はじめに
初めまして!早稲田大学修士2年の栗原健太郎です。ML/DSポジションでサイバーエージェント2023年入社の内定をいただいています。現在は、大学での研究と、入社に向けて各事業部のリアルな仕事や雰囲気を経験することができる内定者バイトに励む毎日を過ごしております!
大学では自然言語処理(NLP)分野で研究をしていますので、今回のアルバイトでもNLP関連のタスクに取り組みました。
本記事では、2022/06-2022/08の3ヶ月間ジョインさせていただいていたAI事業本部 株式会社AI Shiftでのアルバイト中の取り組みやAI Shiftの雰囲気などについて紹介していきます!この後詳細を述べていきますが、まず初めに
「充実した3ヶ月間を過ごすことができました!!」
とお伝えします!NLP・音声分野の活用や研究に関心が強いエンジニアにとって非常に過ごしやすい環境であったと感じましたので、そのような方には特にAI Shiftへ興味を持っていただければと思っております。
取り組んだタスクについて
FAQシステムの背景
株式会社AI Shiftの主力事業の一つがチャットボット・ボイスボットを用いたFAQ対応の効率化になります。FAQ対応にチャットボット・ボイスボットを用いることで、あるサービスを活用するユーザーのFAQ対応を、チャット・電話などの手段を問わずに自動で解決することが可能となります。
チャットボットは、ユーザーの質問に対して複数のFAQをサジェストし、問合せ内容の解決に最も適したFAQをユーザーに選んでもらうという形式のFAQシステムになっています。一方ボイスボットは、自動音声であるという背景から複数のFAQをサジェストすることは難しく、1つのFAQを決めうちでサジェストするという形式になります。いずれのボットにおいても求められる性能は、「ユーザーの問合せ内容に対して、どれだけユーザーの問合せ内容の解決につながるFAQを返すことができるか」という性能になります。
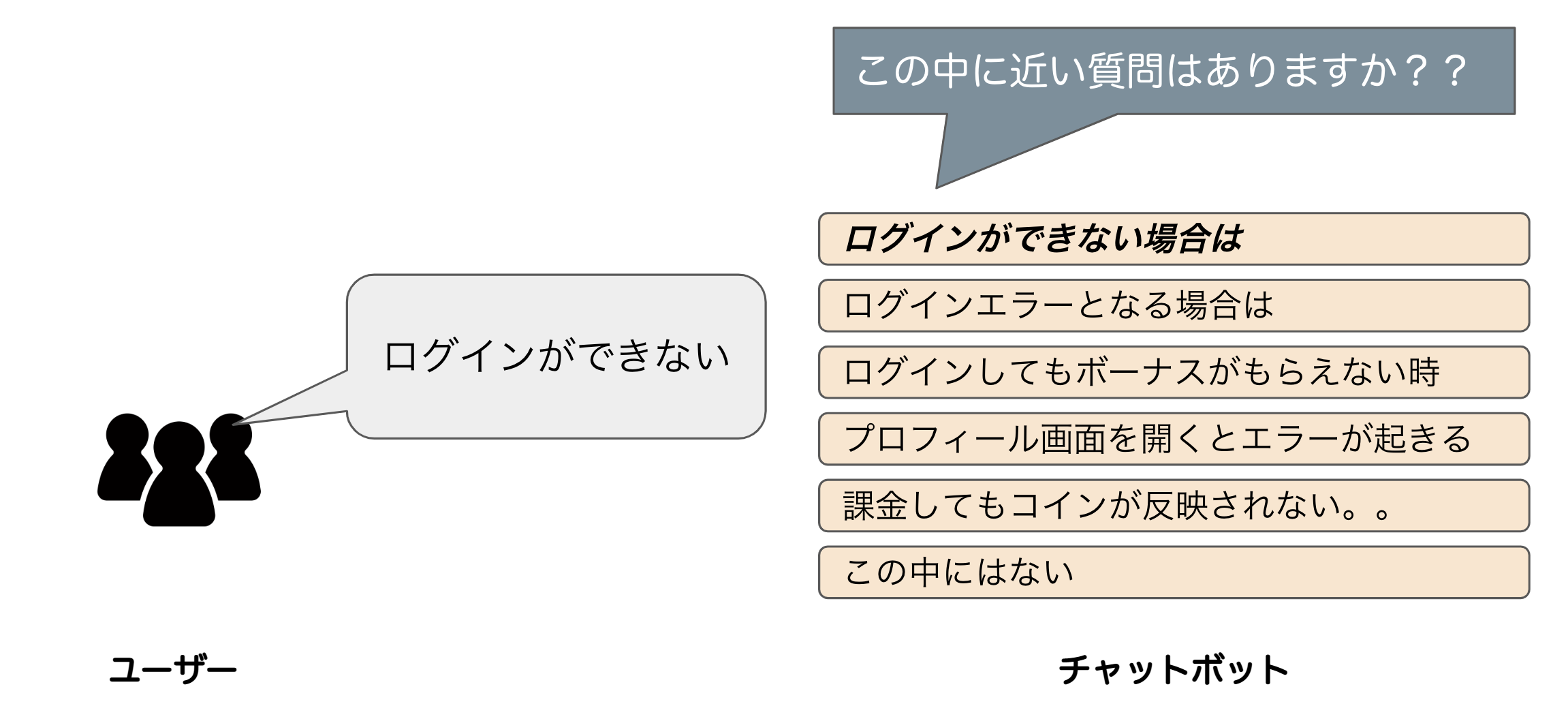
チャットボットとボイスボットにおけるFAQシステムの要素技術には、言語モデルを使用しています。言語モデルの学習においては、チャットボットにおけるユーザーの選択したFAQとユーザーの質問の対話ペアを正例として用いています。本アルバイトでの自分のタスクは、チャットボット・ボイスボット両方で適用可能な「FAQシステムに用いている言語モデルの学習データのフィルタリングによる性能向上の試み」でした。
タスク設定
本アルバイトの非常によかったと思えるポイントの一つがタスクの設定になります。与えられた解像度の高い課題をタスクとして与えられるのではなく、抽象度の高い課題について調査し、その中で発見したより具体的な課題の解決をタスクとすることができました。
まさに、実際の業務において、課題感が明確になっていない場合が多々存在するというリアルさを体感する絶好の機会でした。
具体的には、「ユーザーの質問(問い合わせの)意図がよくわからない」という抽象度が高い課題の実態調査からアルバイトはスタートしました。この調査のために、チャットボットにおける過去の対話ログを眺めていく中で、
- ユーザーのサジェストの選択が適当に行われる事例が多々存在しており、ユーザーの選択したFAQが必ずしも最適とは言えない。
- 1にもかかわらず、本対話ログにおける「ユーザー質問とユーザーが選択したFAQ」という対話ペアを、正例として用いて学習した言語モデルが、新ロジックとして適用されている。
- 学習データのフィルタリングによってさらにFAQシステムの性能を向上できるかもしれない。
という、解像度の高い課題の発見とその改善方法の仮説立てをすることができました。
つまり、抽象度の高い状態で始まったアルバイト期間中のタスクを「FAQシステムの学習に用いている学習データのフィルタリングによる性能向上の試み」という具体的なタスクに落とし込むという流れを経験することができました。
タスク完了までの流れ
分析
タスクは決まったものの、対話ログを眺めている中で感じた「ユーザーの選択したFAQが必ずしも最適とは言えない」という直感の定量的な調査はできていませんでした。そこで、タスク着手時点で正例として用いられていた対話ペア約800件程度に対して、「正例として用いるのにふさわしい対話ペアであるか否か」という2値分類のアノテーションを実施しました。このような地道なアノテーションはNLPあるあるな作業の一つで面倒臭くもあり面白くもある部分です。
アノテーション結果については以下のようになりました。
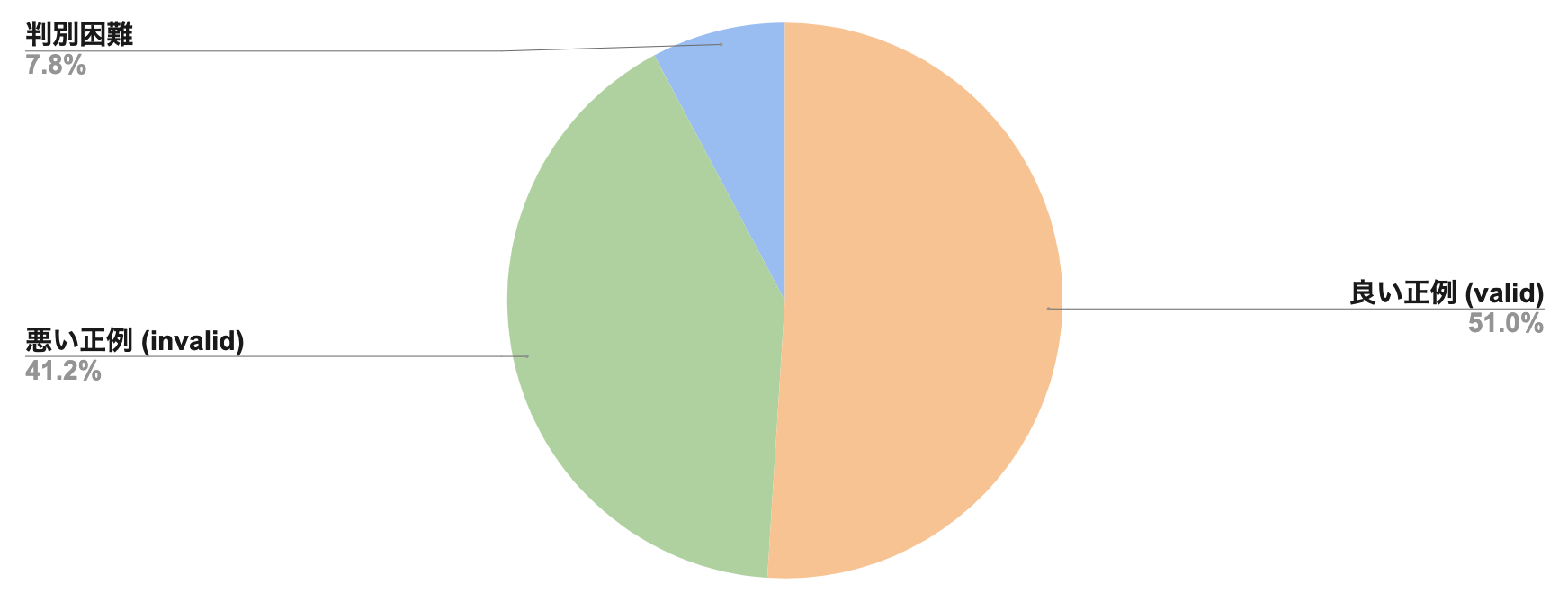
アノテーションの方法や基準についての議論は、本稿では割愛しますが、正例として用いているデータの半数弱に怪しさがあることを改め確認することができました。このような品質の低い正例 (invalid data)をフィルタリングしていきたいですが、その数は数十万件。。。なんとかフィルタリングを自動化したいところです。
提案手法
分析と実験
品質の悪い正例ペアを自動フィルタリングするための手法として、今回は「JSTS [1]で学習したBERT [2]の活用」を提案します。具体的には以下のような手順でのフィルタリングを提案します。
- BERTの事前学習モデルをJSTSデータセットを用いてファインチューニングを実施
- 学習したBERTを用いて各正例の対話ペアの類似度を予測
- 類似度の低い正例の対話ペアを除去
JSTSは、0から5のいずれかの連続値を類似度として割り当てた文ペアのデータセットであり、JSTSで学習したBERT (以下JSTSモデルと呼ぶ)を用いることで2文間の類似度予測をすることが可能です。
こちらの提案手法を適用する前にまず、JSTSモデルを用いて、前節でアノテーションした対話ペアの類似度を獲得し、その分布を確認したところ以下の図のような分布となりました。
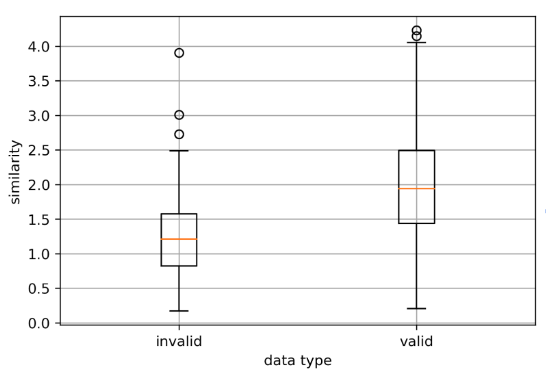
図を見ると、確かにinvalid dataの類似度がvalid dataと比較して類似度が低い傾向があることが読み取れます。例えば、類似度1.5以下の正例対話ペアを除去した場合、valid dataの25%程度のデータは失われるものの、invalid data75%程度のデータを除去することが可能です。
ここまでで、提案手法の方向性の良さとフィルタリングの閾値の感覚が見えてきたので、実験に入りました。
実験の内容は、「訓練データをフィルタリングを実施せずに学習した通常の言語モデルと、フィルタリング済み訓練データを用いて学習した言語モデルの性能の比較」になります。(言語モデルの要素技術にDPR [3]を適用していますが、本稿では割愛いたします。)
フィルタリングは以下の表の通り3種類のパターンで実施して比較を行いました。
| フィルタリングA1 | 類似度 (similarity) 1.5以下の正例対話ペアを除去 |
| フィルタリングA2 | 類似度 (similarity) 1.0以下の正例対話ペアを除去 |
| フィルタリングB | 各テナントのデータを10%削減するようにテナント毎に閾値を設定 |
フィルタリングAについては、ある定数以下の以下の類似度の正例対話ペアを除去し、フィルタリングBについては、一定の割合の正例対話ペアを各テナント毎に除去をしました。
言語モデルの構築は以下のフローで実施しました。

評価データ
評価データにはチャットボットのデータを用いており、モデルの訓練に用いているテナントの対話データで構成されている評価データセット(known data)と、モデルの訓練に用いていないテナントの対話データで構成されている評価データセット (unknown data)の2種類を用いました。スコアについては、各テナント毎に、ユーザー質問に対応しているFAQを選べたか否かの精度を獲得し、その平均値をスコアとしました。
結果・考察
実験結果は以下のようになりました。
| model \ data | dev (known) | test (known) | dev (unknown) | test (unknown) |
| 既存モデル | 0.284 | 0.290 | 0.302 | 0.291 |
| model-filteredA1 (s≤1.5) | 0.278 | 0.285 | 0.352 | 0.364 |
| model-filteredA2 (s≤1.0) | 0.296 | 0.305 | 0.365 | 0.323 |
| model-filteredB (10%) | 0.295 | 0.308 | 0.333 | 0.330 |
既存モデルと比較して、フィルタリングを実施したモデルの方が全般的に高スコアが出ていると言えます。ただし、model-filteredA1がcommon dataにおいて既存モデルより劣っていることから、閾値が高すぎる場合に良質な正例が多く除去されてしまう可能性があります。
また、unknown dataにおいてはフィルタリングを実施した全てのモデルにおいて既存モデルの性能を超えています。この結果は、提案手法を用いることによって、未知テナントにおけるFAQの予測性能が向上したこと、および訓練データの存在しない新規テナントでのボット適用におけるコールドスタート問題の解消につながることを示す結果となっています。
閾値の設定方法について、common data (test)においてmodel-filteredBが最高スコアを得ていることから、閾値の定め方による性能の違いが生じると考えられるため、今後は閾値の変更による性能の変化について調査を実施する必要がありそうです。
とはいえ、短い期間でタスクの設定から定量的な(良い)結果を得るまでを無事完了することができてよかったです!!😂😂
タスク以外のお話
ここまでタスクについて述べてきましたが、ここからはAI Shiftのメンバーや組織全体、そして内定者バイトそのものについて感じたことを述べていきます。特にAI Shiftについて一言で言えば「めちゃくちゃ良い環境でした!!」という言葉につきます!
AI Shiftについて
成長できる
成長できる環境は、働く場所を選ぶ上で重要な観点の一つと考えていましたので、今回AI Shiftが非常に成長環境として良い環境であると実感できたことは、内定者バイトにおける最も大きい収穫といえます!特に
- わからないことをすぐに相談できる。また、理解できなかった時や理解が薄く抜け落ちてしまった箇所も繰り返し聞くことを咎められない。
- 忌憚のないアドバイスをもらえる
という2点に強く魅力を感じています。
前者について、チャットボット・ボイスボットという領域に初めて関わっていく上での、序盤のインプットの量はとにかく多かったです。そのため、理解できないことや、一度教わっても忘れてしまうこともしばしばありました。それでも分からないまま放置しないで、何度でも質問していい(これが特に心理的に非常に嬉しいポイントでした)と言ってくれた社員さんの助言のおかげもあり、常に気軽に質問を投げることができました。行き詰まったまま迷走する時間がほとんどないので、アウトプットを多く出せると思いました。
後者について、自分の分析や実験の甘い点についてはとことん指摘してもらえます。この点も、常に詰めが甘い傾向にある自分としては大変良い点でした。自分の担当タスク以外についても当事者意識を持って気になる点を指摘しあえる環境は、貴重であると思いました。
コミュニケーションが盛ん
社内のコミュニケーションが非常に盛んである点も非常に魅力的でした。社内のビジネスメンバーと開発メンバーのコミュニケーションを促す仕組みが整っていることもあり、チーム内はもちろんのこと、チームの垣根をこえたメンバー同士のコミュニケーションも盛んでした。
それゆえに、プロダクトの課題のチーム間の共有も早く、ゴールを見失うことなく常にビジネスインパクトを意識した研究・開発に取り組むことができるというのはAI Shiftの最大の強みに感じました。(そして人と話してることが基本的に大好きな自分の性格とも非常にマッチしていると思いました笑)
積極的に挑戦できる
サイバーエージェント全社でこの色は強いとは思いますが、もちろんAI Shiftも例外ではありませんでした!まず、内定者バイトという身分でありながら主体的にタスクを決定させてもらえる環境は、そう多くないのではないのかなと思います。さらには、本稿で述べたタスクの内容で論文を書かせていただける可能性もあり、まさに挑戦することを一切咎めない社風はピカイチだなと感じております!挑戦することにはプレッシャーも伴いますが、うまく折り合いをつけつつガムシャラに頑張っていこうと考えています。
内定者バイトについて
リアルな業務経験
やはり、ここまでリアルな業務の経験をすることができるアルバイトは貴重だと思います。大学の研究などでは扱うことのできないような膨大なデータ、あるいはリアルなデータを扱った仕事できるので、エンジニアという仕事の解像度を上げるのに絶好の機会です。どの部署で働いてもこの点はブレないと思いますので非常に良い制度だと感じます。もちろん大学での研究などの本業が忙しい学生が多いとは思いますが、本業に支障が出ない範囲で働くことができますので、自分のペースに合わせて働くのが良いと思います。
ランチ
内定者バイトにおける制度の一つとして、社員さんとランチに行く機会がたくさん用意されていましたので、美味しい肉や魚などを堪能する日々を過ごしておりました。(そして太った。)
と書くと、なんだその制度?となってしまいますが、もちろんこの制度は肉と魚を堪能できることだけがメリットではありません。社員さんとのランチの機会が多くなることで、必ず内定者と社員さんのコミュニケーションが盛んになります。ここでいう社員さんは他部署の方(自分の場合AI Shift以外の方)でも良いので、会社のことやキャリアのことなどの相談はもちろんのこと、他部署の情報収集の場として活用することもできます。もちろん人脈も広がります。おかげで、自分のキャリアや配属などに関する不安を常に共有・相談できる環境が整っているというメリットを自分は感じていました。本当に良い制度だと思います。
総括
最後にまとめです!箇条書きで失礼します!
- AI Shiftでの内定者バイトは主体性が求められる部分が大きい。
- 一方で、働く環境が非常に良いため、それでも安心して働くことができる。
- 内定者バイトでは、今回記事にしたタスクを始めとした無数の実業務を経験することができる。
- 内定者バイトのランチは神
以上です。AI Shiftの皆さんや面談・ランチなどで関わってくれた多くの方々に感謝申し上げます!ありがとうございます🙇♂️
参考文献
- Kurihara, K., Kawahara, D., and Shibata, T. (2022). “JGLUE: Japanese General Language Understanding Evaluation.” In Proceedings of the 13th Language Resources and Evaluation Conference. European Language Resources Association (ELRA). to appear.
- Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2019). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171–4186, Minneapolis, Minnesota.
- Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., and Yih, W.-t. (2020). “Dense Passage Retrieval for Open-Domain Question Answering.” In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) pp. 6769–6781, Online. Association for Computational Linguistics.




