
こんにちは。
アドテクスタジオ Central Infrastructure Agency の青山真也 (@amsy810) です。
アドテクスタジオでは「AI Lab」と呼ばれる、機械学習、計量経済学、コンピュータビジョン、自然言語処理、HAI/HRIなどを専門とする研究者がアドテクに関する技術の研究・開発を行う組織があります。 https://www.cyberagent.co.jp/techinfo/labo/ai/

GPU を用いた研究も積極的に進めており、TensorFlow、Keras、PyTorch などを利用して GPU を用いた画像解析・クリエイティブの自動生成・大規模テキストデータ処理などを行っています。 GPU では画像との相性がよく、特に画像解析やクリエイティブ周りでの活用は顕著な性能差が現れます。 他にも大規模テキストデータ処理の場合には、Web 上のメディアのテキストについて文字レベルや単語レベルの埋め込みを獲得したり、カテゴリ分類するモデルの学習を可能にしています。 マルチ GPU 構成やマルチマシン構成での分散学習を用いることで、数百万ページ以上の規模のデータでモデルのパラメータ探索を行うことを実現しています。
NVIDIA 社が用意している NVIDIA Docker を利用することで研究開発の環境をすぐに用意することが可能ですが、NVIDIA Docker 単体での利用は GPU リソースのスケジューリングやジョブスケジューリング、運用面に課題があると考えています。
そこで Kubernetes と NVIDIA Docker を連携させて、雛形となる Manifest を事前に準備しておくことで利便性を高めることを検討しました。
要求環境と検証環境
現時点の NVIDIA Docker の最新である nvidia-docker の version 2 を使います。
nvidia-docker2 の要求環境は下記の通りです。
- GNU/Linux x86_64 with kernel version > 3.10
- Docker >= 1.12
- NVIDIA GPU with Architecture > Fermi (2.1)
- NVIDIA drivers ~= 361.93 (untested on older versions)
Kubernetes 1.8 以降、Device Plugins のサポートが入った他、GPU Kubernetes の成熟度も上がってきて利用がしやすくなりました。
今回弊社では下記の環境で検証を行いました。
- Kubernetes: 1.9.2
- Docker: 17.12.0-ce
- nvidia-docker: 2.0.2+docker17.12.0-1
- nvidia-driver: 390.25
- GPU: GeForce 1080 Ti(1 ノードにつき 4 枚)
Kubernetes の Node は下記の 2 種類で構築しました。
- 1 台目
- OS: Ubuntu 17.10 artiful
- Kernel: 4.13.0-32-generic
- 2 台目
- OS: Ubuntu 16.04.3 xenial
- Kernel: 4.4.0-112-generic
Kubernetes Master は弊社で使用している AKE (Adtech Container Engine) で構築し、上記の Node を手動で cluster に組み込みました。
手軽に Kubernetes の環境を作ることができるとこういう検証の時に便利ですね。

GPU を利用可能な Kubernetes Node の構築
GPU が利用可能な Kubernetes Node を構築するには下記の 5 Step を行って下さい。
- Docker CE のインストール
- NVIDIA Driver のインストール
- nvidia-docker2 のインストール
- kubelet の feature-gates DevicePlugins の有効化
- DaemonSet nvidia-device-plugin の起動
Docker CE のインストール
Docker CE をインストールします。 Edge は利用できないようなので、Stable を使うようにして下さい。 以前のバージョンの Docker が入っている場合は削除します。
sudo apt-get remove docker docker-engine docker.io
sudo apt-get update
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt-get update
sudo apt-get install docker-ce
NVIDIA Driver のインストール
NVIDIA のドライバをインストールします。 参考: http://www.nvidia.com/object/unix.html
sh NVIDIA-Linux-x86_64-390.25.run
nvidia-docker2 のインストール
nvidia-docker2 をインストールします。古いバージョン (v1) の nvidia-docker が入っている場合には事前に削除します。
参考: https://github.com/NVIDIA/nvidia-docker
# 既存のGPU コンテナの削除
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
# nvidia-docker v1 の削除
sudo apt-get purge -y nvidia-docker
# nvidia-docker リポジトリの追加 (Ubuntu 17.10 でも動作しました)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
# nvidia-docker v2 のインストール
sudo apt-get install -y nvidia-docker2
Docker の設定を下記のように変更し、runc から nvidia-container-runtime を利用するように default runtime の設定を行います。
# Docker daemon の設定確認
cat /etc/docker/daemon.json
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
# Docker daemon の設定のリロード
sudo pkill -SIGHUP dockerd
kubelet の feature-gates DevicePlugins の有効化
GPU を内包したノードで起動する kubelet の起動オプションに Device Plugins を有効化する feature-gate を追加します。 DevicePlugins 機能が有効化することにより、次に起動する nvidia-device-plugin によって GPU リソースを認識することが可能になります。
--feature-gates=DevicePlugins=true
DaemonSet nvidia-device-plugin の起動
ここで一度 reboot します。 弊社の環境では Docker の default runtime に nvidia を指定しても nvidia-device-plugin が正常に動作しませんでした。 恐らく driver のロード周りの影響だと思われます。
$ kubectl -n kube-system logs nvidia-device-plugin-daemonset-2zhtm
2018/02/08 11:02:02 Loading NVML
2018/02/08 11:02:02 Failed to start nvml with error: could not load NVML library.
2018/02/08 11:02:02 If this is a GPU node, did you set the docker default runtime to `nvidia`?
2018/02/08 11:02:02 You can check the prerequisites at: https://github.com/NVIDIA/k8s-device-plugin#prerequisites
2018/02/08 11:02:02 You can learn how to set the runtime at: https://github.com/NVIDIA/k8s-device-plugin#quick-start
DaemonSets で動作する nvidia-device-plugin を起動します。
KUBERNETES_VERSION=v1.9
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/${KUBERNETES_VERSION}/nvidia-device-plugin.yml
nvidia-device-plugin を起動することで、Kubernetes Node 上にある GPU リソースを検知してノードに登録を行います。 kubectl describe node すると nvidia.con/gpu がリソースとして登録されていることが確認できるかと思います。
$ kubectl describe node sandbox-003
Name: sandbox-003
Roles: node
...(省略)...
Capacity:
cpu: 12
memory: 131945888Ki
nvidia.com/gpu: 4
pods: 110
Allocatable:
cpu: 12
memory: 131843488Ki
nvidia.com/gpu: 4
pods: 110
...(省略)...
GPU Container の利用
GPU を割り当てられたコンテナを作成する場合には spec.containers[x].resources に nvidia.com/gpu を指定します。今回は nvidia-smi を使ってコア数を確認します
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpu-2-deploy
spec:
replicas: 2
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- name: gpu-container
image: nvidia/cuda
command: ["sh", "-c", "nvidia-smi; sleep 36000"]
resources:
limits:
nvidia.com/gpu: 2
実際にデプロイ後のコンテナのログを確認してみると、1 つのコンテナにつき 2 つの GPU が接続されていることが確認できます。
$ kubectl logs gpu-deploy-95f544577-mrqr6
Fri Feb 9 07:54:19 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 390.12 Driver Version: 390.12 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 108... Off | 00000000:05:00.0 Off | N/A |
| 0% 33C P8 9W / 250W | 0MiB / 11177MiB | 1% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX 108... Off | 00000000:06:00.0 Off | N/A |
| 0% 36C P8 9W / 250W | 0MiB / 11178MiB | 1% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
リソースの分割の検証
4 枚の GPU で構成されたノードが 2 台の環境を作ったため、先程の 1 コンテナ辺り 2 枚の GPU を割り当てる gpu-2-deploy のレプリカ数を 5 に変更してみましょう。
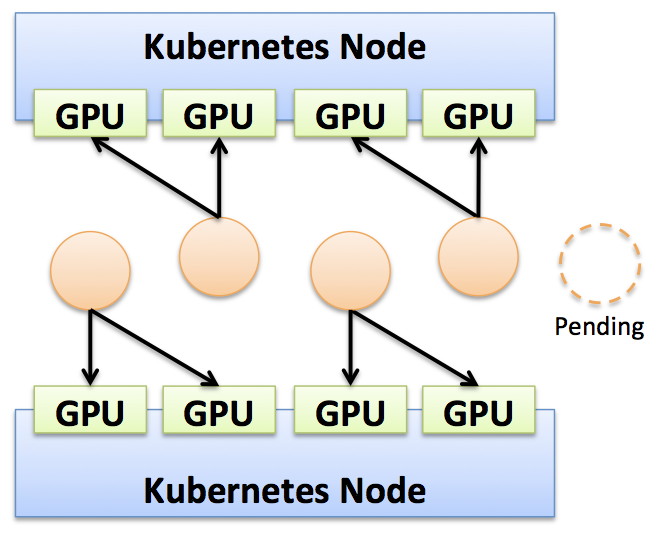
$ kubectl scale deploy gpu-deploy --replicas 5
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
gpu-deploy-95f544577-2xhr8 1/1 Running 0 26s
gpu-deploy-95f544577-4xjts 1/1 Running 0 26s
gpu-deploy-95f544577-d5c7v 0/1 Pending 0 26s
gpu-deploy-95f544577-mrqr6 1/1 Running 0 10h
gpu-deploy-95f544577-pp68t 1/1 Running 0 10h
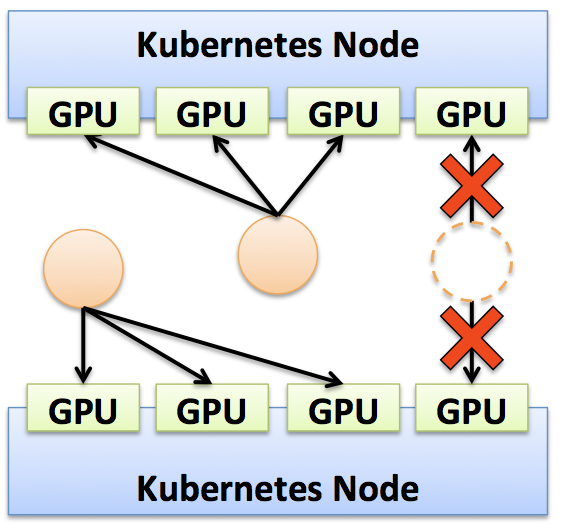
割り当て可能な GPU は 8 枚分しかないので、当然 5 台目は Pending のままとなります。 当然ながら 1 コンテナ辺りの 3 枚の GPU を割り当てるコンテナを 2 台作った後に、1 コンテナ辺り 2 枚の GPU を割り当てるコンテナも作ることはできません。
resources.requests と resources.limits の違い
Kubernetes のリソース制限には requests と limits の 2 種類が存在します。 limits の場合には、GPU がコンテナによって専有される挙動を取るため、limits だけを使う場合には確保した GPU が他のコンテナに使われるといった事態を防ぐことが可能です。
resources:
limits:
nvidia.com/gpu: 2
一方で requests の場合には少々挙動が違います。 例えば、下記のように requests:2 に設定した場合に、コンテナに割り当てられた GPU を確認してみます。
resources:
requests:
nvidia.com/gpu: 2
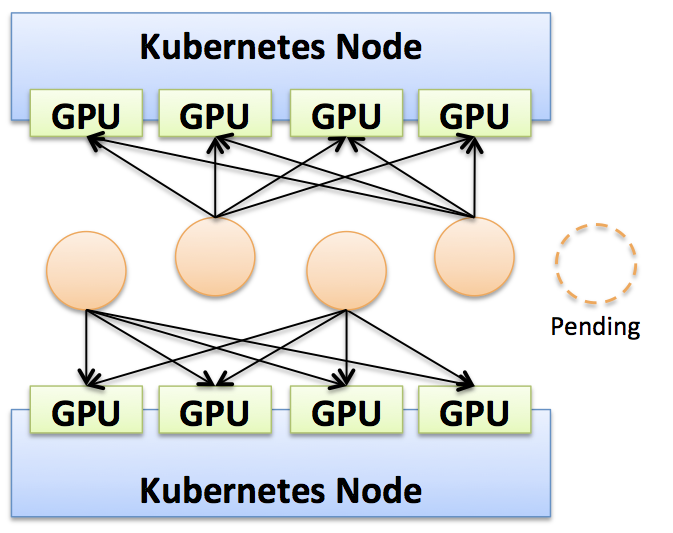
すると、コンテナ上には GPU の割り当て自体は 4 個割り当てられている状況となります。
$ kubectl logs -f gpu-req-56b544d969-5mlf4
Fri Feb 9 08:30:52 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 390.12 Driver Version: 390.12 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 108... Off | 00000000:05:00.0 Off | N/A |
| 0% 32C P8 9W / 250W | 0MiB / 11177MiB | 1% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX 108... Off | 00000000:06:00.0 Off | N/A |
| 0% 36C P8 11W / 250W | 0MiB / 11178MiB | 1% Default |
+-------------------------------+----------------------+----------------------+
| 2 GeForce GTX 108... Off | 00000000:09:00.0 Off | N/A |
| 0% 33C P8 9W / 250W | 0MiB / 11178MiB | 1% Default |
+-------------------------------+----------------------+----------------------+
| 3 GeForce GTX 108... Off | 00000000:0A:00.0 Off | N/A |
| 0% 30C P8 9W / 250W | 0MiB / 11178MiB | 1% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
requests:2 の場合にはコンテナは最大で 4 つまで起動し、一見問題ないようにも思えますが、コンテナからは GPU が 4 枚見えている状態のため、実際は競合を起こしてしまいます。 nvidia-docker 単体で検証を行った際も、ジョブの中盤以降に競合を起こしてエラーで落ちてしまったため、コンテナ上で実行される全てのプログラムが共有で使えるような仕組みを有していない場合には推奨できません。
そのため、コンテナ環境で GPU を利用する場合には、基本的には limits を使ってリソース制限を行うことが望ましいようです。
まとめ
現在アドテクスタジオでは複数台の GPU マシンを使って研究を行っています。従来環境構築に手間がかかった GPU 環境もコンテナを利用することで利便性の高いプラットフォームを提供できると考えています。例えば、Tensorflow を利用する際には gcr.io/tensorflow/tensorflow:latest-gpu などのイメージを利用することで簡単に環境を用意することができるため、今後様々なフレームワークが出てきても柔軟かつ迅速に対応することが可能です。
また、Kubernetes や Docker の GPU 対応も成熟化してきたため、検討中の方は試してみると良いかと思います。