
AI事業本部 小売DXの黒崎(@kuro_m88)です。
Snowflakeの新機能 “Snowpark” を実際に動かし、SnowparkとVirtual Warehouseの関係について検証してみたのでご紹介します。
Snowparkとは?
SnowparkはSnowflakeがSnowflake Summit 2021で発表した新しいデータの処理方法です。
Welcome to Snowpark: New Data Programmability for the Data Cloud
Scalaでデータ処理のコードを書くと、それがSnowflakeと統合されて実行されます。Apache Sparkに似た記法でコードが書けるのが特徴的です。
Apache Sparkは広告配信プラットフォームのDynalystのログ集計基盤に採用したことがあり、使い慣れたフレームワークでした。
そのような背景もあり、Snowparkどのようなしくみで動くのか気になったため検証してみました。
ユーザが書いたコードがSnowflakeのVirtual Warehouseで動くという点も興味深く、Snowparkを通じてVirtual Warehouseの構成やワークロードがどう扱われるのかについても探っていきたいと思います。
DynalystでのApache Sparkの活用事例は以下の記事をご覧ください。
Snowparkのアーキテクチャ
Snowparkの情報は現状だとドキュメントが一番詳しそうです。
DOCS » DEVELOPING APPLICATIONS WITH SNOWFLAKE » SNOWPARK
触ってみると仕組みだったりユースケースのイメージが湧くのですが、触ってみる前はもっと複雑なものを想像していました。
正直なところ、想像以上にシンプルにできていて拍子抜けしました。
Snowparkの仕組みをひとことで表すと、「UDFのコンパイラ+アップローダーとSQL生成ライブラリ」かなと思います。
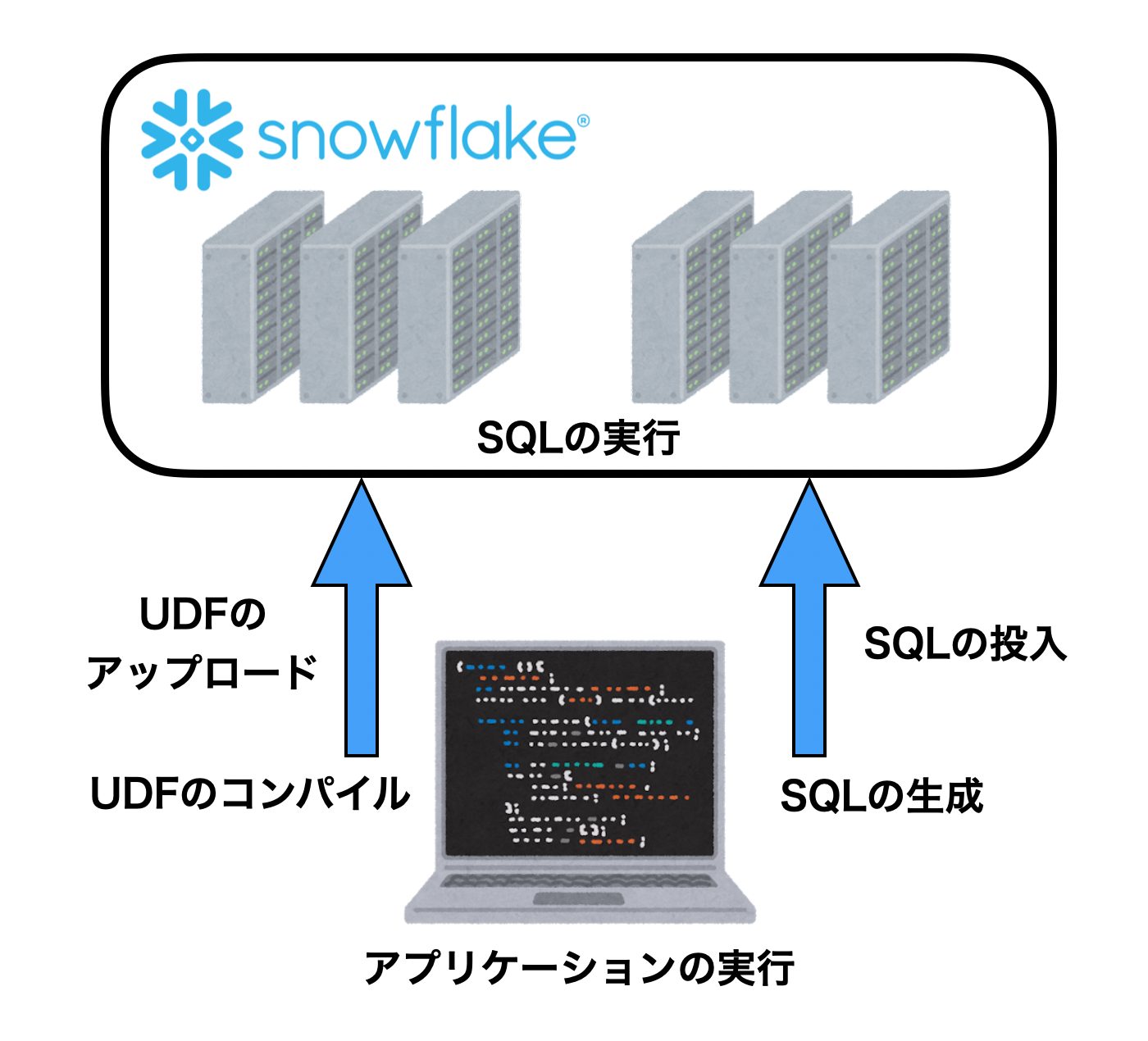
SnowparkからSnowflakeのVirtual Warehouseの構成を推測する
今回の実験で用いたコードはGithubにアップロードしました。
github.com/kurochan/snowpark-blog-20210810
Snowparkの正しい使い方は公式ドキュメントを参考にしてください。Apache Sparkに慣れている方であれば違和感なくコードが書けると思います。
今回はアプリケーションのログからSnowparkの動作を観察しつつ、Virtual Warehouseの挙動を探っていきます。
セッションの生成
SparkでいうところのSpark Sessionのようなものです。このSessionを通じてSnowflakeとデータのやりとりや処理の命令を行います。
def createSession(): Session = {
val configs = Map (
"URL" -> "https://ab12345.ap-northeast-1.aws.snowflakecomputing.com:443",
"USER" -> "SNOWPARK_TEST",
"PASSWORD" -> "password here",
"ROLE" -> "SYSADMIN",
"WAREHOUSE" -> "COMPUTE_WH",
"DB" -> "SANDBOX",
"SCHEMA" -> "PUBLIC"
)
Session.builder.configs(configs).create
}
UDFたち
固定の乱数を返却するUDF
UDFの定義は、関数を定義したあとに、udf()で囲うだけです。
Scalaで書いた関数が簡単にSnowparkのUDFとして利用することができるようになり、このUDFはSnowflake上で動作します。
今回はグローバルな変数にランダムな固定値を入れることで、UDFの実行環境がインスタンス化されるごとに一意な値を返すようにしています。
これによってUDFの実行が複数のマシン(もしくはインスタンス)に分散されて実行された場合に、マシンごとにユニークなIDのようなものを付与されることを期待します。
val randomId: String = scala.util.Random.alphanumeric.take(10).mkString
def getRandomId(s: String): String = {
randomId
}
val randomIdUdf = udf(getRandomId _)
使わない引数を1つ取っている理由は、引数なしのUDFを作成すると実行時にエラーが出てしまったためです。
1を加算して返すUDF
グローバルな変数にカウンタをもたせ、1を加算して返却するだけのUDFです。
マシン内でシングルスレッドで処理がされているのであればincrementAndGetUdfが返す値は単調増加で、オーバーフローしない限り同じ値を返すことはないはずです。
もしもマルチスレッドで実行される場合、この関数はスレッドセーフではないことから、同じ値が重複してしまう可能性があります。
具体的にはcounter += 1という部分の処理がよくない実装になっています。
countに1を足した結果再代入するまでの瞬間に1を足す前の値を別のスレッドが参照してしまう可能性があります。
こういった処理をする場合は一般的にはAtomicIntegerを使うべきです。
今回はあえてスレッドセーフではない実装を使い、確率的に値が重複してしまう現象を利用して、マシンあたり複数のインスタンスを生成しているのか(マルチプロセス)、インスタンスを共有して実行しているのか(マルチスレッド)を推測してみます。マルチスレッドのほうがメモリの利用効率はよさそうですね。
var counter = 0
def incrementAndGet(s: String): Long = {
counter += 1
counter
}
val incrementAndGetUdf = udf(incrementAndGet _)
例えば、4スレッドで実行している合、十分な回数同時にincrementAndGetUdfを呼び出せば同じ値の重複が4つ現れるはずです。
CPUのコア数を取得するUDF
JVMが利用可能なCPUのコア数を取得します。
def getProcessors(s: String): Long = {
Runtime.getRuntime.availableProcessors()
}
val getProcessorsUdf = udf(getProcessors _)
メモリの最大容量を取得するUDF
JVMが利用可能なメモリの最大容量を取得します。
def getMemory(s: String): Long = {
Runtime.getRuntime.maxMemory()
}
val getMemoryUdf = udf(getMemory _)
メモリの現在の使用量を取得するUDF
JVMが利用しているメモリの容量を取得します。
今回のアプリケーションは大量にメモリを消費するようなコードは含まれていないため、UDFのメモリ使用量のオーバーヘッドが推測できそうです。
def getCurrentMemory(s: String): Long = {
Runtime.getRuntime.totalMemory()
}
val getCurrentMemoryUdf = udf(getCurrentMemory _)
main関数
処理の本体です。
ほとんどApache Sparkと同じような雰囲気で記述ができていることがわかります。
val table = session.table("test_log").limit(1000000)
という行は、適当に用意した100万行以上あるテーブルを参照しています。
後段の処理でも、このテーブルの内容は全く使っていません。
何かしらのテーブルの処理が伴わないと、Snowflake側の実行計画の最適化によりVirtual Warehouseがあまり利用されなかったので、データを処理しているように見せかけるためにテーブルを参照させました。
処理の内容としては、先ほど定義したUDFを利用して、
- 100万回ランダム文字列の取得や整数のインクリメント、CPUやメモリの情報を取得
- それらをンダム文字列ごとに集計、カウンタの値の重複を数え上げる
- インスタンスごとのCPUやメモリ等のマシンスペックを表示する
といった流れです。
def main(args: Array[String]): Unit = {
val session = createSession()
val table = session.table("test_log").limit(1000000)
val data = table.select(
randomIdUdf(col("name")).as("static_id"),
incrementAndGetUdf(col("name")).as("counter_value"),
getProcessorsUdf(col("name")).as("processors"),
getMemoryUdf(col("name")).as("memory"),
getCurrentMemoryUdf(col("name")).as("current_memory"),
)
val localResult = data.groupBy(col("static_id"), col("counter_value"))
.agg(
min(col("processors")).as("min_processors"),
max(col("processors")).as("max_processors"),
(min(col("memory"))).as("min_memory"),
(max(col("memory"))).as("max_memory"),
(max(col("current_memory"))).as("current_memory"),
count(lit(1)).as("count"),
)
val clusterResult = localResult.groupBy(col("static_id"))
.agg(
min(col("min_processors")).as("min_processors"),
max(col("max_processors")).as("max_processors"),
(min(col("min_memory")) / 1024 / 1024 / 1024).as("min_memory"),
(max(col("max_memory")) / 1024 / 1024 / 1024).as("max_memory"),
(max(col("current_memory")) / 1024 / 1024 / 1024).as("current_memory"),
max(col("count")).as("conflict_count"),
sum(col("count")).as("exec_count")
)
.sort(col("exec_count").desc)
clusterResult.show(100)
}
実行してみる
sbt runと打つだけでコンパイルと実行ができます。
$ sbt run
[info] welcome to sbt 1.5.4 (Amazon.com Inc. Java 1.8.0_272)
[info] loading project definition from workspace/snowpark-test/project
[info] loading settings for project root from build.sbt ...
[info] set current project to snowpark-test (in build file:workspace/snowpark-test/)
[info] running org.kurochan.snowpark_test.Main
ログを眺める
ログを眺めていきましょう。
UDFをアップロードするためのtemporary stageが生成されています
[run-main-0] INFO (Logging.scala:22) - Execute query [queryID: 12345678-0000-123b-0000-1223000abcde] create temporary stage if not exists "SANDBOX"."PUBLIC".snowSession_12345678901234
UDFの実行に依存するライブラリやコード全体がアップロードされています。
同時にUDF自体もコンパイルし、アップロードしているようです。
[snowpark-2] INFO (Logging.scala:22) - Uploading file file:workspace/snowpark-test/target/bg-jobs/sbt_3ebdd0b2/job-1/target/c88ff8c1/39e5aac4/snowpark-test_2.12-0.1.0-SNAPSHOT.jar to stage @"SANDBOX"."PUBLIC".snowSession_12345678901234
[snowpark-1] INFO (Logging.scala:22) - Uploading file file:workspace/snowpark-test/target/bg-jobs/sbt_3ebdd0b2/target/9b598b89/f74dd7dd/snowpark-0.6.0.jar to stage @"SANDBOX"."PUBLIC".snowSession_12345678901234
[snowpark-3] INFO (Logging.scala:22) - Compiling UDF code
[snowpark-3] INFO (Logging.scala:22) - Finished Compiling UDF code in 324 ms
[snowpark-3] INFO (Logging.scala:22) - Uploading UDF jar to stage @"SANDBOX"."PUBLIC".snowSession_12345678901234
[snowpark-3] INFO (Logging.scala:22) - Finished Uploading UDF jar to stage @"SANDBOX"."PUBLIC".snowSession_12345678901234 in 921 ms
[snowpark-2] INFO (Logging.scala:22) - Finished Uploading file file:workspace/snowpark-test/target/bg-jobs/sbt_3ebdd0b2/job-1/target/c88ff8c1/39e5aac4/snowpark-test_2.12-0.1.0-SNAPSHOT.jar to stage @"SANDBOX"."PUBLIC".snowSession_12345678901234 in 1290 ms
[snowpark-1] INFO (Logging.scala:22) - Finished Uploading file file:workspace/snowpark-test/target/bg-jobs/sbt_3ebdd0b2/target/9b598b89/f74dd7dd/snowpark-0.6.0.jar to stage @"SANDBOX"."PUBLIC".snowSession_12345678901234 in 1467 ms
UDFはSnowflakeのJava UDFとして扱われるようですね。
生成されたクエリ
こんな感じのクエリが生成されたようです。
生のSQLをテキストで貼りたかったのですが、このブログのファイアウォールがこの記事をブロックしてしまうため、仕方なく画像で張り付けています。
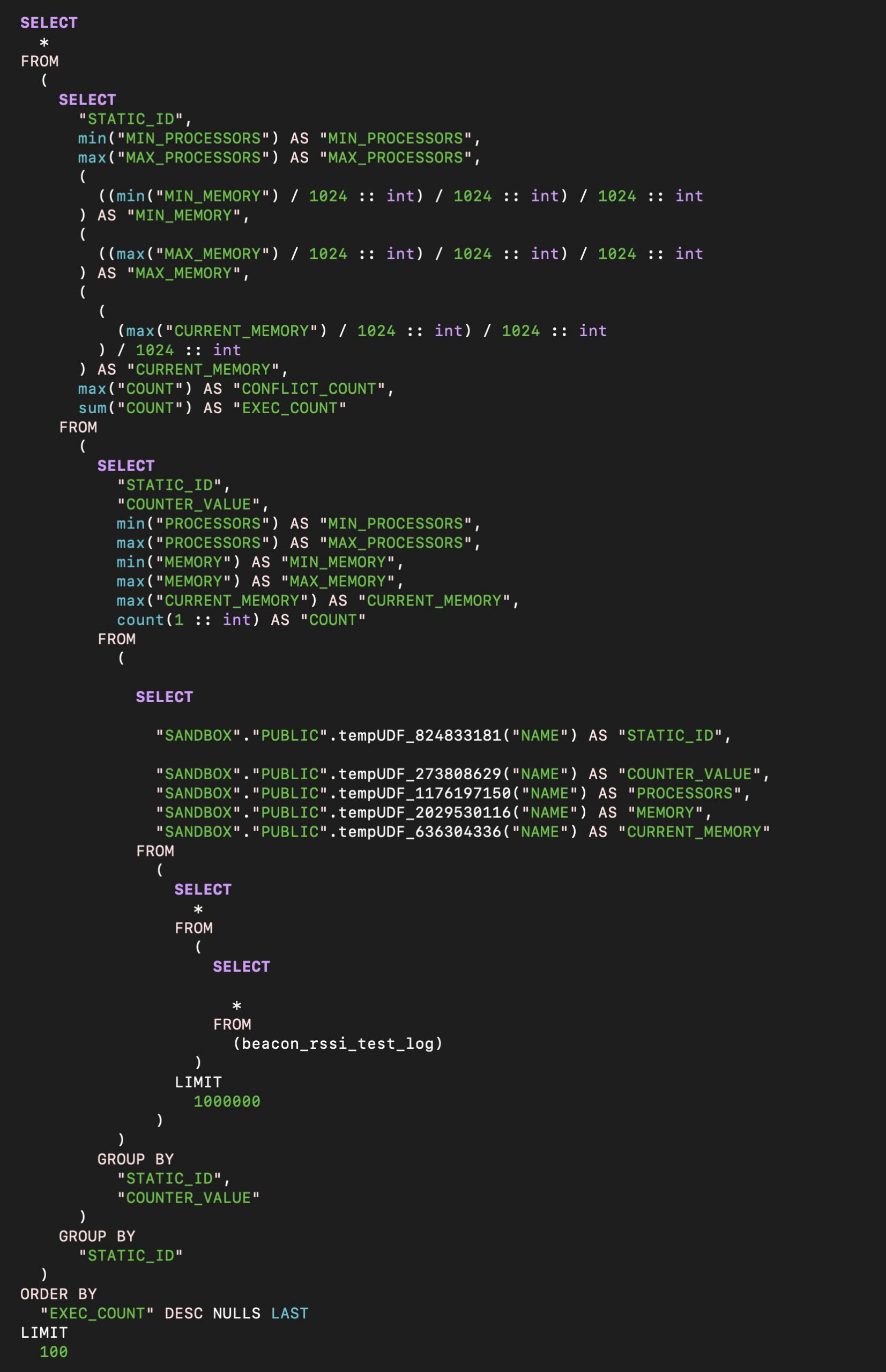
Snowparkは特別なSnowparkの処理用に特別な環境が用意されているわけではなく、最終的には普通のSnowflakeのSQLが生成されていることがわかります。独自の処理はJava UDFとして呼び出されていることもわかります。
SnowparkはApache Sparkのようにワーカーノードが用意されるものかと想像していたのですが、既存のSnowflakeに機能拡張することなく実現されているのがすごいですね。
ここまでの挙動を見て、Snowparkの実態はUDFのコンパイラ+アップローダーとSQL生成ライブラリと言ってもよいかなと思いました。
実行結果
ウェアハウスのサイズをいくつか変えて実行してみたところ、非常にきれいな結果が出ました。
XS
--------------------------------------------------------------------------------------------------------------------------------------------
|"STATIC_ID" |"MIN_PROCESSORS" |"MAX_PROCESSORS" |"MIN_MEMORY" |"MAX_MEMORY" |"CURRENT_MEMORY" |"CONFLICT_COUNT" |"EXEC_COUNT" |
--------------------------------------------------------------------------------------------------------------------------------------------
|CMTYEc52NL |8 |8 |3.000000000000 |3.000000000000 |0.244140625000 |4 |1000000 |
--------------------------------------------------------------------------------------------------------------------------------------------S
--------------------------------------------------------------------------------------------------------------------------------------------
|"STATIC_ID" |"MIN_PROCESSORS" |"MAX_PROCESSORS" |"MIN_MEMORY" |"MAX_MEMORY" |"CURRENT_MEMORY" |"CONFLICT_COUNT" |"EXEC_COUNT" |
--------------------------------------------------------------------------------------------------------------------------------------------
|KkPVK9EUgp |8 |8 |3.000000000000 |3.000000000000 |0.224609375000 |4 |568215 |
|dFfeqXBkKl |8 |8 |3.000000000000 |3.000000000000 |0.216796875000 |4 |431785 |
--------------------------------------------------------------------------------------------------------------------------------------------L
--------------------------------------------------------------------------------------------------------------------------------------------
|"STATIC_ID" |"MIN_PROCESSORS" |"MAX_PROCESSORS" |"MIN_MEMORY" |"MAX_MEMORY" |"CURRENT_MEMORY" |"CONFLICT_COUNT" |"EXEC_COUNT" |
--------------------------------------------------------------------------------------------------------------------------------------------
|q1h13AKykk |8 |8 |3.000000000000 |3.000000000000 |0.150390625000 |4 |201591 |
|LEJ8h3eyEv |8 |8 |3.000000000000 |3.000000000000 |0.150390625000 |4 |152285 |
|LHfFfKMhoC |8 |8 |3.000000000000 |3.000000000000 |0.180664062500 |3 |127785 |
|njroXeETBp |8 |8 |3.000000000000 |3.000000000000 |0.150390625000 |4 |124523 |
|TX1IpHTGyH |8 |8 |3.000000000000 |3.000000000000 |0.125000000000 |4 |115819 |
|52fgt3cGIF |8 |8 |3.000000000000 |3.000000000000 |0.125000000000 |4 |100781 |
|fZb563i8Yi |8 |8 |3.000000000000 |3.000000000000 |0.125000000000 |4 |97993 |
|Ep7n80QVX6 |8 |8 |3.000000000000 |3.000000000000 |0.125000000000 |4 |79223 |
--------------------------------------------------------------------------------------------------------------------------------------------この結果から、Virtual Warehouseの消費クレジット数と同じだけのマシン(のようなもの)が存在することが推測できます。(XS: 1クレット, S: 2クレジット, L: 8クレジット)
Virtual Warehouseのサイズを変えてもマシン1台あたりの性能はかわらず、台数を増やすことで処理性能をスケールさせるようになっているのでしょうか。どのインスタンスもCPUは8コア、メモリは3GBの割り当てで、4スレッド使うようになっているようです。
Snowparkの実行環境はサンドボックスになっており、自前でネットワークなどを通じて外部とのデータの入出力はできませんでした。またデータの入出力はSnowflake側が行うことから、UDFはCPU intensiveになることが想像できます。
JVMから見えるCPUのコア数はハイパースレッディングが有効になっていて8コア見えていて、CPU intensiveな処理をするには同時実行は4スレッドが一番性能が出るのかな?とも想像しました。
Java UDFのメモリは3GB程度まで使えて、オーバーヘッドは120〜250MB程度と思っておけばよさそうです。
疑問
今回Snowparkを試したのはAWS環境でした。AWSのEC2インスタンスのCPUとメモリの比重で一番メモリの比重が少ないのはc5系のインスタンスで、c5.2xlargeが8vCPUメモリ16GBです。
となるとUDFにメモリをもっと割り当てても良いような気もするのですが、なにか理由があるのでしょうか。このあたりは想像がつきませんでした。
追記(2021/08/12)
Snowflakeの本橋さんより情報を頂きました。
あくまでも現段階はこのリソース制限で、今後変わる可能性もあるのでundocumentedということのようでした。
ちなみに、現時点では、1ノード上のJVM全体での合計ヒープサイズの最大は3GBとなっていますが、変更する可能性もあるので文書化していないとのことです。#SnowflakeDB
— Mineaki Motohashi (@mmotohas) August 11, 2021
まとめ
Snowparkの仕組みをログから眺めつつ、Snowparkを使ってSnowflakeのVirtual Warehouseの構成を推測してみました。
今回の検証では、本来想定されているような使い方はしていませんが、その過程でSnowparkの仕組みや、SnowflakeのVirtual Warehouseへの理解が深まった気がします。
SnowparkはまだPublic Preview段階ですが、SQLだけでは扱いづらかったユースケースにも対応できるので、今後の業務に役立てたいと思います。