
この記事は CyberAgent Developers Advent Calendar 2020 11日目 の記事です.
AI事業本部 Dynalystでデータサイエンスチーム責任者をしている金子(@coldstart_p )です. 本日はatma株式会社様と共同で開催したデータサイエンスコンペティション,CA × atmaCup 2nd の話をします.主催側企業として参加した立場からの振り返りという視点の記事となります.
第一回も私が運営側で参加し,その時の開催記事は https://developers.cyberagent.co.jp/blog/archives/24684/ でした.こちらもご一読頂けると幸いです.
データサイエンスコンペティションとは
前提として,そもそもデータサイエンスコンペティションは何かということかに触れます.簡単に言うと「出題者が出すデータ分析タスクを参加者が解いて精度を競う」コンペティションで,上位者には賞金やメダルなどの商品が付与されます.代表的なPlatformは国外だとKaggle, 国内だとSignateや今回共同開催していただいたatma株式会社様のatmaCupが挙げられます.
CA × atmaCup 2ndについて
開催概要

今回は「広告経由のCV予測」という,より私の業務に近い二値分類テーブルデータのタスクで開催しました.開催期間は11/15(日) ~ 11/21(土)の約1週間で,前回の1日限りのオンサイトという形式とは異なり,今回は開会式から閉会式まで全てオンラインの実施でした.
1週間という期間ながらチーム数166,submission数2966という大変な盛況で主催としても非常にありがたかったです.参加者様の参戦記事(u++さんの記事,atma株式会社の社員様の記事)もすでに上がっており,ぜひこちらもご覧いただけると幸いです.
結果
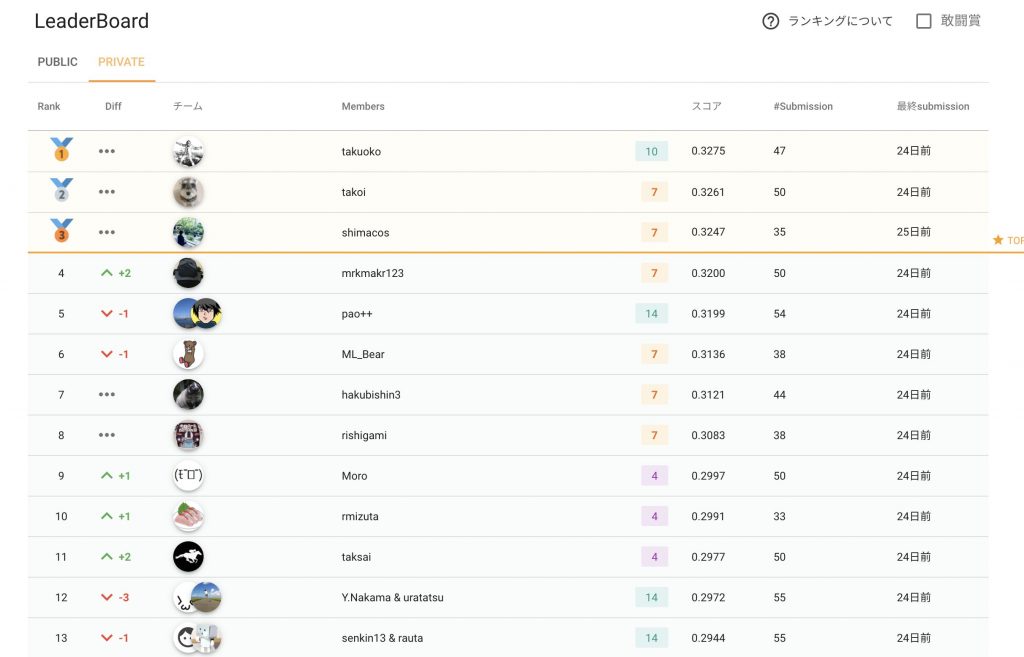
最終結果は上記のようになり,1位takuokoさん(@takuoko1) 2位 takoiさん(@TaTakoihirokazu), 3位shimacosさん(@shimacos)という結果になりました.よく見たら1 ~ 8位まで全員Kaggle Master以上となっており,atmaCupのレベルの高さを思い知らされました.コンペ終了後には皆様積極的にsolutionをサイト内に投稿していただくなど,知見の共有という部分でも非常に盛り上がりました.
データコンペティションを主催するモチベーションとは
今回のコンペ開催日の2日前に,Discovery DataScience Meet up (DsDS) #1 というデータサイエンティストが登壇するイベントがありました.この回のお題がKaggleだったため私が登壇させていただき,そこでデータコンペティションを主催することのモチベーションといった部分の話をさせていただきました.
この時の登壇スライドは
ですが,改めて今回の開催を機に結局このスライドの補足といった部分,課題解決はどこまで達成しうるか? という点に触れようと思います.
主催者側にとっての価値
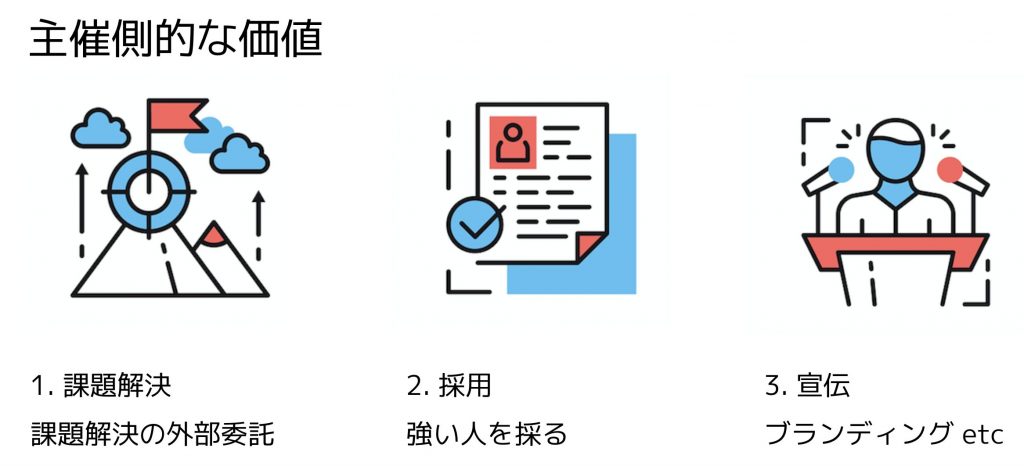
データコンペティションを主催することのモチベーションは大きく3つに分けられると思います.
- 課題解決: 課題外部解決の委託
- 採用: Kaggleで上位に入賞するような優秀なDSへのリーチ
- 宣伝: ブランディングや自社の取り組みの宣伝
上記スライドの発表のオチを先に言うと「良いコンペを開催しましょう」というオチになるのですが,そもそも採用や宣伝の部分で付加価値をつけようとしている理由としては,今回のコンペの解法が課題解決に100%繋がるとは最初から期待していなかったというネガティブな理由があります.これは,2018年頃にKaggleの問題点として挙げられていたデータサイエンスコンペにおける実務的な問題点という部分が関わっています.
データサイエンスコンペは実務に役立つか問題
Kaggleは実務に役立つか? という問題はTwitterなどのKaggleコミュニティで繰り返し議論に上ってきた話です.今回の記事では詳細には触れませんが,特に主催にとって課題解決の部分が役立つか? という問題に関しては例えば以下の問題点があげられます.
- 精度向上のために巨大なモデルが必要とされることが多く,実プロダクトに載せるのはほぼ不可能
- testデータを手元におけるため,これらをutilizeした特徴を作れてしまう
- 特に時系列データの場合,未来の情報を使った特徴量が精度向上に寄与することが多い.当然ながら実務的には全く価値の無い特徴量になる.
これらの問題が強く取り上げられていたのが2018年くらいの雰囲気だったイメージが個人的にはあります.今回のコンペも時系列データだったため,当然ながら未来特徴量も上位解法として挙げられていて,これに関しては主催としても想定通りでした.2018年にKaggleで開催されたTalking Data(リンク)を類似コンペとして想定していましたが,これらの解法の中でも未来特徴量以外に実務的に反映可能な知見が得られればいい,というのが主催としての考えでした.実際には上位解法の中でもいくつか実務的に反映させたい知見があり,これに関しては非常にありがたい結果でした.上記の問題が強く言われていたのが大体2018年頃でしたが,Kaggleに関して言えばテーブルデータではこの問題に対する一つの解答と言った形式のコンペがいくつか開催されています.Time-Series APIを用いたkernelコンペというのがその解答になります.
Time-Series API & Kernel competition

KaggleにおいてTime-Series APIを用いたコンペが初めて開催されたのは(おそらく)2019年のNFL Big Data Bowlになります.現行コンペではRiiid! Answer Correctness Prediction がそれにあたります.これも時系列データのコンペティションなのですが,簡単に言うとTime-Series APIによって推論時に未来情報を得られないようになっていて,未来情報を用いたaggregationといった実務的に不健全な特徴量を作ることが不可能になっているコンペティションです.
Kernel competition自体は2019年以前からあったのですが,学習推論のコードをKaggleの計算環境上にアップロードすることで以下のような計算リソース上の制約をかけつつ実務的にも十分実行可能なモデル同士で競わせることが可能になります.

今回のatmaCup開催後の参加者アンケートでも「Time-Series APIの実装を(難しいのは十分承知だが)やってほしい」という声もいくつかいただきました.実装されるかはatma株式会社様の意思決定次第ですが,今回主催企業として関わる立場からの一つの意見を最後に書いて記事を締めたいと思います.
データコンペティションプラットフォームの成熟と棲み分け
正直に言って,atmaCupでTime-Series APIが実装されたとして主催として使う機会があるかと言われればかなり怪しいと思っています.というのも,当然ながら上記の形式はKaggleの潤沢なインフラがあるから可能なことであって,atmaCupという場でこのインフラコストを誰が担うのかというのはかなり困難な問題になってきます.合計2回の個人的な感覚から言うと atmaCupでこのインフラコストを払うほどペイするタスクを用意するのは非常に困難だと思っていますし,仮にやるとしても素直にKaggleで開催するという意思決定を行うと思います.
更に,Time-Series APIを用いたKernel competitionに関して言えば特にテーブルデータコンペティションの成熟から出てきたコンペ形式というのもあり,初心者(中級者にとっても?)には非常に敷居が高い困難な形式です.より実務に近い形式という点では理想的だとは思いますが,いきなりこのような形式に入る前の受け皿的な場所があってもいいんじゃないかというのが個人的な意見です.
そのような場として,国内において特に採用やブランディングという点でより付加価値をつけやすいatmaCupなどは,そのような需要の受け皿として上手く棲み分けつつ機能していけるのではないかと思っています.一主催としての意見ですが,データコンペティションプラットフォームの成熟とともに,よりこのコミュニティが盛り上がっていけば嬉しく思います.