
この記事は、CyberAgent Developers Advent Calendar 2018 13日目の記事です。
はじめまして、技術本部サービスリライアビリティグループ(以下、SRG)の柘植(@shotaTsuge)・岡田(@rm_rf_slant)です。
今回は、我々が組織という観点で行なっている活動について紹介したいと思います。
SRGとは
はじめに私達の組織についてお話しします。
私達が所属している技術本部のSRGは、メディア管轄(AbemaTV 関連事業以外)と呼ばれる主に、Amebaサービス(アメーバブログやアメーバピグなど)や子会社が提供しているAWAやタップル誕生、技術本部が運用しているアメーバの基盤サービスや秋葉原ラボなどのインフラ周りを横断的にサポートする部署です。
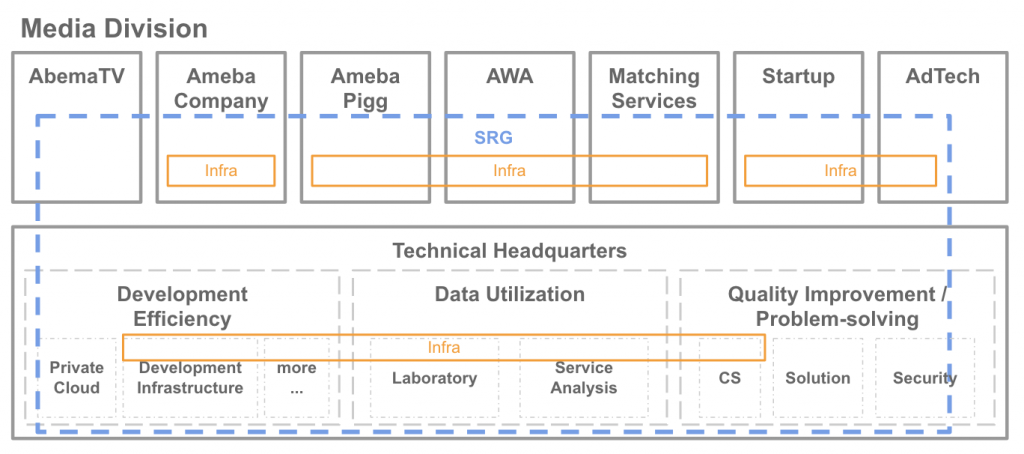
SRG が普段行なっている業務としては、新規サービス立ち上げのインフラ周りのサポートや、既存サービスの運用(インフラ構成見直しや障害対応など)、技術検証をしています。
また、開発効率化の一環として、普段の仕事で利用している開発ツールの共通化も実施しています。
組織が抱える課題について
今までは、インフラエンジニアとして様々なサービスと関わっていく中で、横断組織としてのもどかしさを感じることが多々ありました。
SRG は一時 Site Reliability Engineering を意識(2015年末)して、私達も改善に取り組もうという流れがあり、Site Reliability Engineering についての勉強会をチーム内で開催したり、Toil撲滅運動などといったこともやりました。
しかし、そのような取り組みを継続的に行う中で、様々な要因(事業/システムが200弱もある, 利用技術の多様性など)により、Site Reliability Engineer が持つようなロールの全てを SRG が行うというのは、非現実的だと感じるようになりました。
改めて、横断組織としての強みは何かを考えるようになりました。
その結果、インフラエンジニアとして、様々なサービスに関わってきたことによって得られた ”ナレッジ” を適切に提供できるということが、横断的な組織としての1つの強みなのではないかという仮説が立ちました。
現状はその強みを活かしきれていないという課題を感じており、その課題に対しての取り組みの1つとして、 Amazon Web Services(以下、AWS) が提供している AWS Well-Architected Framework をサービスに試すことにしました。
AWS Well-Architected Frameworkとは
そもそも、 AWS Well-Architected Framework(以下、AWS W-A) とは、どういったものかという人もいると思うので、簡単に説明しておきます。
AWS W-A は、AWSをユーザ向けに10年以上に提供した上で得られた経験を元に、AWSが提供してくれているシステム設計・運用の ”大局的な” 考え方とベストプラクティス集になります。
AWS W-A に関しては、以下の AWS Black Belt Online Seminar の資料がとても参考になります。
また、 AWS W-A の構成要素であるホワイトペーパーやチェックリスト(確認質問集)も、定期的に更新されています。
AWS W-A のホワイトペーパーは、以下の5つの柱で構成されています
- 運用の優秀性
- セキュリティ
- 信頼性
- パフォーマンス効率
- コスト最適化
ホワイトペーパーに関しては、公式サイトで確認することが出来ます。
先日のAWS re:Invent 2018では、 AWS W-A の構成要素の1つであるチェックリストをセルフチェックで行える AWS Well-Architected Tool も発表されました。
今回お話する内容の話では、上記のセルフチェックできるツールは、まだ発表されていなかったので、実際に担当SAの方にチェックリストを用いて、レビューしていただいた上での話になります。
AWS W-Aを試してみて
実際に AWS W-A のチェックリストを試してみた Ameba占い館SATORI や REQU などのサービスの人達からは、
- やって良かった
- 知らないことを知れた
- 出来ていないところが分かった
などのポジティブなフィードバックをもらいつつも、
- 選択式なので、項目によっては回答が難しい
- 実際に課題は分かったけど、どう改善を進めていけば良いのか
- 定期的にセルフチェックしたい
という声も多数ありました。
また、弊社ではAWS以外のプラットフォームも利用しているので、同じようなアプローチが出来ないものかとも思いました。
そこで、利用するプラットフォームに依存しない Well-Architected Framework(以下、CA W-A) を作ることにしました。
CA W-Aを作ってみた
社内でのアクセス制限の運用しやすさなどを考慮し、スプレッドシートに以下のようなチェックリストを作りました。
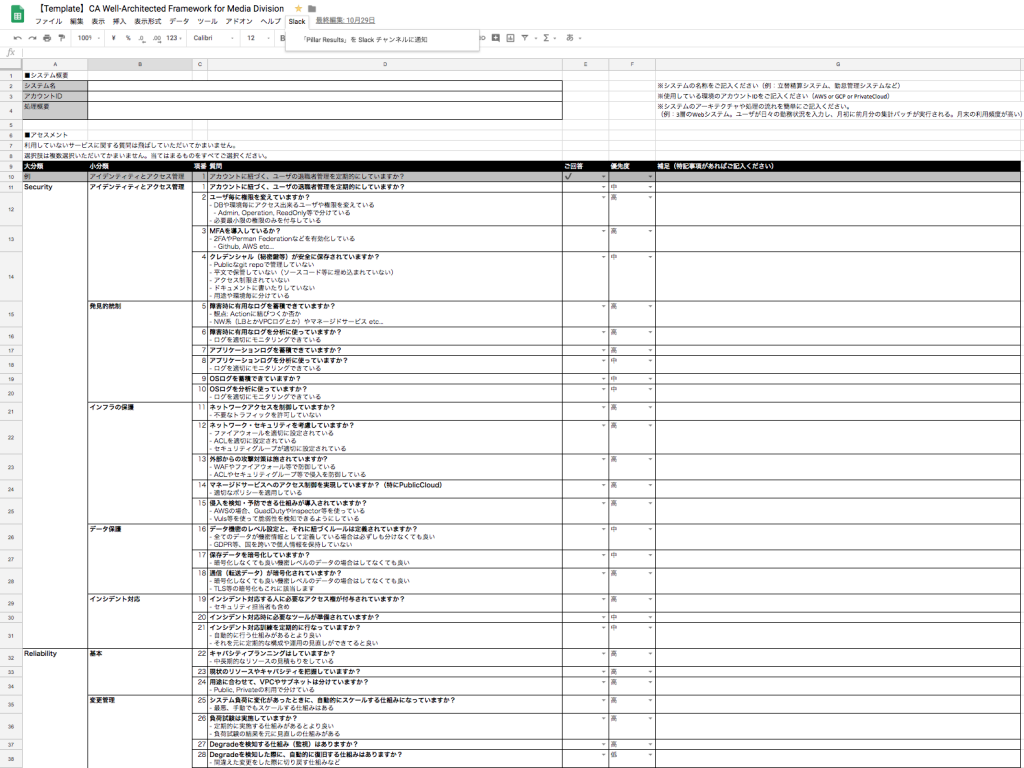
CA W-A を作成する上で、
- 特有ベンダーの質問ではない
- 実施出来てるか出来てないかを選択できるかたち
といったような AWS W-A を試してみて得られたフィードバックを元に、私達なりのアレンジを加えています。
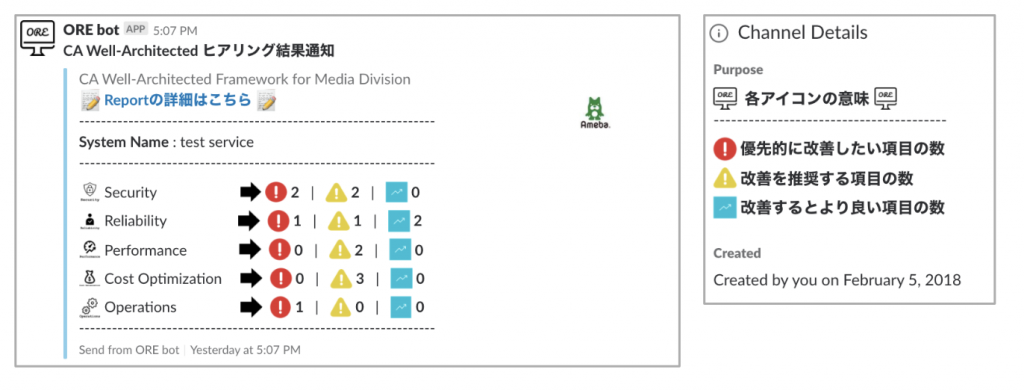
また、 Slack App(Slack API)と Google Apps Script を利用して専用の Bot を開発しました。これによって、レビュー後すぐに簡易的なレビュー結果(Pillar Results と呼んでいます)を任意の Slack チャンネルへ通知できるようになり、シームレスにサービスの担当者とレビュー結果について議論が可能になりました。
CA W-Aを試して感じたこと
CA W-A を実際に タップル誕生 や AbemaTVの広告システム で試してみて、以下のようなフィードバックが得られました。
良かったこと
- 現状の課題が可視化できる
- チームでの話のネタになる
- AWS以外でも使えるチェックリストがあるのは嬉しい
課題に感じたこと
- レビューと改善のサイクルを継続的に行える状態を作るのが難しい
- 項目によっては答えにくいところがあった
- レビューしてからのアクションが難しい
CA W-Aの改善とこれから
CA W-A を試して感じた課題の中でも、レビューと改善のサイクルを継続的に行える状態をどう作るかが、特に難しいのですが、これが一番解決すべき課題だとも感じています。
そこで、そのサイクルを継続的に回すためのフローを私達なりに考えました。

各項目について簡単に説明しますと、
- Condition Review (チェックシートを使って現状の課題の可視化)
- Review Report (レビュー結果のレポート作成)
- Discussion & Planning (レポートを元にディスカッションし、対応計画の作成)
- Improvement (対応計画を元に、改善作業実施)
また、これら項目の中で、一番重要になってくるのが、 Discussion & Planning の部分だと思っており、以下を明確にするという目的があります。
- 何が問題なのか
- 問題に対しての利害関係者は誰なのか
- 問題箇所の技術領域に詳しいのは誰なのか
- 問題を解決する上で誰が責任者になるのか
上記の中でも、何が問題なのかと責任者が明確になっていないと、この次のステップの Improvement を着手することは非常に難しいと思います。
Improvement に関しても、どうすればいいか分からないという問題もあると思いますが、そこはレビューレポートの Suggestion 部分に、私達の組織が持っているナレッジ(ベストプラクティスやモジュールの提供など)を提案するという形でのアプローチをしています。
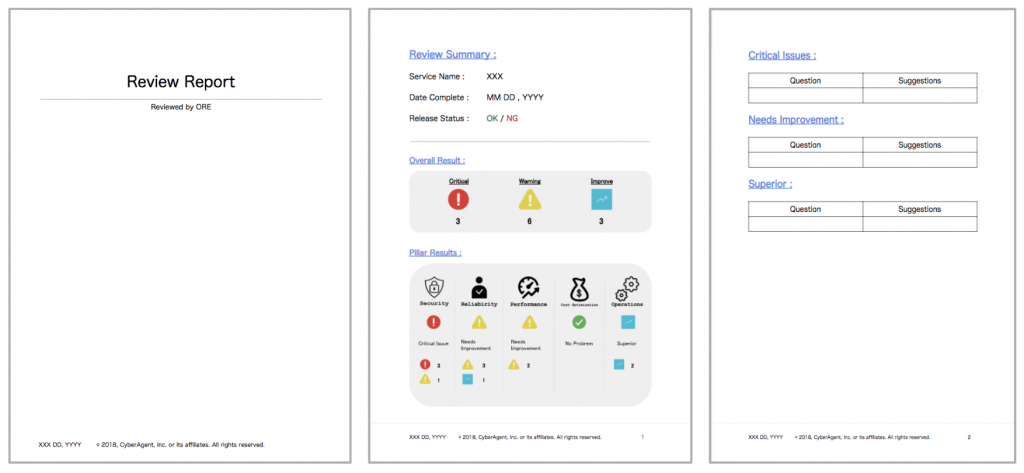
Suggestion 部分に関しては、複数サービスでの CA W-A のレビュー結果を元に、傾向的に早く提供した方が良いものから準備を進めています。
例えば SRG では Terraform のモジュールや Ansible のロールを共通化したり、オペレーション周りの自動化するためのツールなどを開発しています。
これらのツールをより多くのサービスに利用してもらうために、Suggestion として CA W-A を通してサービスに提供できるように現在取り組んでいるところです。
このように、 CA W-A を使うことにより、サービス単体への貢献以外にもメディア管轄に求められているナレッジの取得や共有といったサイクルが加速しています。
さらに、社内に散らばっているナレッジの Index 的な役割としても使うことが出来ないかとも模索しています。
また、既存サービスに比べ新規サービスの方が、こういったフローの導入がしやすいと思い、新規サービスの立ち上げフローの中にも、 CA W-A を取り組む動きを進めています。
弊社では、 AWS / GCP / プライベートクラウドなどの様々なプラットフォームを利用している組織背景により、ベンダーロックインではない CA W-A を作る経緯になりましたが、 AWS W-A は非常に素晴らしいフレームワークなので、引き続き動向をキャッチアップした上で、 CA W-A の方へも反映していきたいと考えています。
また、 AWS で完結しているサービスであれば、 AWS W-A を活用するメリットは非常にあるので、是非活用を検討してみても良いのではないかと思います。
最後に
Well-Architected Framework は、システム(サービス)の健康診断のようなものだと私達は考えています。
健康診断も同じですが、悪いところを知った上で、どう改善していくのかが大事あり、改善できる環境を作ることが重要だと思います。
なので、継続的に改善ができる環境づくりや、何に投資していくべきかの事業判断するための判断材料の1つとして、 Well-Architected Framework を活用していきたいと思っています。
また、私達は「 Organizational Reliability Engineer(ORE) 」という、今回の記事で紹介したような “組織の信頼性向上” に対してコミットしていくロールを定義し、組織課題に対して日々取り組んでいます。
今回は、その中の1つの取り組みとして Well-Architected Framework の話をしましたが、 ORE としては、以下のような組織を目指しています
- 組織全体としてのナレッジが最大化されサービスへ還元出来ている状態
- 事業レベルでのシステムリスクが共通認識できている状態
- サービス成長につながる技術戦略が作れている状態
今回シェアした内容は、私達がチャレンジしている取り組みの一部でしかないので、また機会があれば、その他の取り組みについても紹介したいと思います。