
技術本部 サービスリライアビリティグループ(SRG)の柘植(@shotaTsuge)です。
#SRG(Service Reliability Group)は、主に弊社メディアサービスのインフラ周りを横断的にサポートしており、既存サービスの改善や新規立ち上げ、OSS貢献などを行っているグループです。
本記事は、サイバーエージェントグループと他複数社向けに特別開催したAWS Observability Workshopの開催レポートになります。本記事を通して、運用とは何なのかを改めて考えるきっかけとなれば幸いです。
Day1
Day1では、「サービスを動かし続けるために何が必要か」というタイトルで、
- 運用とは何なのか
- Amazonでの運用例
- AWS環境では、どのように運用すればいいのか
- AWSが提供しているMonitorとObserveサービス
- 監視の考え方
についてをAWSの矢ヶ崎様に講演していただきました。とても素晴らしい内容だったのですが、残念ながら講演資料の一般公開は出来ないとのことなので、開催レポートという形でお届けします。
以下、矢ヶ崎様が話した内容の一部です。
運用とは
さっそくですが、運用と聞いて何を思い浮かべるでしょうか?
Amazonには、Working backwardsという考え方があります。先ずはユーザ目線でサービスを使っていて困ることは何かを考えます。そして、プレスリリースを書いたりFAQを考えたりとユーザから逆引きで考えていきます。
ユーザとしては、サービスが当たり前に動いていることを期待していると思いますが、サービスを動かしているとシステムだけではなく、様々な問題が起こりえます。

そして、サービスを動かし続けるためには、誰かが支え続ける必要があります。
つまり運用とは、なんとかしてサービスを提供し続けるためのすべての業務のことです。
しかし現実問題として、すべての業務を手作業で維持し続けるのは難しいため、自動化とスケールが必要不可欠になります。当たり前のことですが、売り上げがなくても運用にはコストがかかるので、損益分岐点を意識し出来る限りコストを抑えて、売り上げを上げる必要があります。

ここで気をつけなければいけないのは、インシデントが発生することによりユーザが離れ、売り上げが下がるリスクがあるということです。なので、サービスレベルにあった安定運用のために、技術的負債に向き合うことも重要となります。
運用についてAWSはどう考えているのか
Amazon CTOのWerner Vogels氏は、Everything fails, all the time(故障しないものは無い)であるため、我々は壊れることに備える必要があると言っています。

AWS re:Invent 2020のDeveloper Keynoteでは、砂糖の生成工場の話を事例にしながら運用とは、
- Operations are forever(運用は永遠である)
- Monitoring is for operators(監視は運用者の為のものである)
- Monitoring ≠ Observability(監視と観測性は違う)
- To log everything(全てのログを取ろう)
- Spotting failures before customers do(ユーザが故障に気づく前に対処すべき)
- Everything fails eventually(全てのものはいずれ故障する)
であるといった話をしています。AWSの運用についての考えを知ることが出来るので、観ることをおすすめします!また、Chaos EngineeringやObservabilityについても話しています。
ユーザが困らないために必要なこと
ユーザが困らないためには、下記の3つが必要になります。

- ユーザが期待するサービスレベルを数値で決めて設計することが必要
運用の観点では、外部指標のSLAよりも、内部指標であるSLI、SLOの方が重要になります。また、SLAはあくまでも契約の話なので、SLAを元に可用性を考えてはいけません。
- 可用性の指標を決めて障害時の仕組みを設計することが必要
可用性の指標は、ビジネス要件的に決める必要があります。また、RTOやRPOは外部公開していなくても、内部的には持っておき、それを元に設計するべきです。
- インシデントからの回復方法が必要
問題を検出した際に、自動もしくは手動での復旧時間をいかに短くするかが重要になります。
また、サービスの運営においては、可用性におけるリスクとイノベーションの速度及びサービス運用の効率性のバランスを取る必要があります。そして、SLOをベースにエラーバジェットの設定を行ったり、サービスとして許容できるリスクを数値化するなどといったリスクの管理が重要になります。
実際に、障害が起きてしまったら
実際に、障害が起きてしまった時は、
- インシデント検知
- 事実確認
- 暫定対応(回復優先)
- 根本的原因調査(問題管理)
- 恒久対応
- 再発防止(横展開)
といった流れで、対応することが多いと思います。障害が起きた後に、障害報告書を書いている人はどれくらいいるでしょうか?
書くのは大変ですが、体系立てて物事を整理できるので、障害が起きた後は、障害報告書を書くことをおすすめします。またPostmortemについては、障害報告書よりも内部向けに知見を残すことを目的としており、近年使われている例が増えてきています。
大規模インシデント発生時に、AWS Post-Event Summaries というドキュメントを公開することがあるので、こちらが障害報告書の参考になるかも知れません。

そしてインシデント解決に導くための組織体制としては、HashiCorp SREのインシデント指揮官トレーニングの手引きの話が参考になります。
サービス開発で重要なこと
サービス開発において、
- いかに速くユーザからフィードバックを貰えるか
- いかに速くユーザへサービスを提供できるか
が重要になります。そして、組織がアプリケーションやサービスを迅速にリリースできるようにするためには、DevOpsが重要になります。
DevOpsは、Culture(文化)+ Practice(実践)+ Tools(ツール)の3つが上手く合わさって初めて機能します。DevOpsの実現には、エンジニアだけでなく、ビジネス側の人も巻き込むことが重要になります。
Amazonでの運用例
一般的な開発の流れとして、開発と運用で役割を分けることがありますが、Amazonではプロジェクトではなくプロダクトにフォーカスを置いており、Two-Pizza チームでDevOpsをまわしています。
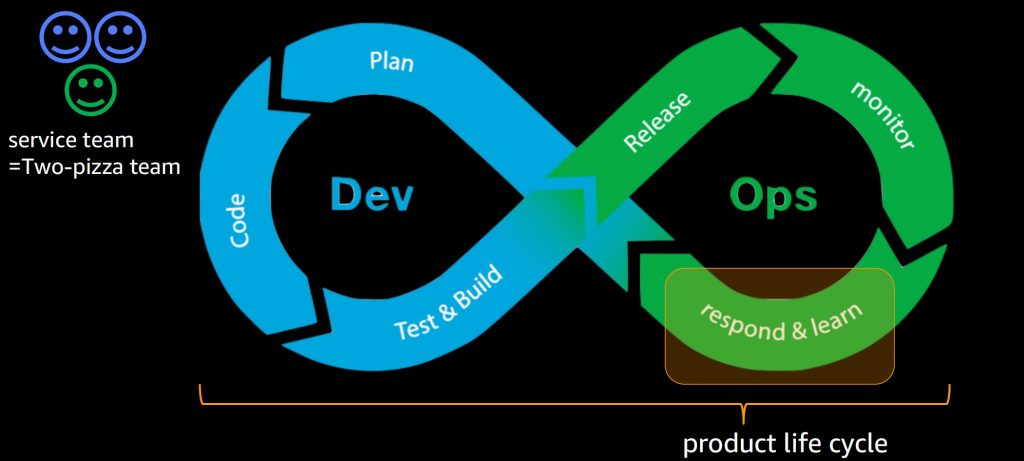
Werner Vogels氏は、開発と運用の間の壁は不要なので、You build it, you run it(作ったら、運用しろ)と言っています。また、このやり方は運用を改善する仕組みを開発者が開発するモチベーションになることにも繋がっているそうです。

すべてはCustomerに価値を届けるためということが、最も重要になります。
そのために、サービス運用のすべてをチームが担当するべきなのです。

これを実現するために、Bezos API Mandate(APIの勅命)により、2001年にモノシリックなアプリケーションとチームから、マイクロサービスなアプリケーションとTwo-pizza チームへ変わっていきました。
大きなシステムを複数チームで運用していくのは、チーム間での揉め事も発生しやすくなるので、いかにチームとシステムを疎結合にしていくかが大事になります。
AWS環境では、どのように運用すればいいのか
AWS環境でサービスを運用する際には、AWS Well-Architected Frameworkが非常に重要になります。
AWS Well-Architected Frameworkとは、AWSをユーザ向けに10年以上提供した上で得られた経験を元に提供しているシステム設計・運用の“大局的な”考え方とベストプラクティス集になります。
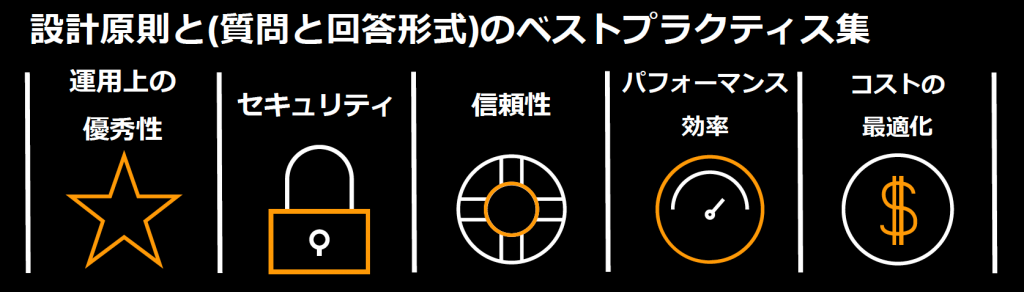
今回は、MonitoringとObservabilityに関係が深い質問項目についての話をしていました。
運用上の優秀性の柱
Q.ビジネスの成果をサポートするために、組織をどのように構築しますか?[OPS 2]
A.責任と所有権を定義し、共有認識する。
Q.どのようにワークロードを設計して、その状態を理解できるようにするのですか?[OPS 4]
A.テレメトリーやトレーサーを実装する。
Q.ワークロードの正常性をどのように把握しますか?[OPS 8]
A.KPIやサービスレベルを定義し分析する。
信頼性の柱
Q.ワークロードリソースをモニタリングするにはどうすればよいですか?[REL 6]
A.適切なモニタリングを設定し、定期的にレビューを実施する。
パフォーマンス効率の柱
Q.リソースが稼働していることを確実にするためのリソースのモニタリングはどのように行いますか?[PERF 7]
A.ユーザの体験にあったモニタリングをする。
AWSが提供しているMonitorとObserveサービス
AWSが提供している管理とガバナンスに分類されるサービスは、このように非常に多くあります。そのひとつとして、Monitor&Observeサービスは提供されています。
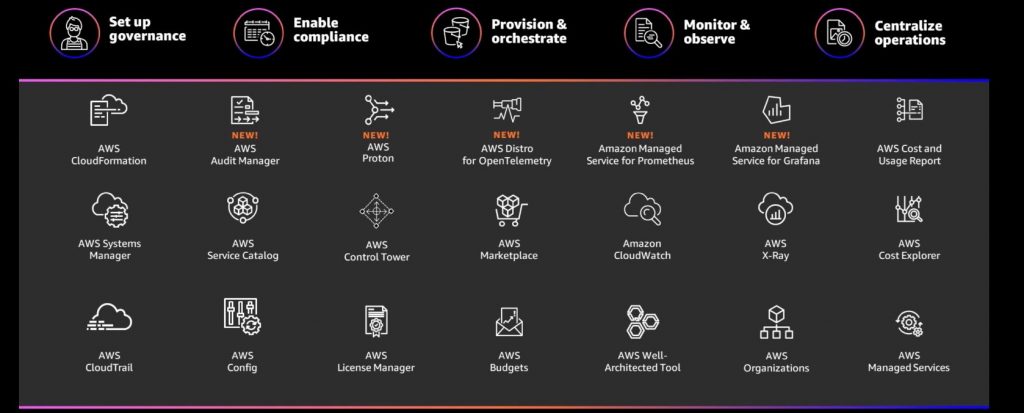
Monitor&Observeサービスの全体像は、下記画像のようになっています。
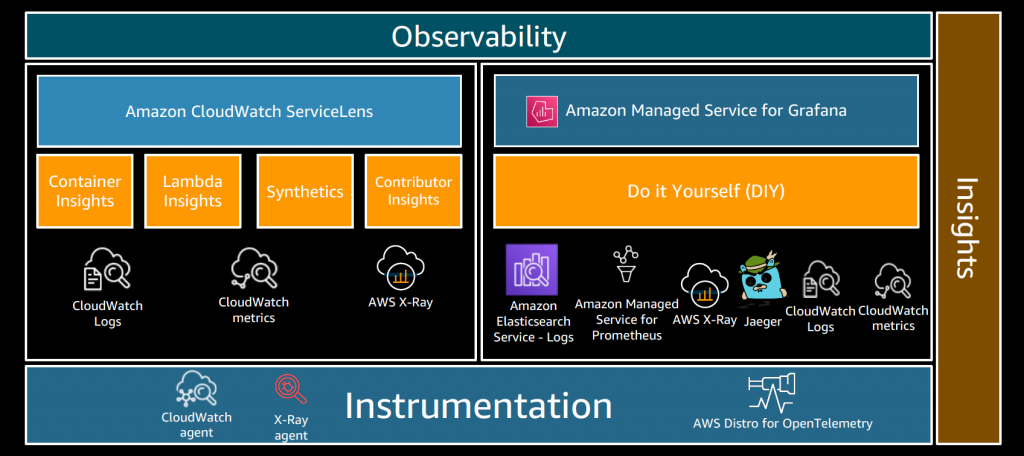
そもそも、なぜObservabilityが重要なのか?
MTTR(平均復旧時間)を短くするために重要になります。
- 検出(Detect)
- 調査(Investigate)
- 修復(Remediate)
を短くするためのObservabilityの土台として、メトリクス、ログ、トレースの取得が必要となります。
監視の考え方
監視は、下記の5つの目的のために使います。

しかし、不適合な監視、情報不足や通知過多といったような目的と監視方法がマッチしないアンチパターンになっていないかを注意する必要があります。サービスの運用に関わっていると、
- リクエストでなくプロセスを監視していたので、ユーザ影響に気付けなかった
- トラブル調査のために、ログを調べようと思ったら必要なメトリクス、ログが取得できていなかった
- 普段からアラートが多くて、重要な通知を見逃してしまった
といったことは、心当たりがある人も多いかと思います。
以上が、Day1の講演内容の一部です。
Day2
Day2では、One Observability Demoを使ったハンズオン形式のワークショップを行いました。
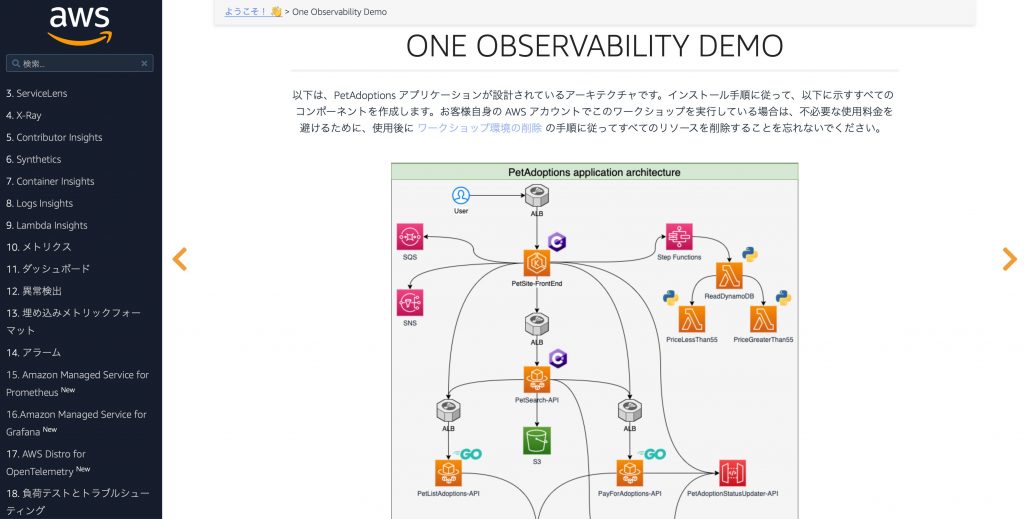
One Observability Demoは、ワークショップを通して、Amazon CloudWatch ServiceLensやAWS X-Ray、Amazon CloudWatch Contributor InsightsなどのAWSが提供しているMonitor&Observeサービスを活用して、複雑なマイクロサービスをどのようにモニタリングすれば良いかを、実際に手を動かしながら学ぶことができる内容となっていました。ちなみに、こちらのワークショップは一般公開されているので、誰でも試すことができます。
参加者からの声
今回のワークショップ参加者からは、
- 普段、インフラの運用に関わっていない人にとっても、良い機会になった
- 自分達が運用しているサービスは、出来ているのかと考えさせられた
- Observabilityの利便性や有用性についての理解が深まった
- ハンズオンの作り込みが凄かった
- Amazon CloudWatch ServiceLensの活用方法を知れて良かった
などのポジティブな感想を沢山いただきました。
最後に
今回のワークショップでは、座学とハンズオンという形で二日間にかけてサービスの運用監視について学びました。
特に本記事では触れていなかったのですが、SRE的な文脈の流れで話していた「組織の数だけ運用がある」という言葉がとても印象的で、良い運用が出来ているかを判断するために、ユーザ目線で考えたサービスレベルを定義し、分析する必要があると改めて実感しました。
今後は、AWSが提供しているMonitor&Observeサービスを上手く活用し、横断的SREチームとしてWell-Architectedな運用のサポートをしていきたいと思います!