
みなさんこんにちは!
現在2017年新卒としてアドテクスタジオのDynalystという部署でエンジニアをしております、中村と申します。
早いもので去年参加したAdvent Calendar 2016の内定者バイトの記事を書かせていただいてから一年が経ちました。
今回は、アドテクスタジオの代表として11月27日~12月1日にラスベガスで開催されたAWSのre:Inventに参加してきましたので、その時に聞いてきたRedshiftのお話をしようと思います。
元ネタのセッション動画はこちらにありますので、これを見ていただければこの記事より詳しく載ってますw
この記事はCyberAgent Developers Advent Calendar 2017 15日目の記事になります。
Amazon Redshiftとは
Amazon RedshiftはAWSのフルマネージドサービスのデータウェアハウスです。何ペタバイトものデータに対して高速にクエリを解析し並行に処理を実行することで、すぐにほしい結果を返してくれます。
とはいえ、やはりデータが多ければ多いほど、クエリが複雑であれば複雑であるほど結果が出るまでに時間がかかるのもまた事実です。
そこでRedshiftの構造をより深く知ることで、さらなるクエリの高速化を実現しうるポイントをここで紹介したいと思います。
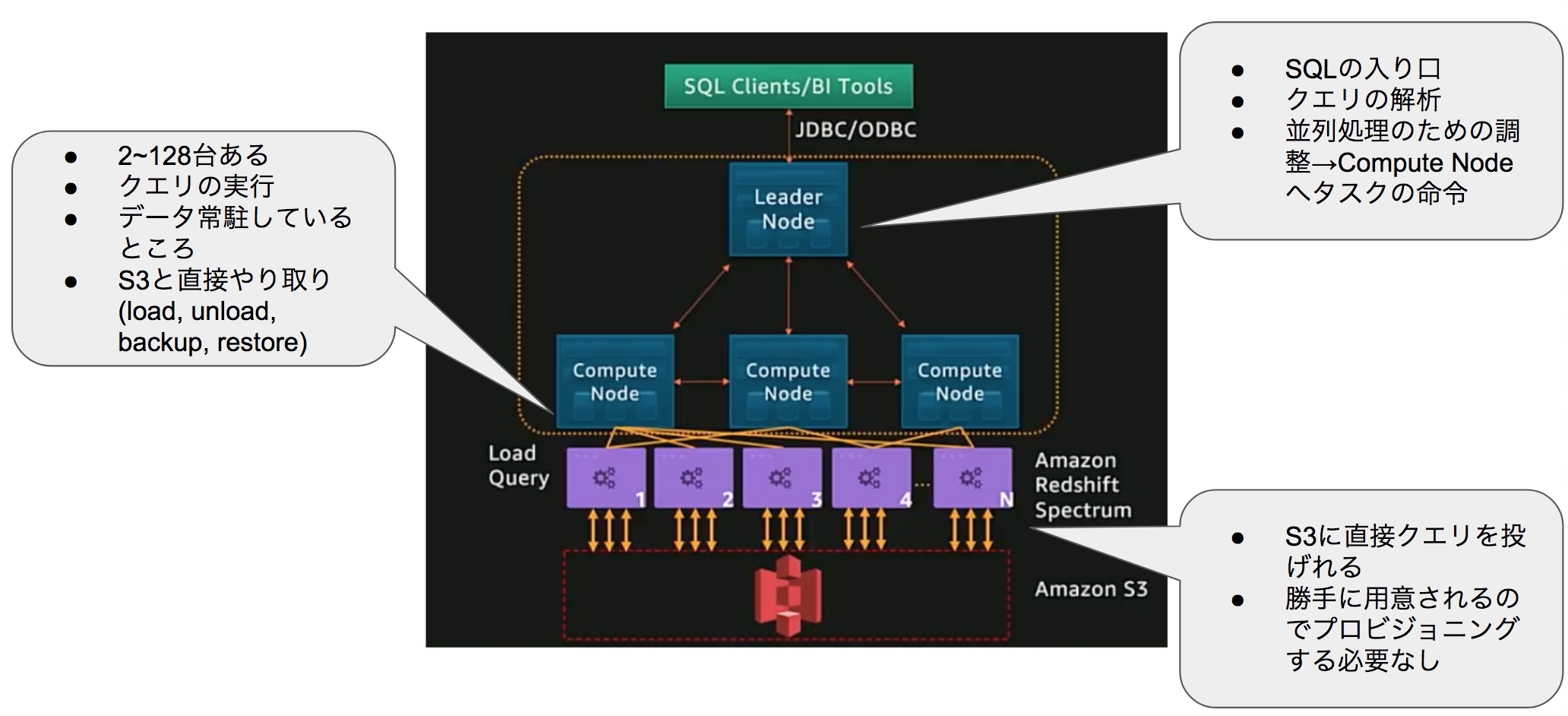
Redshiftの内部構造
Redshiftの内部ではまず、Leader NodeとCompute Nodeの二種類に分かれます。
Leader Node: ユーザーが流すクエリの入り口であり、そのクエリの解析、並行処理のための調整を行い、Compute Nodeへとタスクの命令を行います。
Compute Node: 実際にクエリの実行をするところです。対象のデータが常駐していてS3と直接やり取りします。
また、Compute Nodeの下にはRedshift Spectrumのレイヤが存在し、S3のファイルに対して直接クエリを実行することもできます。またこのレイヤは勝手にAWS側で用意されるため、自分でプロビジョニングする必要がありません。
Columnar
Redshiftでは列指向のストア方式を採用しています。
実際に分析をする際に必要なカラムは限られていることが多いので、この方式を採用しているのは納得ですね。後述しますが、データの圧縮においても列指向の方が当然圧縮しやすいでしょう。
圧縮
Redshiftを使うのであれば、小さなテーブルでない限りデータの圧縮は必須です。
圧縮をすることで、ストレージスペースの節約だけでなく、ディスクIOの量が減少するのでクエリの高速化が図れます。また、圧縮をすると圧縮前と比べてクラスタに4倍以上ものデータの保存が可能になります。
基本的にCOPYコマンドを使用してデータをS3からRedshiftへ移す時に自動的にデータが圧縮されます。
データ挿入後でもANALYZE COMPRESSIONコマンドで最適な圧縮タイプを知ることができます。また、圧縮タイプの一つとしてzstdもサポートしています。
ここでのポイントは「圧縮をすることにデメリットがない」ということです。積極的に全てのテーブルに対して圧縮をかけていきましょう。
Blocks
カラムごとのデータは1MBごとにイミュータブルなblockという単位に分割されます。
そして、その各blockごとに圧縮のエンコードがなされます。
Zone Maps
インメモリのblockのメタデータです。
blockごとにそのカラムのmin, maxの値を持っています。
後ほど例を挙げますが、このZone MapsがあることでIO処理を減らす効果があります。
Sort Keys
SORTKEYSによりカラムをソートすることでZone Mapsをより効果的に使用しIO処理を減らしてクエリの実行速度を上げます。
ここで実際に例を見てみましょう。
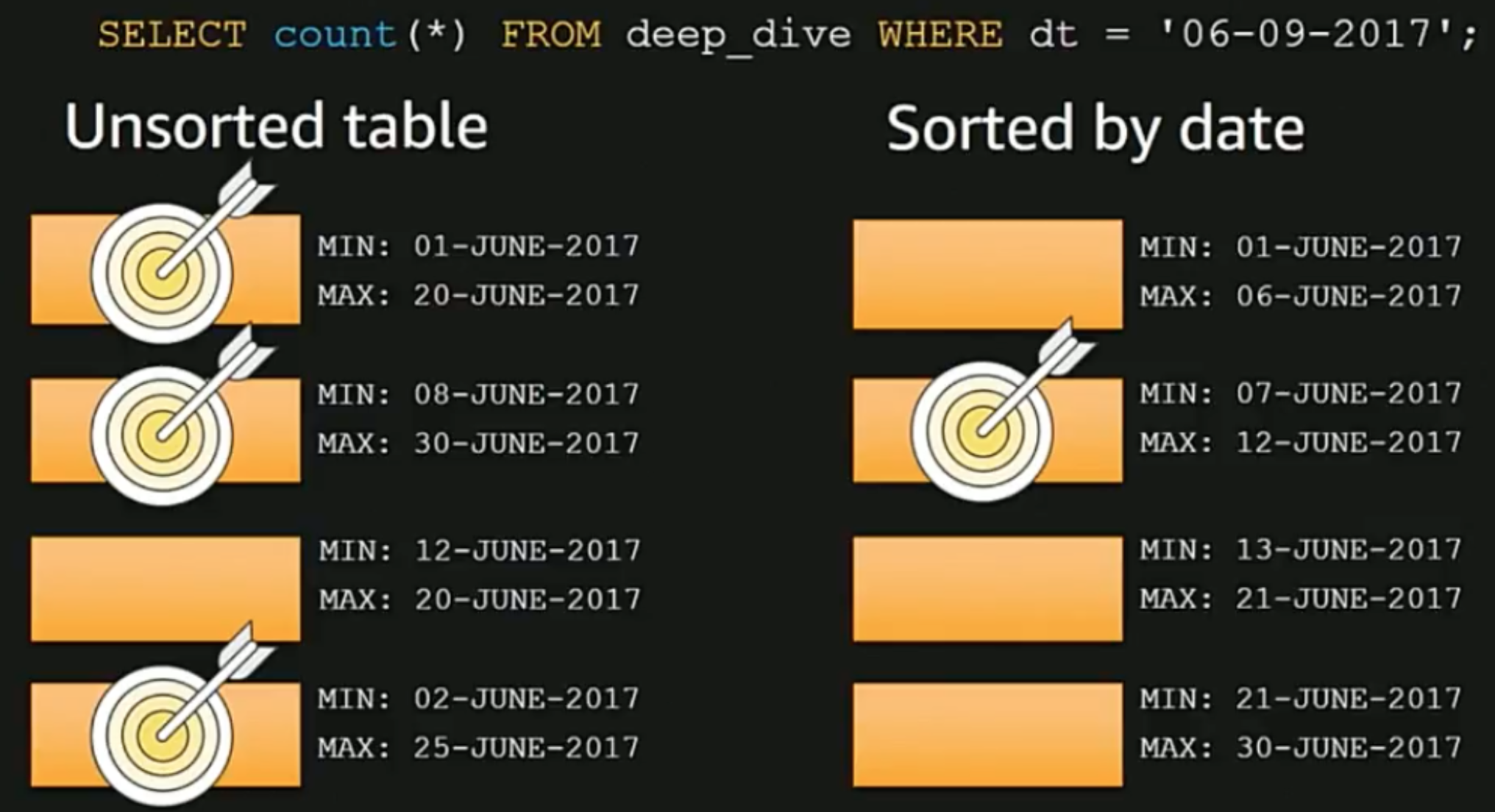
where句で2017年6月9日のデータの取得を試みている例です。
まず、左側のunsorted tableの4つのZone Mapsを見てみると、このクエリを満たすためには4つのZone Mapsのうち3つに対してIO処理が発生していることがわかるかと思います。これだけでもZone Mapsがmin, maxの値を持った結果、IO処理が3/4に減少していますね。
一方でsort tableの方を見てみましょう。当然ですがdatetimeでソートされているため、ピンポイントで特定のZone Mapsのblockに欲しいデータがあることがわかります。この例ではIO処理が1/4に減りました。
このことからもわかるように、よくwhere句でfilterするカラムにはSORTKEYを適用しましょう。
ただし、注意点としてSORTKEYは小さいテーブルに対してはあまり効果を発揮しないという点、そして指定するカラム数は4つ以下にする点に気をつけましょう。適応するカラムが多ければ多いほどSORTKEYによるIO処理削減性能は当然落ちます。
Slices
実際にクエリを実行するcompute nodeは幾つかのsliceというものを持ちます。
テーブルのrowごとのデータは各sliceに分けられています。
sliceごとに持っているプロセスは、当然そのsliceが持つデータに対してのプロセスになります。結果slice単位での並行処理が可能になっています。
データ分散
sliceへのデータの分散方法は以下の3種類が存在します。
- EVEN
- KEY
- ALL
それではここでも例を元にそれぞれのデータ分散の方式を見ていきましょう。
EVEN
ラウンドロビン方式でデータの分散を行います。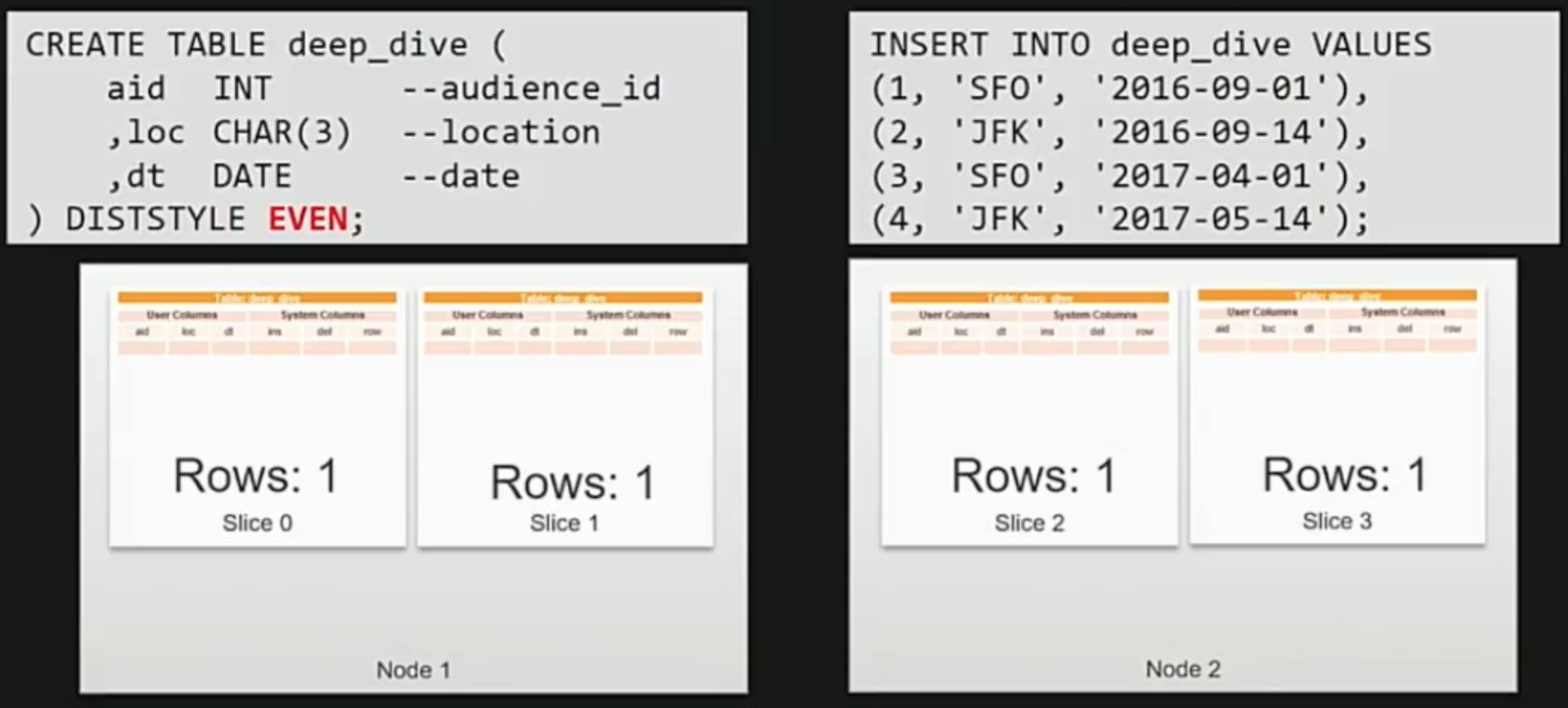
テーブル定義の最後にDISTSTYLE EVENとすれば適応されます。
上記の通り、4つのデータがひとつずつslice0~3に入っているのがわかるかと思います。
この方式は単純ではありますが、何も考えずとりあえず分散しているイメージですね。
KEY その1
KEYの分散方式では指定されたカラムのハッシュ値でデータ分散を行います。
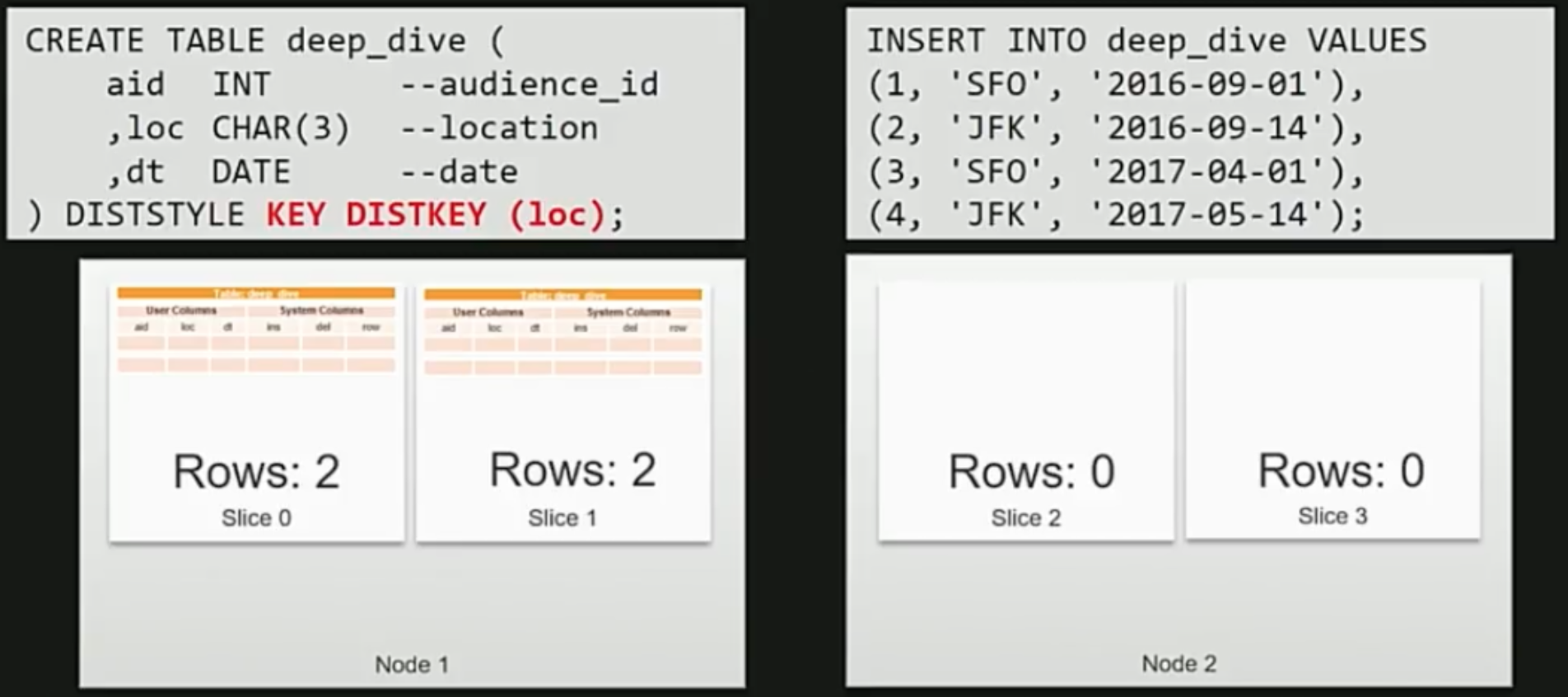
上記の例ではKEYをlocationにしているため、SFOかJFKの2種類のハッシュ値しか存在しません。
そのため、slice0と1のみにデータが集中してしまいます。
KEY その2
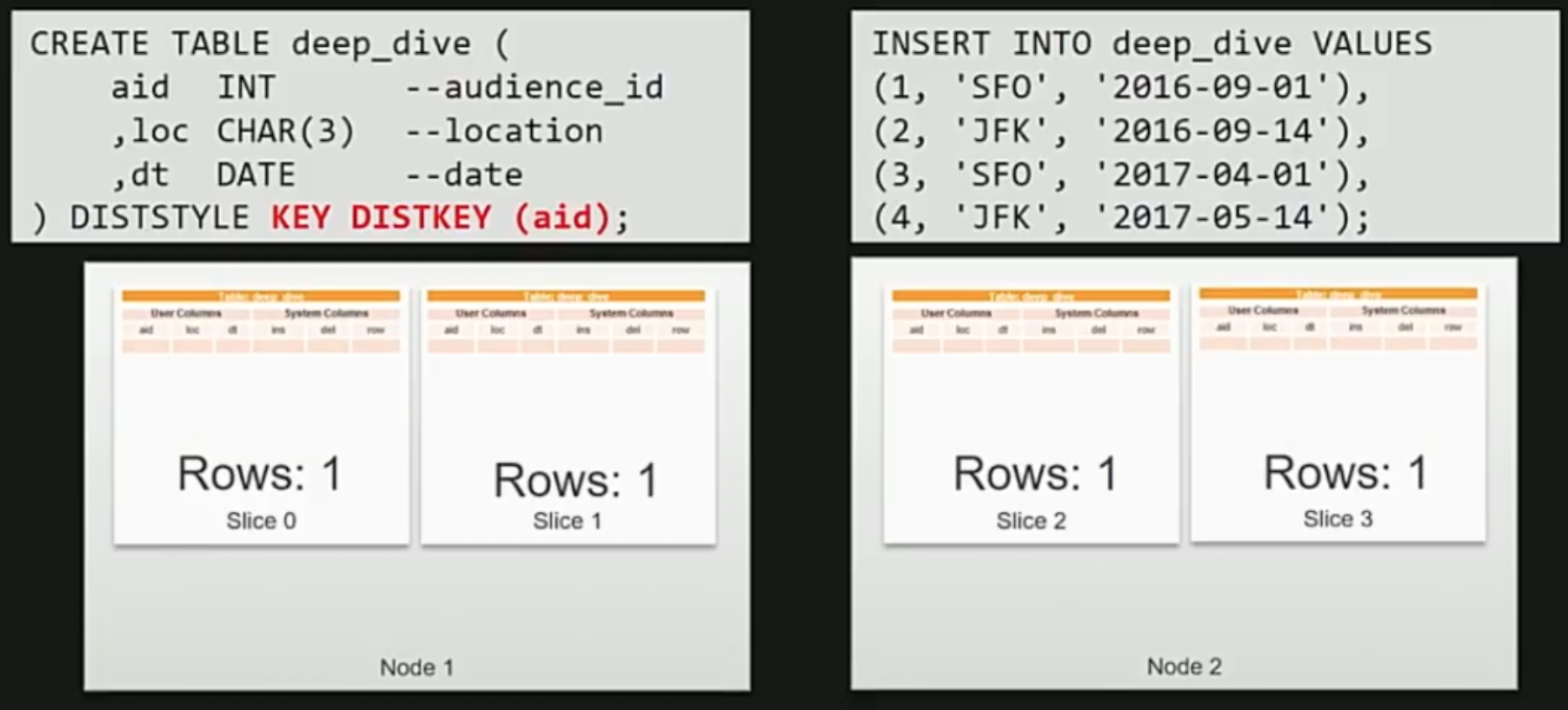
次はKEYをaudience idにした場合です。
この場合、idは一意に決まっているため当然互いのデータは別々のsliceの中に入ります。
ALL
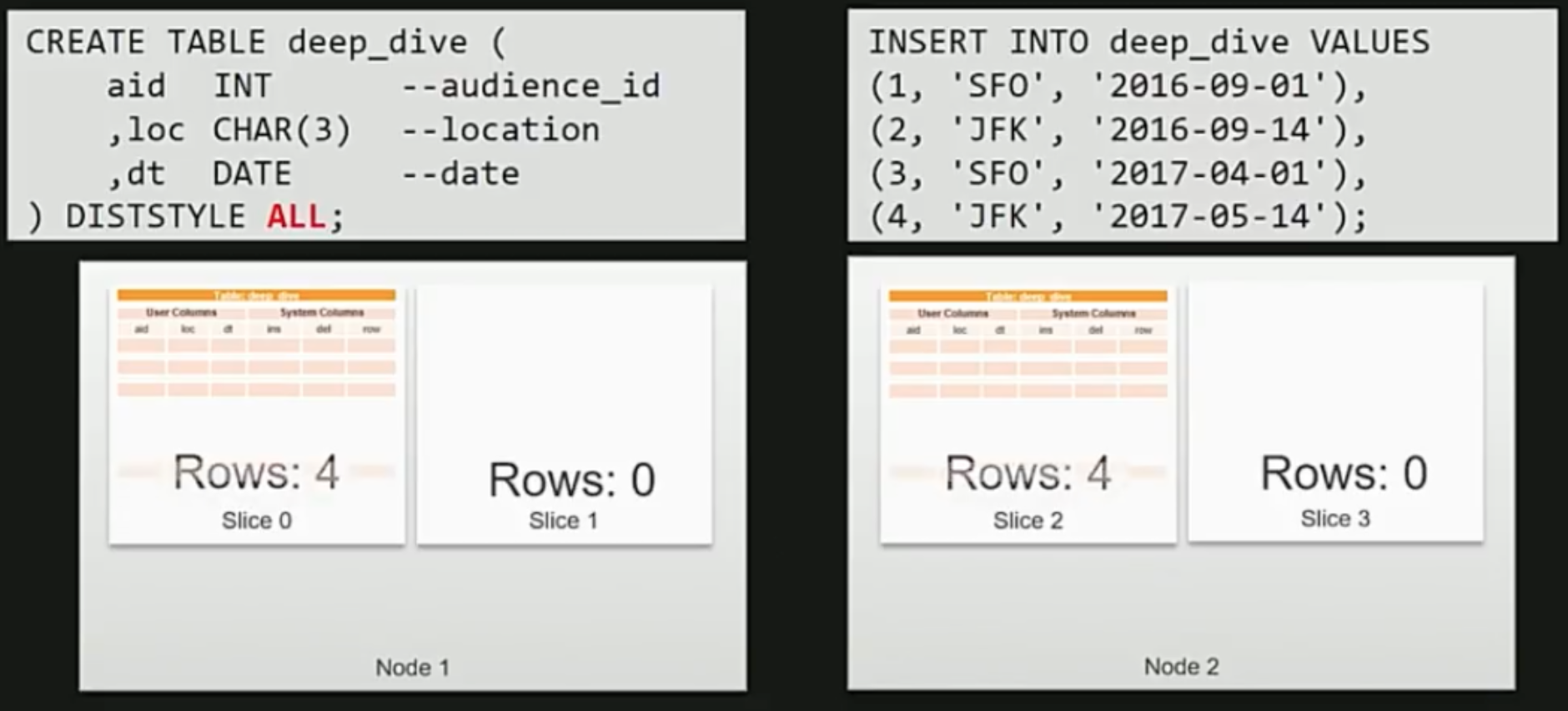
最後にALLですが、こちらは名前の通り、全てのデータを各compute nodeの1つめのsliceに格納する方式になります。
どの分散方式を使うべきか
以上つらつらと3つの分散方式について説明させて頂きましたが、ではどんな時にどの分散方式を使用するとよいでしょうか。
KEY
- 大きなテーブルどうしのJOIN
- INSERT INTO SELECTをよく使う場合
- GROUP BYをよく使う場合
KEY分散方式ではハッシュ値を元にするため、基本的に同じカラムの値でJOINすることに長けています。
同様に、INSERT INTO SELECTもGROUP BYもハッシュ値を元に行える為、高速です。
ただし、例にも挙げたとおり、KEY分散方式は指定するカラムをどれにするかが非常に重要になってきます。指定するカラムを間違えれば分散したデータ量に差が出てきてしまうからです。その点は注意しましょう。
ALL
- ファクトテーブルとディメンションテーブルのJOIN
- 小さなテーブルのディスク使用量の削減
- 3M rows以下のサイズのディメンションテーブル
ALLでは結局のところ全てのデータが同じsliceに格納されいるため、外部キーでJOINしなければならないファクトデーブルとディメンションテーブルでの結合が効率よく行えます。
また、比較的小さなデータ量のテーブルに関しては一つのsliceで完結するため速いです。
EVEN
- KEY方式、ALL方式のどちらにも当てはまらない場合
- どの方式を採用すればいいかわからない場合
実際のところ、EVEN方式でも十分なパフォーマンスが出るらしいので、最適な分散方式がわからなければ無理に特殊なKEYやALLといった方式を使う必要はないかもしれません。
もし既にデータ分散を行っているのであればちゃんと意図した分散ができているかどうかの確認を行うこともとても大切です。

上記のような例のクエリを流すことで最もデータが多いsliceと最もデータが少ないsliceのデータ量の割合を見ることができます。
KEY分散方式の場合、割合が1であることがもちろんベストですが、もしこの値が2や3だったりする場合にはKEYとして指定するカラムを今一度再検討し直してみましょう。
S3からのファイルのCOPY
Redshiftを使用している方の多くがS3にあるファイルをRedshiftへCOPYしているかと思います。
その時、当たり前ですが複数のcompute nodeに対してCOPYしたい対象のファイルが1つだけですと
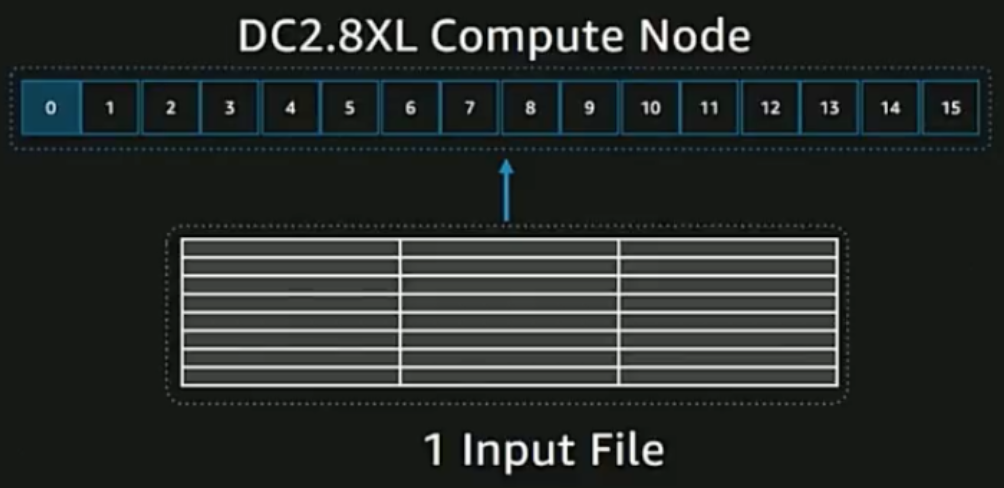
一つのノードのみが仕事をして他のノードはidle状態になります。せっかくある他のノードがもったいないですね。
なので、単純ですが、このような場合にはCOPYするファイルをcompute node数分に分割してみましょう。

そうすればCOPY速度が劇的に上がります。
ファイル分割の目安としてはgzipにした時に1MBから1GBぐらいになるのが良いそうです。
また、redshiftはCOPYの際にJSONなどのファイルフォーマットにも対応していますが、できれば単純な文字のデリミタ(例えばCSVとかTSVとか)の方がより速くCOPYすることができます。
Redshift Spectrum
ここで少しRedshift Spectrumについて触れておきますが、S3のファイルをわざわざCOPYしなくて済むから使おう。といった単純な考え方だけで使用するのはやめておきましょう。
Redshift Spectrumを使用するならば
- ELTよりもクエリを回す際のクラスタを節約したい時
- COPYするよりもデータをfilterしてパフォーマンスが向上する時
にしましょう。
Redshift Spectrumはデータスキャンに対して課金が発生するので、別クエリなのに同じファイルが対象になってしまうと、そのファイルに対して複数回データスキャンをかけるので非効率的ですし、お金ももったいないです。
使用する際には、しっかりと使う理由を持って使いましょう。
データ挿入
場合によってはRedshiftのすでにあるテーブルに対してデータの挿入を行う場合があるかもしれません。
ここで気をつけてほしいのが、前述したblockはイミュータブルである、ということです。
つまりデータの挿入は内部的には、新たなblockの作成、古いblockからのデータのコピー、そして新たなデータの挿入が行われるということです。
小さなデータを挿入するのと、100K rows以下のデータを挿入するのとではあまりコスト的には変わらないので、可能であれば挿入したいデータをまとめた上で挿入しましょう。
また、もう一つblockがイミュータブルであることで気をつけなければいけない点として、データの削除を行う場合があります。
UPDATEやDELETEそして、Redshiftの標準コマンドとしてはありませんがUPSERT(結局これはDELETEしてINSERTなので)などで発生する削除はblockがイミュータブルである結果、全て論理削除となります。
残念なことにRedshiftは自分で解放されるスペースを取り戻して再利用することはないので、放っておくとパフォーマンスが悪化します。その為、UPDATEやDELETE、 UPSERTをしている場合には、定期的にVACUUMやDEEP COPYなどで物理削除を行いましょう。
まとめ
以上、沢山書かせて頂きましたが、要点をまとめます
- 全てのテーブルには積極的に圧縮をかける
- よく使用するカラムに対してSORTKEYを適用する
- 状況に応じて適切なデータ分散を行う
- ノード数分にCOPYするファイルを分割する
- blockがイミュータブルであるため、データの挿入や削除には注意する
以上、まとめでした。
最後になりましたが、新卒の何も知らないこんなやつにre:Inventの参加を譲って下さったDynalystとアドテクスタジオの皆さんに感謝です。
この記事が皆さんにとってRedshiftを更に快適に使うきっかけになりますと幸いです。