
AI事業本部の小西(@hiroki_k8)です。
AI事業本部の小売DXでは、様々なチャレンジをしています。
その中で今回は、プロダクト企画からサービスインまで爆速で行うための1つの考え方と設計・実装面をご紹介します。
目次
- どのように爆速を実現するか
- エンジニアとして楽しむための要素も忘れずに
- 実装時の課題と解決案について
- まとめ
どのように爆速を実現するか
結論は、❝AWSに任せられる部分は任せちゃおう!❞です。
❝爆速❞と聞くと、スピードですよね。
システム開発において、スピードが速ければそれだけで良い。というわけではないですよね。
システム開発を進める際には、時間、コスト、品質、スコープという要素があります。
時間を短くしようとすると、よく品質やコストを犠牲にしがちです。
この犠牲にしがちな品質やコストを、❝AWSのマネージドサービス❞を用いることで守りながら、
できるだけ早く・高品質なシステム開発を実現する。
AWSのマネージドサビースとは
マネージドサービスとは、運用をAWSが引き受けてくれるサービスのことです。
例えば、
- セキュリティ
- 構成管理
- 監視
- バックアップや冗長化
等が組み込まれています。
マネージドしてもらうことにより、僕たち開発者はコストと時間がかかる部分を意識することなく、サービス設計に集中できます。
さらに、フルマネージドサービスという、運用と保守等全てをAWSが引き受けてくれるサービスもあります。
一方で、マネージド・フルマネージドサービスはAWSが運用や保守、チューニングを担ってくれるため、制約や制限が付いてきます。
爆速を実現する考え方
マネージド・フルマネージドサービスの制約や制限事項とうまく付き合いながら、任せられる部分はAWSに任せ、エンジニアが本来集中したいロジック部分に集中する。
そして、それらのサービスを利用するということは、1つ1つ選定するサービスが特定の要素に特化しているということも忘れてはいけません。
つまり、AWSの200以上あるサービスの中から目的に応じてサービスを選定して、それらを組み合わせて利用することが必要ということです。
これはAWSの「Building Blocks」という考え方の理解が必要です。
エンジニアとして楽しむ要素も忘れずに
プロダクト開発をするうえでスピードは大切ですが、エンジニアのチャレンジも必要ではないでしょうか!
今回は、GraphQLにチャレンジしました。
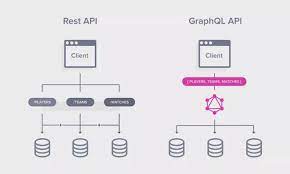
※ 画像引用元: ICHI.PRO
なぜAWS AppSyncを選定したのか
今回のプロダクト開発では、管理画面を作りました。
GraphQL は、アプリケーション・プログラミング・インタフェース (API) 向けのクエリ言語とサーバーサイドランタイムの両方を指します。
クライアントがリクエストしたデータだけを提供することを優先します。
ということで、クライアント側のAPIリクエスト構造や回数をシンプルにすることで、開発を速くしようと考えたためGraphQLを選択しました。
そして、そのGraphQLをフルマネージドで提供してくれるのが、AWS AppSyncでした。
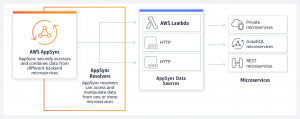
※ 画像引用元: aws appsync
爆速で開発できたのですが、アプリケーションコードを書いている中で、悩んだ部分がありましたので、
そちらを次の章でご紹介させていただきます。
実装時の課題と解決案
GraphQLを用いることでClient側でAPI呼び出し関連の複雑な処理が無くなる一方でServer側では複雑になりそうな部分が多々ありました。
その中でも一般的に課題とされている部分で
- N+1問題
- Pagination問題
があると思います。
今回は、Pagination問題について、実装にてどのように解決したのかご紹介します。
Pagination問題とは
GraphQLで実用化されており、有名なページネーション方法の中から今回は、
❝Relay-style cursor pagination❞を選択しました。
下記のようなスキーマですね。
PageInfo {
hasPreviousPage
hasNextPage
endCursor
startCursor
}GraphQL公式Paginationについての説明はこちら
問題点は実装に関する部分です。
まずは仕様についてです。
要約すると、
- レコードをすべて取得する
- cursorが入力で存在すれば、カーソルのレコードの前や、後を削除する
- edgesから指定されているfirstや、lastの件数分をレスポンスする
です。
この仕様のまま実装すると、データベースから全件取得することになり、
データ量が増加した際のパフォーマンス劣化等、困る部分が多々あります。
そのため、今回は仕様に沿いながら、データベースからは部分的にデータを取得する実装をしました。
Pagination問題の実装方法
上記の通り、データベースから部分的にデータを取得する実装にすると、
- 次のページが存在するか
- 前のページが存在するか
という情報を取得することに工夫が必要になりました。
方法としては、
- firstやlastで指定された件数 + 1件の取得を試みて、その件数分取得できたら、次/前ページが存在すると判断する
- 本体データ取得のクエリと分けて、次/前のページが存在するかどうかクエリを発行する
の2つを案として検討し、コード(1つの関数)を完結に保つ観点から、後者を選択し実装しました。
まとめ
- AWSに任せられる部分は、どんどん任せちゃおう
- GraphQLに技術的チャレンジし、爆速で開発することができました
さいごに
【採用強化中】サイバーエージェントでは、140兆円の小売業界をデジタルで再発明するため、覚悟ある仲間を募集しています。
