
はじめに
AI事業本部Dynalyst所属エンジニアの加藤です。
データ分析を担当しており、Amazon Redshiftにクエリを投げたりPythonで分析したりしています。
私の所属するDynalystではオンライン広告配信システムを設計しており、DSPとしてリターゲティング広告を配信しています。オンライン広告配信システムの仕組みとDynalystの立ち位置については以前こちらのブログに書きましたので、ぜひご覧ください。
Dynalystでは日々大量の入札リクエストを捌いており、それに対するレスポンスや、広告のクリック履歴などがログとして蓄積されています。そのデータ量は膨大ですので、分析する際には基本的にログの期間を絞って集計します。ところが稀に、指定した期間が長すぎたり、そもそも期間を指定していないクエリを流してしまう事故が発生します。すぐに気づいてクエリをキャンセルすれば問題ないのですが、不要なクエリが長時間気づかれないまま流れ続けたケースも過去に存在しました。
このような背景から、長時間Running状態になっているクエリを検知して、Slackに通知することで事故を防ぎたいと考えました。Redshiftではクエリモニタリングルールを設定することにより指定時間以上かかっているクエリを自動で中止することが可能ですが(参考: WLM クエリモニタリングルール | AWS)、分析内容によっては長時間かかることを許容する場合もあることから、今回は中止はせずにSlackに通知する方向で実装を進めます。また、今回はPythonを用いた実装について説明します。
長時間Running状態のクエリを検知するクエリを作成する
Redshiftでの実行中のクエリについての情報はSVV_QUERY_INFLIGHTビューに格納されています。
(スーパーユーザーはすべてのクエリを確認できますが、通常のユーザーは自分のクエリしか確認できないので、スーパーユーザーで接続することをお勧めします。)
SVV_QUERY_INFLIGHTでは同じクエリのテキストが200文字刻みで別の行に格納されていますので、クエリテキストを取得するためにはシーケンス番号で集計して結合する処理が必要になります。Slackに通知する際にユーザー名や実行開始時間も通知内容に含めたいことを考慮し、N分以上Running状態のクエリを検知するクエリを次のように記述しました。
SELECT usename,
pid,
starttime + INTERVAL '9 hour' AS starttime_jst,
1.0 * date_diff('second', starttime_jst, localtimestamp + INTERVAL '9 hour') / 60 AS elapsed_minutes,
LISTAGG(RTRIM(text)) WITHIN GROUP (ORDER BY sequence) AS query_stmt
FROM SVV_QUERY_INFLIGHT inflight
LEFT JOIN pg_user
ON inflight.userid = pg_user.usesysid
WHERE elapsed_minutes > N
AND suspended = 0
GROUP BY usename,
pid,
query,
starttime_jst
ORDER BY starttime_jst実行中のクエリについて以下のような結果が得られます。
| usename | pid | starttime_jst | elapsed_minutes | query_stmt |
|---|---|---|---|---|
| admin | 1111 | 2020-01-01 12:00:00 | 61.2345 | SELECT * FROM hoge_log |
| guest | 2222 | 2020-01-01 13:00:00 | 1.2345 | SELECT * FROM fuga_log |
あとは、得られたクエリをSlackに通知すれば完成です。
Pythonを用いてRedshiftにクエリを投げ、得られた結果についてSlackに通知する
Pythonからwebhookを利用してSlackに投稿します。Redshiftへの接続には psycopg2 を利用しました。
今回はPythonコードを定期実行することを想定して作成しました。その場合、指定時間以上経過しているクエリについて通知するという条件だけだと、クエリがキャンセルされない場合に何度も通知されてしまいます。一度検知したクエリのpidを別ファイルに保持してもいいのですが、実行方法の関係上1ファイルで完結したいという動機もありました。そこで、指定時間の2倍以上かかっているクエリは検知対象から外すという形で実装しました。これを指定時間より早い周期で定期実行することで、漏れなくクエリを検知できます。
全体としては以下のようなコードになりました。
import argparse
import psycopg2
import os
import pandas as pd
import requests, json
description = """
Post alerts to slack for queries running in Redshift that take longer than [minutes] minutes.
"""
REDSHIFT_HOST = "hogehoge.redshift.amazonaws.com"
REDSHIFT_PORT = 1234
REDSHIFT_USER = "user_name"
REDSHIFT_PASSWORD = "PASS"
REDSHIFT_DB = "database"
parser = argparse.ArgumentParser(description=description)
parser.add_argument("-m", "--minutes", type=int, help="What is the threshold (minutes) for posting queries to slack.")
args = parser.parse_args()
# query_stmtは改行が"\n"で表された1行の文字列なので、"\n"を実際の改行に変換します。
def replace_newline(txt):
return txt.replace("\\n", "\n")
sql = f"""
SELECT usename,
pid,
starttime + INTERVAL '9 hour' AS starttime_jst,
1.0 * date_diff('second', starttime_jst, localtimestamp + INTERVAL '9 hour') / 60 AS elapsed_minutes,
LISTAGG(RTRIM(text)) WITHIN GROUP (ORDER BY sequence) AS query_stmt
FROM SVV_QUERY_INFLIGHT inflight
LEFT JOIN pg_user
ON inflight.userid = pg_user.usesysid
WHERE elapsed_minutes BETWEEN {args.minutes} AND 2.0 * {args.minutes}
AND suspended = 0
GROUP BY usename,
pid,
query,
starttime_jst
ORDER BY starttime_jst
"""
connection = psycopg2.connect(host = REDSHIFT_HOST, port = REDSHIFT_PORT, user = REDSHIFT_USER, password = REDSHIFT_PASSWORD, dbname = REDSHIFT_DB)
connection.get_backend_pid()
query_df = pd.read_sql(sql=sql, con=connection)
connection.close()
slack_txt = ""
for i, row in query_df.iterrows():
slack_txt += f"""{args.minutes}分以上かかっているクエリを検知しました。
*pid:* {row.pid}
*user_name:* {row.usename.replace(' ', '')}
*start_time:* {str(row.starttime_jst)[:-7]} (JST)
*query:*
```
{replace_newline(row.query_stmt)}
```
"""
WEB_HOOK_URL = "https://hooks.slack.com/services/hogehoge"
if slack_txt != "":
requests.post(WEB_HOOK_URL, data = json.dumps({"text": slack_txt,}))このようにSlackにポストされます (自分に返信が来るよう実装を加えています)。
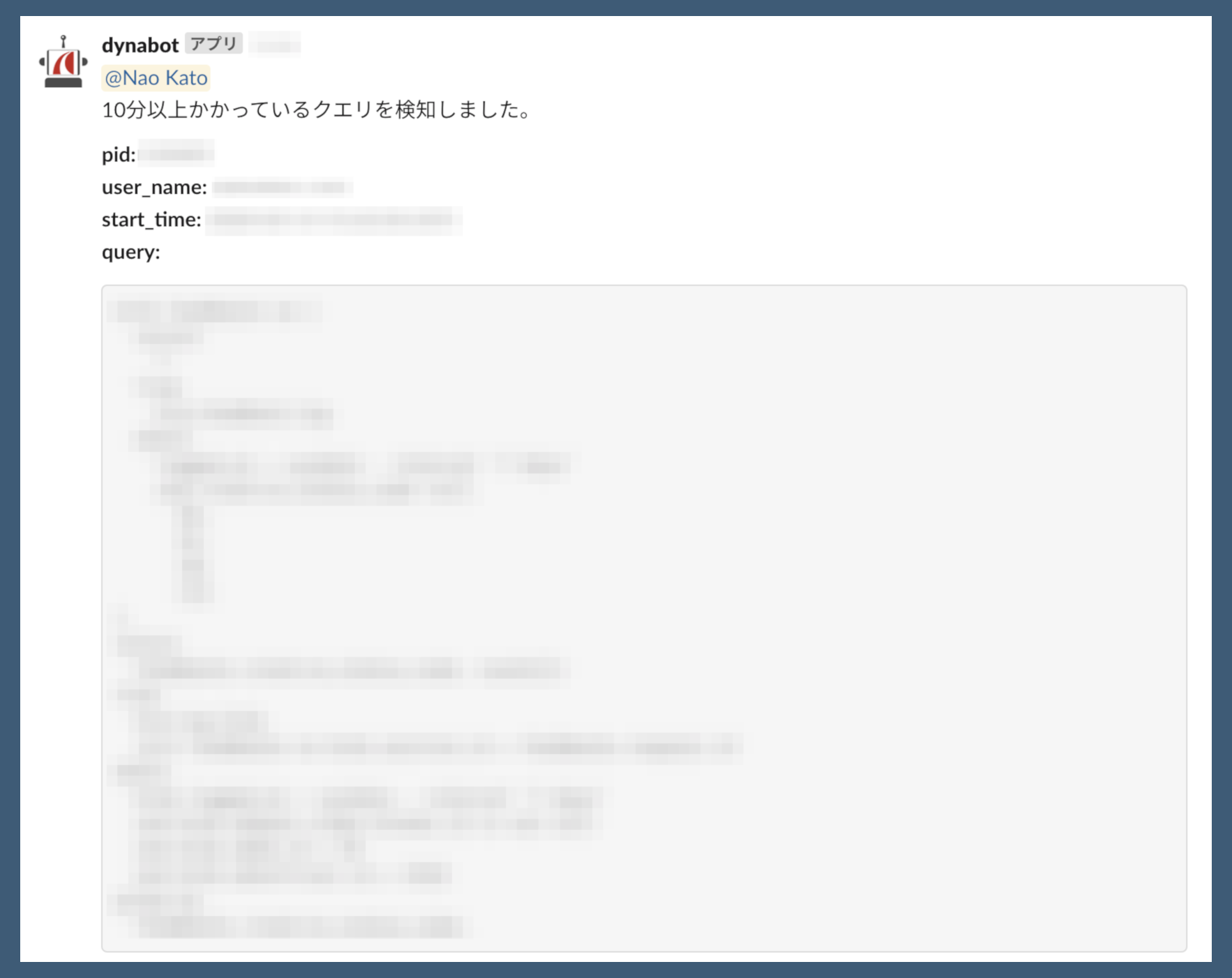
あとはこのPythonコードをcronなどなんらかの方法で定期実行することにより、Redshiftで長時間実行中のクエリを検知してSlackに通知する実装が完成しました。
おわりに
私は日々の業務をちょっと便利にしたり、雑務を自動化・効率化したりすることが好きなので、この他にもGoogle Apps Script (GAS) を用いた自動化をいくつか作成しています。具体的には
- スケジュールに登録された時間の15分前にSlackでスケジュール内容をメンションする (参考: AWSでメールを受信したらLambda Functionをキックし作業を自動化する仕組みを作る | CyberAgent Developers Blog)
- Trelloを用いておこなっている定期ミーティングの議事録を自動作成して投稿する
- Slack Botの作成 (texの数式コマンドを画像化)
などを作成しました。
今回はGASを用いることはなく全てPythonで完結させましたが、GASは各種GoogleサービスやAPIと連携できて非常に幅広い処理を作成できますので便利です。
もちろん全てに当てはまることではありませんが、日々の業務の中で、面倒だと感じたり不便を感じたりすることがあるのであれば、それはきっと自動化のチャンスだと思います。
ぜひ皆さんも、PythonやGASを用いて日々のタスクを自動化していきましょう!