
CyberAgent Developers Advent Calendar 2021 – Adventar 15日目の記事です。
はじめに
こんにちは、株式会社タップルでバックエンドエンジニアをしている野口です。
タップルでキャッシュストアとして利用している「Amazon Elasticache For Redis(以下Elasticache)」の約4年越しとなる大幅アップデートを行い、以下のようなコストパフォーマンスの改善に成功しました。
- クラスターサイズを1/2へ
- CPUUtilizationの約45%削減
本記事ではアップデートに至った経緯や移行方法についてご紹介します。
タップルについて
マッチングアプリ「タップル」は、2014年5月にサービスを開始。
グルメや映画、スポーツ観戦など、自分の趣味や行きたい場所をきっかけに恋の相手が見つけられるマッチングアプリとして支持される国内最大規模のマッチングアプリです。

タップルにおけるキャッシュ戦略について
タップルはベーシックな「Cache-Aside Pattern」を採用しており、下図のような構成でキャッシュストアを利用しています。
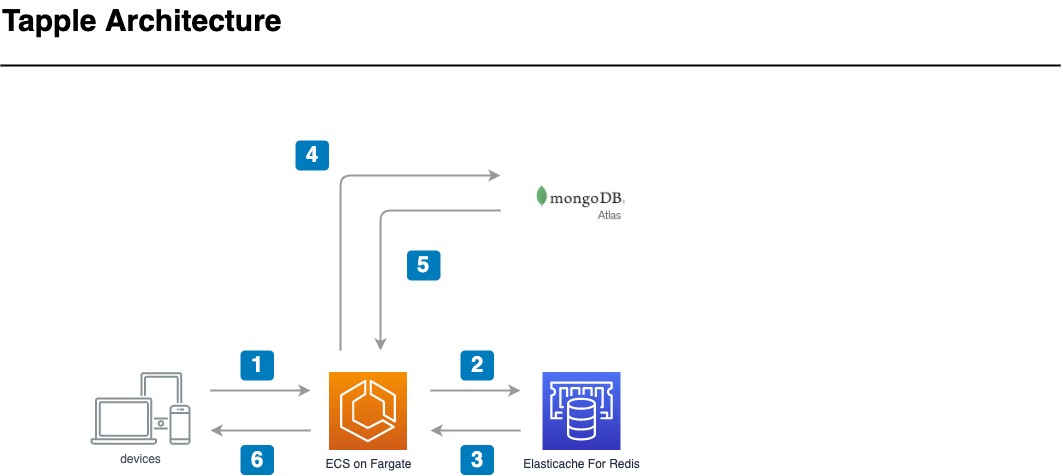
アップデートに至った経緯
タップルは、2017年6月に「Elasticache」の利用を開始し、当時の最新インスタンスタイプからアップデートすることなく、Redis 3.2.10を約4年間運用してきました。
ユーザー数増加や、サービス機能追加・改修によってシステム負荷が逼迫した際に、水平スケーリングによる負荷を分散させる運用を続けてきましたが、コストが増大する一方だったため、アップデートに取り組むことにしました。
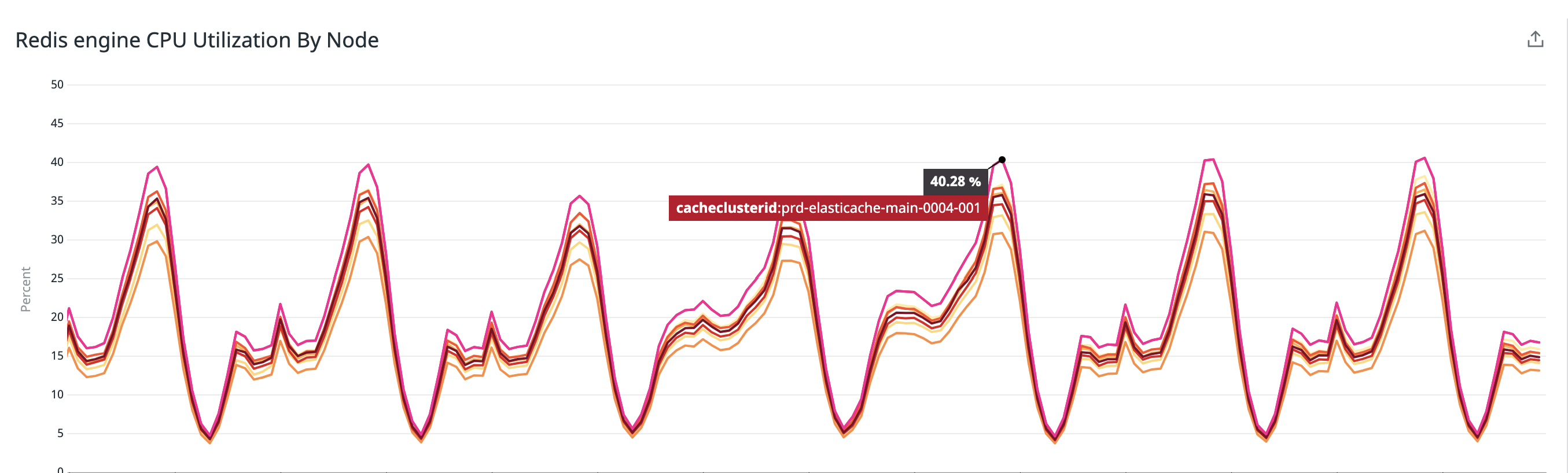
2021年8月16日のCPU使用率
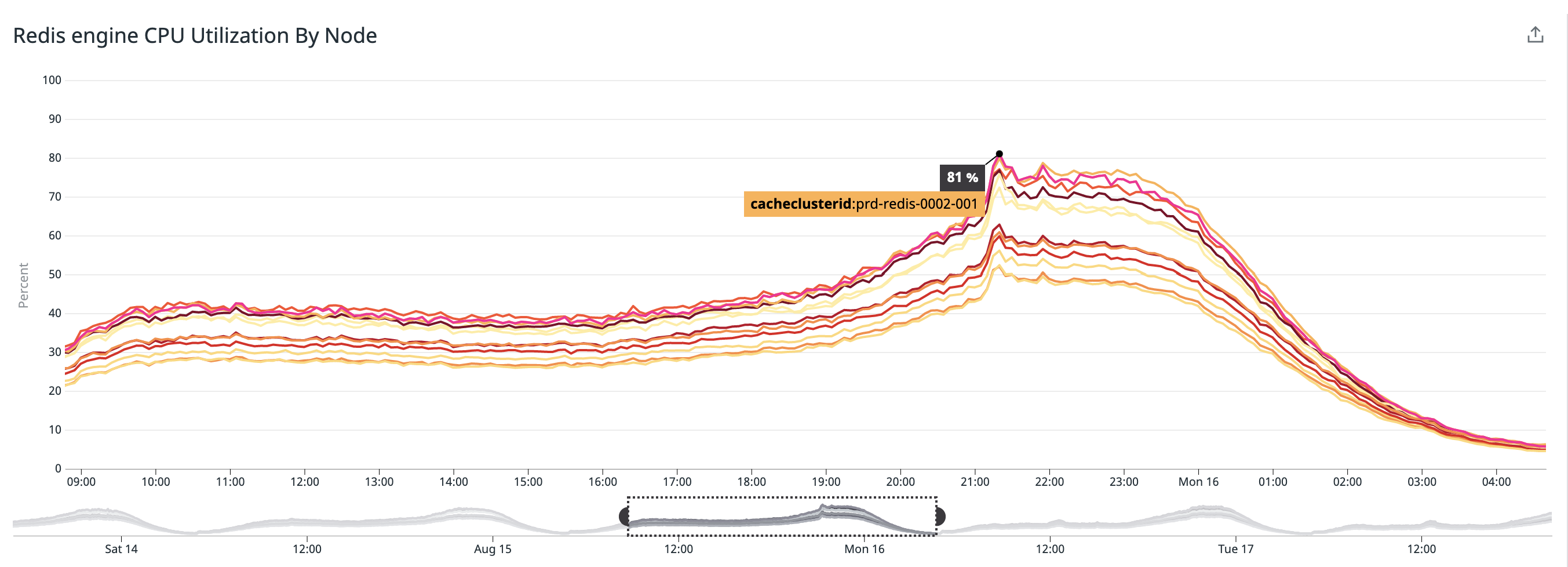
現状を整理して見えてきた問題
アップデートに向けて現状の整理と理想状態を書き出してみると、約4年間アップデートをしていないことによる課題がありました。
Graviton2ベースのインスタンスへのアップグレードができない
Elasticacheは、2020年10月頃にGraviton2ベースのインスタンスファミリーである「M6g および R6g」が東京リージョンで利用可能になっています。
しかし、タップルで利用していたElasticacheは、ノードタイプに「cache.r3.large」を採用していたため、最新のインスタンスに直接アップグレードすることができませんでした。
一度「cache.r5.large」へアップグレードしたのち、「cache.r6g.large」へアップグレードする必要がありました。
永続データの存在
タップルは一部のキャッシュデータを「永続データ」として管理しており、揮発するとサービスに不具合が発生してしまう状態でした。
したがって、移行時にキャッシュデータ自体の移行や扱いを整理する必要がありました。
有効期限がかなり長いKeyが多くある
移行に伴い、アプリケーション部分の調査をしたところ、「5184000sec(60Day)」「7776000sec(90Day)」と有効期限がかなり長いキャッシュが見つかりました。
さらに、アプリケーションの不具合で有効期限が「n年」という期間のキャッシュデータや、意図せず有効期限が指定されていないキャッシュデータが多くありました。
以下一部抜粋
prd-elasticache.tapple:6379> info keyspace
# Keyspace
db0:keys=2877661,expires=1089843,avg_ttl=60344874285676
移行プランについて
先述した課題を踏まえて、AWS Solutions Architectの方々やタップルSREと移行プランについてディスカッションを行った結果、以下のような移行プランが検討されました。
1. 既存クラスターに対してバージョンアップ実施
1つ目の移行プランは「既存のElasticacheクラスターのそれぞれのノードに対して、バージョンアップを行う」という方式です。
- インスタンスファミリー
- cache.r3.large → cache.r5.large → cache.r6g.large
- Redisバージョン
- 3.2.10 → 6.x
おそらくこの方式が「最もシンプルかつ移行コストもかなり低い」のですが、タップルは以下のような点からこちらの移行方式を採用していません。
- 一度のアップデート作業で、「cache.r6g.large」へのインスタンスファミリー変更ができない(2回アップデート作業が必要)
- アップデート後に何か問題が発生した場合に、以前の状態へ切り戻せない
- 有効期限が設定されていないキャッシュデータや、有効期限がかなり長いキャッシュデータが残り続けてしまう
- アップデート時のダウンタイムがどのくらい発生するか想定できない
5.0.5以降のバージョンを利用している場合はオンラインでのアップグレードが可能になっています。
2. 新規でクラスターを作成後、ダブルライトによる段階的な移行
2つ目の移行プランは「新しくクラスターを作成し、アプリケーションからのダブルライトによる段階的な移行を行う」という方式です。
1つ目の移行プランよりも移行コストは高いですが、以下の点からメリットが大きいと判断し、タップルはこちらの方式を採用することにしました。
- 移行時にダウンタイムが発生しない
- 移行中問題が発生した場合、既存クラスターへ向き先を変更することで切り戻しできるため、いわゆる”Two way door”な状態になる
- 「cache.r6g.large」インスタンスファミリーへの切り替えが1度のアップデート作業で完了する
- 有効期限が未設定のキャッシュデータなど、不要なものを取り除いた上で、適切な有効期限でキャッシュデータを管理可能
デメリットして以下の点が挙げられますが、トレードオフを検討し、許容しました。
- 移行完了まで2クラスター分のランニングコストが発生する
- 現状の運用だと必要以上にコストがかかる点や、アップデートによるメリットを提示した上でコスト面の合意を取りました
- ダブルライトにより、アプリケーションのレイテンシに影響が発生する可能性がある
- ここに関しては後述で詳細についてご説明します。
移行期間について

移行に向けての前準備
移行プランの方針を決定したところで、移行の前準備として、先述の通り現状の課題点を解決するべく整備をいくつか行いました。
Redis固有のパラメータについての調査
運用しているRedis3.2.10と古かったため、6.xまでのリリースノートを全て確認し、Elasticacheクラスターに設定する「パラメータグループ」に適切な値を設定する必要がありました。
結果として、バージョンに適した「パラメータグループファミリー」の設定値をそのまま利用していますが、変更を検討したパラメータについていくつか参考程度に記載します。
| Name | Default | Description | Usage |
| maxmemory-policy(eviction-policy) | volatile-lru | maxmemory-policy was added in version 2.6.13. In version 4.0.10 two new permitted values are added: allkeys-lfu, which will evict any key using approximated LFU, and volatile-lfu, which will evict using approximated LFU among the keys with an expire set |
使用されてからの経過時間が長いキャッシュから消していきたかったので、volatile-lruを設定しました。
|
| cluster-allow-reads-when-down | no | When set to yes, a Redis (cluster mode enabled) replication group continues to process read commands even when a node is not able to reach a quorum of primaries. |
Failover等が発生した場合にセカンダリから古い読み取りを許容できなかったため、no を設定しました。
|
| active-expire-effort | 1 | The default value of 1 tries to avoid having more than 10 percent of expired keys still in memory. It also tries to avoid consuming more than 25 percent of total memory and to add latency to the system. You can increase this value up to 10 to increase the amount of effort spent on expiring keys. The tradeoff is higher CPU and potentially higher latency. We recommend a value of 1 unless you are seeing high memory usage and can tolerate an increase in CPU utilization. |
有効期限切れのキャッシュデータを優先的に削除したい要件がなかったのと、 システムリソースに負荷をかけてまで有効期限管理をしなくてもよかったので 1 を設定しました。
|
https://docs.aws.amazon.com/ja_jp/AmazonElastiCache/latest/red-ug/ParameterGroups.Redis.html
Redis 6.xを利用する場合は、以下のコマンドでデフォルト値を確認できます。
$ aws elasticache describe-cache-parameters --cache-parameter-group-name default.redis6.x.cluster.on
永続データの廃止
キャッシュストアで永続化しているいくつかのデータは、
アプリケーションの見直しを行い、永続データを管理するストア(MongoDB Atlas)へ移行する、もしくはデータを利用しなくても済むようにアプリケーションを整備しました。
有効期限の設定の必須化と最大長の設計
アプリケーションからキャッシュストアを利用する際の運用ルールとして、以下の整備を行いアップデート後に適切な形でキャッシュストアを利用できるように設計し直しました。
- キャッシュストアを利用する際は、有効期限を必ず設定すること
- キャッシュデータの有効期限を最大「2592000sec(30Day)」で設定すること
ダブルライトマイグレーションによるレイテンシの悪化に対してのリスクヘッジ
ダブルライトを行うということは、アプリケーションからのキャッシュストアへの書き込み操作が純粋に2倍になるため、システムに負荷が発生します。
本来であれば、ロードテスト(負荷テスト)を実施した上で、移行プランに問題がないか?を精査するべきですが、
今回のアップデートは諸都合によりロードテストを実施できなかったため、以下のような対策を用意していました。
- アプリケーションからのダブルライトを設定値によって停止・再開をできるように
- レイテンシの大幅な悪化や、レイテンシSLOを違反する場合は、任意のタイミングでダブルライトを停止できるようにしておく
- トラフィックの少ない時間帯でのダブルライト開始
- 前提: タップルは、アプリケーションへのトラフィックに波があり、PM 06:00(JST)を超えるとトラフィックが多くなるという傾向があります。
- ダブルライト開始直後に、キャッシュストアのクラスターサイジングの設計ミスでレイテンシ悪化を引き起こす可能性も考えられたため、トラフィックの少ない時間帯にダブルライトを開始することにしました。
- エラーハンドリングの調整
- ダブルライトは何か問題あってもサービス影響がないようにしておく必要があるため、アプリケーションからのキャッシュストアへの書き込み操作は一律ハンドリングを行い、エラーを握り潰す対応を入れていました。
移行開始〜完了まで
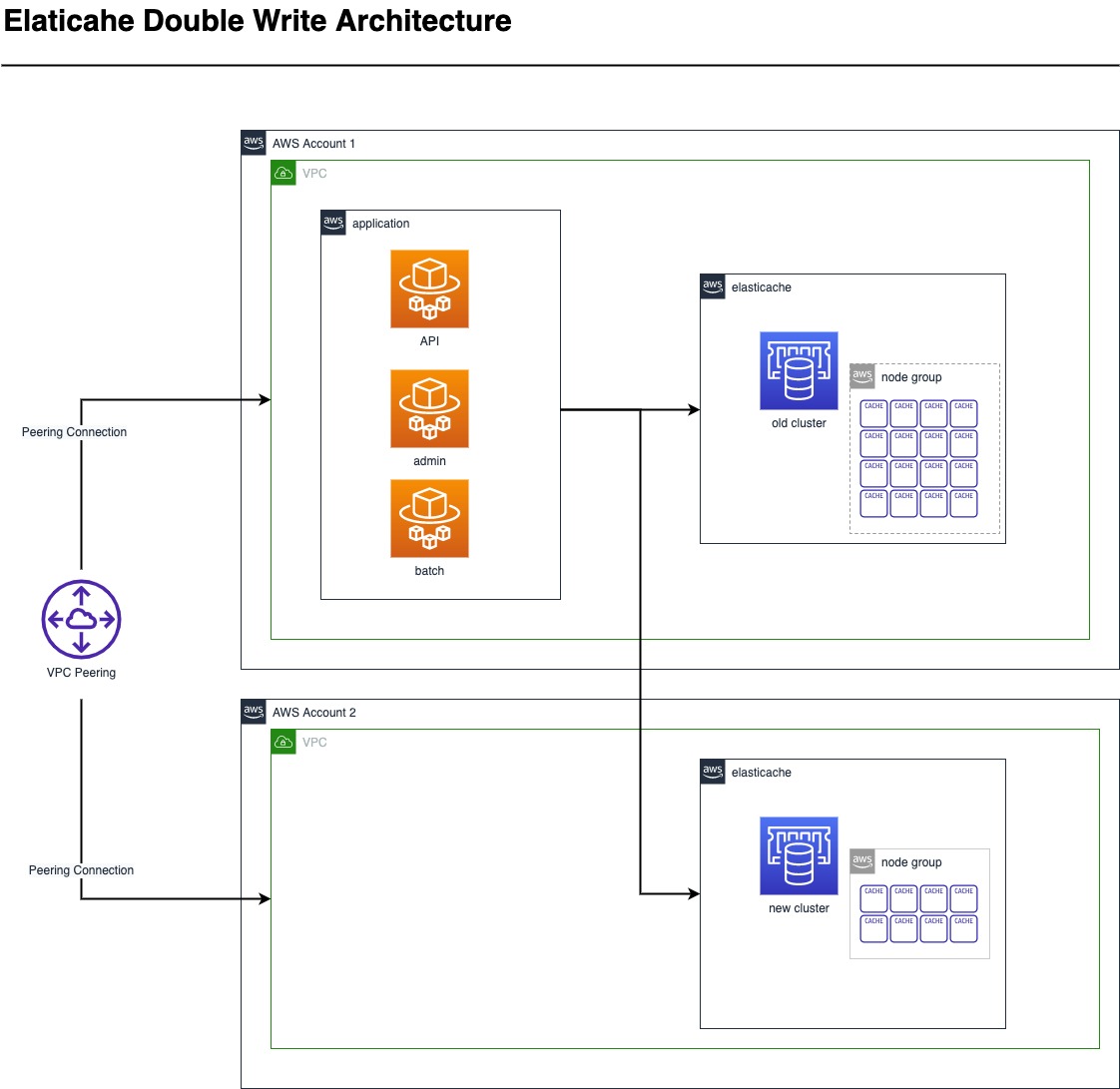
アーキテクチャ構成
タップルは以下のようなアーキテクチャ構成でのダブルライトマイグレーションを実施しました。
ダブルライト開始から約1ヶ月の期間を経て、読み取り操作の開始
先述の通り、アプリケーションからキャッシュストアを利用する際の有効期限を「2592000sec(30Day)」に再設計を行なったことで、
約1ヶ月間のダブルライトマイグレーション期間を経て、移行先のクラスターと移行前の旧クラスターでキャッシュデータ数が同等になりました。
読み取り操作の移行においても、ダブルライト開始時と同様に以下のようなレイテンシ悪化対策を用意しておくことで、サービス影響が出ないように切り替えを実施しました。
- アプリケーションからの移行先クラスターへの読み取りを設定値によって停止・再開をできるように
- レイテンシの大幅な悪化や、レイテンシSLOを違反する場合は、任意のタイミングで移行前の旧クラスターへ読み取り操作を切り戻せるようにしておく
- トラフィックの少ない時間帯での切り替え
- 読み取り切り替え直後に、キャッシュストアからのNetworkBytesOut が一気に増加することが想定されたため、トラフィックの少ない時間帯に切り替えを行うことにしました。
アップデート前後のメトリクス変化
約3ヶ月間の移行期間を経て、無事にアップデートを終えることができました。
アップデート前後で得られたメリットについてご紹介します。
CPUUtilization約45%削減
アップデート前
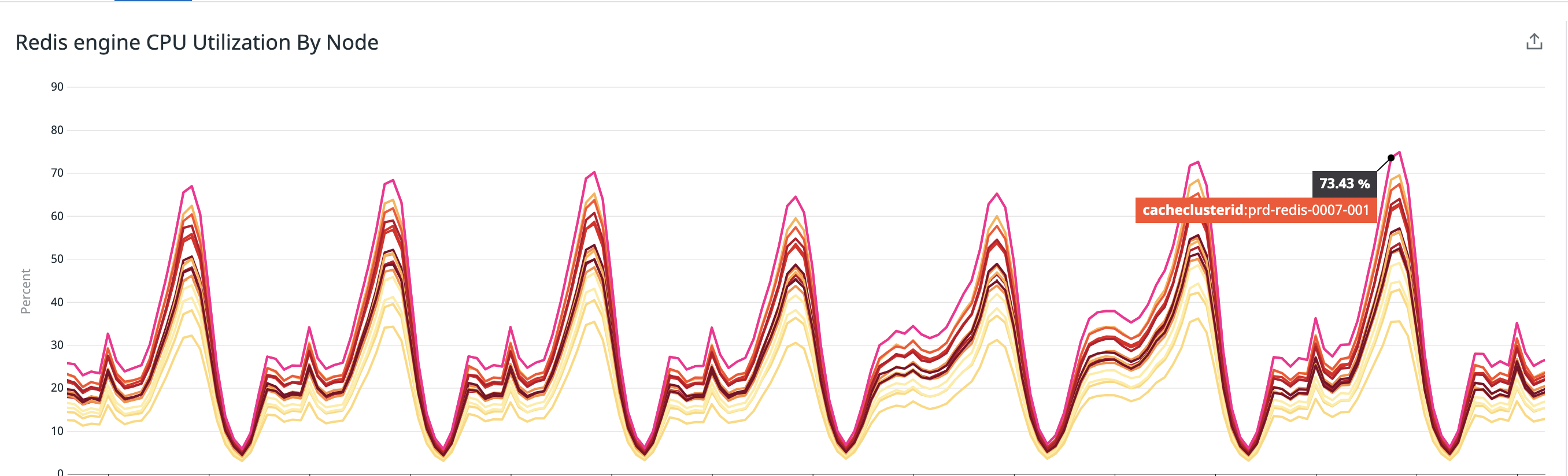
アップデート後
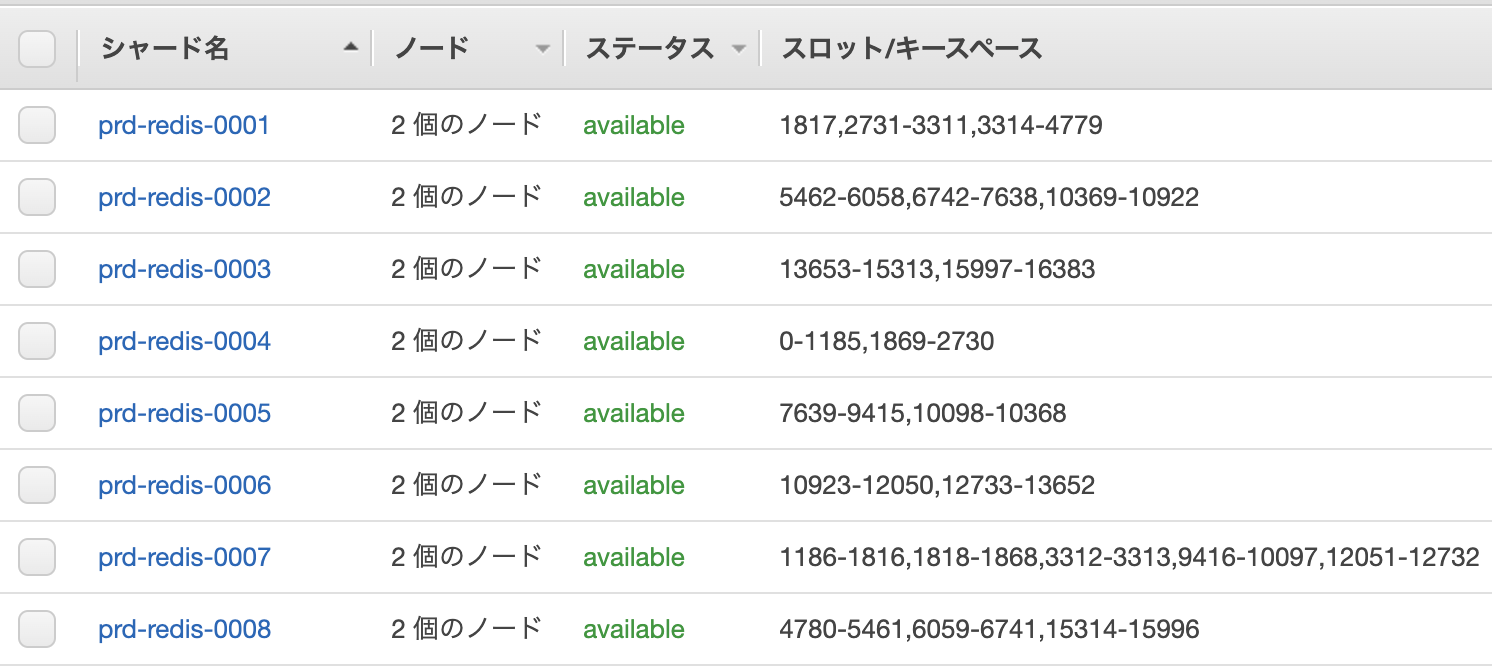
クラスターサイズを1/2へ
アップデート前
- シャード数: 8
- シャードごとのレプリカ数: 2
- 8シャード2レプリカ = 16ノード
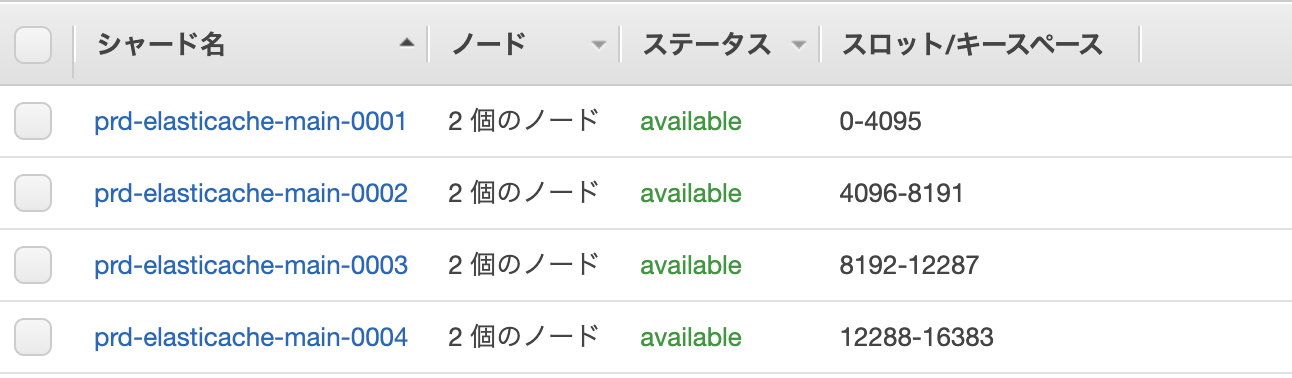
アップデート後
- シャード数: 4
- シャードごとのレプリカ数: 2
- 4シャード2レプリカ = 8ノード
さいごに
最後まで読んでいただきありがとうございました。
タップルは「サービス影響なし・ダウンタイムなし」で無事約4年越しとなるアップデートを完了することができました。
今回の取り組みで身に染みて感じましたが「アップデートは定期的に行う」ということを今後も引き続き行なっていきたいと思います。
改めてになりますが、ご尽力いただいたAWS Solutions Architectの方々ありがとうございました。
宣伝
タップルにご興味のある方いらっしゃいましたらぜひカジュアル面談しましょう🏕