
この記事はCyberAgent Developers Advent Calendar 2018 4日目の記事です。
アドテクスタジオのDynalystでバックエンドの開発をしている黒崎(@kuro_m88)です。2015年に新卒で入社してから3年半が経ちました。
今年は集計クラスタのランニングコストを今までの約1/4に抑えたのでその方法と、導入時に発生したトラブルを紹介してみようと思います。
Dynalystとは
Dynalystはスマホ向けの広告配信プラットフォームです。アドテク業界でいうとDSPという立場に居ます。広告の配信はオークション形式で取引が行われているのですが、Dynalystだと月間数千億リクエスト、1秒あたりだと最大数十万リクエストを受けています。開発、運用しているシステムの概要については以前発表し、ログミーさんに書き起こして頂いた記事があるのでこちらをご参照ください。
月間数千億リクエストをさばく大規模アーキテクチャの仕組み CAの広告配信システムの舞台裏
発表資料だとこちらです。
資料の後半にも書かれていますが、これだけのオークションリクエストと広告配信量があると毎時/毎日の決まった集計ですら一苦労です。量でいうとgzip圧縮した状態で1日あたり3TB以上あります。
Dynalystの集計
集計はただフィルタしたりグルーピングして値を足し合わせるわけではなく、広告主の国によってタイムゾーンや通貨単位は異なりますので集計時に変換したり、広告主の設定によってあるログと別のログの紐づけ条件が変わったりといった細かい処理が挟まります。
配信設定やタイムゾーン設定、ある日の通貨の換算レートなど、いわゆる「ファクトデータ」はAmazon Aurora(MySQL互換データベース)に、集計対象のログデータはAmazon S3(オブジェクトストレージ)に、集計結果の保存先はAmazonS3とAmazon Auroraに、というように複数の入力と複数の出力が存在します。複雑な集計の条件があったり入出力が複数存在することからDynalystではApache Sparkを用いて集計を行っています。
Apache Sparkはクラスタコンピューティングフレームワークで、処理をScalaで記述するとそれが複数台のワーカーで分散されて実行されます(pysparkというpython用のライブラリもあります)。アプリケーションコードで集計が記述できるので処理に柔軟性が持たせられますし、SQLと違ってテストフレームワークも充実しているのでテストコードも記述しやすいです。
簡単な例で実際に使われているコードではないのですが、SQLで以下のように表現される集計があるとします。
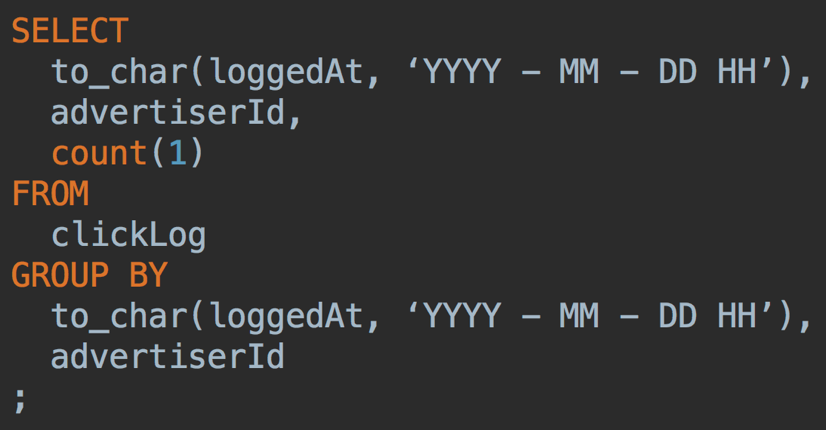
Sparkだと以下のようになります。
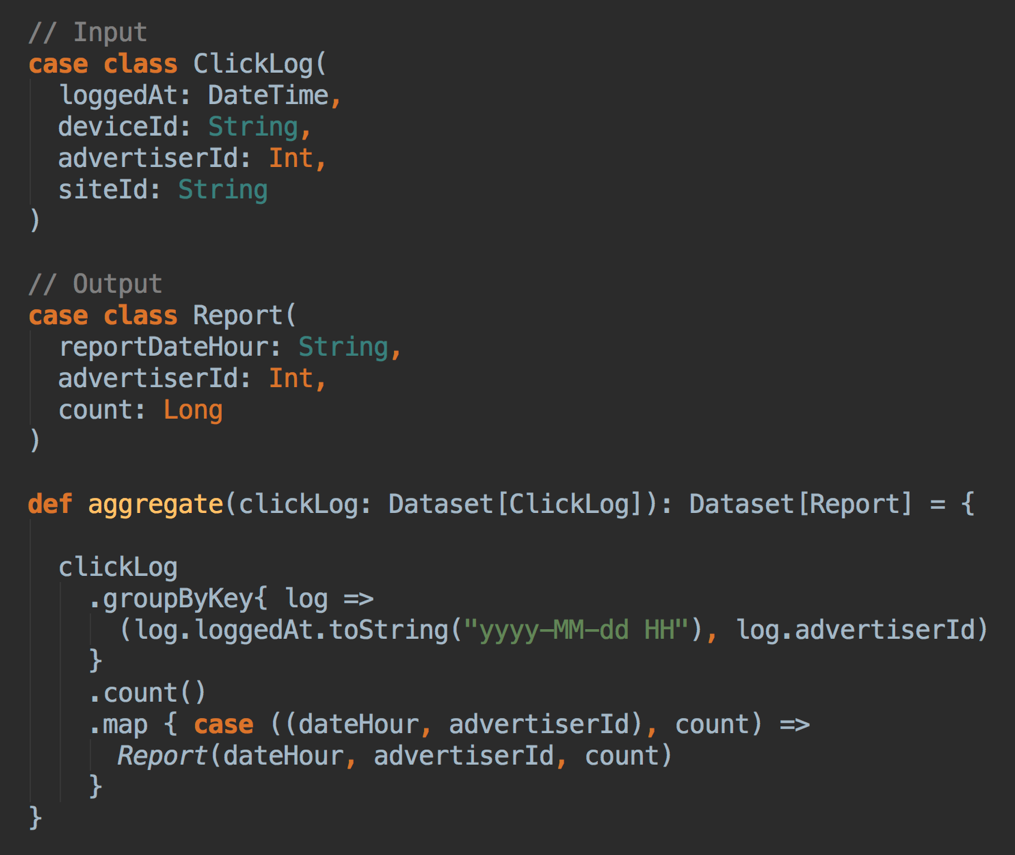
case classはデータの型の定義で、aggregateメソッドがSQLで書いていた相当の処理です。ScalaのListの操作と同じような雰囲気で書けて、これが実行時には複数のワーカーに分散されて実行されます。SQLと見比べると分かりやすいかと思います。
Datasetという型が出てきますが、これに関しては昨日ちょうど同じ部署の方が書かれていました。
SparkのDataFrame/Datasetって型安全なの?
Sparkのクラスタ自体はAmazon EMRというサービスを用いて自動で管理されています。集計ジョブごとにEMRのクラスタを起動していて、集計の種類によりますが、1クラスタあたりのサイズはCPUが200〜300コア、メモリが400〜500GBくらいです。毎日50クラスタ程度起動しています。毎日800〜1000台のサーバを作っては捨ててを繰り返していることになります。(さすがに非効率なので1日分のログをすべてメモリに乗せて集計することはしていません)
今までは集計クラスタをオンデマンドインスタンスで運用していたのですが、今年にほぼすべてスポットインスタンスを使った構成へと変更し、大幅なコスト削減に成功しました。
ログファイルはS3だけでなくAmazon Redshiftに取り込まれているので、単純なアドホック集計であればRedshiftにSQLを流していて、毎日/毎時実行されるような集計や複雑な集計はApache Sparkでテストコードとともに実装する、という使い分けをしています。
EMRでのスポットインスタンス
AWSではスポットインスタンスという仕組みがあり、オンデマンドでの起動に備えて待機しているインスタンスを格安で利用することができます。待機しているインスタンスを借りるだけなので、オンデマンドインスタンスと違ってオンデマンドインスタンスとして割り当てられた等の理由で突然シャットダウンされる可能性があります(シャットダウンされる場合は2分前に通知を受け取ることもできます)。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/using-spot-instances.html
常時稼働していないといけない用途には向きませんが、障害耐性のある環境であればこれを許容する代わりに大幅なコスト削減が見込めるというわけです。Apache SparkはRDD(Resilient Distributed Dataset)という障害耐性のあるデータモデルを採用していて、クラスタの一部のメンバーに障害が発生してもそれを検知して処理が継続できるようになっているので何かしらの理由で一部のスポットインスタンスが終了しても問題ありませんし、Amazon EMRはスポットインスタンスを使った構成の場合に、可能な場合はEMRからSparkへ停止予定のインスタンスが通知されるようになっています。そのため停止予定のインスタンスにはジョブを振らないようにして停止前にクラスタのメンバからはずしておくこともできるようになっています。
https://docs.aws.amazon.com/ja_jp/emr/latest/ReleaseGuide/emr-spark-configure.html
スポットインスタンスの価格は需要と供給のバランスによって動的に変化しますが、1年以上前までは価格変動が激しく、瞬間的にオンデマンドの価格を上回ってインスタンスが終了されることがしばしば発生していましたが、1年前よりスポット価格の価格変動がかなり穏やかに変わりました。
Amazon EC2のスポットインスタンスの価格変動が穏やかになりました
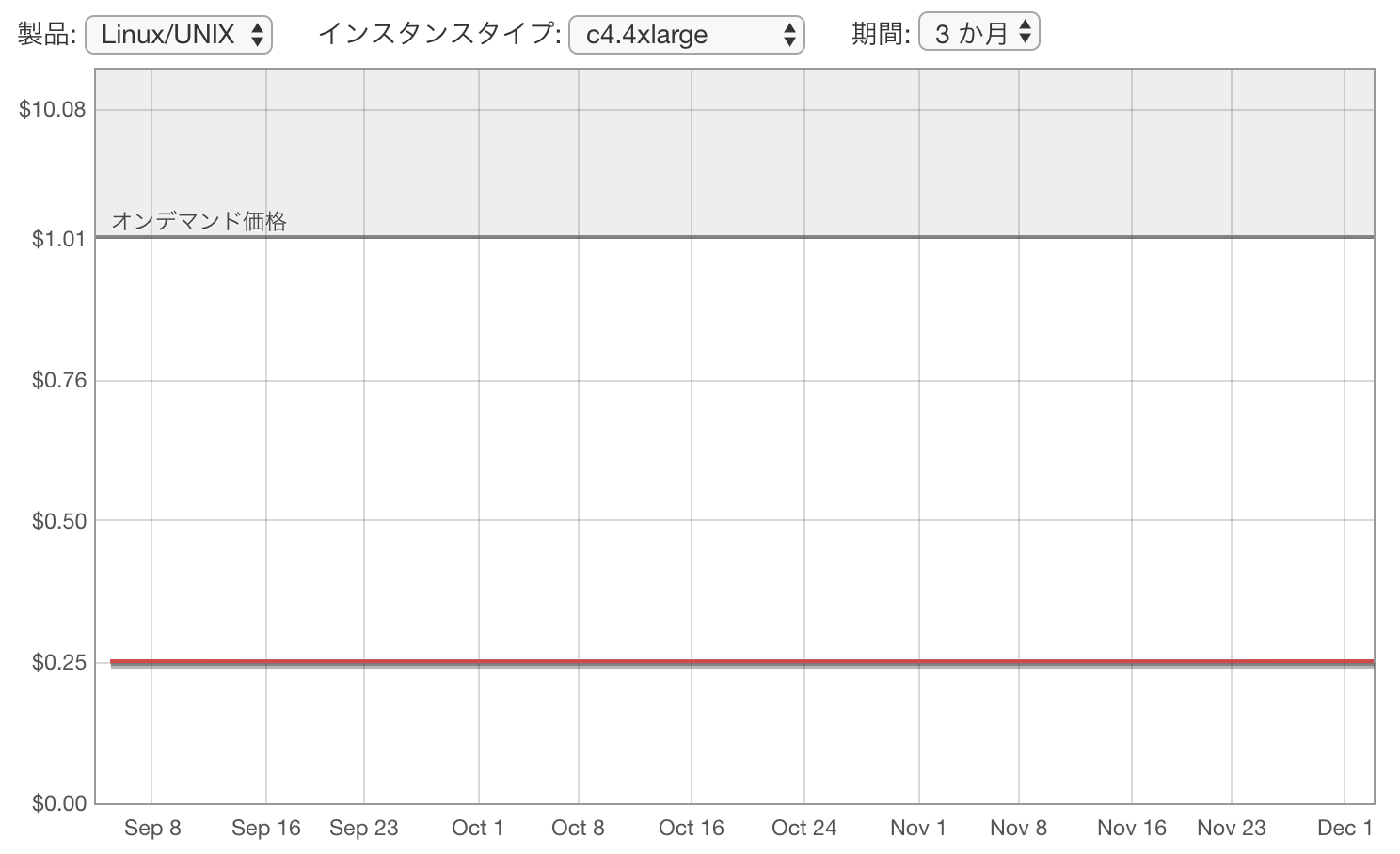
こちらは東京リージョンのc4.4xlargeインスタンスの実際の過去3ヶ月間のスポット価格の変動の履歴です。ほぼ変動がないように見えます。安定して約1/4の価格を維持していますね。今後もこの価格が続くことは保証されていませんが、他のインスタンスタイプやサイズの価格を見比べて一番コストパフォーマンスの良いインスタンスを使うのがよさそうです。
EMRのインスタンスの購入方法はいくつか種類がありますが、今回は「Instance Fleets」という機能を使いました。
https://docs.aws.amazon.com/ja_jp/emr/latest/ManagementGuide/emr-instance-purchasing-options.html
Instance Fleets
Instance Fleetsは複数種類のオンデマンドインスタンスやスポットインスタンスを組み合わせてインスタンスを買うことができます。
これにより複数のインスタンスタイプのスポットインスタンスの候補を用意し、その中で一番価格が安いインスタンスで起動しようとし、そのインスタンスの在庫がない場合はその次に安いインスタンスを起動し、設定したタイプのスポットインスタンスがどれも確保できない場合はオンデマンドインスタンスを起動する、といった設定もできます。
集計用のクラスタは処理に必要なリソースのキャパシティが確保できさえすればいいので、インスタンスタイプはそこまでこだわりはありませんし、複数のインスタンスタイプが混ざっていたとしても問題ないことが多いはずです。Instance Fleetsのおかげで在庫が枯渇しやすいインスタンスタイプをインスタンスの候補に入れていても複数種類の候補を設定しておけばリソースの確保に失敗する確率を非常に低くできます。また、リクエストするインスタンスタイプごとに要求するリソースごとに重みを設定できるので、値段以外の要素でインスタンスが確保される優先順位を制御することも可能です。
DynalystではEMRのMasterノード(1台)をオンデマンドで、Coreノード(複数台)とTaskノード(複数台)をスポットインスタンスで構成しています。Masterノードだけは終了してしまうとEMRクラスタが崩壊してしまうのでオンデマンドを使用しています。
実際の設定例
AWSのマネジメントコンソールからポチポチして起動してみて雰囲気を掴んだらaws-cliで設定をひとつひとつ指定してみてそれぞれの設定項目の意味を理解するのがおすすめです。
aws-cliのオプションの説明はこちらです。
https://docs.aws.amazon.com/cli/latest/reference/emr/create-cluster.html
Instance Fleetsの詳細な説明はドキュメントをご覧ください。
https://docs.aws.amazon.com/ja_jp/emr/latest/ManagementGuide/emr-instance-fleet.html
こちらが設定例です。MasterノードとCoreノードだけで構成する場合です。(長くてすみません)
{
"Name": "master-fleet",
"InstanceFleetType": "MASTER",
"TargetSpotCapacity": 0,
"InstanceTypeConfigs": [
{
"WeightedCapacity": 1,
"EbsConfiguration": {
"EbsOptimized": true,
"EbsBlockDeviceConfigs": [
{
"VolumeSpecification": {
"VolumeType": "gp2",
"SizeInGB": 16
},
"VolumesPerInstance": 1
}
]
},
"BidPriceAsPercentageOfOnDemandPrice": 100,
"InstanceType": "m4.xlarge"
},
{
"WeightedCapacity": 1,
"EbsConfiguration": {
"EbsOptimized": true,
"EbsBlockDeviceConfigs": [
{
"VolumeSpecification": {
"VolumeType": "gp2",
"SizeInGB": 16
},
"VolumesPerInstance": 1
}
]
},
"BidPriceAsPercentageOfOnDemandPrice": 100,
"InstanceType": "m5.xlarge"
}
],
"TargetOnDemandCapacity": 1
},
{
"Name": "core-fleet",
"InstanceFleetType": "CORE",
"LaunchSpecifications": {
"SpotSpecification": {
"TimeoutDurationMinutes": 10,
"TimeoutAction": "SWITCH_TO_ON_DEMAND"
}
},
"TargetSpotCapacity": 320,
"InstanceTypeConfigs": [
{
"WeightedCapacity": 16,
"EbsConfiguration": {
"EbsOptimized": true,
"EbsBlockDeviceConfigs": [
{
"VolumeSpecification": {
"VolumeType": "gp2",
"SizeInGB": 32
},
"VolumesPerInstance": 1
}
]
},
"BidPriceAsPercentageOfOnDemandPrice": 100,
"InstanceType": "c5.4xlarge"
},
{
"WeightedCapacity": 16,
"EbsConfiguration": {
"EbsOptimized": true,
"EbsBlockDeviceConfigs": [
{
"VolumeSpecification": {
"VolumeType": "gp2",
"SizeInGB": 32
},
"VolumesPerInstance": 1
}
]
},
"BidPriceAsPercentageOfOnDemandPrice": 100,
"InstanceType": "c4.4xlarge"
}
],
"TargetOnDemandCapacity": 0
}
JSONを読んでなんとなくどんなことができるのか察していただけるといいのですが、TargetOnDemandCapacityとTargetSpotCapacityの数値でオンデマンドインスタンスとスポットインスタンスの割合(キャパシティ)を定義します。1インスタンスあたりのキャパシティの数値はWeightedCapacityで定義します。これにより、8コアのインスタンスはCapacity 8、16コアのインスタンスはCapacity 16と定義すると必要なキャパシティが32だった時に16コアのインスタンスを2台とか、8コアのインスタンスを4台とか、16コアのインスタンス1台と8コアのインスタンス2台といった組み合わせの中からその時点で一番安くなる組み合わせが選ばれます。
Sparkの場合はCoreノードのうち一番小さいサイズのインスタンスを基準に1つのSparkのExecutor(タスクを実行するコンテナのような単位)のサイズをEMRが決定してSparkのクラスタの設定をするので、インスタンスのサイズの候補の組み合わせはc4.xlargeとc5.xlarge等できるだけ近いものを選んだ方がよいです。c5.largeとc5.xlargeを混在させることは可能なのですが、大きい方のインスタンスのリソースが十分に割り当てられず、非効率になってしまいます。
Spark自体はクラスタに異なるサイズのExecutorが居てもそれを考慮してタスクのスケジューリングをしてくれるので、EMRが適切なパラメータをSparkに対して動的に設定してくれるような改善があると嬉しいなと思っています。
運用してみて発生した問題
これはとある日のEMRクラスタのスポットインスタンスの状況です。集計中にエラーが発生してクラスタが終了してしまいました。エラーの原因を見ると全てのインスタンスが終了したためにクラスタが終了したというような内容でした。
終了してしまったクラスタに所属していたスポットインスタンスの一覧を見て終了した理由を確認しました。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/spot-bid-status.html
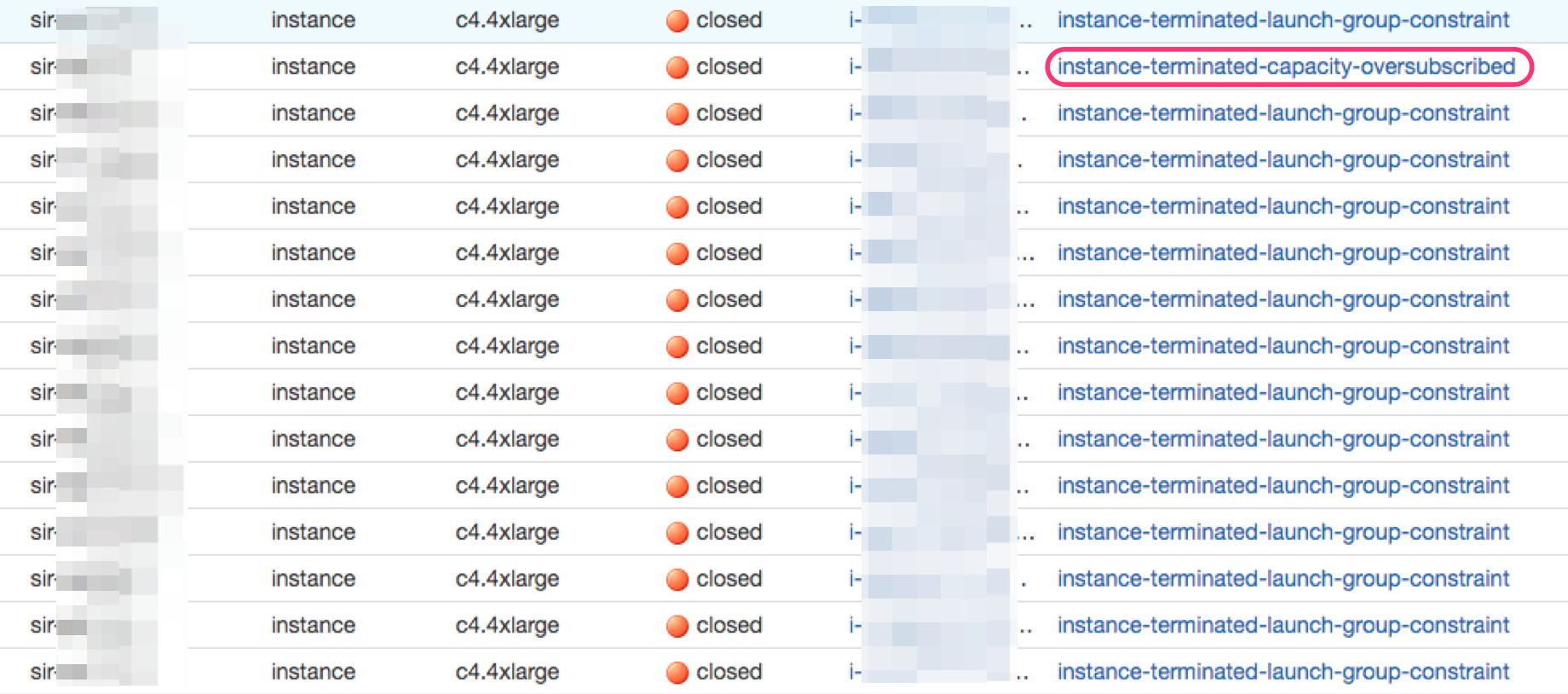
1台だけinstance-terminated-capacity-oversubscribedという理由で、その他は instance-terminated-launch-group-constraint という理由でインスタンスが終了しています。2つの理由をそれぞれ調べました。
instance-terminated-capacity-oversubscribed は「スポット料金や利用可能な容量の変化により、Amazon EC2 が スポットインスタンス を終了する必要がある場合」ということで、スポットインスタンスですのでこの挙動は想定どおりのものです。インスタンスが不足した場合はキャパシティを維持するためにEMRによって新しいインスタンスが追加されることを期待しますがそのようにはならなかったようです。
instance-terminated-launch-group-constraint は 「起動グループ内のインスタンスの 1 つ以上が終了したため、起動グループの制約条件が満たされなくなりました」ということで、スポットインスタンスが維持できなくなったためではなく、前述の1台のインスタンスが終了したことがトリガになってインスタンスが終了したように見えます。
キャパシティを維持するためにインスタンスを追加しようとするのではなく、インスタンスを終了する方向に動く挙動は想定とは異なったため、AWSのサポートの方に調査をお願いしました。
1ヶ月ほどのやりとりののち、「ある時点からドキュメントのような挙動に仕様変更がなされた」というような内容の回答がもらえました。今はドキュメントどおりの挙動になっていて、クラスタのうち1台のサーバが終了させられても新しいインスタンスを起動して補完するように動くことは確認しました。前述のとおり毎日50クラスタ程度立てていますが、それ以来クラスタの起動が失敗したことはありません。
まとめ
クラスタコンピューティングのフレームワークに耐障害性のあるものを使っていると、それを生かして安価なインスタンスを活用しコストを大幅に削減できること、Amazon EMRの場合は「Instance Fleets」という機能を使って柔軟な構成設定によって定義できることを紹介しました。
オンデマンド価格とスポット価格の差額分のお金が浮いたのでそのままシステムコストを減らすのもよいですし、クラスタのインスタンス数を増やすなどして集計を速くしてもよいと思います(2倍のサイズにしたら2倍速くなるわけではないと思うので、ケースによってはインスタンス数を増やすとコストパフォーマンスが下がります)。EC2インスタンスの課金形態が最初の10分以上は1秒単位の課金になったので思い切った構成にしやすくて助かりますね。
明日は Akio Itayaさんの番です!
https://adventar.org/calendars/2951#list-2018-12-05