
AI事業本部Dynalystの加藤です。2ヶ月間、#Dynalyst にて就業していた2021年度に新卒入社予定の内定者 長江さんからの寄稿記事となります。
以下本文です。
はじめに
AI事業本部のDynalystというオンライン広告配信プロダクトで、2020年8~9月の2ヶ月間データサイエンティスト(以下DSと略称)の就業型アルバイト(以下、内定者アルバイト)に取り組んだ長江と申します。
私が内定者としてアルバイトで取り組んだ
- Dynalystの機械学習システムの活用
- DynalystのDSで取り組むことができること
- Dynalystのリモートでの内定者アルバイト受け入れ体制
について紹介します。
Dynalystの機械学習システムの活用
Dynalystではリターゲティング広告を展開しています。リターゲティング広告は、ゲーム広告を例にあげると、アプリをインストール後ゲームをプレイしなくなったユーザーに対して、起動を促すような広告を配信することでゲームのアクティブユーザーを増やすことに貢献します。
まず、Dynalystで機械学習がどのように活用されているか簡単に説明します。以下の図はDynalystのサービスで機械学習が活用されるまでの流れを表した概略図です。
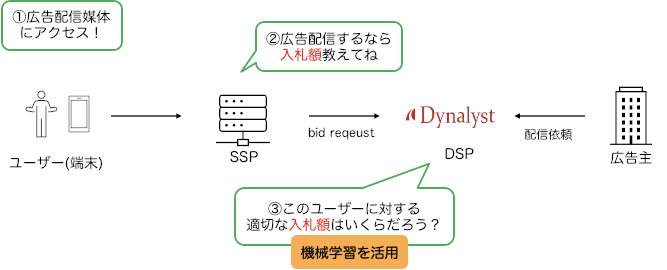
上の図で登場する4役のプレーヤーを紹介します。
- ユーザー(端末):スマホやタブレットを使用している方々を指しています。
- SSP:Supply-Side Platformの略で、広告媒体の収益最大化を目的に、各DSPに対して広告掲載のオークションを開催します。
- DSP:Demand-Side Platformの略で、広告主から広告掲載を依頼され、SSPが開催する広告枠オークションに参加することで広告を配信します。DynalystはDSPとして広告を配信しています。
- 広告主:アプリなどの自社サービスをインストール・プレイしてもらうために、DSPに広告掲載を依頼します。
Dynalystが機械学習を活用するまでを3ステップでまとめると
- ユーザーがSNSなど広告配信媒体にアクセスする
- SSPが、広告を掲載するDSPに対して入札額を聞く
- DSP(Dynalyst)が、SSPから送られてきたユーザー情報や広告主からの情報を元に、適切な金額で入札する
となり、「適切な金額で入札する」課題に対してDynalystでは機械学習を活用して解決しています。
では、適切な入札額をどのように機械学習を活用して決定しているのでしょうか?
下の図はDynalystが機械学習を活用して適切な入札額を決定するまでの流れを説明した図になります。

Dynalystでは、SSP、広告主からのユーザー情報を元にして、広告配信媒体にアクセスしたユーザーが広告をクリックする確率であるCTR、クリックした後にConversion(CV:アプリ起動、インストールなどの広告成果となる行動)する確率であるCVRを、機械学習を活用して予測します。
広告主は1CV獲得するのにいくらの金額がかかるのかを重要視しており、また、Dynalystが入札したときにユーザーがCVする確率はCTR×CVRの形で与えられます。したがって、CTR×CVRの値に比例して入札額を増減させることが考えられ、適切な入札額の決定のためにCTR、CVR予測は非常に重要であると言えます。
DynalystのDSで取り組むことができること
それでは、今回私がDynalystのDSとしてどんなことに取り組んだか紹介したいと思います。私が取り組んだタスクは「特徴量追加によるCVR予測精度改善」です。上述の通り、Dynalystの入札額決定のためにCVR予測は非常に重要で、同時にその予測精度が向上することはDynalystの売り上げに大きく貢献することになります。
タスク背景
今回私に与えられたタスクの背景について簡単に説明します。前提として、SSPごとに取得できる特徴量というのは異なっています。下の図はDynalystのCTR、CVR予測における今回の私のタスクに該当する部分を示した図になります。
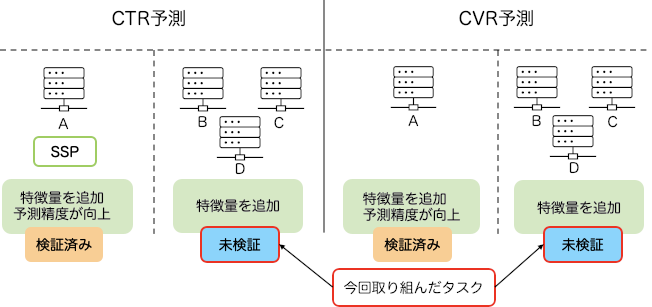
図のように、今回扱った特徴量を取得できるSSPは一部のSSPだけでした。Dynalystでは、今回扱った特徴量を取得できるSSPで特徴量を追加することにより、CTR、CVR予測精度が向上することを既に検証していました。私が内定者アルバイトに参加する時期に、他のSSPでも今回扱った特徴量が取得できるようになりましたが、特徴量追加による精度向上の検証は行われていない状態でした。
そこで、私の内定者アルバイトでは、既に特徴量追加による精度向上が確認できているSSPと同様に、他のSSPでも特徴量追加による精度向上が見込めるかを検証し、Dynalystで運用されている機械学習システムに新たに組み込むのがタスクとなります。
2ヶ月の内定者アルバイト期間中でのタスクの進行と、触れた技術は以下のようになっています。
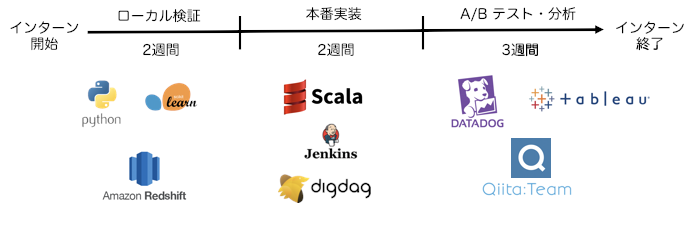
では、ローカル検証、本番実装、A/Bテスト・分析の3つの段階に分けて具体的に行った内容を説明します。
ローカル検証
ローカル検証の目的は、現在Dynalystで運用されているCTR、CVR予測モデルをbaselineとして、新しい特徴量を追加した場合、CTR、CVR予測精度を最も向上させる追加特徴量の組み合わせを探索することです。
ローカル検証ではDynalystの過去の広告配信ログを用いてモデルの学習・検証をPythonで行いました。分析コードがGitHubに共有されているため、プロのデータサイエンティストのノウハウをコードから学ぶことができました。
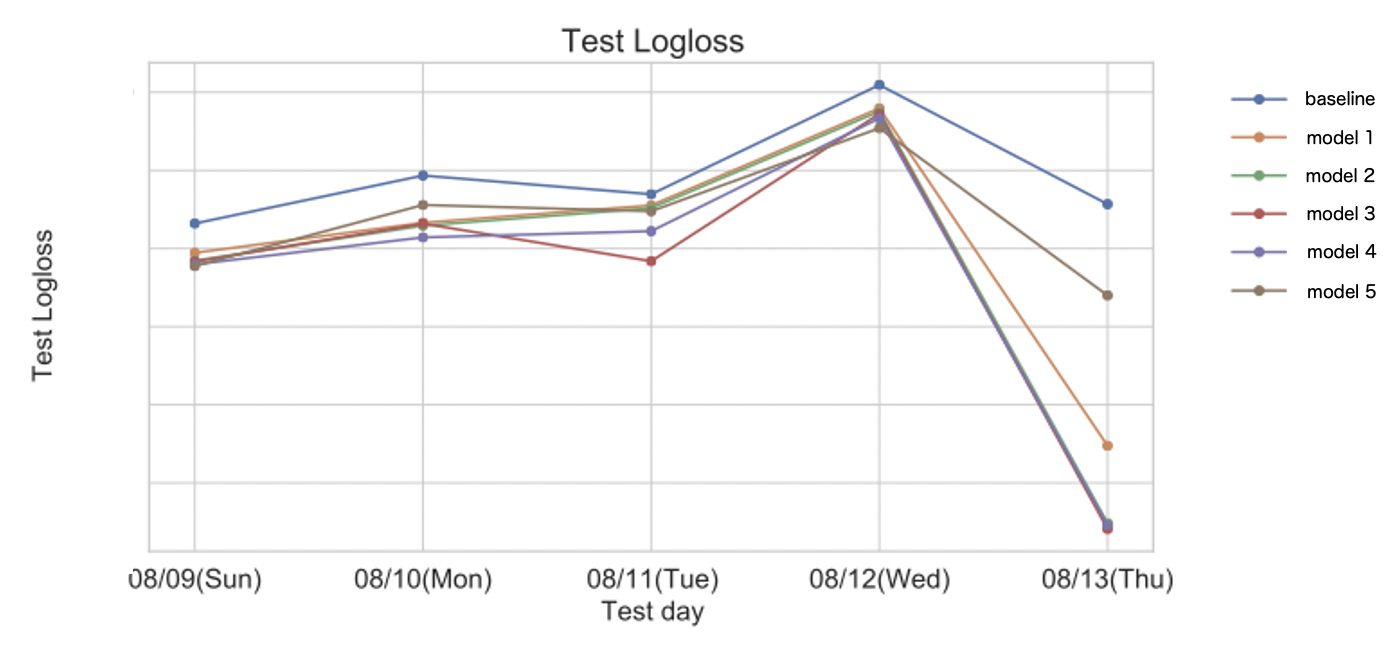
下の図は新しい特徴量を追加した場合のCTR予測のloglossを表しています。loglossとはCTR予測精度の良さを表す指標で、値が小さいほど精度が向上していることを意味します。図中のmodel 1 ~ 5はそれぞれ、特定の特徴量の組み合わせを追加したモデルに対応しています。baselineと比較して、新しく特徴量を追加したモデルのloglossが減少していることより、特徴量追加によるCTR予測精度向上を確認できました。
一方、CVR予測では、CTR予測の場合のように単純に新しい特徴量を追加するだけでは精度が向上しませんでした。この問題をメンターの方に相談すると、生データを確認してみることをアドバイスしていただきました。実際に生データを目視で確認してみると、SSP間にある追加特徴量での表記揺れがあることを確認できました。Dynalystでは全てのSSPで共通のCVR予測モデルを使用しているにも関わらず、SSP間の表記揺れを考慮せずに特徴量を追加していたため、CVR予測に悪影響をもたらしていたことが判明しました。
このような生データを目視で確認することの重要性を内定者アルバイト中に何度も経験しました。SSP間の表記揺れを考慮して、改めて新しい特徴量を追加したCVR予測の結果は下の図になります。
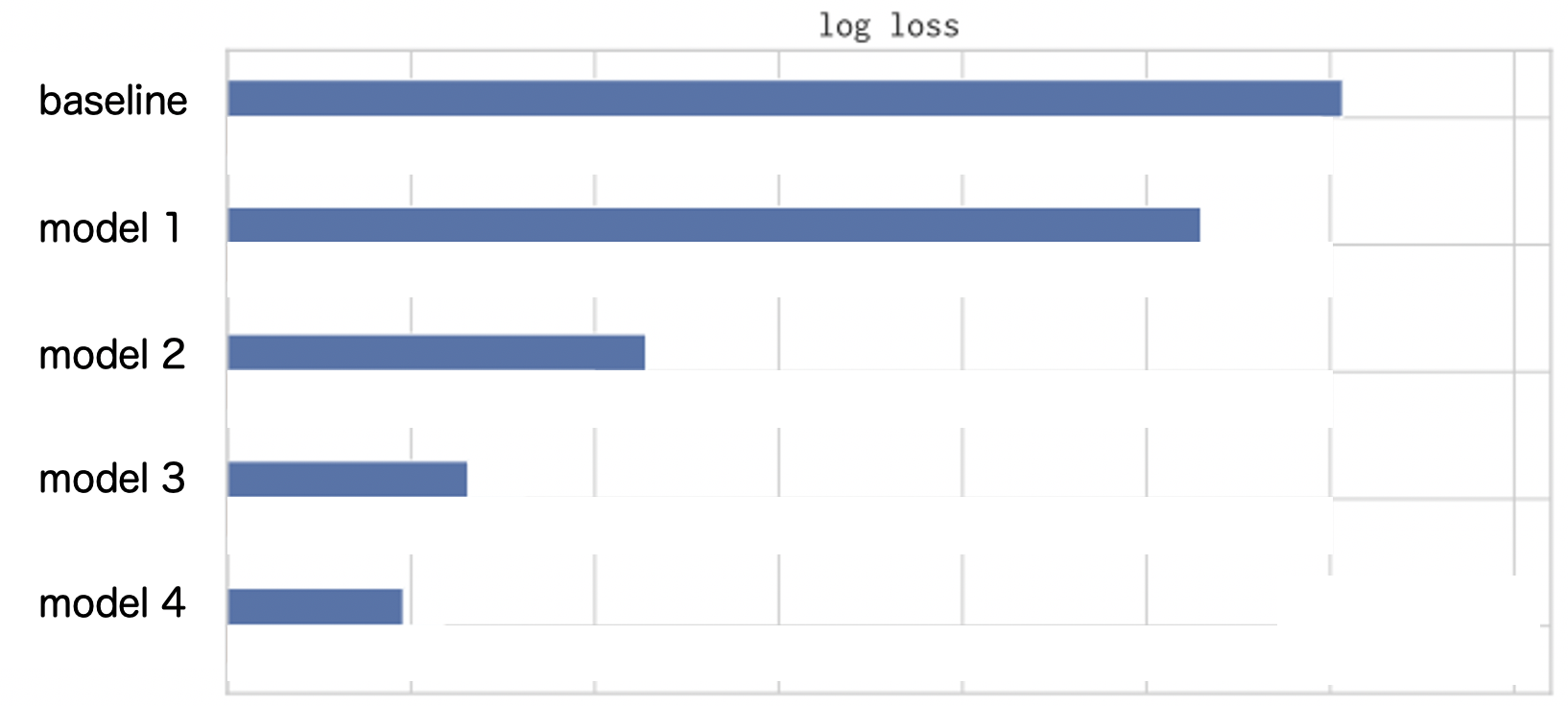
model 1 ~ 4 が新しい特徴量を追加したモデルで、baselineに対してloglossが減少して精度が向上していることを確認できました。
本番実装
ローカル検証の結果を元に、特徴量を追加したCVR予測モデルの本番実装を行いました。
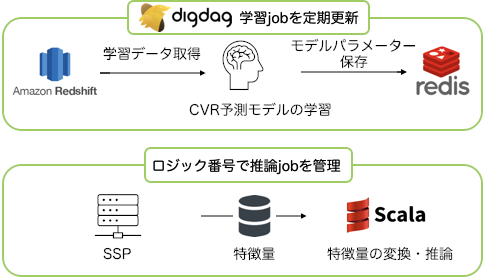
下の図は本番実装の概略図になります。学習部分ではRedshift上のログから学習データを取得し、CVR予測モデルを学習し、モデルパラメータをredis上に保存する一連のパイプラインの実装を行いました。予測モデルは常に最新のデータで学習させ続ける必要があるため、ワークフローエンジンのdigdagを用いてモデルを定期更新するようにします。推論部分は、SSPから来る特徴量を変換し、モデルの推論を行うまでをscalaで実装を行いました。
DynalystではDSが機械学習モデルの本番実装まで行うため、MLエンジニアとしての実装力をつけられる強みがあると思います。
A/Bテスト・分析
Dynalystでは予測モデルを変更する場合、ローカル検証で精度が向上したとしても、必ず本番環境でのA/Bテストを行った上で、運用の判断を行っています。適用率をいきなり50%に上げず、段階的に適用率を上げています。
下の表は今回のA/Bテストでの適用率の期間の例です。それぞれの適用率で目的が異なり、機械学習モデルを安全に運用するよう最新の注意を払っています。

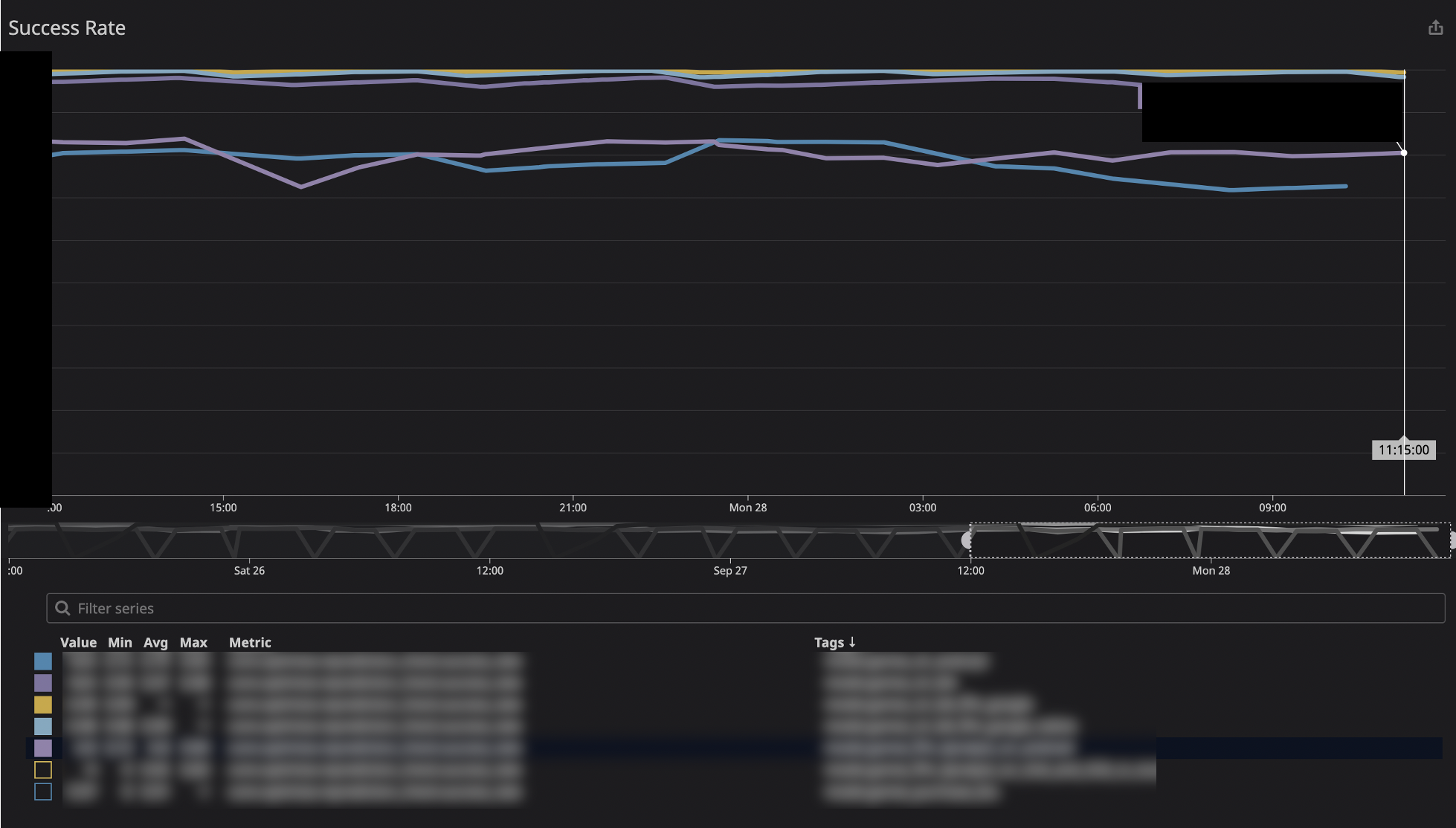
Dynalystでは機械学習モデルの予測値に異常値がないか、Datadogという監視ツールを用いて下の図のような画面で常にチェックしています。異常値の割合が閾値を超えた時にslackに通知が飛んでくるようになっています。
今回、1%適用の段階で異常値の割合が多いことが、この監視ツールによって検出されました。1%適用の目的であるヘルスチェックができ、未然に機械学習モデルの事故を防ぐことができました。このような機械学習を安定して運用する技術であるML OpsのDynalystでの取り組みは、今回メンターをしていただいた加藤さんの記事に詳しく記載されています。
今回、異常値の割合が多かった原因を調査したところ、学習時にSQLで学習データを作成する時の欠損値補完と、推論時にscalaで実装している特徴量変換の欠損値補完の方法が異なっていることが原因であると突き止め、バグ修正を行うと無事正常に予測できていることを確認しました。
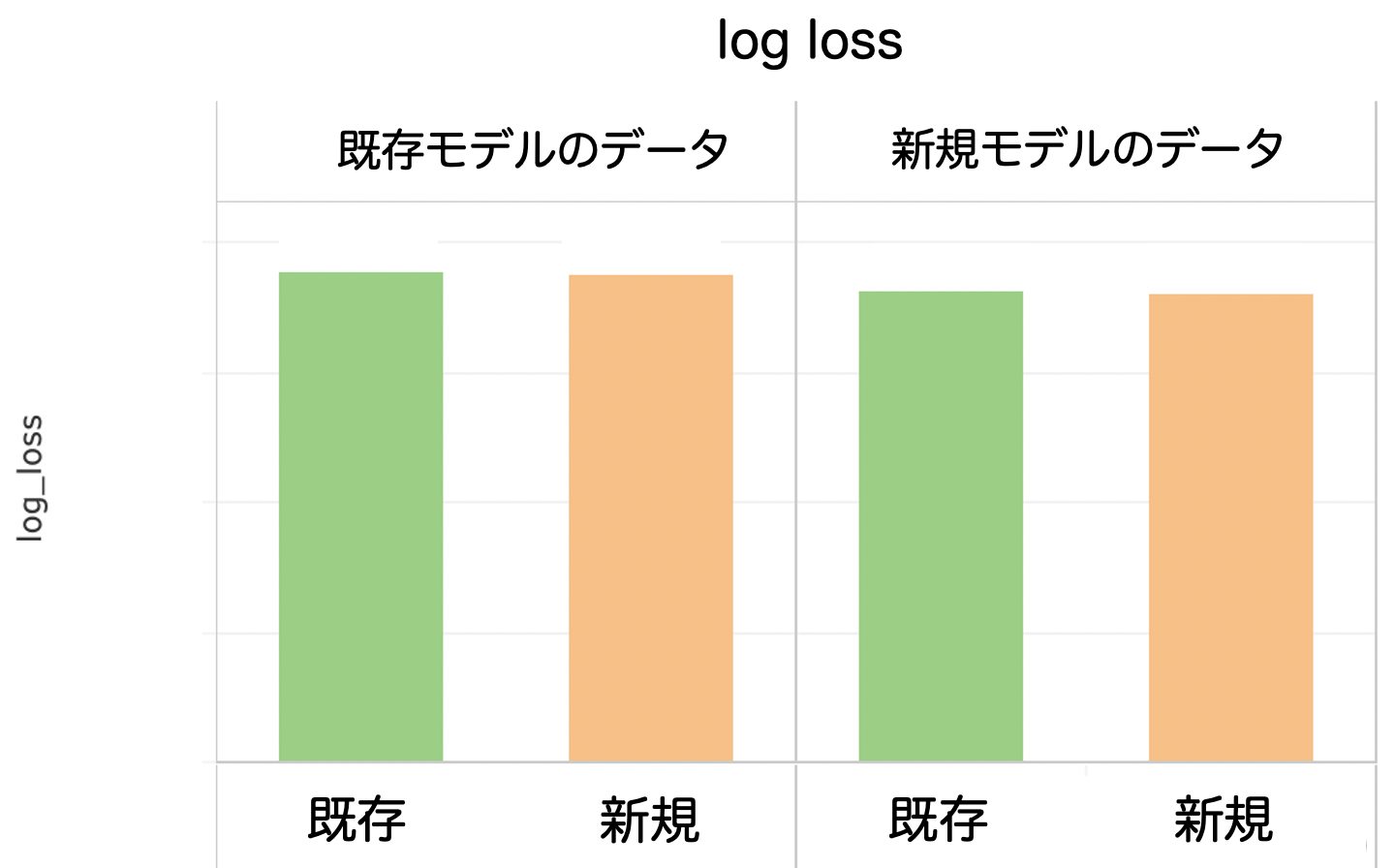
10%適用では、CVR予測精度が改善できているか、ビジネス指標が極端に悪化していないかをチェックしました。下の表は既存モデルと新規モデルでのloglossのグラフになります。
ここで注意するべきなのは、A/Bテストで2つの予測モデルを使用した場合、入札額が予測モデルで変わることにより、入札後の配信ログのデータの分布が2つの予測モデルで異なるため、それぞれの予測モデルで使用されたデータだけで評価すると、モデルの優劣を正しく評価することができないことです。そのため、A/Bテストで2つの予測モデルの精度を比較する際は、評価データに2つの予測モデルで共通のデータを使用する必要があります。
Dynalystではモデルの予測精度を正しく評価できるように、2つのモデルで使用されたデータをそれぞれのモデルに適応することにより、データが異なることで正しく評価できない問題を解決しています。10%適用では新規モデルが既存モデルよりloglossの値が小さく、精度が改善していることを確認できました。
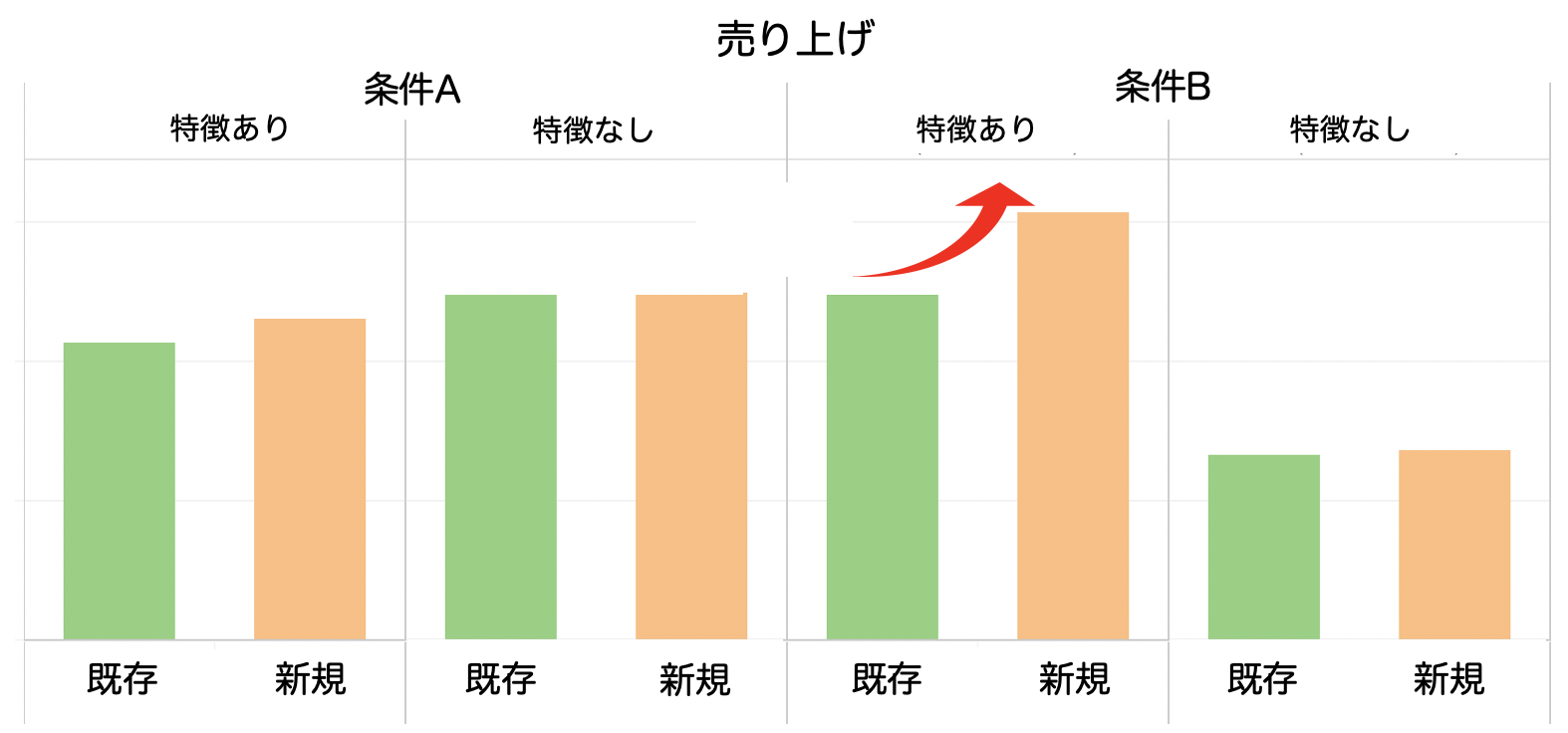
次に、ビジネス指標の1つとして売り上げに着目して見たところ、下の表のように、一部の追加特徴量の有無によって、特定の条件で売り上げが大きく増加していることを確認できました。
この原因を調べるため、A/Bテストで使用されたモデルパラメータをローカル検証し、CVR予測の性質から考察しました。すると、着目した特徴量が取得できるSSPで、calibrationの値が新規モデルでは上振れていることを確認しました。calibrationとは、CVR予測値の平均値を真のCVRの値で割った値で、予測値の真値とのズレのを表す指標です。calibrationが上振れているためCVRが高めに予測され、売り上げが増加した要因となったと今回は考察しました。
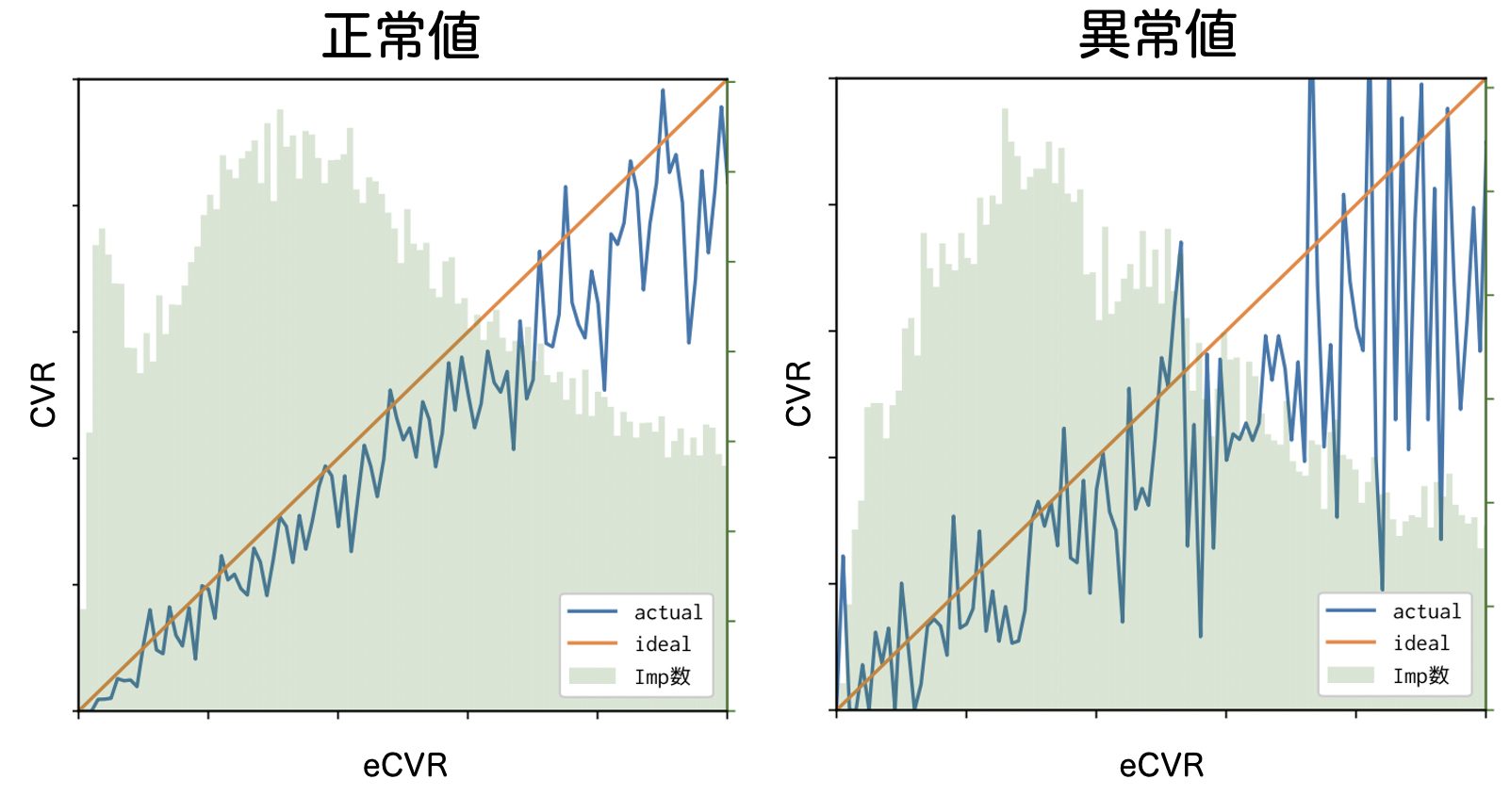
calibrationが上振れていた原因を調べるため、実際に入札時に使用されたデータを確認してみると、着目した特徴量の一部の値が異常値となっているデータが存在することが確認できました。異常値の影響を調べるため、下の図のようなcalibration curveを描いてみたところ、異常値となっているデータのCVR予測値が理想線から大きく解離していることを確認しました。calibration curveは縦軸に真のCVR、横軸に予測値のCVRをとり、データをビン分割した際の各分割区間の平均値をプロットした図で、モデルの予測値の理想値からの乖離を調べるのに役立ちます。
以上の分析から、CVR予測モデルの性質から売上増加の要因を考察することができました。
他のビジネス指標を調査したところ、特徴量追加モデルの方が改善していることを確認できたため、50%適応へ上げることができました。
50%適用の分析、意思決定は残念ながら私の内定者アルバイト期間中にデータがたまらなかったため、メンターの方に引き継いでいただくことになりました。しかしながら、今回の内定者アルバイトでローカルでの検証、機械学習モデルの本番実装、A/Bテスト・分析までの一連の流れを行うことができ、非常に価値ある経験をさせていただきました。
Dynalystのリモートでの内定者アルバイト受け入れ体制
今回の内定者アルバイトではフルリモート体制で参加したので、Dynalystのリモートでの内定者アルバイトはどのようなものだったか紹介します。
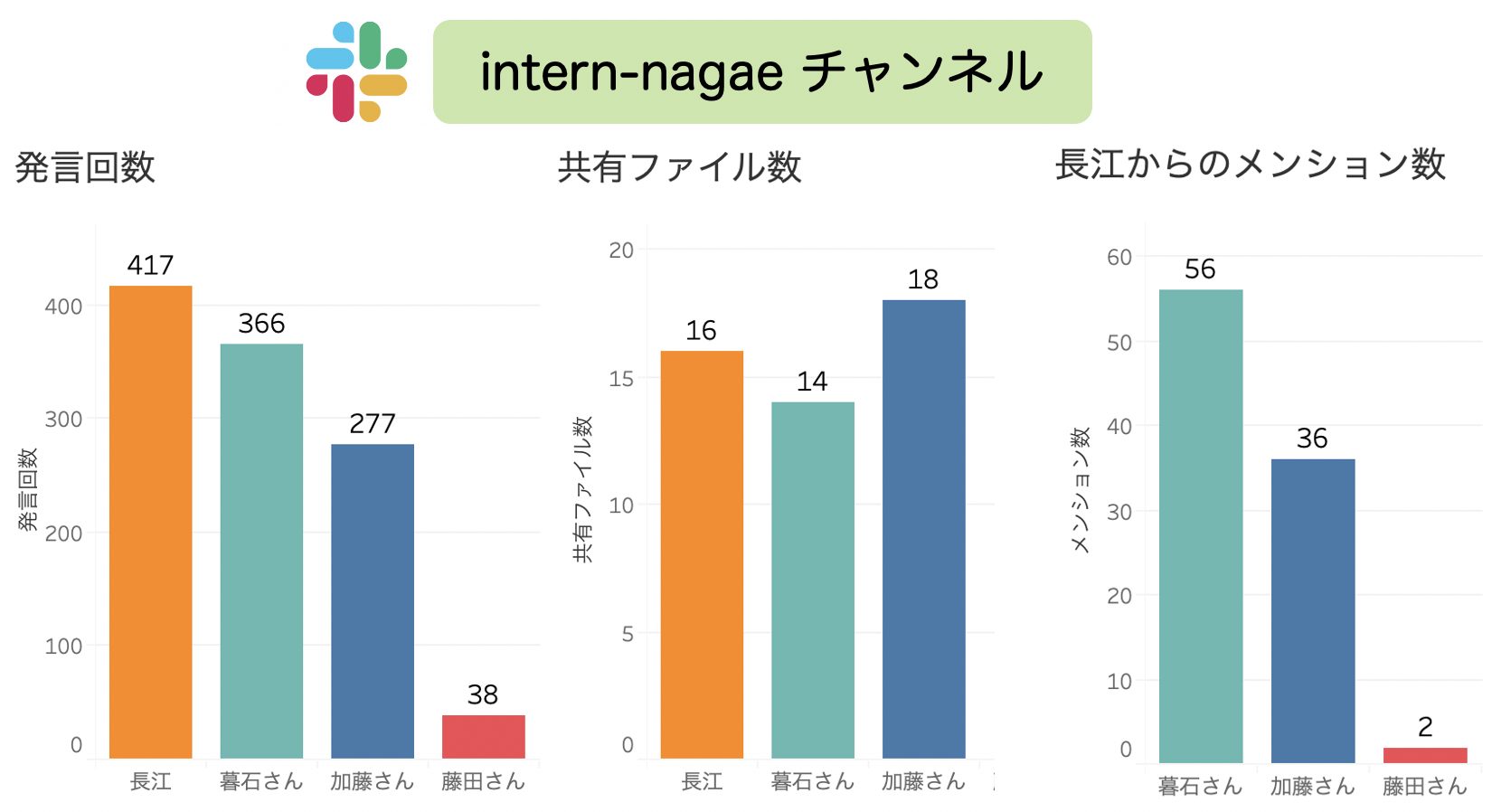
まず、今回の内定者アルバイトでの指導はslackベースだったので、メンターと自分のチャンネルであるintern-nagaeの2ヶ月間の状況をまとめたのが下のグラフです。発言回数が全体で1200回をこえていて、私からのメンション数が合計100回近い回数投げている様子から、slackベースで密にサポートしていただけていたことが分かります
DSチームのリーダーである藤田さんから鋭い質問がたまに飛んでくるため、リモートで気が緩みそうな中、良い緊張感を持って仕事に取り組むことができました。
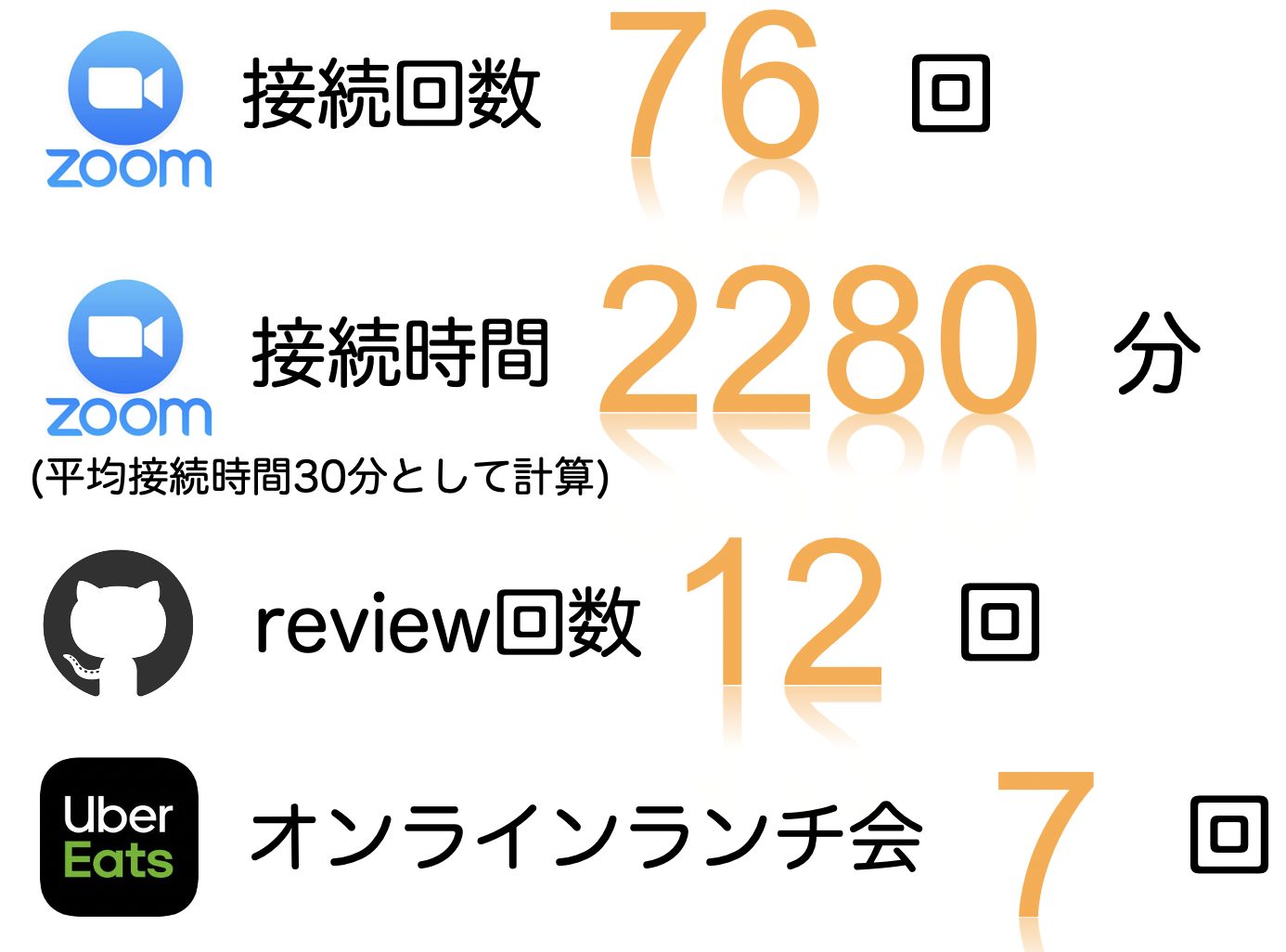
文字では伝えづらい部分を補うためzoomを使用して、口頭で説明をしていただくことが多く、zoomの接続回数は2ヶ月間で76回に及び、接続時間では2280分も繋いでいただいたことになります。
また、オンラインランチ会を頻繁に開いてくださり、オンラインのため生じる心理的距離感を埋めてくださるよう大変配慮をしていただきました。
おわりに
フルリモート参加で受け入れが難しい中、本当に親身になって対応していただきました。
国内のDSインターン・アルバイトで、ローカル検証からA/Bテストまで行わせてもらえるところは貴重だと思います。Dynalystは所属しているエンジニアの方々の技術レベルが非常に高く、ミーティングからコーディングまで、プロダクトに本当の意味で貢献できるDSの能力を学ぶには最高の環境でした。また、ビジネスの方々のエンジニアリングへの理解の深さ・学習意欲に大変驚きました。
以上、長くなりましたが私の内定者アルバイトの体験を通じてDynalystの魅力を知っていただければ幸いです。本当に素晴らしいチームでした。ありがとうございました。