
アドテク本部の大田です。普段はアドテク本部内の研究開発組織 AI Lab においてインターネット広告クリエイティブの自動生成に関する研究に携わっております。
今回は同じく AI Lab に所属している山口の招待講演が行われ、我々にとって重要な研究領域であるコンピュータビジョンのトップカンファレンス ICCV 2017 に参加してきましたので簡単にですがレポートを記したいと思います。

会場はイタリア・ヴェネツィアのリド島にある PALAZZO DEL CINEMA。巨大なスクリーンを構えるホールを3つ有するシアターであり、ヴェネツィア国際映画祭にも使われているようです。ちなみに我々はヴェネツィア本島の方に宿泊していたため、毎日水上バスでホテルと会場を往復していました。
ICCV について
ICCV は CVPR/ECCV と並ぶコンピュータビジョンのトップカンファレンスであり、ECCV と交互に隔年開催されています。今年は16回目の開催となり、参加登録者数は 3,107 人にも上ったそうです。論文投稿本数は 2,143 本、その内 621 本が口頭発表もしくはポスター発表へと採択されました。
会議日程はチュートリアル・ワークショップ・メインカンファレンスに大別されます。メインカンファレンスにおける口頭発表は全て大会場にてシングルセッションで行われ、他の2ホールへとライブ配信されるようになっています。

ワークショップにおける招待講演・共著論文
最終日の Computer Vision for Fashion ワークショップでは山口が招待講演 Computer Vision meets Fashion としてファッションにまつわるビジョン研究における昨今の発表や動向を踏まえつつ自身の研究についても紹介。参加者との活発な質疑応答が行われました。

また、同ワークショップ・ポスターセッションにおいては東北大学 Tangseng さんとの共著論文 Recommending Outfits from Personal Closet についても発表。個人の持つアイテム群から適切な着合わせを推薦するシステムを提案しています。

発表論文紹介
それでは数々の発表の中から大田が気になった論文について幾つか紹介したいと思います。
Mask R-CNN
Kaiming He, Georgia Gkioxari, Piotr Dollár, Ross Girshick
https://arxiv.org/abs/1703.06870

論文より図2: Mask-RCNN によるセグメンテーション結果
FAIR グループによる今回の ICCV の Best Paper Award 。物体認識と同時に各物体の領域までをも高精度・高速に推測するネットワーク構造の提案を行っています。これにより同じクラスに属する物体の fine-grained な認識も可能になったとのこと。結果もさることながら He さんによるプレゼンテーションも圧巻で会場が沸いていたように思います。
Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks
Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros
https://arxiv.org/abs/1703.10593
https://junyanz.github.io/CycleGAN/

論文より図1: CycleGAN による画像間でのスタイル転送結果
既存手法において必要とされていたペアワイズな訓練データセットを必要とせずに元画像から対象画像へとスタイルを転移させる CycleGAN の紹介。スタイル転移元と転移先ごとにデータ集合を作成できていれば、両方向のスタイル転送が可能であることを結果画像によって示しています。
StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks
Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, Dimitris Metaxas
https://arxiv.org/abs/1612.03242
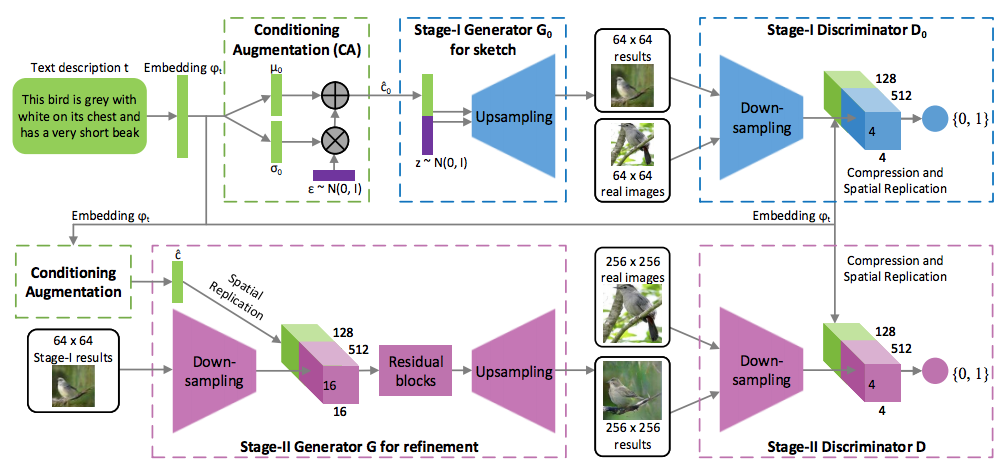
論文より図2: Stage-I と Stage-II という StackGAN の2段構え構造
GAN を2層分束ねることで説明文のみからの画像生成を行う手法を提案しています。1層目で説明文から一旦低解像度の画像を生成し、2層目で 256×256 への高解像化を施すといったフェーズになっています。
Learning Cooperative Visual Dialog Agents with Deep Reinforcement Learning
Abhishek Das, Satwik Kottur, José M. F. Moura, Stefan Lee, Dhruv Batra
https://arxiv.org/abs/1703.06585
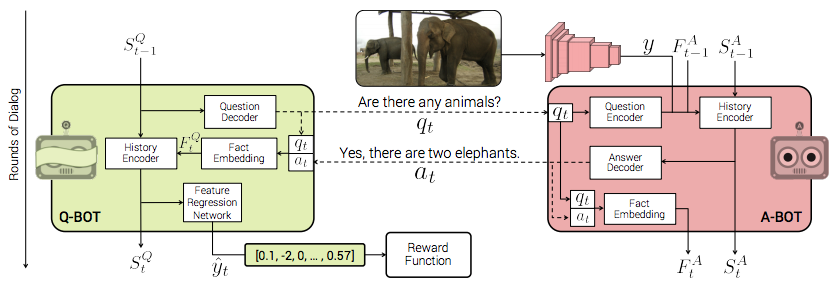
論文より図2: Q-BOT と A-BOT に分かれ、質疑応答を繰り返すことで画像を推測。正解に近いと報酬が得られる
CVPR 2017 で報告されていた Visual Dialog に強化学習の枠組みを追加。画像を手元に用意した A-BOT とその画像に関する質問を繰り返す Q-BOT とに分かれ質疑応答を繰り返すことで、最終的に Q-BOT が画像を推測し、正解すると報酬が得られるといったシステムを構築しています。VQA 版 Akinator といったところでしょうか。
MarioQA: Answering Question by Watching Gameplay Videos
Jonghwan Mun, Paul Hongsuck Seo, Ilchae Jung, Bohyung Han
https://arxiv.org/abs/1612.01669
http://cvlab.postech.ac.kr/research/MarioQA/
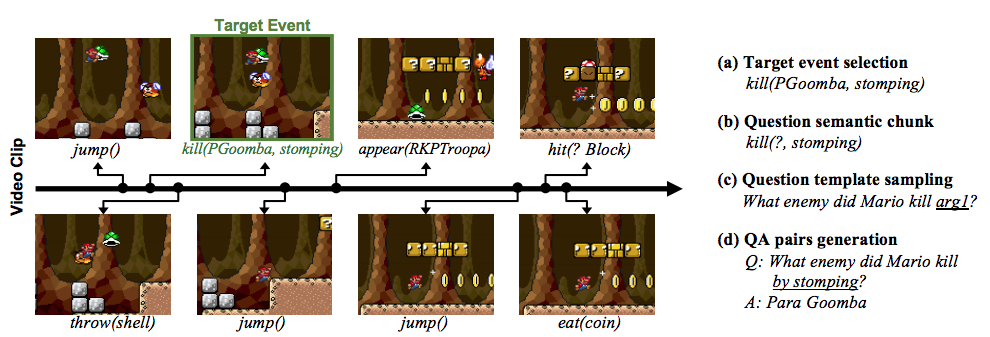
論文より図1: Video QA 生成の仕組み。時系列にまとめられたイベント情報と学習用の問答テンプレート
上記の通り、画像をもとに質疑応答を行うチャットボットは Visual QA ですが、こちらは動画、それもテレビゲームのプレイ動画を元に質疑応答を行う VideoQA という仕組みを提案しています。マリオがどういった動きや道具で敵を倒したかなど、動画シーンと対応するアクション・パラメータをコマンド形式で時系列にまとめ、それを学習させることで複雑な動きを含むアクションゲームに対するシチュエーションの QA フレームワークを構築しています。
BAM! The Behance Artistic Media Dataset for Recognition Beyond Photography
Michael J. Wilber, Chen Fang, Hailin Jin, Aaron Hertzmann, John Collomosse, Serge Belongie
https://arxiv.org/abs/1704.08614

論文より図2: ポートフォリオサイト Behance 上で感情をベースにラベル付けされたデータの一部
純粋な物体認識用のデータセットにおいては、招き猫の画像に対して ‘猫’というラベルを付与することはなかなかありません。アーティストのポートフォリオサービスである Behance から得られるような写真に留まらないイラストや風景などに対し、コンテンツや感情ベースでのラベル付を行ったデータセットの提案論文になります。
おわりに
今回の ICCV は複雑な認識タスクをニューラルネットワークをうまく組んで解くといったものや、教師なし学習・強化学習のアプローチで学習が行われているケースが多く見受けられたように思います。
メインカンファレンス初日には開催形式の変更についても議論されました。毎年開催になるとの噂もあったのですが、今後はこれまで通り隔年開催のまま口頭発表がパラレルセッション形式へと移行するそうです。また、次回 2019 年の開催は韓国ソウルになります。2021 年の開催地についても触れられ、オーランドとの多数決の結果、僅差でモントリオールに決定しました。
CVPR 同様、今回の ICCV の口頭発表動画も YouTube の Computer Vision Foundation チャンネルにアップされる予定だそうです。トップカンファレンスでの各プレゼンターによる論文解説発表をご覧になってみてはいかがでしょうか。
アドテク本部 AI Lab ではインターネット広告を取り巻く課題解決のため様々な研究活動を行っております。今回得た知見もクリエイティブ自動生成のみならず今後の研究開発にうまく取り入れ、事業をより伸ばしていけるよう役立てていければと思います。