
AI事業本部小売セクターでデータサイエンティストをしている藤田です。現在、小売の購買データを用いたデジタルマーケティングの新規事業立ち上げに携わっています。この経験をもとに、5/28に開催されるサイバーエージェンの社外向けカンファレンスCA BASE NEXTで、「事業立ち上げにデータサイエンティストは必要なのか?」というタイトルで登壇します。新規事業の詳細については触れられないのですが、データサイエンティストがどういう部分で事業立ち上げに貢献できるのかを話せればと考えています。
本投稿では、貢献ポイントの一例として、立ち上げ期に事業の強みになるようなデータサイエンスに関わる機能(以下では単に「予測機能」と呼ぶことにします)をどう作るかを自分の経験をもとに整理してみます。
予測機能を作る
まず、事業を成長させるようなデータサイエンスタスクのロードマップを作成してタスクを定義し、そのために必要なデータ基盤を整備します(詳細は本編の発表で)。そういった準備が整った後に、事業の強みになるような予測機能の実装をします。私が所属する新規事業のケースでは、その予測機能は購買予測でした。
立ち上げ期に予測機能を作る上での重要なポイントは以下の4点だと考えています。
- 予測結果を使って、どう意思決定を改善するか?
- 予測をシステムでどう扱うか?
- 予測モデルをいかに早く作れるか?
- 予測モデルの今後の改善余地はあるか?
以降では、この4点について詳細を整理していきます。
予測結果を使って、どう意思決定を改善するか
予測機能自体に価値があるようなビジネスモデル(Google Cloud Vision APIなど)でない限り、予測機能の目的は予測の結果を通して何らかの意思決定を改善することです。
ビジネスにおける意思決定の例は以下です。
- ECサイトでユーザにどの商品を推薦すべきか?
- どのユーザに割引クーポンを配るべきか?
- 施策A, Bがあるときにどちらを選ぶべきか?
- ある商品の値段を上げるべきかどうか
単位、粒度、決定方法などは違いますが、いずれも意思決定といえます。ECサイトでの商品推薦を例に取ると、予測機能はあるユーザがある商品をクリックしたり購入したりする確率を提供し、その予測結果を使って最終的にどの商品を推薦するかを意思決定します。したがって、どういう意思決定を改善したいかによって、予測機能に求められる性能が変わります。
私が所属する新規事業のケースでは、ユーザの購買傾向(予測結果)をインターネット上の広告枠を買い付けるための入札額(意思決定)に反映したいというモチベーションでした。ここで考慮したことをいくつかあげてみます。
- ある期間内の購買確率を予測するのか、購買頻度を予測するのか
単に購買するかどうかが知りたいのであれば前者で十分ですが、購買個数も重要なKPIなのであれば後者の採用も検討します。
- 予測値をどう入札額に反映するのか
適当な関数を使って予測値が基準より高ければ1より大きくなるような値に変換するなどは一つの手です。この関数の形によっても最適な予測モデルが変わるので、たとえば外れ値を厳密に予測する必要がないような関数であれば、外れ値に影響を受けにくいモデルや評価指標の採用を考えます。
予測をシステムでどう扱うか?
要件を満たすラインでいかにシンプルに実装できるかが重要です。メリットは以下の2点です。
- 本番で稼働するものをできるだけ早く作ることができる
まずは本番環境で動かして、そこでの性能を評価して改善のためのPDCAを回せる状態にします。
- 簡単に作り直すことができる
事業の展開次第でどういう予測に注力したいかが変わりうるので、作り込みすぎず、すぐに作り直せる状態にしておきます。
シンプルに実装した例として、インターネット広告買付でのコンバージョン予測(CVR予測)におけるオンライン推論 vs バッチ推論をあげてみます。
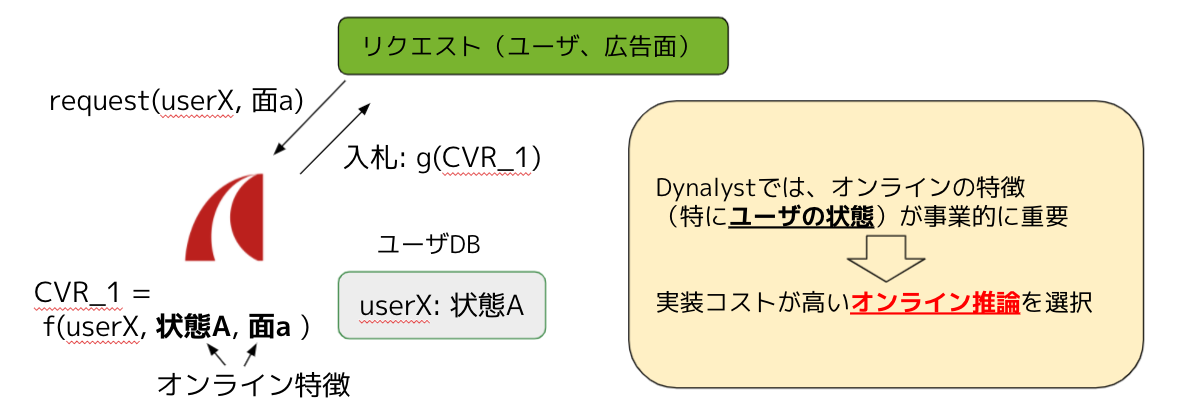
僕が以前所属していたDynalystというDSPの広告プロダクトでは、オンライン推論を用いていました。リクエストに含まれるユーザIDから、自社のユーザDBを参照してユーザの状態を取得し、その状態や広告面などのリアルタイムな情報を使って推論を行っています。これはユーザの状態を考慮することが事業にとって重要だからです。したがって、実装コストが高くてもオンライン推論を採用しています。 AI Labの芝田さんがCythonでオンライン推論を高速化する話をしますので、そちらも是非参考にしてください。
サイバーエージェントにおけるMLOpsに関する取り組み | CA BASE NEXT – CyberAgent Developer Conference by Next Generations
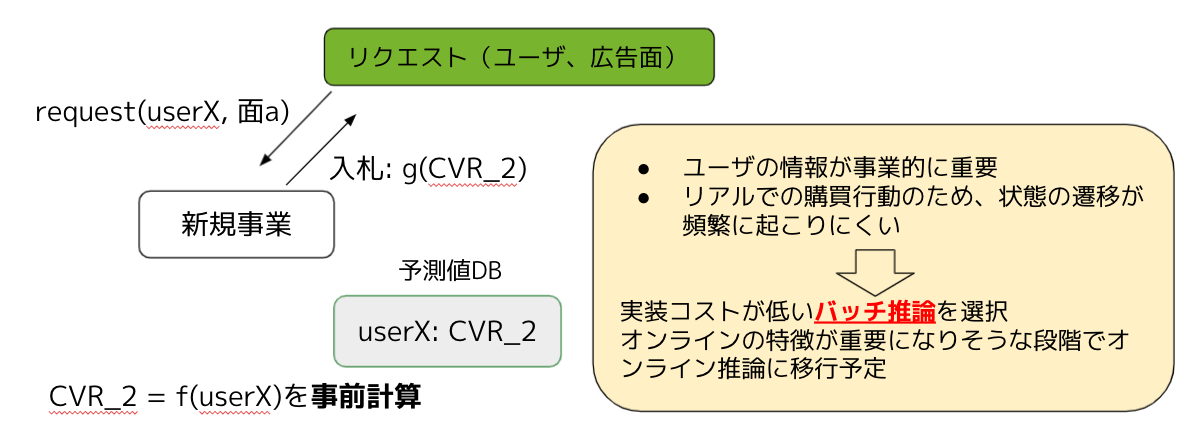
一方、現所属の新規事業では、バッチ推論を採用しています。あらかじめバッチで推論を行い、各ユーザの予測値をDBに保存しておきます。リクエストが来たときに予測値DBから対象ユーザの予測値を取得し、その予測結果を使って入札します。事業的に重要なのは実店舗での購買行動であり、ユーザ状態の遷移が頻繁に起こりにくいので、実装コストが低いバッチ推論を選択しています。リアルタイムな特徴が重要になりそうな段階でオンライン推論に移行できればと考えています。
予測モデルをいかに早く作れるか
最初から予測モデルの作成に時間をかけすぎないことが重要だと思います。「いかに手早くそれっぽい精度のモデルを作る」方法とそうする理由がにのぴらさん (@nino_pira) のブログでまとめらているので、是非参考にしてください。
予測モデルの今後の改善余地はあるか
予測モデルを作った後に、以下の2点を整理します。
- 予測モデルが運用されて、データが貯まってきたらどうするか
予測モデルが事業KPIを改善するために最も重要なのは、実際に本番で運用されてユーザのフィードバックを受けた結果のデータです。データが貯まってきたらどういう指標を見るべきかを事前にまとめておきます。
- 時間的な余裕があったらどこをどう改善するか
早さを意識して予測モデルを作っていると、改善したいポイントがいくつも出てくると思います。それらの改善による事業インパクトと工数をある程度試算し、事業の状況に合わせて適切なタイミングでリソースを突っ込む意思決定ができることが重要です。
最後に
今回は、CA BASE NEXTの登壇内容の中で時間の都合上触れられなさそうな部分をピックアップして紹介しました。予測機能を作る以外にも、事業立ち上げ期にデータサイエンティストが貢献できる部分はあるので、ぜひ本編のほうも見ていただけるとありがたいです。
事業立ち上げにデータサイエンティストは必要なのか? | CA BASE NEXT – CyberAgent Developer Conference by Next Generations
【採用強化中】サイバーエージェントでは、140兆円の小売業界をデジタルで再発明するため、覚悟ある仲間を募集しています。
