
(CyberAgent Developers Advent Calendar 2021 – Adventar 2日目の記事です。)
メリークリスマス!
CyberAgent AI Labの尾崎安範です。
普段はロボットとのインタラクションやそのためのコンピュータビジョンについて研究しています。
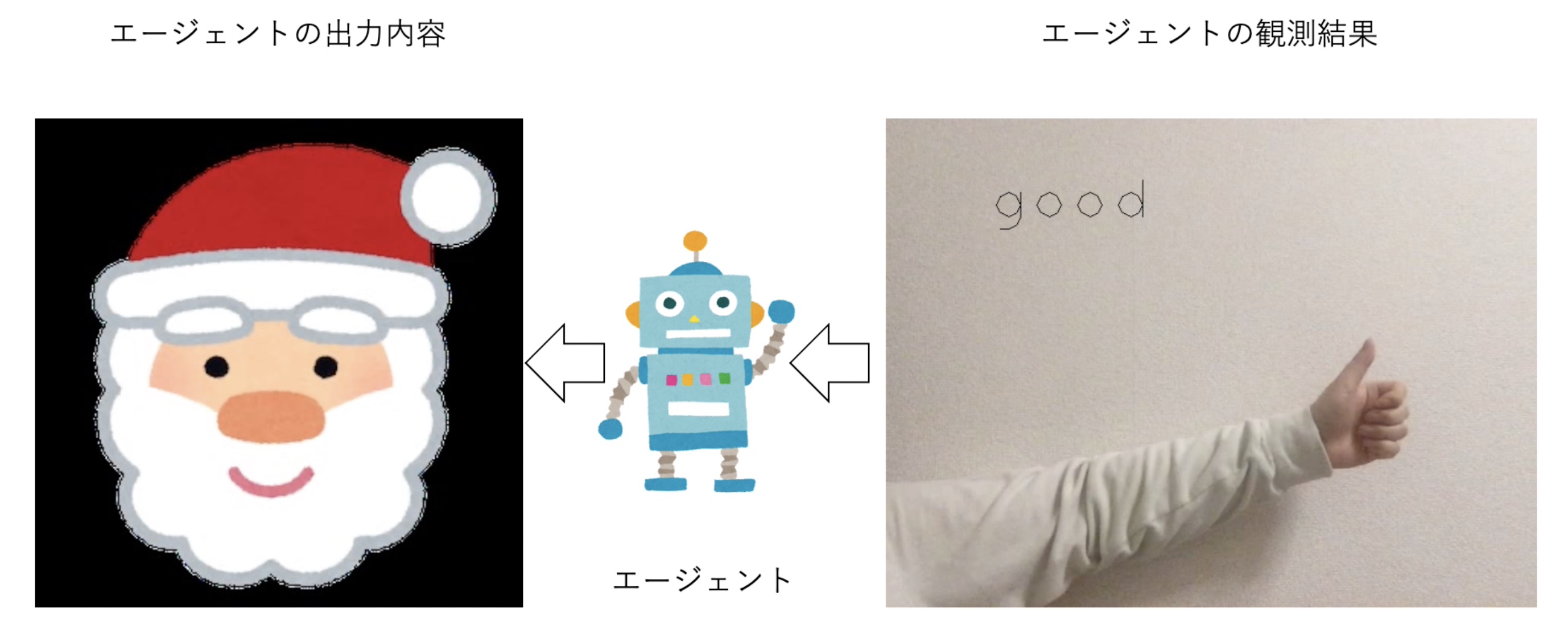
今回は「いいね👍で始めるインタラクティブ強化学習入門」というふわっとしたタイトルですが、具体的には「ユーザが最もいいねと思っている画像を自分から探し出すモノの作り方」について説明します。例えば、ディスプレイに上の図左のような画像を表示しているとき、カメラから上の図右のようにいいねというハンドサインが読み取られたら、なるべくそのいいねされた画像を表示してくれるようにしてくれるモノを作ります。
そのモノとは一体何なんでしょうか。
どうやってそんなモノを作り出すのでしょうか。
詳しく見ていきましょう。
なお、本記事の対象者は少なくとも強化学習とその一種であるQ学習はわかっているものとしています。強化学習がわからない場合はこちら(外部)を、Q学習がわからない場合、こちら(外部)を読むとわかりやすいでしょう。
背景
まず、モノについてもうちょっと具体的にしてみましょう。今回対象とするモノはエージェントと呼ばれるモノです。エージェントとは何かしらの入力が与えられたときに何かしらの出力を返すモノです。このエージェントに何かしらを逐次入力したときに何を返すべきか考える問題を逐次的意思決定問題と呼びます。
今回は、画像を入力すると画像を返すエージェントについて考え、そのエージェントがどんな画像を返すべきか考える問題を説明していきます。
実世界インタラクション強化学習について
強化学習とはこの逐次的意思決定問題を解く手法の代表例です。強化学習ではエージェントが環境の状態に応じた能動的に行動して報酬を得ながら学習することで問題を解いていきます。
それではこの強化学習を実世界において利用したいと考えます。しかし、冷静に考えてみると、例えば、実世界にある「いいね」というハンドサインはどのようにエージェントは知れば良いのでしょうか。カメラから入力された画像には手以外のさまざまな情報が混じっています。解決策は色々ありますが、ここでは状態を直接知るということは諦めて、カメラから入力された画像、すなわち観測結果otから状態を間接的に推定して行動を決定することにします。さらにエージェントの概念を拡張して、観測結果を入力するためのハードウェアをセンサー、行動を出力するためのハードウェアをエフェクターと定義します。
実世界における強化学習をユーザとのインタラクションに利用したいと考えます。この場合、環境=ユーザとなるため、一般的な話より具体的になります。図1を見ながら説明していきます。
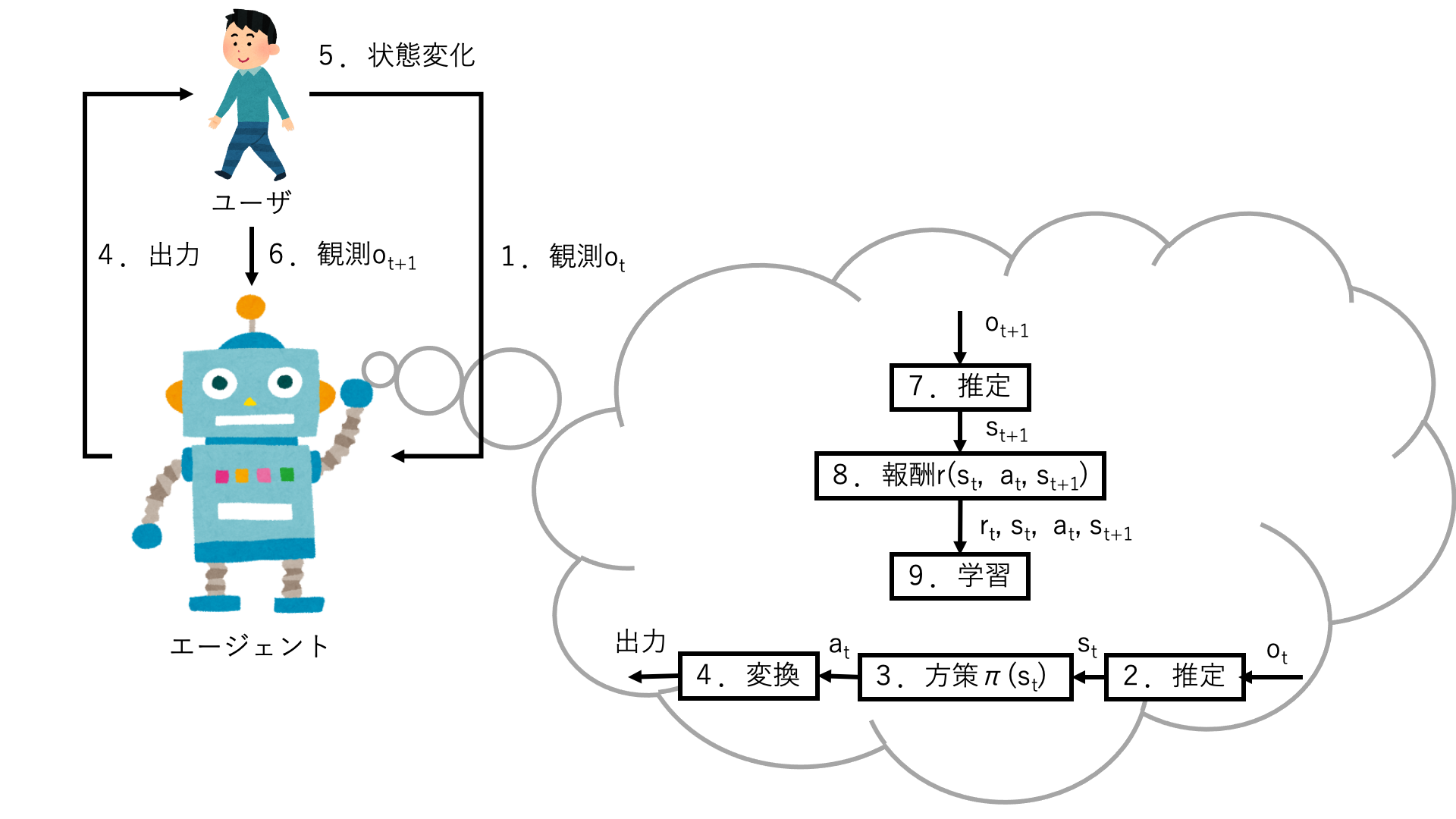
図1 提案する問題設定を可視化したもの
- エージェントはユーザの現在の観測結果otをセンサーから取得する
- エージェントは観測結果otからユーザの現在の状態stを推定する
- エージェントは方策(行動方針)πに基づいて行動atを決定する
- 行動atの内容をエフェクターに出力する。
- 行動atによりユーザは次の状態st+1に遷移する(エージェントにはこの遷移は未知であることに注意)
- エージェントはユーザの現在の観測結果ot+1をセンサーから取得する
- エージェントは観測結果ot+1からユーザの現在の状態st+1を推定する
- エージェントに報酬r(st, at, st+1)を与える。
- エージェントは報酬や行動、状態をもとにして方策を修正するように学習する
この問題設定を部分観測マルコフ決定過程 (POMDP) と言います。解き方はいろいろありますが、ここでは信念MDP (belief MDP) に近い解き方を実現しています。厳密な解き方をすると組合せ爆発を起こすため、今回は割愛させていただきます。特に今回のような解き方をインタラクティブ強化学習[1]と言うらしいです。私はユーザ中心型強化学習[2]とよんでいました。
今回の問題の定式化
さて、今回の「ユーザが最もいいねと思っている画像を自分から探し出す」問題を次のように定式化します。基本的には状態や行動が取りうる値を定義しています。
- 観測集合O: 3秒間に取得できたWebカメラの画像列
- 状態集合S: {いいね, その他}
- 行動集合A: {サンタの画像, トナカイの画像, スノーマンの画像}
- 報酬関数r: 次の状態が「いいね」だったら1。それ以外は0
- 方策π: 線形減衰するε-greedy
- 学習方法: Q学習
今回は問題を分かりやすくするために簡潔に表現しています。ご了承ください。
実装概要
さて、このインタラクティブ強化学習を実際に作っていきましょう。この前提として、開発環境や実行環境を次のとおりに示します。
- コンピュータ: MacBook Pro (MBP)
- OS: Mac OS Big Sur
- CPU: Intel Core i5
- GPU: MBP内蔵のもの(CUDAは)
- センサー: MBP内蔵カメラ
- エフェクター: MBP内蔵ディスプレイ
- プログラミング言語: Python
- ライブラリ: OpenCV, MediaPipe
この環境を用いて、インタラクティブ強化学習を実装します。実装の概要としては次のとおりです。
- エージェントはユーザの現在の観測結果otをMBP内蔵カメラからOpenCVを用いて取得する。
- エージェントは観測結果otからユーザの現在の状態stをMediaPipeのHandsを用いて推定する。
- エージェントは方策πに基づいて行動atを決定する
- 行動atが示す画像をMBP内蔵ディスプレイに出力する。
- 行動atによりユーザは次の状態st+1に遷移する
- エージェントはユーザの現在の観測結果ot+1をMBP内蔵カメラからOpenCVを用いて取得する。
- エージェントは観測結果ot+1からユーザの現在の状態st+1をMediaPipeのHandsを用いて推定する。
- エージェントに報酬r(st, at, st+1)を与える。
- エージェントは報酬や行動、状態をもとにQ学習する
テスト
以上の通り、実装したものが正しく動作しているか試験しましょう。まず、ユーザは次のとおりとなっています。
- サンタの画像がいいねと思っている。それ以外の画像はどうでもいいと思っている。
- いいねと思っている画像にはサムズアップを行い、それ以外はサムズダウンを行う。
もし、ユーザがこの通りに動いた場合、最終的にサンタの画像がずっと表示されるはずです。
テスト結果
サンタの画像をユーザがいいねと思ったときにテストした結果が映像1になります。
映像1: テスト結果。エージェントがサンタの画像を表示するように学習する。
(ここではわかりやすさを優先するために、観測結果から状態をリアルタイムで推定しています。
従って、実装概要と説明した実装とは微妙に異なります。)
映像1を眺めていると、最初はランダムな画像がディスプレイに表示されていましたが、最終的にサンタの画像だけがディスプレイに表示されています。これは最初にランダムに探索を行い、その結果を活用したためだと考えられます。この結果から強化学習が正しく行われていることがわかります。
まとめ
今回は「いいね👍で始めるインタラクティブ強化学習入門」と題しまして、「ユーザが最もいいねと思っている画像を自分から探し出すモノの作り方」について説明しました。
この知識を応用すれば、インタラクションの方法を自律的に獲得するCGアバターやロボットを作り出すことができます。この分野をこの記事よりも深く学びたい人は参考文献[1]をお読みください。それでも物足りないという方はぜひインターンシップなどで弊社に来てください。よろしくおねがいします。
補足説明
- この問題は強化学習でなくても解けます。特にバンディットアルゴリズムで効率よく解けます。しかし、インタラクティブ強化学習の話をしたいため、あえて強化学習でときました。
- POMDPの性質上本来は確率的に解く問題ではありますが、初学者にもわかりやすくするために決定的な問題として扱っています。
参考文献
[1] Neziha Akalin et al., “Reinforcement Learning Approaches in Social Robotics”, arXiv, 2020
[2] Yasunori Ozaki et al., “Can User-Centered Reinforcement Learning Allow a Robot to Attract Passersby without Causing Discomfort?”, IROS 2019
各種イラストの出典元