
はじめまして。4月に入社した新卒サーバーサイドエンジニアの久米(@kume_ru)です。5/24からAI事業本部 AirTrackに配属されました。
5/13の午後から5/20の午後までのおよそ5営業日にかけて、AI事業本部に配属された新卒エンジニアに対し、開発研修が実施されました。AI事業本部ではインターネット広告事業も行っており、研修では広告システムにまつわる研修として、「CTR予測を行いつつ、2000rps (request per second) を捌く簡易DSPを作る」ということを行いました。
結果として、レスポンス時間の分布が95%% 17ms、99%% 29msという爆速でレスポンスを返すハイパフォーマンスなDSPを作ることができたので、どのような構成で作ったかをご紹介させていただきます。

DSPとは
DSP(Demand Side Platform)は広告の取引のシステムの一つです。複数の広告を管理しており、主に別のシステムであるSSP(Supply Side Platform)から受け取ったリクエストに応じて最適な広告を選択し、返します。
DSP及びアドテクに関する詳しい解説はこちらの記事に書かれています。
要件
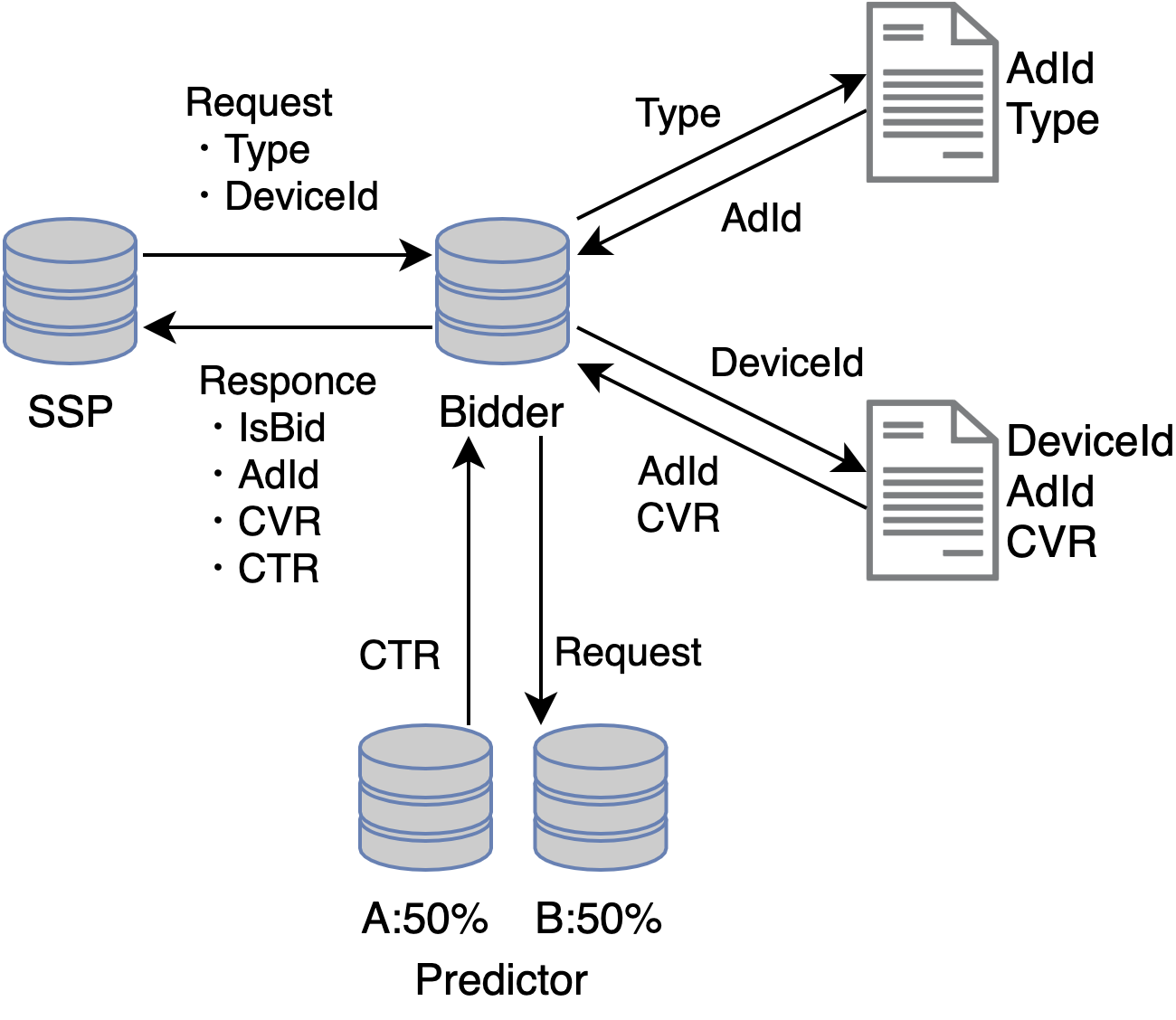
研修では簡易的なDSPとして以下の要件を満たす必要がありました。
- SSPからのリクエストに応じ、最適な広告を選択し、レスポンスを返す。
リクエストは最大2000rpsで行われ、95%以上のリクエストに対し50ms以内にレスポンスを返す。- リクエストには広告タイプ(Type)、ユーザー(DeviceId)、その他デバイスやアプリの情報が含まれる。
- DSPは広告ID(AdId)と広告タイプのテーブルを持つ。
- DSPはユーザーIDと広告IDの組み合わせに対するCVR*1のテーブルを持つ*2。
- 指定の広告タイプ及びユーザー情報を用いて各テーブルを参照し、両テーブルに共通して存在する広告IDが
- ある場合、広告IDを返すことを示すフラグ”IsBid”にTrueを与え、CVRが最も高い広告IDを返す。
- ない場合、IsBidにFalseを与えて返す。
- CTR*3を予測する。
- 事前に与えられた学習データから予測モデルを作成する。
- リクエストの情報から予測モデルを使ってCTRを予測し、レスポンスに含める。
- 予測モデルに対しABテストを行う。
- 異なる予測モデルを2つ作成し、50%:50%で適用し、分析する。
*1:広告を閲覧したユーザーが、広告が目的とする行動(商品の購入等)を起こす確率をCVR(Conversion Rate)と呼ぶ。
*2:CVRは本来予測を行う対象ですが、研修では簡単のため予測値がテーブルとして与えられた。
*3:ユーザーが広告をクリックする確率をCTR(Click Through Rate)と呼ぶ。
チーム
基本的にサーバーサイド一人、ML/DS一人の二人チームでの開発でした。要件1,2はサーバーサイドが、3,4はML/DSが主な担当となります。
自分はサーバーサイドなので、同じく21新卒 AI事業本部 極AI事業部 ML/DSの秋山とチームを組むこととなりました。
成果物
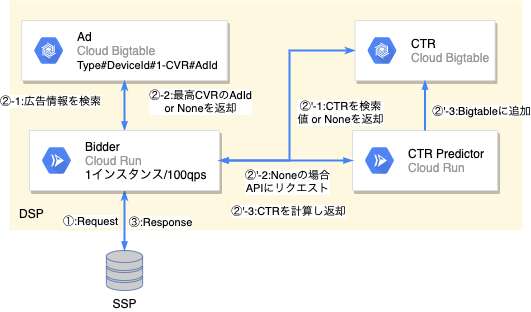
クラウドにはGCPの指定がありました。コンピューティングにはCloud Run、データベースにはBigtableを用いています。
処理の流れは図中記載の通りです。②と②’は並列に実行されます。
①:SSPからリクエストを受け取ります。
②②’:レスポンスに必要な情報を取得します。
②:TypeとDeviceIdからAdIdを取得します。
②’;リクエストからCTRを予測します。
③:SSPにレスポンスを返します。
DSP(Bidder)とCloud Run
Cloud Runはフルマネージドなサーバーレスのコンテナサービスです。
結論からいうと、Bidderには不向きでした。
Cloud Runはインスタンス数のオートスケール機能を持ち合わせていますが、設定できるのは最小インスタンス数のみです。また、オートスケールのトリガーはCPUの使用率になっています。Bidderはリクエスト数は多いもののCPU使用率は低いため、リクエスト数が増えてもオートスケールが適切に機能しません。
今回作ったDSPは、4CPU2GBの1インスタンスで100rpsほどさばけました。しかし2000rpsに対してオートスケールを用いると、14インスタンス程度しか起動せず、リクエストタイムアウトが頻繁に発生しました。そのため、2000rpsという要件に対して最小インスタンス数を20に設定することで対応しました。
インスタンス数を固定して使っているため、この使用方法では料金を考えるとGCEを使ったほうが良さそうです(ほぼ同じスペックの場合、Cloud RunはGCEの3~4倍の料金がかかります)。また事前に負荷が知らされているので、最小インスタンス数を恣意的に設定して対応できていますが、それ以上の負荷が来るとオートスケールに頼ることとなり、再びタイムアウトが発生します。よってコンテナでDSPを運用する場合、リクエスト数に対してオートスケールをかけることのできるサービスを使用するべきだと思いました。
ただしCloud Runのメリットとして、CI/CDが簡単に(ほぼ自動で)構築でき、この短期間の研修の中では時間のリソースの観点から非常に助かりました。また、本番テストの構築で予測モデルの更新を行う際、ほとんど処理を止めることなくイメージを変更することができました。
広告(Ad)用のBigtable
改めてDSPの要件に以下のものがあります。
指定の広告タイプ及びユーザー情報を用いて2つのテーブルを参照し、両テーブルに共通して存在する広告IDがある場合、CVRが最も高い広告IDを返す。
この操作はリクエストごとに行われるため、低レイテンシ、高スループットなデータベースが必要となります。また、ユーザー情報は何千万、何億行と非常に大きなテーブルとなっています。これらを満たすものとして、フルマネージドなKVSであるBigtableを採用しました。
Bigtableには、2つのテーブルを広告IDでJOINしたものを用いて、keyに{Type}#{DeviceId}#{1-CVR}#{AdId}を、valueにAdIdとCVRを保存しました。このkeyの設定にはBigtableの仕様と要件に基づく以下の意図が含まれています。
- Bigtableの仕様
- key
- 1つのみ
- 一意
- 自動で昇順に並ぶ
- クエリ
- 接頭辞で検索可能
- 上位からの取得件数制限
- key
- keyの意図
{type}#{device_id}:接頭辞検索でAdIdとCVRを取得可能#{1-CVR}:同じ{type}#{device_id}に対してCVRの降順となる。上1件を取ることでCVRが最も高い広告のみを取得可能。#{AdId}:キーを一意にする。
同一の{type}#{device_id}に対し、CVRが最も高い広告のみを保存することでも要件を満たすことは可能ですが、実際の運用とはかけ離れた実装であると考え行いませんでした。ただし、CVRを降順に並べること自体は有用であると考え、Bigtableには全てのデータを保存した上で、アプリケーション側で取得件数の制限を行うことで高速化を図りました。
CTR予測用のBigtableとCloud Run
全体で最もボトルネックになる処理だと考えられたのはCTRの予測部分でした。そのため、秋山はカテゴリカルな特徴量のみを用いて予測を行い、既知の特徴量の組み合わせと予測結果は全てBigtableに保存しておくという手法をとることで、レスポンス速度の向上を図ってくれました。さらに未知の組み合わせのリクエストが来た際は、予測サーバーがリアルタイムでCTRの演算を行いDSPに返すとともにBigtableに追記することで、予測サーバーへの問い合わせを極限まで減らすようにしています。
用いた特徴量は7種類、既知のデータから予測可能な組み合わせ数は915,840でした。本番テストでは、Bigtableに存在せず予測サーバーに問い合わせが行われた件数は8,782,996件中96件であり、絶大な効果がありました。
問題点としては、特徴量が増えると組み合わせ数が爆発的に増えること、連続値を扱うためには量子化を行う必要がありこれも組み合わせ数が爆発的に増えることがあげられます。
負荷試験の結果

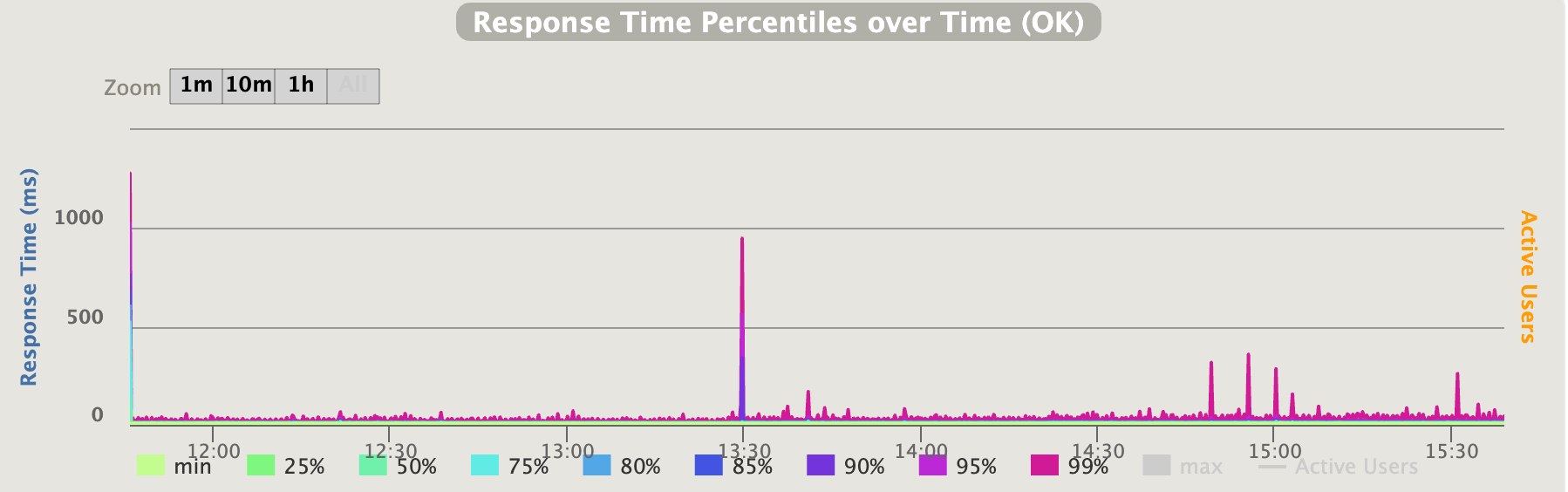
負荷試験は2000rpsを4時間連続でかけるというものでした。
- レスポンス返却率:27989361 / 27999867 ≒ 99.96%
- 返却できていない10506件は主に立ち上がり時のエラーです。主なエラー内容は、負荷試験用のクライアントが1000ms以上のレスポンスを強制的に破棄する設定よるものです。
- レスポンス時間:95%% 17ms, 99%% 29ms
- 13:30にスパイクができているのは、予測モデルの更新を行うためにBidderのCloud Runのイメージの変更をおこなったためです。
- IsBidの正答率:100%
- AdIdの正答率:10%(100%)
- CVRが最も高い広告のAdIdを返した割合です。
- Bigtableの接続先を間違い、
{Type}#{DeviceId}#{CVR}#{AdId}をキーに持つものにしていました(正しくはCVR→1-CVR)。その結果、CVRが最も「低い」広告のAdIdを返す天の邪鬼なDSPと化し、正答率が10%と低い数値になっています。 - CVRが最も低い広告のAdIdを返した割合は100%だったので、ロジックとしては問題ありませんでした。
結果として、レスポンス精度100%?の超爆速DSPを作り上げることができました。
感想
Bidderのロジック自体は非常に単純であり、コードの記述量は少ないものでした。またGCPを初めて触ったこともあり、まずどのようなサービスがあるのかを調べるところから始まり、要件に応じたサービスを選択し、パフォーマンスチューニングを行うという実務に近い経験ができ、非常に楽しい研修でした。ML/DSとペアで開発するのも初めてだったので貴重な経験となりました。
実際のところ、当初DSPを1週間で作れと言われたときは「無理やろ」という感想でしかなかったです。しかしやってみると、案外完成度が高いものを作り上げることができました。先輩方の研修の設定の上手さに感動しています。
様々な準備をしていただいた先輩方に感謝申し上げます。また、ペアとなった秋山にも感謝しています。
最後に、自分はプロダクトマネジメントのできるエンジニアとして活躍したいと考えています。
これからAI事業本部にてよろしくお願いいたします。
宣伝
6/8に同じ研修を受けたAI事業本部 極AI事業部の小林(@Cat_to_Love)の記事が公開される予定です。是非そちらもご覧ください。