
はじめに
みなさんこんにちは。
CIU の @makocchi です。
RDB(Relational Database) といえば MySQL や PostgreSQL が真っ先に思い浮かぶ方も多いと思います。
弊社内でも数多くの RDB が稼働していますが、RDB を運用しているとこのような課題にぶつかりがちではないでしょうか?
-
- 性能は足りているんだけどディスクの容量だけ増やしたい
- ディスクの容量は余裕あるけど、性能だけ増やしたい
- 無停止でスケールさせたい
- レプリケーションの遅延を解消したい
最近比較的新しいオープンソースのソフトウェアとして TiDB が登場してきました。
TiDB は MySQL 互換があり、MySQL 用のライブラリやクライアントがそのまま使えるというメリットを持ちつつ比較的モダンな発想で作られているソフトウェアです。
コンポーネント毎に無停止スケールすることが可能で、アーキテクチャ上レプリケーションの遅延も発生しません。
これは触ってみるしかない!
というわけで、この度 PingCAP 社の協力のもと社内の有志で TiDB のハンズオンを開催して TiDB を実際に触ってみました。
TiDB とは
TiDB は HTAP ワークロードをサポートするオープンソースの NewSQLデータベースです。
HTAP = OLTP(Online Transaction Processing) + OLAP(Online Analytical Processing)
OLAP を実現するにはデータ構造を OLTP から変更しないといけないのですが、TiDB では同時に実現することが可能なのが特徴です。(HTAP 用のコンポーネントを別途動かしておく必要があります)
TIDB は MySQL と互換性があり、水平方向のスケーラビリティ、強力な一貫性、および高可用性を備えています。
TIDB の内部では各種コンポーネントが分かれており、そのコンポーネント毎に無停止でスケールが可能です。
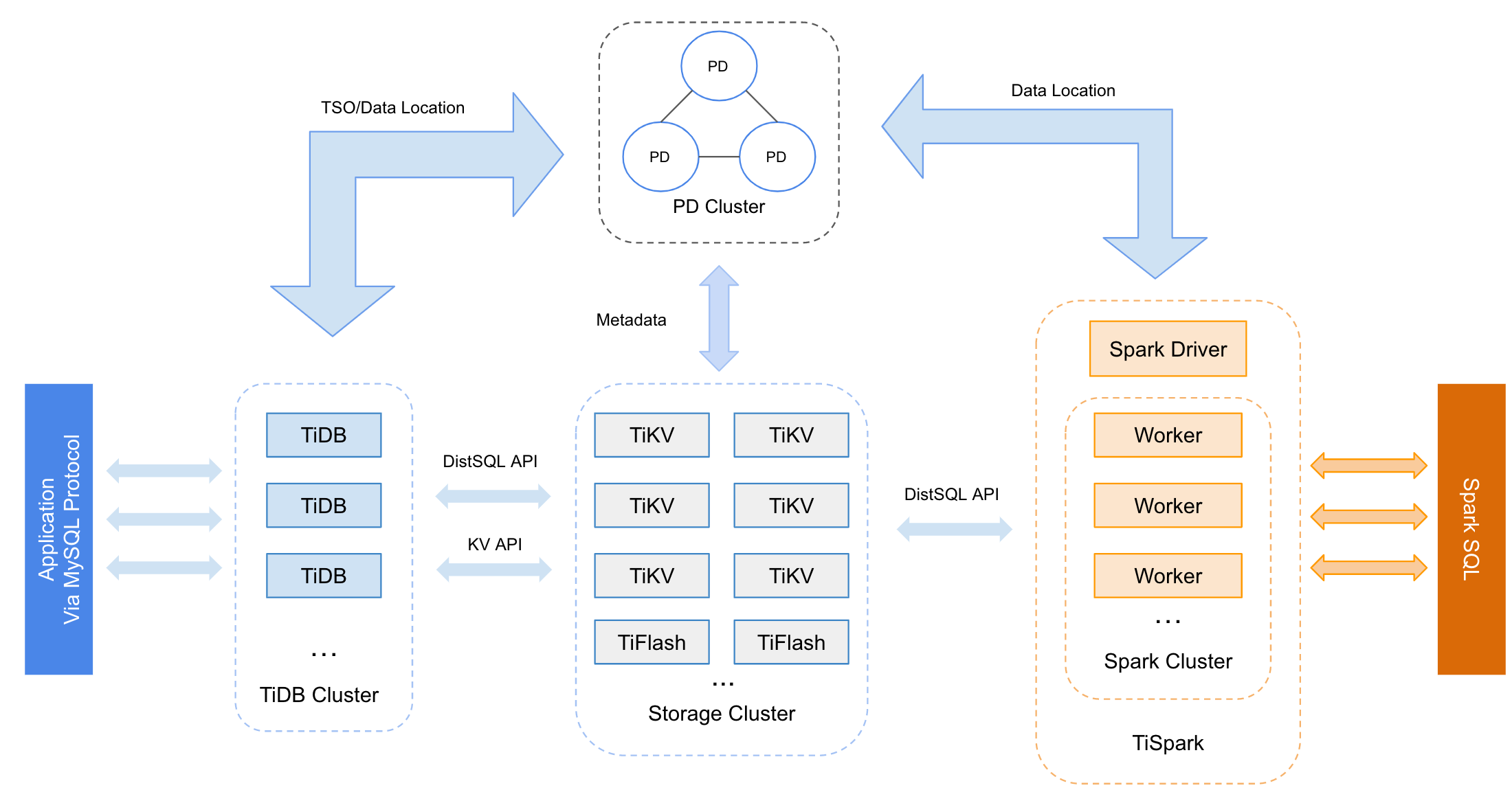
実際に SQL を処理するのは TiDB のコンポーネントになり、read も write も処理することが可能です。ですので実質 multi master のように扱うことが可能になります。
TiDB のデータ格納は TiKV という別のソフトウェアが使われています。TiKV は CNCF によって管理され、現在は Graduated なプロジェクトになっています。(TiDB は CNCF 管理ではなく、TiKV だけです)
ちょっと話はそれますが、TiKV の内部では facebook の RocksDB がストレージ部分で使われていたり、Raft や Google の Percolator が使われていたり、技術的にすごく面白い部分がたくさんあります。
もちろん TiKV 単体でも KVS として機能しますので、気になった方は是非触ってみてください!
TiDB はオープンソースで公開されていますが、主に開発しているのは PingCAP 社になります。
ハンズオンの内容決め
今回のハンズオンを企画するにあたり、PingCAP 社と綿密に打ち合わせを繰り返して内容をブラッシュアップしていきました。
TiDB は開発も活発ですので、打ち合わせしていく最中にバージョンが上がってしまったなんてこともありました。
また、ハンズオンする時にこういう機能あったらいいのになっていうのが判明したので、それを実際に実装してコントリビュートすることもしてみました。
support rendering template when set “–local” option
tiup に読み込ませる yaml を生成する際に任意の値を埋め込めるようにしました。1.7.0 で取り込まれたのでそれ以降のバージョンで使えます
最終的にはこのような内容のハンズオンを開催することができました。

ハンズオンの環境は社内で使われているプライベートクラウドを利用しました。
実際にハンズオンする際に PingCAP 社の講師の方はパブリッククラウドで作業することになるので、環境差異をなるべくなくすようにちょっと工夫してプライベートクラウド側の環境を用意しました。
何度もシミュレーションして一つずつ問題を解決していく部分は地味に大変でした・・・
その甲斐あってか、当日のハンズオンは特に問題なく進みました。
実際にハンズオンをやってみて
ここからはハンズオンをやってみた個人的な感想になります。(一部参加者のアンケート結果の内容も含んでいます)
- tiup が優秀すぎて管理がすごく楽にできる
- TiDB に関する作業はほぼ tiup というコマンドが担当してくれます。必要なオペレーションは tiup を叩くだけで自動で行える点は非常に楽でした。
- ダッシュボードがとても良い
- 今現在どんなクエリが流れているのか、そのクエリの実行計画はどうなっているのかをダッシュボードでリアルタイムに分析する機能が最初から提供されています。
- クエリの分析の他にホットスポットの表示やクラスターの状態も把握できます。

- Prometheus と Grafana も一瞬で入る
- Prometheus と Grafana の環境も tiup であっという間に構築できます。
- Grafana は便利なダッシュボードが始めから入っており、こちら側でダッシュボードを作成する必要がありません。
良いところばかりではなく気になった部分も挙げておきます。
- クラスターを構築する際には yaml の定義ファイルを指定するが、スケールさせる時にはまた別途スケール用の yaml を用意しないといけない点が残念でした。構築する際に使った yaml との差分を検知してスケールさせる仕組みになっていれば良いなと思いました。今後に期待しましょう。
- MySQL 互換ではあるが、完璧ではなくて Stored Procedure や UDF に対応していなかったりするのが残念。また、MySQL 8.0 対応もまだ完全ではないようです。
- 分散システムという特性上、どうしてもクエリに対してネットワーク等のレイテンシが乗ってくる点に注意。
- 数ms で返さなきゃいけないような場合には TiDB は不向きだと思います。
- tiup は Kubernetes で TiDB を動かしたい時に対応していない
Kubernetes で TiDB を動かしたい時は?
tiup は非常に優秀なツールというのは既に紹介させて頂きましたが、内部的には対象のノードに ssh で login して各種操作を行います。
つまり対象が Kubernetes の場合には tiup は不向きということになります。
しかしその問題は tidb-operator が解決してくれます。tidb-operator を使えば Kubernetes 上に TiDB を簡単に構築でき、宣言的に TiDB を管理することが可能になります。
tidb-operator については自分がまとめた発表資料がありますので、もし興味がありましたらこちらも合わせて見ていただけると幸いです。
おわりに
TiDB は世間的には NewSQL と呼ばれるカテゴリに分類されます。
TiDB は Google の Spanner の論文を参考に設計されたとされており、いわゆる Spanner クローンと言われるケースもあります。
Spanner に設計思想を得たものとして、他には CockroachDB や YugaByteDB があります。
MySQL のインターフェイスを持っているのは TiDB ですが、CockroachDB や YugaByteDB は PostgreSQL のインターフェイスを持っています。
モダンなアーキテクチャで作られたこのようなソフトウェアを使う機会が最近は増えてきたんじゃないでしょうか。
また、TiDB は既存の MySQL から binlog を受け取って slave にすることができたり、逆に MySQL 等に対して更新を反映させることも可能です。
今後はこのような機能も是非検証していきたいと思っています。
実は TiDB はマネージドサービスとして使うこともできます。(TiDB Cloud)
しかも最近 Developer Tier が追加され、ある程度無料で使うことが可能になっています。
みなさんも是非触ってみてくださいね!