
こんにちは、AI事業本部 Dynalyst所属のデータ分析担当の金子(@coldstart_p)です。
今回はCA Tech JOBの制度を用いてインターンに参加して頂いた樋口 心さんからの寄稿記事です。
以下本文です。
こんにちは、2020年1月のTech JOBインターン生の樋口です。
AI事業本部DynalystというWeb広告の事業部に配属させていただきました。
本稿ではインターンで取り組んだレコメンドロジックの評価について紹介します。
本稿におけるレコメンドロジックとはサービスの利用ユーザに適切なコンテンツを提示するアルゴリズムを指します。
(ex. AmazonやNetflixなどのおすすめアイテムを提示するもの)
そのアルゴリズムの良し悪しをオープンデータによる実装を交えて評価しました。
また記事の後半にはインターンの感想も書きました。
こちらも合わせてご覧いただけると幸いです。
導入 ~良いレコメンドとは~
機械学習をプロダクトに実装するには、最適化する指標を選定し、導入効果を計る必要があります。
分類や回帰の問題であれば、多くの場合、推論精度を調べることで効果を計ることができます。
(ex. 広告クリック予測モデルの精度がX%になった。既存モデルよりY%向上したのでZ円の損失を防げる)
しかし、レコメンドについてはどうでしょうか?
ユーザが未来にアクションを起こすアイテムを推薦できた割合を精度とした場合、
単純に精度向上を追求すると下記のようなレコメンドができてしまうかもしれません。
- Aというマンガの1巻を読んだユーザにAの2巻,3巻,4巻,5巻,…と推薦してしまう
- あるスーパーでは多くの顧客が卵と牛乳を買う。そこで、全員に卵と牛乳を推薦してしまう
このようなレコメンドは確かにユーザに対して高い精度で推薦できていますが、
ユーザへの良い体験や、プロダクトの成長をもたらしているとは言えないでしょう。
良いレコメンドは
- 売れていない商品を推薦し、購入を促す
- ユーザが興味を引く商品を提示し、満足度を向上させる
など新たなユーザと商品のマッチングを成立させるものであると直感的に言えそうです。
では精度だけでは不十分ならば、どのような指標を用いてレコメンドを評価すればよいのでしょうか。
例えば、‘Beyond accuracy: evaluating recommender systems by coverage and serendipity’という論文には精度に加えて以下の指標を評価すると良いと記載されています。
- coverage : 何種類のアイテムを推薦できるか
- serendipity : どれだけレコメンドがポジティブなサプライズを与えるか。未知でかつ有益な情報なら高い値を示す。
このようにレコメンドは複数の観点から評価する必要があります。
そこで今回、簡単なレコメンドロジックと複数の評価指標をPythonで実装し、
オープンデータに適用してみました。
分析 ~MovieLensを複数指標で評価~
MovieLensというオープンデータに対して実験を行いました。
実験に用いたコードはgithubにて公開しているので、追実験する際に参考にしてください。
分析対象
本実験にはMovieLens 100K Datasetというデータセットを用いています。
1000人のユーザが1700の映画のうちいくつかに5段階の評価をしており、
(ユーザ、映画、評価)のペアが10万件あります。
各ユーザは必ず20本以上の映画に対して評価をおこなっています。
実装ロジック
今回実装したレコメンドロジックは、
- ユーザベースの協調フィルタリング
- アイテムベースの協調フィルタリング
です。下記に簡単にロジックについて説明いたします。
ユーザベース
似ているユーザが高評価したかつ、自分がまだ評価していない商品を推薦するロジックです。
表示例:あなたに似たユーザに基づいたおすすめ商品です
ユーザaに推薦する場合、下記のように行われます。
- ユーザ間の類似度行列を求める
- 類似度行列からユーザaと似たユーザ群を抽出する
- 似たユーザ群の類似度とユーザ群の評価を商品ごとに掛けて合計する
- 3の値が大きく、かつユーザaが未評価な商品を推薦アイテムとする
※今回はコサイン類似度を使用していますが、
ユーザ間の評価値の平均の差異が精度に悪影響を及ぼすので、別の類似度指標を使ったほうが良いです。
アイテムベース
自分が高評価した商品に似たかつ、自分がまだ評価していない商品を推薦するロジックです。
表示例:過去のあなたの嗜好に基づいたおすすめ商品です
ユーザaに推薦する場合、下記のように行われます。
- アイテム間の類似度行列を求める
- ユーザaのした全評価とアイテムの類似度を要素ごとに掛け、合計する
- 2の値が大きく、かつユーザaが未評価な商品を推薦アイテムとする
実装評価指標
coverage
ベン図:何種類のアイテムが推薦されているか
accracy
- NDCG:正解データとレコメンドのランキング順序がどれだけ一致しているか
- MRR:推薦が当たった最初のアイテムがレコメンドランキングにて何番目に位置しているか
その他
ジニ係数:アイテムの推薦頻度がどれだけ偏っているか
評価指標はこのサイトを参考にさせていただきました。
各指標の意図や読み取れることは実験結果と同時に記載いたします。
実験結果
ベン図
推薦した全アイテム数

1度でも推薦することが出来たアイテム数を示しています。
推薦した適合アイテム数
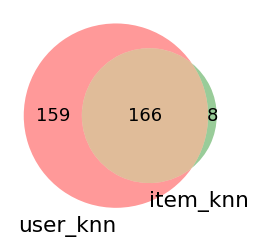
推薦し、更にテストデータに存在したアイテム数を示しています。
どちらも数が大きければ、レコメンドのバリエーションが豊富と言えます。
図からわかるようにユーザベースはアイテムベースに比べて
推薦できるアイテムが多いことがわかります。
両者の積集合が小さい(ロジックが変わると推薦アイテムの傾向も変わる)場合は、
両方のレコメンドリストを表示することも有用でしょう。
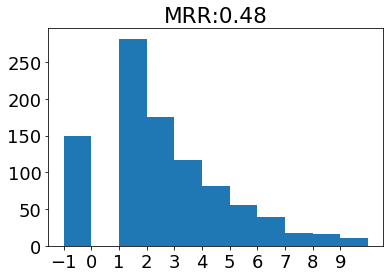
MRR
今回使用したレコメンドロジックではそれぞれ推薦度を元にランキングを出力できます。
MRRはレコメンドリストを上位から見て、最初の適合アイテムの順位の逆数を取った指標です。
1に近いほど、適合アイテムを高い順位に推薦できていることになります。
下記グラフには、適合アイテムの順位とMRRを同時に表示しています。
また−1は適合アイテムがなかったユーザを示しています。
ユーザベース
アイテムベース
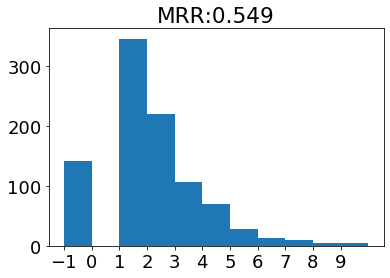
上記指標を確認すると、
アイテムベースのほうが高い順位に適合アイテムを出していることがわかります。
レコメンドの提示枠が限られている場合は、
上記のヒストグラムを確認しながら、適切な提示数を決めるとよいかと思われます。
NDCG
NDCGはレコメンドリストが正しい順位かを表す指標です。
1に近いほど、ユーザの評価値が高いアイテムを高い順位に推薦できています。
計算したところ、
ユーザベース ndcg: 0.549
アイテムベース ndcg: 0.595
となりました。
こちらもMRRと同じく精度を表す指標なので、
アイテムベースのほうが良い結果となりました。
ジニ係数
ジニ係数は各アイテムの推薦頻度の均一度を表す指標です。
均一であれば0,不均一であれば1に近づきます。
今回はどのように推薦頻度が偏っているか表すローレンツ曲線をプロットしています。
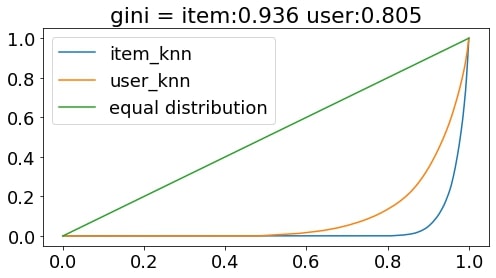
上記グラフを確認すると、
アイテムベースはユーザベースに比べかなり上位アイテムに偏って推薦していることがわかります。
不人気なアイテムの推薦頻度を上げるためには、
トレーニングデータで出現頻度の高いアイテムに何らかの重みをつける必要があると言えそうです。
実験の考察・感想
いかがだったでしょうか。
今回の実験から、ユーザベースとアイテムベースの長所短所や使い分けを考察することが出来ます。
ユーザベース
- 長所: 幅広いアイテムを推薦することができる
- 短所: 評価値の高いアイテムを高い順位に推薦できない
アイテムベース
- 長所: 評価値の高いアイテムを高い順位に推薦できている
- 短所: 特定のアイテムしか推薦することが出来ない
これらの使い分け
- 推薦アイテムの表示枠が小さい→アイテムベース
- 多くの商品を推薦したい→ユーザべース
プロダクトにおけるレコメンドの要件と照らし合わせ、
適切な指標を分析しながらレコメンドロジックを作成していただければと思います。
インターンについて
最後にTech jobインターンについて紹介したいと思います。
非常に学びの多いインターンで、特に下記のポイントが良かったです。
現場でデータ分析をする難しさを知ることができた
インターン中は上記のようにアルゴリズムの評価に取り組みましたしたが、
普段の研究やKaggleなどとは異なる様々な制約や要件があり、非常に難しかったです。
具体的には
- ネット広告は高トラフィック、低レイテンシな環境でも耐えうる実装である必要がある
- バグをリリースすると即日で数百万の損失を被る可能性がある
- ログに残っているデータと実データで母集団の差がある
- 配信ロジックやデータの変更に頑健なモデルである必要がある
などが挙げられます。
ビジネスでは実装に対して責任を持ち、他者に論理的に説明することの必要性を改めて実感しました。
僕が体感したことは、Dynalystの加藤さんの記事に詳しく書いてあります。
現場の実装フローを学べた
インターンでは、現場のデータサイエンティストの方が抱えている課題の一部を任せていただきました。
作業も社員の方と同様のフローで進め、結果をMTGで発表する機会が与えられました。
データサイエンスの課題がどのように発生し、どのようにアウトプットされていくかがリアルに体感できたのは実務型インターンの最大のメリットだったと思います。
また、Dynalystの開発は誰がどの作業をしているかがすぐにわかり、社内の知見を共有できる仕組みで運用されていて、どのようにチーム開発をするのが良いかなど大きな枠組みでのソフトウェアエンジニアリングの勉強にもなりました。
社員さんと話す機会がとにかく多かった
業務中は同部署の方にSlackやQiitaで疑問を書くとすぐに答えていただけました。
他にも、メンターの金子さんや人事の方がシャッフルランチの機会を設けてくださり、様々な社員さんとお話することが出来ました。
そこでは研究所や他部署のデータサイエンティストの方とお話でき、
自分の取り組んでいる課題についてアドバイスを頂いたり、ソフトウェアエンジニアのキャリアの歩み方なども教わることができました。
余談ですが、ヒカリエとスクランブルスクエアのランチはとってもおいしかったです笑。
おわりに
途中に国際学会や修士の中間発表練習などがあり、10日しか参加することができなかったのですが、
それでも温かく受け入れていただき本当にありがとうございました。
毎日本当に充実したインターンでした。
22卒の方にもおすすめのインターンなのでぜひ応募してみてください。
それではここまで読んでいただきありがとうございました。
