
はじめに
タップル SREの赤野、CAM SREの庭木です。
タップルは2021年3月頃にMongoDB on Amazon EC2(以下EC2 MongoDB)からMongoDB Atlas(以下Atlas)への移設を行いました。
今回はこの移設での取り組みについて紹介します。
Atlasへ移設することになった経緯・目的
タップルでは定期的にキャパシティプランニングを目的とした負荷試験を実施しており、今後のDAU増加のシミュレーションに対してシステムのキャパシティが確保できるかを定期的に確認しています。
タップルSREのキャパシティプランニングの取り組みについては、以前発表させていただいた資料があるのでこちらにも目を通していただけると幸いです。
2020年の12月頃にもキャパシティプランニングを実施しており、当時のシステム状態のままでは今後のDAU増加に耐えられず、MongoDBがボトルネックになることが分かったためSREでボトルネックの解消に取り組むことになりました。
MongoDBのボトルネックについて
負荷試験環境で、ある程度スループットを上げるとMongoDBのWiredTigerのWrite Ticketが5分おきに枯渇する現象が起きていました。
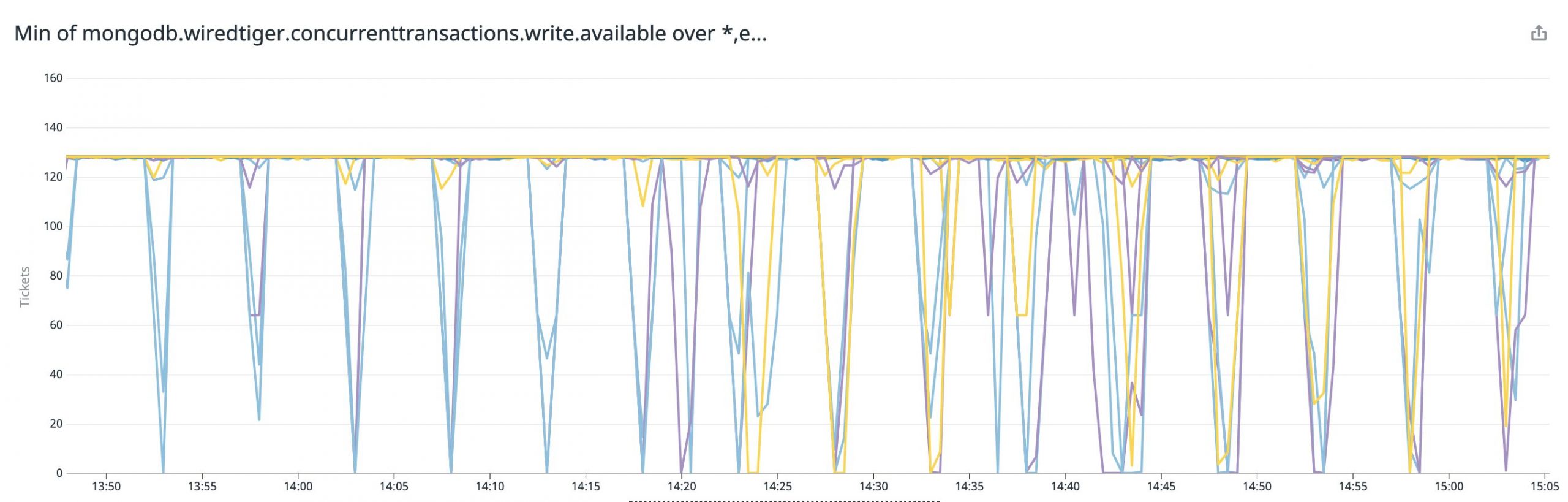
同じ周期でsystem.sessionsというコレクションへのupdateもスパイクしており、5分という間隔がメモリに保存されたlogical sessionsがsystem.sessionsコレクションに同期される間隔とも一致していたため、同期の際にWrite Ticketを消費していると予想していました。
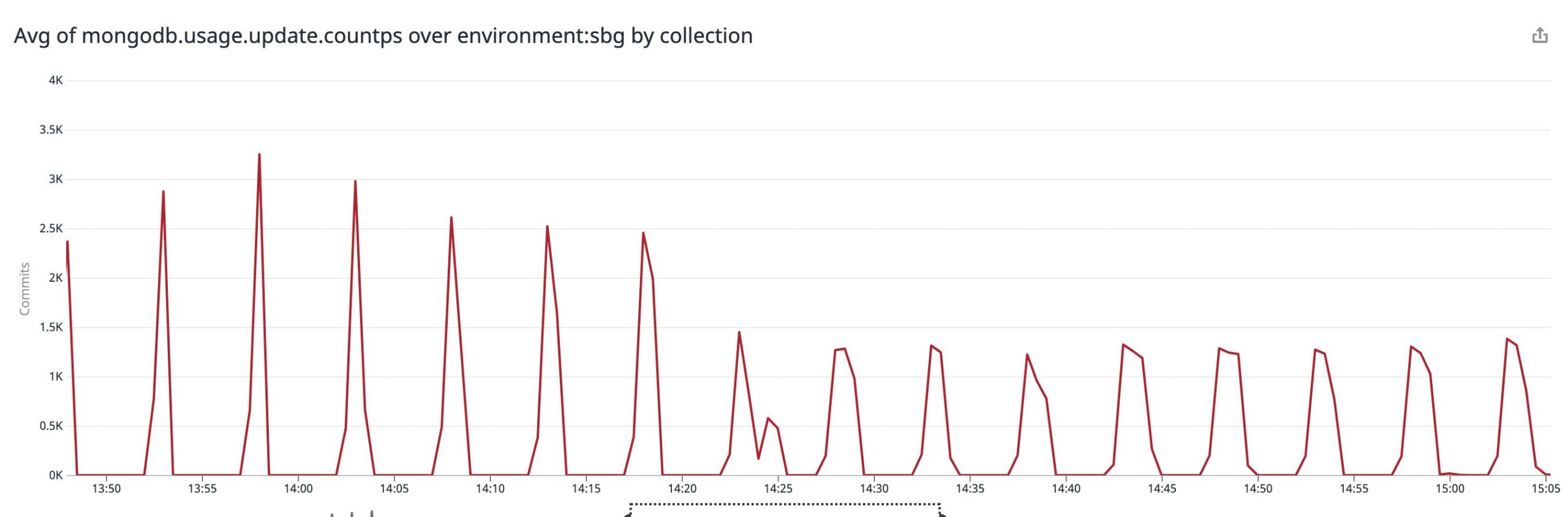
system.sessionsはMongoDB内部で使用されているコレクションであることと、5分おきにレイテンシが悪化するというバグissueも起票されていたため、MongoDBのメジャーバージョンアップでボトルネックが解消するかを検証することにしました。
また、スケールアウト・スケールアップを重ねたことで管理しづらくなっていた状態にも課題を感じていたので、Atlasへの移設も同時に進めることに決めました。これらをMongoDBボトルネック解消プロジェクトとして推進し、下記を実施しています。
- MongoDBのメジャーバージョンを3.6系から4.0系に上げる
- EC2 MongoDBからAtlasへの移設
- コア機能コレクションのdatabase分離
Atlasへの移設は管理・運用コストの削減を目的に実施しました。また、今回のようにMongoDBがボトルネックとなった場合にサポートケースで相談できることもメリットに感じています。
3つ目に記載したコア機能のdatabase分離は、MongoDB内のdatabaseの粒度での分割のことで、今後クラスターレベルでの分割などが必要になった場合に対応しやすくなることを期待して実施しました。
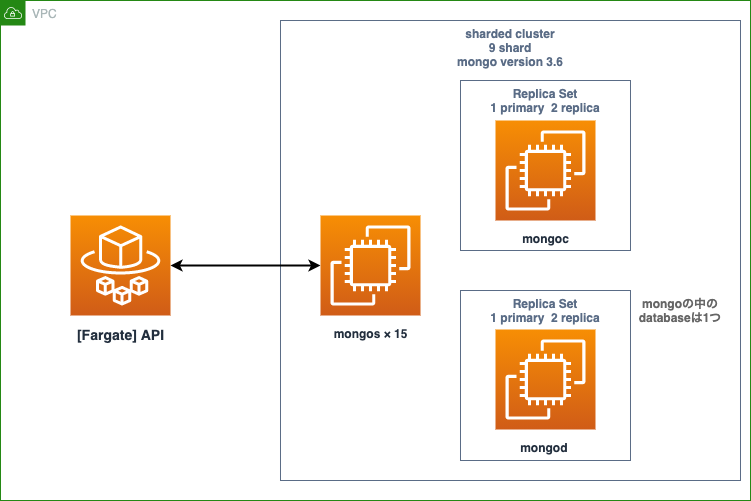
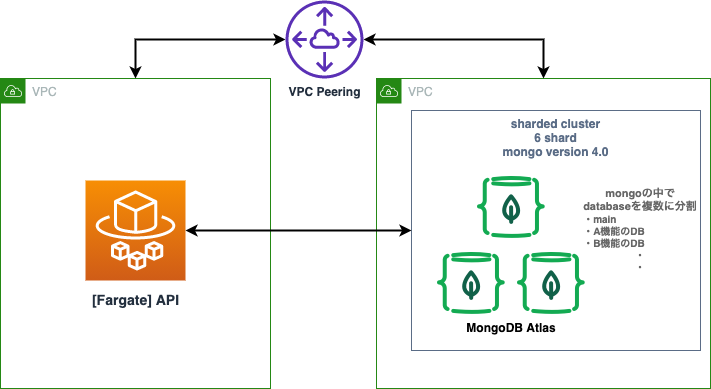
ざっくりですが移設前と移設後の構成図です。
負荷試験による検証
負荷試験を行い下記の検証を行いました。
- mongoのメジャーバージョンアップでボトルネックが解消されるか
- Atlasで十分なパフォーマンスが出るか
バージョンアップの検証はAtlasパターンで何か問題が起きるケースを想定して、EC2とAtlasの両方のパターンで検証を行いました。
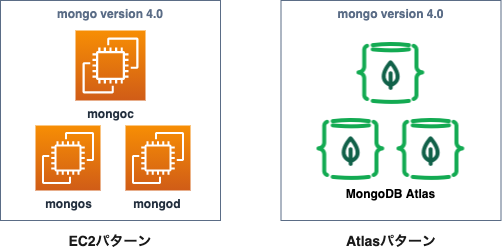
検証の結果、両方のパターンでボトルネックとなっていたWrite Ticketの枯渇が発生しなかったため、4.0系にバージョンを上げることでボトルネックが解消されると判断しています。
続いて、AtlasのインスタンススペックをEC2 Mongoのスペックと同程度にしてパフォーマンス測定を実施したのですが、当初は期待通りのパフォーマンスを出すことが出来ませんでした。
Atlasのサポートケースで相談しところ、Atlasは1インスタンスにmongodとmongosが同居する構成になっており、mongosも考慮してスペックを選択する必要があることが分かりました。
mongosも考慮してAtlasのスペック調整をしたところ、期待通りのパフォーマンスを確認できたためAtlasへの移設も可能と判断しています。
また、パフォーマンス検証の際にMongoクラスターのシャード数を減らしても問題がないことが分かったため、シャード数を9から6への削減も実施しています。
Atlasへの移設プランを計画する
検証でAtlasへ移設する判断ができたので、本番環境をAtlasへ移設するプランを計画し始めました。
まず、メンテナンスを実施するかの方針について話し合いを行い、今回はメンテナンスを実施する方針で進めることにしています。
メンテナンスを実施した方が作業がシンプルになることと、事業責任者の方からアクセスの少ない深夜から朝までの時間帯なら長期メンテナンスの実施を許可してもらえたことが理由です。
メンテナンスを実施できることになったので、作業としてはEC2 MongoからAtlasにデータをコピーしてアプリケーションの向き先を切り替えるだけなのですが、大きな課題となったのがデータコピーがメンテ時間内に収まるかどうかでした。今回、確保できていたメンテナンス時間は9時間ほどだったのですが、当時のMongoDBのデータサイズは約2TB、ドキュメント数は約75億あり、負荷試験環境のためのデータ準備の段階で9時間以上かかる想定ができていたため、データ移設の方法を工夫する必要がありました。
データの移設の方法として検討したのは下記の4パターンです
- Atlas LiveMigration を使用
- MongoDB CloudManagerのバックアップからリストア
- mongodump, mongorestore を使用
- サイズの大きなコレクションの過去データを事前にリストアしておく
最終的に4番目に記載したサイズの大きなコレクションの過去データを事前にリストアしておくの方法を選択しているのですが、まずは1~3の方法を採用しなかった理由について説明します。
Atlas LiveMigration
LiveMigrationはAtlas側の機能で、稼働中のMongoクラスターからAtlasクラスターに対してレプリケーションを張ってデータを同期できる機能です。おそらくこの方法が最もシンプルかつ、サービスを稼働させながら同期できるのでダウンタイムも短く出来ます。
ただ、VPCピアリングを使用することが出来ずインターネットを経由した通信をする必要があり、使用するためには既存のMongoDBクラスターの設定とインフラに手を加える必要がありました。タップルでは既存の環境に手を加えたくないという理由で使用しない判断をしています。
MongoDB CloudManagerのバックアップからリストア
MongoDB CloudManagerはAtlasと同じくMongoDB社が提供している製品で、タップルではMongoDBの定期的なバックアップにCloudManagerを使用していました。CloudManagerはAtlasクラスターへのリストアも可能だったので、CloudManagerからのリストア検証も行ったのですが、タップルの場合はCloudManagerからのリストアがエラーになってしまい成功しませんでした。
このエラーはMongoDBのconfigに下記を設定していたことが原因でした。
// mongod.conf
storage:
directoryPerDB: true
wiredTiger:
engineConfig:
directoryForIndexes: true
directoryPerDB, directoryForIndexes は両方ともMongoDBのデータディレクトリの構成に関係するオプションなのですが、CloudManagerはリストア先とバックアップの間でこの設定に差異があるとリストアできないという制約があり、Atlasで作成されるクラスターは false で設定されていました。
Atlas側の設定は変更できませんが、CloudManagerのサポートに連絡することで新規取得分からのバックアップ側で設定を変更してもらうことが可能です。ただ、その場合は既存のEC2 Mongoへのリストアが実行できなくなってしまいます。
タップルではこのリスクを許容できないという理由で使用しない判断をしています。
mongodump, mongorestore を使用
こちらはMongoDB公式ツールのmongodump, mongorestoreを使用して、メンテナンス中にEC2 Mongoからmongodumpでダンプを取得し、mongorestoreでAtlasにリストアする方法です。
単純な実行ではダンプとリストアの両方を合わせて20時間以上かかってしまったため、チューニングすることでの実行時間の短縮を目指し
- –numParallelCollectionsオプションで並列数を調整
- ツールを実行するインスタンスとAtlasのスペックを上げる
などを行いましたが、メンテナンス時間に収まる時間短縮が実現できなかったため採用できませんでした。
サイズの大きなコレクションの過去データを事前にリストアしておく
前の手順のチューニングの際に、mongodump, mongorestoreにかかる時間をコレクション毎に計測をしており、全体でかかるダンプ,リストア時間の85%ほどが6つのコレクションでかかっていることが分かっていました。そのため、6つのコレクションのみタイムスタンプを指定した過去分のデータを事前にAtlasにリストアしておき、メンテナンス当日は6つのコレクションの更新分とその他のコレクションのリストアのみ行う方法です。
前提として、タップルでは各ドキュメントに作成日時,更新日時のタイムスタンプを保存するフィールドを付けるようにしています。
- メンテナンス事前作業
- 6つのコレクションで過去分のデータをリストア
- メンテナンス当日作業
- 6つのコレクションで更新分のinsert, update, deleteを取り込む
- その他のコレクションをリストア
mongodumpは–queryオプションで条件に合ったデータのみのダンプを取得できるので、作成日時が過去のドキュメントを指定してダンプを取得できます。
メンテナンス当日のinsert, updateの取り込みはmongoexport, mongoimportのupsertモードを使用しました。mongoimportのupsertモードは、リストア先にドキュメントが無ければinsert、存在する場合はupdateが実行されるので、mongoimportでinsertとupdateを取り込むことが出来ます。
deleteを取り込むためには削除されたドキュメントの_idを知っておく必要があるため、6つのコレクションのドキュメントが削除された際に、_idと削除日時を記録する実装をアプリケーション側に追加しました。
そのデータを元にmongoシェルでdeleteコマンドを発行することで取り込みます。
オペレーションが複雑になってしまいますが、この方法でメンテナンス時間内にリストアできる目処がたったため、この方法を採用しました。
ドキュメント数が多いコレクションの事前データの投入方式について
メンテナンス時間が最大でも9時間ほど(深夜から朝まで)を予定していたため、その時間内にデータの移設を完了するために事前に下記検証と確認を実施しました。
- 本番の12時間分のデータを活用してmongoexport, mongoimport, deleteクエリーの実行時間の測定
- mongoexport, mongoimportでタイムスタンプなどBSONの型が崩れないかの確認
- 参考URL: https://docs.mongodb.com/v3.6/reference/mongodb-extended-json/
mongoexportコマンド例
mongoexport [DB接続情報] --readPreference primary -d [データーベース名] -c [コレクション名] -o [エクスポートするjsonのファイル名].json --query '[クエリ]'
DB接続情報
--host [mongosのhostname]
クエリ
{\"[フィールド名]\": {\"\$gte\" : ISODate(\"[日時]\"), \"\$lte\" : ISODate(\"[日時]\")}}
日時例
2021-01-26T00:00:00+09:00
参考URL
https://docs.mongodb.com/database-tools/mongoexport/#std-option-mongoexport.–readPreference
mongoimportコマンド例
EC2 MongoDBとAtlasで接続情報が異なるのでそれぞれコマンドを用意しました。
EC2 MongoDB用
mongoimport [DB接続情報] --numInsertionWorkers=8 --writeConcern 1 -d [データーベース名] -c [コレクション名] --file [mongoexportしたjsonファイル]
DB接続情報
--host [mongosのhostname]
Atlas用
mongoimport [DB接続情報] --numInsertionWorkers=8 -d [データーベース名] -c [コレクション名] --file [mongoexportしたjsonファイル]
DB接続情報
--uri mongodb+srv://[ユーザー名]:[パスワード]@[クラスター名xxxx.xxxx.mongodb.net]/?w=1
コマンドのオプション
- –numInsertionWorkers:を指定するとインポート速度が向上する可能性があります。
- –mode=upsert:更新モードでimportする
- –writeConcern 1:レプリカセットのプライマリに伝播のみ確認
参考URL
https://docs.mongodb.com/manual/reference/write-concern/
https://docs.mongodb.com/database-tools/mongoimport/
deleteコマンド例
mongo [DB接続情報] --eval "db.[コレクション名].remove({\"_id\": [削除したいID]},1)"EC2 MongoDB用
DB接続情報
--host ドメイン -u [ユーザー名] -p [パスワード] -authenticationDatabase adminAtlas用
DB接続情報
mongodb+srv://[クラスター名xxxx.xxxx.mongodb.net]/[データベース名] -u [ユーザー名] -p [パスワード] -authenticationDatabase admin約12時間分のデータを活用して、単純に移設の検証を実施すると問題が生じました。
- mongoimportコマンドをそのまま実行(300万レコード)
- 全然進捗が上がらず6hぐらいの見込み
- deleteクエリーの実行
- 実行時間 60m
そこで、dstat,top,vmstatを活用しボトルネックの調査を実施しました。
- CPUなのかネットワーク帯域なのかdiskのIOなのかMemoryなのかその他なのか
- Amazon EC2のCPUスペックを上げても速度はかわらない
その結果、mongoexpotしたjsonファイルをmongoimport時にBSON形式に変換する処理に時間がかかっていることがわかりました。
exportしたjsonファイルを一定の行数(5万行程)に分割し、mongoimportを複数並列で実行することで速度を向上できることが分かりました。基本的に分割数が多くなればなるほど早くなるので、インスタンスのCPUスペックを上げれば調整可能です。
工夫した結果、下記のように大幅に実行時間を削減することができした。
- mongoimport 全然進捗が上がらず6hぐらいの見込み -> 16m
- deleteのクエリー 60m -> 10m
また、今回はスケジュールとの兼ね合いで検証と利用しませんでしたが、
bulk.insert()やdeleteMany()も活用するとより改善できるかもしれません。
参考URL
https://docs.mongodb.com/manual/reference/method/Bulk.insert/
https://docs.mongodb.com/drivers/node/usage-examples/deleteMany/
リストアデータの整合性確認について
リストアしたデータはコレクション毎に下記を比較しての整合性を確認するようにしました。
- ドキュメント数
- updateを取り込んだドキュメントのハッシュ値
6つのコレクションのみupdateの取り込みも行っているので、mongoexportで既存環境と移設後の環境からupdateがあったドキュメントをjsonで出力し、それぞれのmd5hashコマンドの結果を比較することで正しくupdateが取り込めているかを確認しました。
また余談ですが、差分が生じたときのために、exportしたjsonファイルを比較するスクリプトも別途用意していました。
mongoexportする特定の日時範囲の指定は下記のように広めに指定しました。
- メンテナンス準備時のmongodumpした日付より前から
- メンテナンス中に入ってDBの更新がなくなったときの日付まで
※exportしたファイルのデータはmd5hashする前にsortする必要があります。
メンテナンス当日の構成図
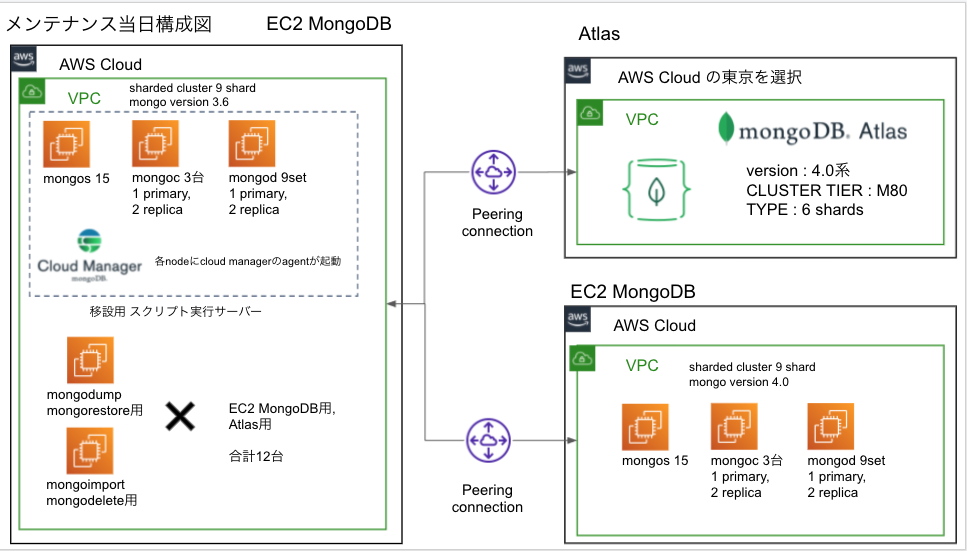
メンテナンス時の構成は上図のように、EC2 MongoDBとAtlasの2つの移設先があります。
本番のデータベースを既存の開発/準本番/本番が同居しているアカウントから分離したいこともあり、別アカウント上で保険のプランとしてEC2 MongoDBを用意し、致命的な問題が生じない限り基本的にはAtlasへ移設する前提で進めつつ、手順書レベルで両方にデータ移設を実施しました。
構成について詳細を記載
- AWS環境はそれぞれ別アカウントを利用
- Atlasは Cloud Provider & Region を作成時に選択することができるので、Amazonを選択して同じリージョンを選択
- 移設対象のアカウントとそれぞれVPC Peeringを実施
- mongodump,mongorestoreなど移設用のスクリプトを叩くサーバを用意
- スクリプトを実行する並列数の確保とリストア先毎に専用のインスタンスにするために、合計12台ほど用意
- mongodump,mongorestore用 3台 x 2パターン(Atlas, MongoDB EC2用)
- mongoexport,mongoimport用 3台 x 2パターン(Atlas, MongoDB EC2用)
- スクリプトを実行する並列数の確保とリストア先毎に専用のインスタンスにするために、合計12台ほど用意
- 別環境へ誤って実行するのを防ぐためセキュリティグループでIP制限を実施
メンテナンス当日への準備
メンテナンス当日に向けてメンテナンス手順書の作成とリハーサルの実施を行いました。
メンテナンス手順書はGoogleスプレッドシートで作成しています。
工夫しているポイントは下記です。
- 当日担当者が来れない場合も想定し、コマンドをそのまま実行できるように手順書を用意
- 関係者が多いためスケジュールの要約を用意し、作業終了ごとに時間を記載し共有。

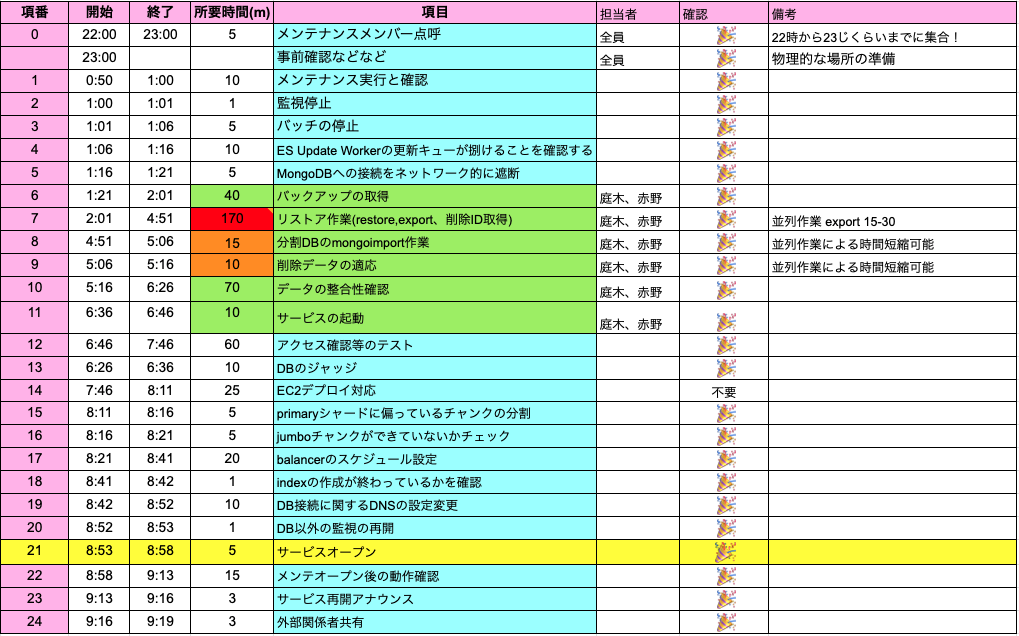
持ち物も参考までに載せておきます。
- PC
- PC 充電器
- ホワイトボード
- 印刷した手順書 3-5部(印刷)
- 手順書をホワイトボードに貼るための磁石
- 目薬 (深夜対応なので意外と大事です!)
- モニター
- モニター変換機器
さらに、メンテナンス当日は下記についても工夫しました。
- 手順書は印刷して、ホワイトボードにはり、メンバーが即座に見えるようにし、作業が完了したらマーカーで線を引いてどこまでタスクが進んでいるか記載
- 長時間のメンテナンスなので、レッドブル、ガム、甘いもの等も買い出しして楽しく元気にやることを心がけた
- 情報をスムーズにやり取りするために、座席が遠い場合は近くに集合
- オフィス等で人数も増えると遠くなったり、階が違ったりすると動作確認した際の情報がすぐに確認ができません
- 移設メンテナンスを数十回経験していますが、これは本当に大事です
メンテナンス当日のトラブル
メンテナンス当日にトラブルが2点生じて対応したので紹介します。
一部のコレクションでmongorestoreコマンドが失敗した
mongorestoreコマンドを実行した際に一部のコレクションで下記のようなエラーが発生しました。
createIndex error:
"The field 'safe' is not valid for an index specification."
原因はmongodumpで生成されるmetadata.jsonに不正なオプションが入っていたことでした。
具体的には、metadata.jsonのindex情報の中に “safe”:null というオプションが入っていたのですが、Mongo側にはこのようなオプションは存在しないためエラーになっていました。
下記はmetadata.jsonから抜粋した例です。
{
"indexes":[
{
"v":1,
"key":{
"id":1.0
},
"name":"id_1",
"ns":"hoge.fuga",
"background":true,
"safe":null
},
}
metadata.jsonから “safe”:null を取り除くことでエラーを回避することができたので、全てのmetadata.jsonを修正してから再実行で対応しました。
そもそも、metadata.jsonに “safe”:null が入ってしまっていたのは、使用しているmongooseというライブラリに問題があったようです。こちらに関してはissueが上がっていました。
なぜリハーサルで発見できなかったのか
リハーサルではMongoDB CloudManagerで取得していたバックアップからリストアしてリハーサル環境を構築していたのですが、リストア時にCloudManager側で “safe”:null が取り除かれていたため、発見することができませんでした。
Atlasへのリストア整合性の確認でドキュメントの数が合わなかった
Atlasへのリストアデータの整合性確認でいくつかのコレクションのドキュメント数が合わない問題がありました。
スピードを向上させるためにmongoimportを同時に250個ほど実行していたのですが、その中のいくつかで下記のようなエラーが起きていたことが原因でした。
Wed Mar 10 05:14:53 JST 2021
2021-03-10T05:15:09.642+0900 error parsing command line options: error parsing uri (mongodb+srv://xxxx:xxxxxxxxxx@prd-cluster.xxxxxx.mongodb.net/xxxxx?w=1): lookup _mongodb._tcp.prd-cluster.xxxxx.mongodb.net on xxx.xxx.xxx.xxx:53: no such host
2021-03-10T05:15:09.642+0900 try 'mongoimport --help' for more information
接続先をmongodb+srv方式で指定して実行していたのですが、一度に多くのリクエストをした場合DNSでエラーになってしまうようでした。
作業ログから失敗した実行を特定し、再実行することで対応して解決しました。
上記トラブルもありましたが、8時間ほどでメンテナンスを完了することができました。
問題が起きた際には、メンテ手順を進めるチームと問題を解消するチームに分かれて対応することで、スムーズに進行させることができていたと思います。

最後に
Atlasへの移設は無事に完了し、目的としていたMongoDBのボトルネックの解消と管理コストの削減を実現できました。移設から3ヶ月ほど運用していますが特に問題も起きていないので、移設して良かったと感じています。
移設への障壁やトラブルがたくさんありましたが、多くの方からサポートを受けながら赤野・庭木チームでなんとか乗り切ることができました。
一つの目標に対して、毎朝の朝会で問題や完了したこと、直近やることや気になることを共有し、こまめに意思疎通を図ったことで同じ方向を向けたことが良かったと思います。
今後もSREチームで協力して、サービス成長に対するシステムボトルネックの排除を続けていきます。