること全般を広く担当するチームと、MLモデルの作成のみに特化したチームの大きく分けて2種類に分類できると思います。前者の広く担当するチームのメリットとしては、プロダクト内に深く入ることで新たな課題を発見しやすい点や、今回のように問題がMLモデル外に発生していた場合に対応しやすい点等が挙げられます。後者の特化型チームのメリットとしては、ML部分だけを切り離すことでプロダクトへの依存度を減らし、他プロダクトをまたいで活動しやすい点や、MLモデル作成だけに注力することでより優れたモデルを作成できる点等が挙げられます。
どちらも一長一短ですが、個人的には前者のチーム体制のほうが働きやすいかなと考えています。特に既存プロダクトにMLを採用していく場合は、優れたMLモデルを作ることと同等に、まず何をMLに置き換えればKPIが改善するのか、今のデータ構造に課題点はないか等を考えることが重要となります。また、本番に投入したMLモデルを継続的に使用することは想像以上に難しく、モデル精度の悪化や学習の異常終了など、MLモデル部分以外での問題が多く発生します。そのような不具合に対して、前者の体制のほうが柔軟に対応できるのかなと思います。
チーム体制のあり方やMLモデルのモニタリング等まだまだ解決すべき課題があるので、今後も議論を重ねながら改善し続けていきたいと思います。以上、AI事業本部Dynalystの加藤でした。
おまけ
月イチで表彰があるのですが、今回の改善がきっかけで2019年12月にAI事業本部アドテクDivのMVE(Most Valuable Engineer)をいただきました。MVE以外にも新人賞やチーム内ベスト等の表彰があり、成果に対して褒める文化が根付いていて非常に働きやすい職場なので、興味のある方はぜひAI事業本部にお越しください。

以上。