
AI事業本部のインフラ組織SIAでエンジニアをしている牧垣です。
はじめに
Jupyter Notebookは機械学習・データ解析の分野ではすっかり空気のようなインフラになりました。仮説・実験・考察のサイクルを回しやすいので、科学分野では昔から人気があります。コードと結果が可視化できるという基本機能そのものに、作業ログや手順書・使い方ドキュメントなど、他分野での需要もあります。
夢を膨らませると用途はまだまだ思いつきそうですが、つまり「複数人で同じものを見て、同じ認識をすることができる」というのがJupyter Notebookの良いところです。「あの件、どうだった?」「あ、たぶん大丈夫だと思います」といったあやしげな状態になりにくくなります。また、可視化が容易な点も長所です。百聞は一見にしかず。同じ目的を持ったツールとしては、Tableau・DOMO・LookerなどのBIツールと言われるものがあり、データ・ドリブンな仕事スタイルを推進することが目的だと思われます。
そう考えると、Jupyter Notebookは「ごりごりとプログラミング可能なマニアックなBIツール」と言ってもいいかもしれません。とはいえ、IDEではないためプログラミング環境としては貧弱であり、目的によってはPyCharmなどのほうが便利でしょう。オープンソースなので使うだけなら無料、というのも嬉しい点ですが、何らかの形でのコミュニティへの貢献が求められます。それはそれで楽しいですが。
データ解析に限らず、ちょっとした用事でも幅広くJupyter Notebookを使っていくと、大変よろしいかと思っています。あのときに何を問題とし、何を考え、何をしたのかを個人レベルでも残しておくことは後でとても役に立ちます。人事考課の時期とかに。今期何やったっけ、って忘れがちですよね。
とはいえJupyter Notebookにも使いづらい点はあります。そこをKubeflowとJupyter Enterprise Gatewayによって解決しよう、というのがこの記事の要点になります。
ここが困るよJupyter Notebook
便利なJupyter Notebookですが、使いはじめてしばらくすると、少し不便なところが見えてきます。まず、自席のPCなどのローカル環境でJupyter Notebookを使う場合:
- 長時間にわたる計算に向いていません。自席のPCをつけっぱなしにするしかありません。
- とにかく計算リソースが足りません。CPUファンもうるさいですし、メモリも足りませんし、ディスク容量はいわずもがな。ツールが特定OSに依存している場合は、それらすべてのOSが必要となります。
- こうなると「とにかく100V電源で動く一番良いやつをフルスペックで3台くらいください」といった横車な稟議を通すことになるでしょう。また、自席周辺のスペースも確保しましょう。この手法の実装には出世が必要となります。
- 準リアルタイムなNotebookの共有ができません。多くの場合、隣席とはIPを教えればHTTP通信ができるかもしれませんが、拠点が異なる場合やセキュリティソフトウェアが真面目な場合は通信できないでしょう。また、やはりサーバー側のPCを起動させ続けることになります。共有相手が多忙だと自分が帰れなくて困りますね。
また、仮想マシンや計算機を占有してもよい場合など、リモート環境での場合:
- 計算資源が固定されるので、大きめに予約・使用頻度の低いハードウェアが常時ON状態など、無駄になりがちです。リソースをコンテナなどで分離せずに複数人で共有すると、様々なニーズ(大容量メモリ、GPU、ライブラリのバージョンなど)に答えるため、単一の巨大戦艦になりがちです。Notebook見たいだけ、の場合はさらに無駄になります。
- 巨大戦艦はカッコいいですが、とにかくメンテナンスが大変です。再起動の調整をしているうちに猿が惑星を支配して半分砂に埋まった巨大なサーバーを見つける、というところまで予知して膝が崩れました。
- オンプレ用にGPUやTPUを購入しようにも、お値段がそれなりです。1つをみんなで仲良く使ってほしいですよね。大声を出して買ってもらったけれど、実際にはCPU演算で十分だった、流行っているので使ってみたかっただけだった、といったこともありえます。
- そこで、クラウド……なのですが、こちらもお金がかかります。GPUインスタンスを起動したままだけれど、実は最近使ってないなんて大声では言えない、でも解析に使ってたデータをEBSに置いたままだしモデルもレポートもそこにあるな、ってことありませんか?
- また、そもそも分散計算に不向きです。本来の目的ではなかったと思われ、Jupyter Notebookの仕組み上しかたのないことです。そういうふうにできていません。
これらの問題の大部分は、「Jupyter Notebookが動いている計算機が持つ資源を使う」==「Jupyter Notebook自体と計算資源が同一である」という問題に起因していると考えています。「Jupyterを使うということは、そういうことだ」というたった1つの冴えたやりかたもありますが、不便さを放置するわけにはいきません。
やりたいこと
さて、要望をまとめると以下のようになります:
- Notebookサーバーが簡単に構築できる
- ここで「簡単」!=「手順が少ない」であり、「簡単」==「直感的」~=「独自色が薄い」という意味です。
- Notebookサーバーの稼働自体には小さいリソースで十分なので、多少は動かしっぱなしでも問題ないでしょう。リモートで安定してJupyter Notebookサーバーを起動できれば、進捗・結果の報告、相談などを、1つのURLで共有できるようになって便利です。これで自分だけは帰れますね。
- 計算リソースをオンデマンドで簡単に取得したい
- GPUを使うときだけ切替る……といった使用感を想定しています。メモリ多めの単一インスタンスが欲しいなら、その時だけ切り替える、など。使い終わったらリソースを縮小しておいてくれると文句なしです。
- 作業を残しておくだけならローカルのJupyter Notebookで十分です。計算したいときだけ計算資源を使える、という形が実現できれば問題ありません。
- データとNotebookは単一で巨大な領域で共有され、単一の視点から読めてほしい
- 処理結果などはしかるべき場所でしかるべく共有されているべきでしょう。
- 複数Notebookでのバッチ処理、データ・パラレルな処理などでは、共有ストレージが必要です。
- ユーザーは「安心して好き勝手に使いたい」し、インフラ担当は「運用を楽にしたい」
- インフラ屋からすると「皆が好きに使ってよいサーバー」は管理したくないものランキング第1位です。2位は、結果としてやたらと高いサービスレベルを求められることになってしまった「それ」です。
- インフラおじさんは不機嫌が顔に出やすいので(?)、ユーザーは戦々恐々としながら計算リソースを使うことになります。1人がすべてを占有したら?リソース取得に制限をかける?あの部署だけは制限を緩める?果たして我々は何と戦っているのでしょうか。
- 簡単にデータパラ計算したい、長時間の計算やバッチ処理をしたい
- コンテナがデータ量に応じて並列で起動する、といった形態を想定しています。想像するだに便利そうですね。
- つい重い処理をNotebook内でそのまま始めてしまってPCが消せない、ってことありますよね。GPU使わないのにGPUインスタンスでCPU演算を始めてしまった、など。
- バッチ処理としては学習Workflowが挙げられますが、正直なところ巨大なシェルスクリプトになっていたりして、そもそもまともなWorkflowエンジンを使いたいですよね。
これらの要望を、KubeflowとJupyter Enterprise Gateway(EGW)を使って以下のようなシステムを作ることで解決を試みます。
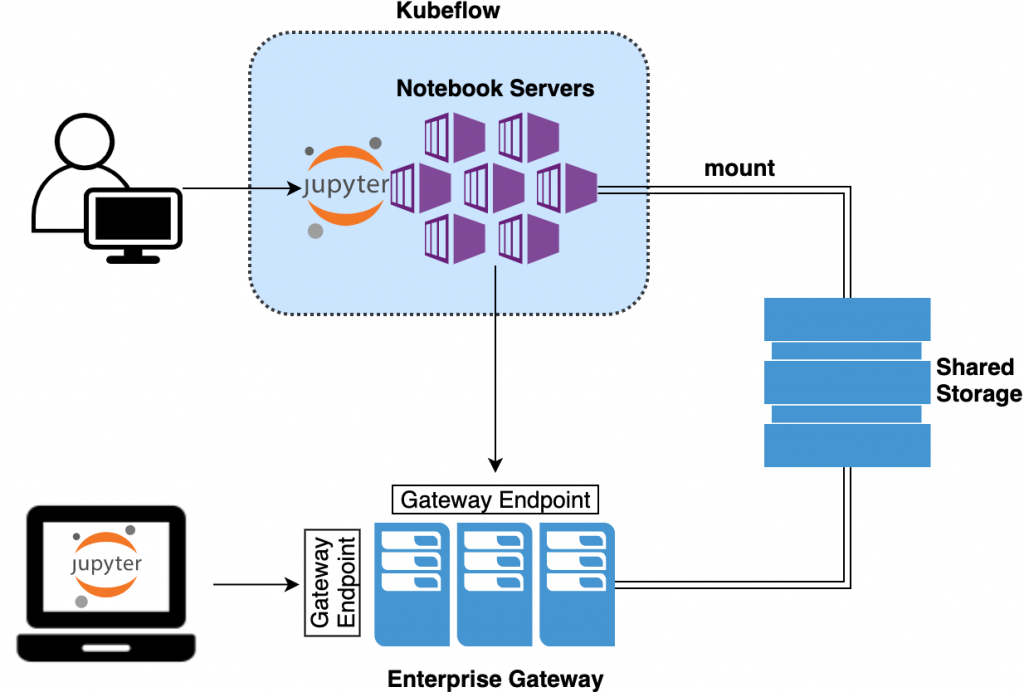
KubeflowとEGWを構築し、データはNFSで共有する、という仕組みです。Jupyter Notebookと計算基盤を分離します。計算自体はEGW内で、Jupyter Notebook自体はKubernetesクラスタ内でもローカルPC内でもよい、という形です。
Kubeflow
Kubeflowに関しては、公式サイトにある通り:
The Machine Learning Toolkit for Kubernetes
という説明がまさにその通りです。具体的には以下のような仕組みが含まれます。
Jupyter Notebookに関してはKubeflowで簡単に作成できそうです。早速試してみます。弊社にはAKEというKubernetes on OpenStackな仕組みがあります。コマンド一発で:
ake cluster create
Kubernetesクラスタが完成してしまいます。
NAME STATUS ROLES AGE VERSION makkie-cluster-ake-default-s-nlezsdp Ready node 50d v1.16.2 makkie-cluster-ake-default-s-nodhwaa Ready node 50d v1.16.2 makkie-cluster-ake-default-s-nzynhqv Ready node 50d v1.16.2 makkie-cluster-ake-m0bpumqr Ready master 50d v1.16.2
Kubeflowのデプロイは、Kubeflowのドキュメントに従います。大事なのは次の一行だけです。
kfctl apply -V -f https://raw.githubusercontent.com/kubeflow/manifests/v0.7-branch/kfdef/kfctl_k8s_istio.0.7.1.yaml
簡単!これだけでほんとうに動きました。
あとはぽちぽちと操作するだけでJupyter Notebookインスタンスを作れてしまいます。
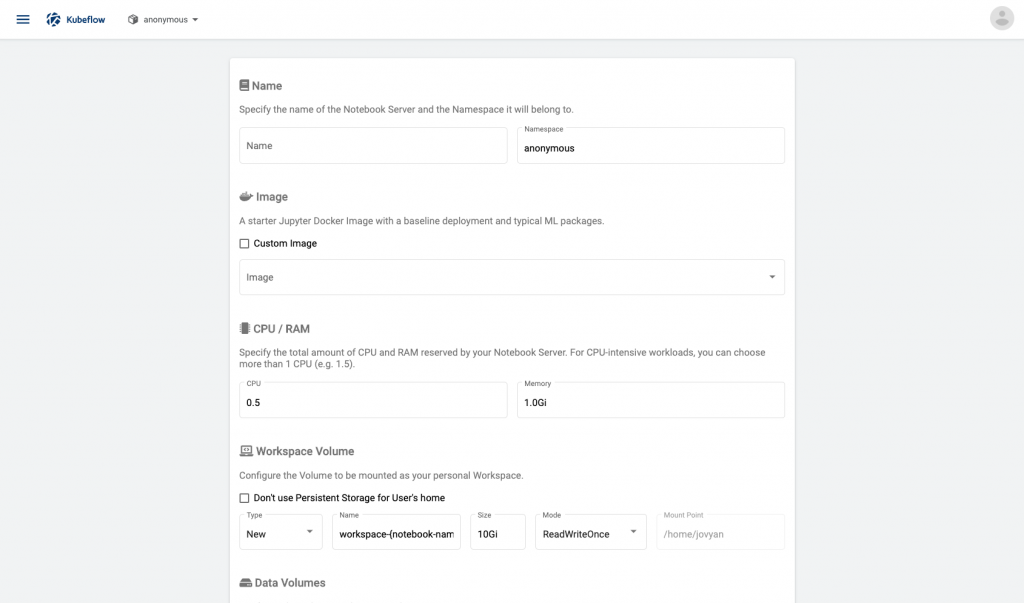
NotebookインスタンスはNotebookというカスタムリソースとして定義されています。実際には、NotebookリソースはStatefulSetを作成し、最終的にはJupyter Notebookを起動するPodが作成されることになります。
Jupyter Notebookサーバー周りの要望は、これで無事解決しました。
Jupyter Enterprise Gateway
さて本題はこれです。Jupyter Enterprise Gateway(EGW)とは、ドキュメント曰く:
Jupyter Enterprise Gateway is a pluggable framework that provides useful functionality for anyone supporting multiple users in a multi-cluster environment. Some of the core functionality it provides is better optimization of compute resources, improved multi-user support, and more granular security for your Jupyter notebook environment–making it suitable for enterprise, scientific, and academic implementations.
From a technical perspective, Jupyter Enterprise Gateway is a web server that enables the ability to launch kernels on behalf of remote notebooks. This leads to better resource management, as the web server is no longer the single location for kernel activity.
うーん、抽象的でイマイチ何を言っているのかつかめませんが、不思議とやりたいことはこれでできそうだなと感じます。
Jupyter Notebookのコード実行部分はKernelと呼ばれ、 RubyのrbenvやPythonのvirtualenvのような隔離された実行空間のようなものです。Pythonの使用例が多いですが、Ruby・Go・Cなども使えますし、他にもたくさんのKernelが公開されています。
このリストを見ていると、インフラ屋としてはAnsibleとSSHが気になります。作業ログが必要な場合や、手順書の一形態として、かなり便利に使えそうです。
さてこのKernelですが、Jupyter Notebookが起動しているところと同じところで動きます。これが「Notebookと計算資源が同一」ということの意味です。このKernelを分離してリモートKernelとして別ホストで実行し、その結果をNotebookが受け取る、といったことを実現するのが、Enterprise GatewayやKernel Gatewayと言われるものになります。従って、リモートKernel内でのpwdやdfは、リモートKernel内での状態を示します。Notebookはローカルで起動していても、リモートKernel内の状態が返ってきます。
ではEGWはどこで動かすことができるのかというと:
- Spark Standalone
- YARN Resource Manager
- IBM Spectrum Conductor
- Kubernetes
- Docker Swarm
などへのデプロイにデフォルトで対応しています。今回はKubernetesを使います。また、KernelとNotebookの分離、という機能以外にも:
- 認証
- Idle Kernelの自動削除
などが実装されています。なんとも便利そうですね。
EGWのデプロイ
別のKubernetesクラスタを作成して、そこにEGWを構築してみましょう。ドキュメントによれば、Manifestが用意されているようなので:
ake cluster create kubectl apply -f https://raw.githubusercontent.com/jupyter/enterprise_gateway/master/etc/kubernetes/enterprise-gateway.yamlnterprise-gateway.yml
これもまた簡単ですね。EGWクラスタにそれっぽいServiceが作られています:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE enterprise-gateway NodePort 10.102.15.52 8888:31695/TCP 24d
EGWへの接続
つまり、このEGWのServiceに対して、Jupyter Notebookがいわば「接続しにいく」ということになります。方法は JUPYTER_GATEWAY_URL 環境変数を設定して、Jupyterを起動すればよいです。
JUPYTER_GATEWAY_URL=http://10.8.2.69:31695 jupyter lab
私がJupyter Lab派なのは自明です。これでKernelの実行ホストがEGWクラスタになります。EGWのKernelにはSparkやTensorflowなども用意されています。後に述べるように、独自のカスタムKernelを定義することもできます。
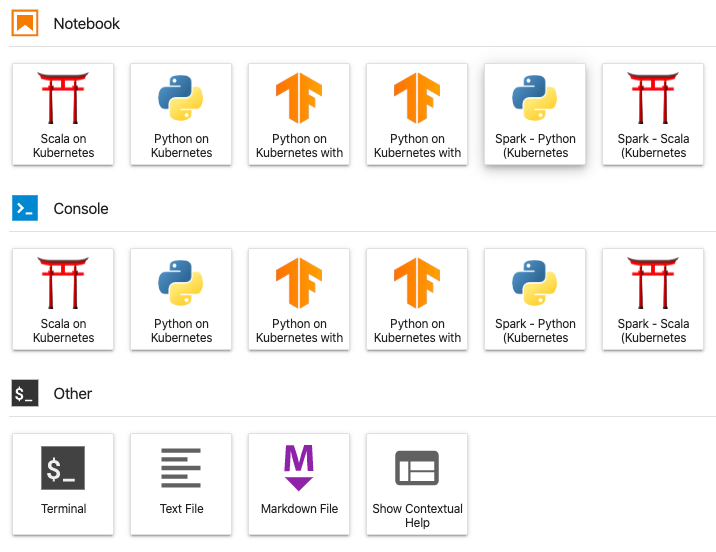
例えばNotebookのPython on Kubernetesを選択すると、KernelがPython on Kubernetesになっています。
![]()
Notebookサーバーに環境変数を設定するには、Notebookリソースの環境変数に設定します。
apiVersion: kubeflow.org/v1beta1
kind: Notebook
metadata:
name: ntbk
spec:
template:
spec:
containers:
- env:
- name: JUPYTER_GATEWAY_URL
value: "http://10.8.2.69:31695"ですが、PodDefaultというリソースを作るのがKubeflow流です。
apiVersion: kubeflow.org/v1alpha1
kind: PodDefault
metadata:
name: enable-jupyter-enterprise-gateway
spec:
desc: Enable Jupyter Enterprise Gateway
env:
- name: JUPYTER_GATEWAY_URL
value: "http://10.8.2.69:31695"
selector:
matchLabels:
enable-jupyter-enterprise-gateway: "true"PodDefaultという名前がわかりにくいですが、Notebook Pod環境のデフォルト値を設定しておくカスタムリソースと言えます。PodDefaultを作っておくと、Notebookサーバー作成画面のConfigurationsから選択できるようになります。名前が違うのでちょっとわかりにくいですね。

PodDefaultはNotebookリソースのLabelで指定しても動きます。
apiVersion: kubeflow.org/v1beta1
kind: Notebook
metadata:
labels:
enable-jupyter-enterprise-gateway: "true"EGWでJupyter NotebookとKernelを分離したことにより、Notebookを停止してもKernelは演算が終わるまで起動し続けます。計算資源の切替や長時間の処理でも、Jupyterという単一のインターフェース内で閉じているため、煩雑さがありません。EGWクラスタはKubernetesクラスタでもあるので、Kubernetesが持つクラスタ管理機能はすべて利用可能であり、運用も楽になります。
また、EGWにはIdle状態のKernel Podの自動削除(Culling)という機能があり、Idle状態が一定時間を越えると、自動的にPodが削除されます。使っていない計算資源を占有し続ける、といったことがなくなるので、とてもありがたいです。
カスタムKernel
ところで、EGWが作成するリモートKernelの実体はEGWクラスタ内のPodです。
NAME READY STATUS RESTARTS AGE guest-8c5e78f0-696a-46ab-9e24-a75da05e0ace 1/1 Running 0 3m31s
つまり、計算専用Kubernetesクラスタに、他の場所のNotebookから接続しにいく、といった感覚です。このEGWが、たとえばGPUクラスタになっていればよいわけです。科学計算向けにチューニングされたクラスタや、メモリを多く積んだクラスタ、TPUが接続されているサーバーなどでもかまいません。必要なときだけGPUクラスタを使って、終わったら他の人に開放して、無駄なくGPUを共有できます。GPU複数枚で分散、といったことにも対応可能です。実体はPodなので、Imageとメタデータ定義(kernelspec)を作れば独自のカスタムKernelを作ることもできます。実はPython 2.5を使いたい……という場合も安心ですね。コードの将来は不安ですが。
共有環境へのインストールバトル、管理者への依頼チケット、ビルド手順書、あの悪鬼の巣窟 /opt や /usr/local/opt も不要です。コンテナの本領発揮です。
NFS
単一データストアとしては、令和もNFSを使うことになります。共有ファイルシステムは運用が辛い印象がありますが、機械学習が流行り始めてさらに重要度が増してしまった印象です。Lustreなどはいたるところで稼働中であり、AWS FSx for Lustreなどのマネージドサービスもあります。イマドキではCephFSになるでしょうか。CephFSはいつか挑戦したいです。
とはいえ、弊社にも簡単に使えるNFSv4がありますので、いったんはこれを使いましょう。
NFSをNotebookから使う
まずはJupyter NotebookにNFSマウントを設定します。が、その前にPersistentVolumeClaim(PVC)を作成します。
apiVersion: v1
kind: PersistentVolume
metadata:
name: anonymous-afs-share-sia-makkie
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
nfs:
server: afs01.shared.ar.adtech.local
path: /Shared/SIA/makkieapiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: afs-share-sia-makkie
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi
volumeName: anonymous-afs-share-sia-makkie
storageClassName: ""PVCを作っておけばNotebookインスタンス作成画面で指定できるようになります。いまのところ選択式のUIではないのが残念なところですが、Volume周りのUIは絶賛開発中のようです。Manifestを書くなら:
apiVersion: kubeflow.org/v1beta1
kind: Notebook
spec:
template:
spec:
containers:
- volumeMounts:
- mountPath: /home/jovyan/work
name: afs-share-sia-makkie
volumes:
- name: afs-share-sia-makkie
persistentVolumeClaim:
claimName: afs-share-sia-makkieDeploymentを書くのとあまり変わらないですね。ところで「AFS」ってなんですかって?AI Tech Studio File Systemの頭文字です!社内ではAFSと呼ばれています。
NFSをEGWから使う
これでNotebookサーバー内からNFSを読み書きできるようになりましたが、EGWが作るリモートKernelは別クラスタ内のPodなので、リモートKernel内からはNFSが見えません。Podを起動するのはEGWであるため、これにはEGWの設定を変えることになります。EGWのManifestを変えてkubectl applyします。
apiVersion: apps/v1beta2
kind: Deployment
spec:
template:
spec:
containers:
- env:
- name: KERNEL_VOLUME_MOUNTS
value: "[{'name':'afs-shared-sia-makkie','mountPath':'/home/jovyan/work'}]"
- name: KERNEL_VOLUMES
value: "[{'name':'afs-shared-sia-makkie','persistentVolumeClaim':{'claimName':'afs-share-sia-makkie'}}]"KERNEL_VOLUME_MOUNTSとKERNEL_VOLUMESという環境変数にPVCを設定します。JSONを文字列として書き込むのは人類の可読性能には早すぎますが、今はしかたありません。以上により、リモートKernelからNFSが見えるようになります。

これで複数のNotebookやリモートのKernelから同じデータが見えるようになったため、Notebookのバッチ実行や並列計算が楽にできるようになりました。やはり共有ストレージは便利ですね……。
まとめ
Jupyter Enterprise GatewayとKubeflowによって、長時間の計算やJupyter Notebookの共有がとても楽になりました。ちょうど軽いデータ解析の仕事があったので、この仕組みを使いつつ作るということをしていました。自分で作っておいて言うのもアレですが、かなり便利です。自分が欲しいから作ったので当たり前ですが……。
残された問題達
とはいえやるべきことはまだあります。
Sessionの復旧
KernelがNotebookから分離されたことで、確かに長時間の計算はしやすくなりました。しかし、ブラウザタブを消すなどしてしまうと、プログレスバーやログなどの出力セッションを復旧することはできません。WebSocketが切れるからです。このSessionのResumeができない点は、長年Jupyter Notebookの大きな問題として扱われていました。しかし、最近になって、ついに改善する動きがでてきました。
Kernel providers by kevin-bates · Pull Request #112 · jupyter/jupyter_server
いやもうほんとうに待ち望みました。ありがとうございます。
リモートKernel自動削除後の問題
Sessionの復旧に関連して、Idle Podの自動削除機能に関する問題も言及しておかねばなりません。現在のJupyter Notebookは、リモートKernelのPodが削除されたあとも、旧Kernelに接続し続けようとしてしまう不具合があります。存在しないKernelを使おうとするので、もちろんエラーになります。原因を探るのは結構大変でしたが、分かってみれば単純なコーディングミスでした。
パッケージの異なる同名の例外クラスをExceptしていたという。次期リリースには直っているハズです。
Argo、あるいはPipeline
記事内で言及しなかったバッチ処理の問題です。KubeflowにはArgoベースのPipelineという機能があるので、権限を適切に設定すれば、実はArgoを使うことができます。データ並列な処理をする要件があったので、Argo Workflowを書いてみたりしました。
しっかりと動いてくれて便利ではあったのですが、Kubeflow PipelineはPipeline SDKを使わねばならず、もう少し簡単にWorkflowを流せるといいのになと思いました。「このセルの内容を、このManifestで、このKubernetesクラスタで実行して」という操作がNotebook上で完結してしまうといいのに、と思っていたら「素のPipeline書くの結構めんどくさいですよね」というわけで:
作ってくれている人がいるようです。いやもうほんとうにありがとうございます……。
Kubernetesはインフラの抽象化や、システムの構成要素の分類・名前付けに関して多大な貢献をしましたが、計算資源の使用手法の抽象化はしませんでした。人の欲は果てがないので、「でも本当は計算資源って、指先のように自由に使えたほうがいいなぁ」とか「計算に対してリソースが自動で付与されるのが理想なんだろうなぁ」と私は思っています。メモリをどのくらい消費するかわからないけれど、1TiB消費してしまってもうまいことアサインされて問題なく動く、という世界を作れるといいなぁと思います。