
この記事はCyberAgent Developers Advent Calendar 2021 11日目の記事です。
みゆっきこと山中勇成(@toriimiyukki)です。普段は、ABEMAで動画配信基盤の開発運用を担当しています。
直近では、配信システムの大規模刷新プロジェクトなどを担当しており、こちらの模様はCA BASE NEXTの発表からアーカイブを閲覧可能です。
モニタリング定例のすゝめ
ABEMAでは、24時間365日のリニア型配信やVOD配信など、昼夜を問わず落とすことができないミッションクリティカルなサービスを運用しています。サービスを支えるマイクロサービスは、配信分野に限っても20サービスを超えています。
既にPrometheusなど、各種モニタリングソリューションでの監視やアラーティングなども行っていますが、この記事では、あえて手動監視を定期的に行う、モニタリング定例を勧めたいと思います。
なぜやるのか
なぜ、手動監視を定期的に行うのか。モニタリング定例の開催には、次の目的があります。
モニタリングにおける知見を共有し、メンバーのスキルアップを狙う
サービスのメトリクスやログを注視するタイミングは、リリース時や障害時など限られてきます。モニタリングの知見が豊富だと、障害時にサービスのモニタリングを即座に行うことができ、素早く障害の原因を特定し、復旧することができます。
しかし、サービスのメトリクスやログの特性や暗黙的な認知などをオンボーディングで全てを説明することは不可能で、障害時に必要とされるモニタリングの知見や能力を教え込むのは難易度が高いです。そこで、モニタリングを定期的に実施することにより、それらの知見を予め共有し、障害時の対応能力の向上に貢献することができます。
また、モニタリングのリンクや見方などをドキュメント化することにより、オンボーディングや障害時に参照することも可能です。
サービスのメトリクスやログを再確認し、異常な傾向がないか確認する
各種モニタリングソリューションで、閾値やスパイクなどの検知や異常なログの検出などを行っていても、不具合や設定ミス、機械的に気づけない傾向など、目視でないと気づけない問題もあります。
そこで、メトリクスやログを目視で確認することで、これらの事象を洗い出します。
異常な傾向やリクエストが生じている場合は、調査と対応を行いサービスを正しく稼働させる
発見した事象について、調査や対応が必要な場合は、それらをタスクに切り出します。そうすることで、サービスの調査や改修自体のタスクをきちんと管理することができます。
どうやるか
私のチームで行っている方法の説明になりますが、基本的には、毎週1時間の枠を確保して、次の流れで行います。
- 直近の障害とリリースの振り返り(全員/目安2分)
- 前回までの改善タスクの振り返り(全員/目安2分)
- モニタリングの実施(個人/目安30分)
- モニタリング結果のレビュー(全員/目安20分)
- 改善タスクとして切り出して担当者を割り振る(リーダー/目安5分)
これらの流れは必ずしも対面で行う必要はありませんが、リモートでも画面共有ができるツールを使うと便利です。
直近の障害とリリースの振り返り
全員で前回のモニタリング定例から発生した障害やリリースをまとめ、共有します。これにより、この後実施するモニタリングのスパイクや異常などの原因を特定することに役立ちます。
前回までの改善タスクの振り返り
前回までに挙げられた改善タスクを整理します。ただし、詳細にやりすぎると時間がなくなってしまうため、進捗を軽く尋ねる程度にします。
モニタリングの実施
各種モニタリングツールを開いて、メトリクスやログを確認します。全員で各サービスをモニタリングすると非常に時間がかかるため、サービスごとに担当者を割り振り、メトリクスやログを確認します。また、サービスごとの担当者は週ごとにローテーションすることで、網羅的にサービスを把握することが可能です。
現状、私のチームでは監視対象のサービス一覧をNotionのDatabaseにまとめています。ちなみにカラムにあるPointとは、サービスを見るのにかかる仮想的なコストです。
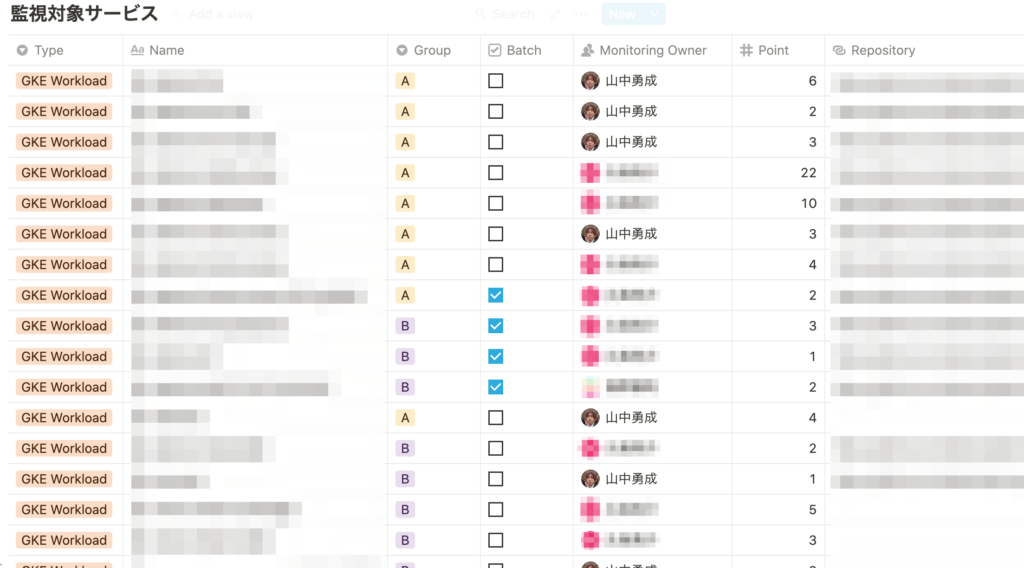
また、モニタリング定例ごとにページを作り、Linked Databaseでサービス一覧のDatabaseと連携しています。モニタリング実施時にサービス毎にMonitoring Ownerを決めています。ユーザーの横に表示されているのはPointの合計で、ローテーションや割り振りの際に参考にしています。
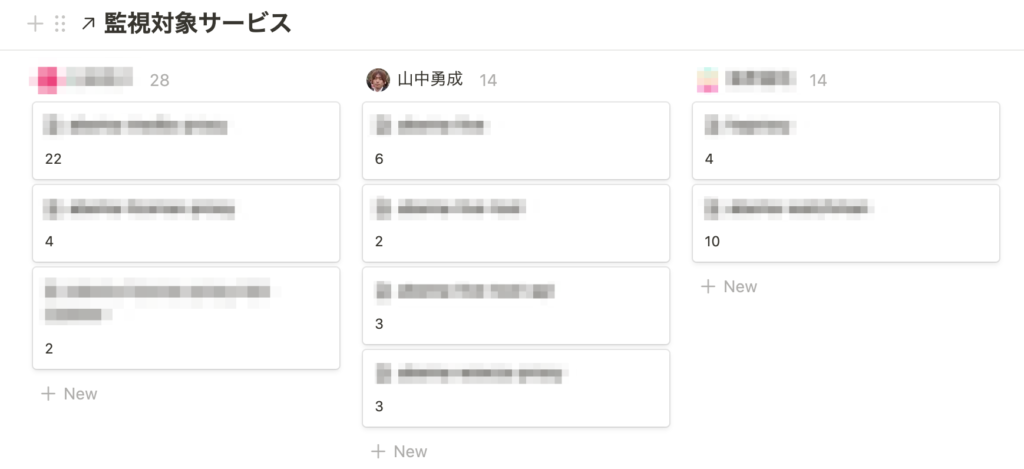
それぞれのサービスのページには、モニタリングツールへのリンクが貼られていて、ここからダイレクトに開くことが可能です。また、モニタリング時の注意点などもこのページにまとめることができます。

メトリクスについては、RED methodやUSE methodなどのメトリクスを中心に見ていきます。RedisやMongoDBなど、ものによってはサービス固有の指標も見ていきます。
ログについては、INFOレベルをざっくり見て、WARNのレベルを対象に絞って目grepを行ったり、特定のエラーログについて絞り込みを行い、特定の日からエラーが増えてないかなどをヒストグラムを見て確認します。(ログの見方をしっかり説明すると、それだけで1時間かかりそうです)

それぞれの指標は現在から1週間前までを対象にして調査します。
そして、モニタリングを行って気づいた事象を、専用のSlackチャンネルに投稿します。投稿時には、以下の項目を含めるようにします。
- サービス
- 発生日時
- 発生頻度、件数(ざっくりでもOK)
- 概要(どの様なエラー・事象かを簡潔に)
- メトリクス・ログのリンクやスクリーンショット
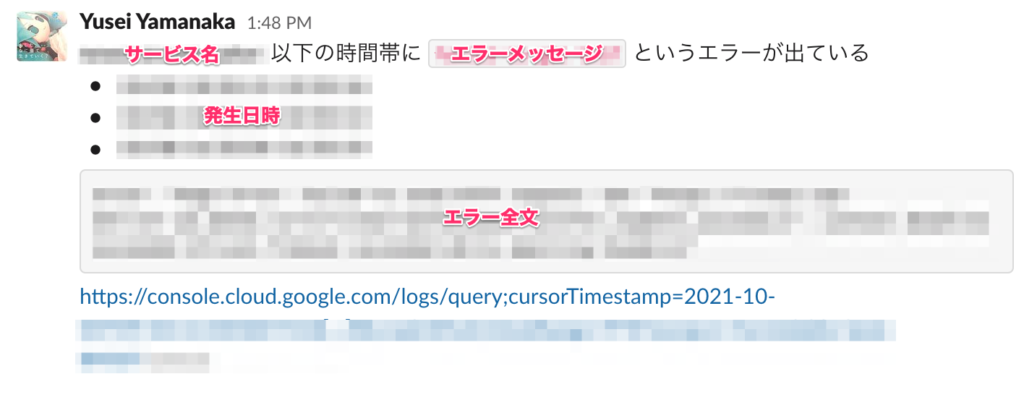
これにより、事象の概要をSlackの投稿で掴むことができ、詳細の内容が知りたい場合でもリンクから辿ることが可能です。また、後に同様の事象が出てきた時にSlackの検索機能を用いて、既出の問題であるかどうかを調べることができます。
もし、担当しているモニタリングが終了した場合は、声をかけて他の人に割り振られたモニタリングを行います。(みんな早く終わればハッピーなはずです)
モニタリング結果のレビュー
投稿された事象について、一つずつ全員で調査を行います。全員で行うことで早く調査できるという意味もありますが、その人だけが知っている・解決できることなどを早く認知できるという意味もあります。(もしかしたら、そのログを実装した人は問題ないことを知っているかもしれません)
調査中に分かったことは、投稿のスレッドに書いておくと後々便利です。最低限でも、最終的にどうするか(静観でも)書いておくことをお勧めします。
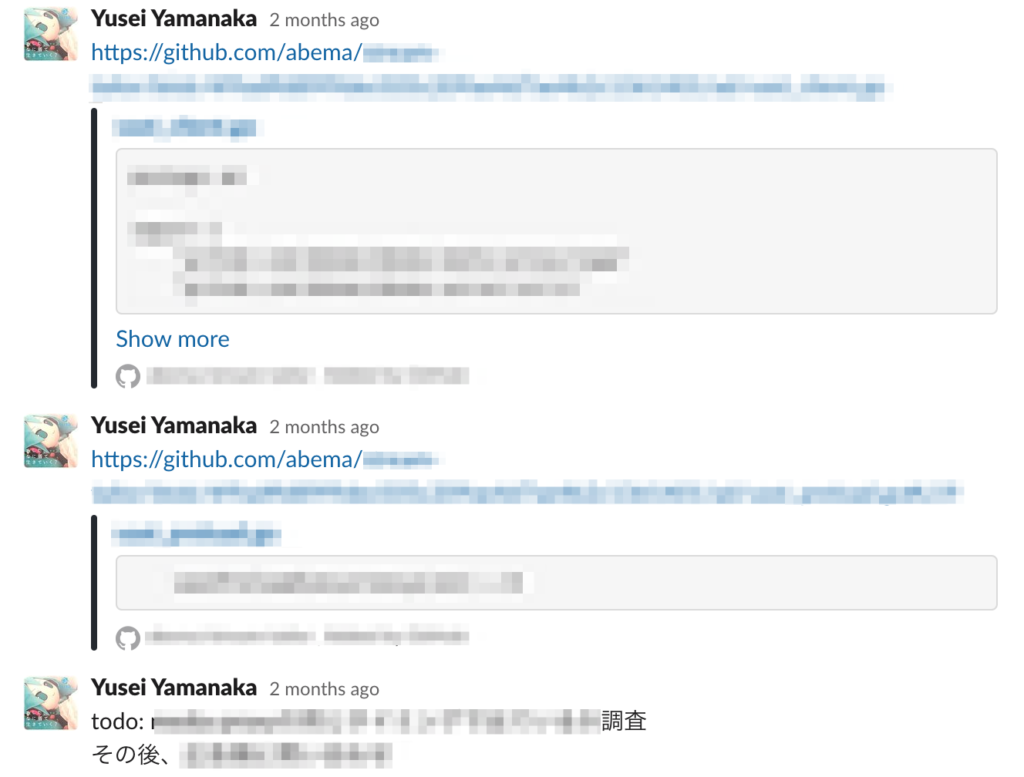
一つの事象のレビューは、残りの時間を気にしながら、もし調査に時間がかかりそうであれば、タスクとして切り出します。
改善タスクとして切り出して担当者を割り振る
続けて調査が必要な事象、改善が必要な事象などをタスクとして切り出して、担当者を割り振ります。
タスクに立候補者がいる場合は良いですが、そうでない場合はリーダーがタスクの内容によって、担当者を割り振ってしまって良いと思います。
ちなみに、私のチームでは、モニタリング定例の改善タスクをGitHubのIssueで管理しており、Projectを作成することでカンバンで管理をしています。
より良くするために
最後に、モニタリング定例を良くするためのポイントを紹介します。
気になったら報告する
モニタリング定例の目的の一つは、チームメンバーの「知見」を増やすことです。例えば、一時的なメトリクスの欠けが監視基盤のトラブルであったり、一件だけ出たあまり見ないエラーログが障害の原因になるかもしれません。
そのためには、メンバーに気になった些細なことでも事象を報告してもらい、既に認知している問題などであれば、その理由とともにチームに説明すると良いと思います。また、リーダーが報告しやすい雰囲気を作ることも大切です。
長時間行わない
私のチームでは、モニタリング定例のために毎週1時間の枠を押さえています。モニタリングの進捗により、多少の延長はあると思いますが、1時間以上やると集中力が持たなくなるため、あまり伸ばすべきではないと思います。
サービス数が多い場合には、サービスをグループごとに分けて週ごとに担当するグループを決めても良いと思います。実際に、私のチームではグループを2つに分け、それぞれ隔週毎に行っています。1週間前の指標までしか遡らないため、サービスとしては隔週ごとのモニタリングになってしまいますが、あくまでも、異常な傾向などを予め検知することが目的ですので、全ての時間を対象としなくても良いわけです。
改善タスクを長期間放置しない
優先度の低い改善タスクなど、長期間放置してしまったタスクは溜まる一方です。また、タスクが割り振られた人の負担にもなります。
実際に事象が再発していなかったり、サービスに問題がないのであれば、一定期間でタスクをクローズするべきだと思います。また、いつかのモニタリングで問題が出てきた際には、そのタイミングでジャッジをすると良いです。その際には、Slackを検索して既出の問題でないか、前回はどういう判断に至ったかを調べると良いです。
ここまで、私のチームで行っているモニタリング定例をベースに紹介しました。実は、モニタリングを行っているうちに、Notionが向いてない(モニタリングのリンクが変更になると、全てのページを回って編集する必要がある)とか、Slackでの報告をGitHub Issueで管理するのはやりづらいなど、多々問題も出てきたのですが、それについてはまたどこかのタイミングで改善策をお話しできればと思います。
ちなみに、2021年12月17日(金)には、ABEMA Developer Conference 2021を開催予定です。ABEMAで使用しているモニタリング基盤の紹介や私が直近やっているプロジェクトなども紹介予定です。是非ご覧いただければと思います。
それでは、よいモニタリングライフを!