
2021新卒 AI事業本部 極予測AIの小林拓磨です!
今回はAI事業本部名物のアドテクコンペについて、例年のDSP系のアドテクコンペと今年新たに行う最新版の生成系コンペ「広告自動生成コンペ “極”」(以下極コンペ)について解説していきます!
目次
アドテクコンペとは
AI事業本部にて例年行われているコンペであり、ネット広告において
「ネット上に存在する大量の広告枠に対し、リアルタイムに枠の価値を予測し枠の購入リクエストを送る」
という役割を持つサーバー(DSP)を擬似的に作成します。
- 大量のリクエスト(1000request per second [rqs])を捌きながら予算管理等をどのチームよりも安定して行う(サーバーサイド)
- 限られたレイテンシ(100 [ms])の中でモデルによるどのチームよりも最適な枠の値付けを行う(ML/DS)
大きくこの二つのチャレンジングな所を乗り越えながらサーバーとML/DSが連携しつつも、
1000rps・100msの世界を同世代と何とかして生き残るコンペです。
著者が学生の際に参加し当時の様子など振り返った物についてはこちらのブログをご参考ください。
楽しさを一部でも伝えるために2019年度のアドテクコンペ終了後の懇親会の様子を載せています。
この時知り合ったサーバーサイドの同期のおかげで、ML/DSエンジニアながらも推論モデルをサーバーに載せる際のサーバー・インフラの知識の必要性とシステムの監視の楽しさを知る事ができました。
そのお陰もあってか今では私も開発責任者として自ら作成したモデルを載せたシステムをインフラから設計・構築・監視する様になりました。
 過去の懇親会の様子
過去の懇親会の様子
アドテクコンペの新たな形「極コンペ」
例年は上記で説明したDSPと呼ばれる予測モデル載せたサーバーを開発するコンペでしたが、
今年度は大きく形式を刷新して開催します。
過去に学生として参加した自分としては関連する部署のメンバーとして企画運営・開発に関わる、少し感慨深いコンペになっています。
アドテク領域において、これまで枠値付けに関する最適化は行われている一方で、昨今はクリエイティブの最適化の重要性が増して来ています。
実際にAI事業部では極シリーズ、特に極予測AIというサービスが台頭しており、大きな成果を上げています。極シリーズに関しては以下をご参考下さい。
その中でも広告バナーにおけるコピー(広告文)の生成を行う機能が、極予測AIでは重要な機能となっています。今回はその「極予測AI コピー生成」をテーマにコンペを行います。

コンペ概要・コピー生成とフロー
ざっくり以下の図で説明します。
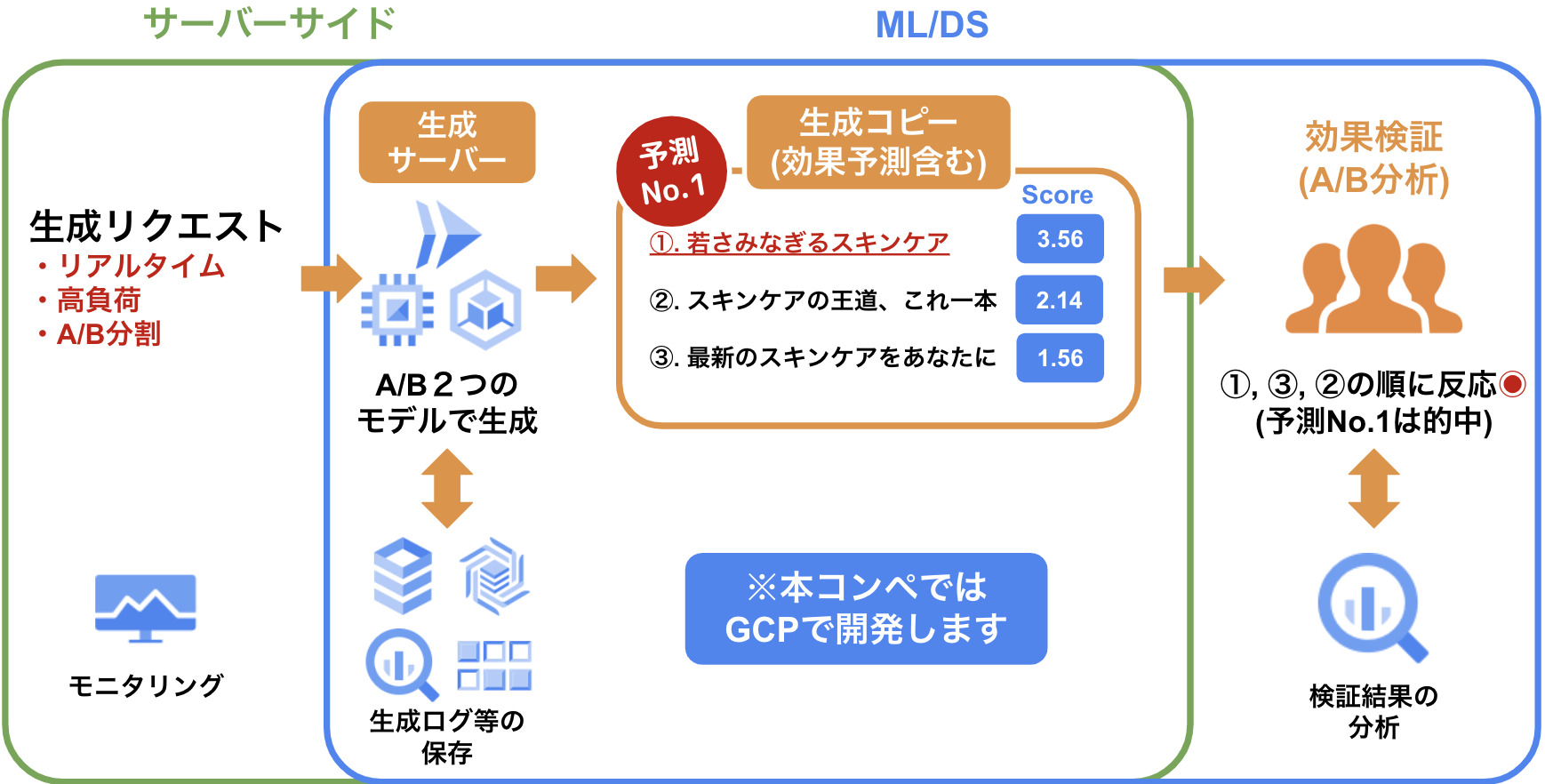
- 生成リクエストに対し使用する生成モデルを決定、広告文をリアルタイムで生成
- 効果予測した生成コピーを選定・ソートしてレスポンスとして返す
- 生成リクエストが全て完了した後、どの生成されたコピーが効果(反応)が良いかを実際に人が見て評価
- 評価を元にどの生成モデルの性能が良いのかを検証する
上の例で①は、効果予測結果No.1と効果検証No.1が一致し、効果の良いコピーが生成された事と言える
この様な流れで広告文を生成し
「どれだけ効果の良い広告コピーを安定して生成しレスポンスできたか」
を競うコンペになります。ここでそれぞれ
- サーバーサイド:リクエストを捌き切るサーバーとインフラ構成
- ML/DS:より効果の良い広告文を生成するモデルの構築・分析
について各々の責務を全うする訳ですが、
「安定して効果の良い広告コピーを生成する事のできる実運用に耐えうる生成サーバー」
については、図にもある通り両者が責務を全うする必要があります。
以降にそれぞれのチャレンジングな(面白い)箇所について触れていこうかと思います。
サーバーサイド
サーバーサイドは生成リクエストを受け取り、ML/DSが作成した生成・予測サーバーを用いて、生成文をレスポンスとして返すAPIサーバーを構築します。
ここでサーバーサイドとしてチャレンジングな(面白い)箇所として
- 大量の生成リクエストが送られてくる
正常な生成結果やレスポンスをリアルタイムに返す必要があります。 - 大規模な深層生成モデルの高負荷な処理を安定的に回す
深層生成モデル、予測モデルを扱うことによりかなりのレイテンシが掛かります。インフラの構成が重要になる局面なども存在します。 - A/Bテストの為のリクエスト分割
複数の生成ロジックを作成しどちらの方が優れているかの分析を行う為にリクエストを適切な基準で分割しなければなりません。
等が挙げられます。特筆すべきは大規模な深層生成モデルを扱いリアルタイムにリクエストを捌き続ける必要があるという点です。
インフラ構成から考える所も含めてサーバーサイドとして、学生時代では中々体験しない実装かと思います。しかし、実際の現場ではこれらは深層学習・生成モデルを根幹とするサービスでは必要不可欠な要素です。実際に自分も現場では深層モデルの実装をしつつもそれをサービスとして実現する為のバックエンドの実装に時間を掛ける事が多いです。
「インフラの経験ないけど大丈夫だろうか…」
と心配になる方もいらっしゃるかと思うのですが募集ページに記載されている様なとても優秀なメンターの方々がサポート・アドバイスして下さるので安心してご参加ください(サポートの手厚さもCAのインターンの印象的な所です)
コンペでは「どれだけ対象となる生成リクエストを正常にレスポンスできたか」という点も評価の対象になります。この辺りはサーバーサイドとして腕の見せ所かと思います。
ML/DS
ML/DSは「生成リクエストの情報からどれだけ整合性のあったコピーを生成し効果の良いコピーをレスポンスとして返すか」、
という所がポイントになります。チャレンジングな(面白い)箇所として
- 整合性が高く効果の良いコピーを生成するための生成手法
前処理からモデルのリサーチ、選定まで、ここは純粋にML/DSとしての力を発揮できる箇所です。 - 生成と効果予測のレイテンシを考慮したモデルの選定
ここが一番今回のコンペ特有になるところです。実際の現場でも実用に耐えうる範囲で性能の良いモデルを実装していくというのが重要になってきます。 - 複数の生成ロジックの優劣を分析する為のA/Bテスト(効果検証)
今回は複数のモデルを用いて生成、実際に人へ生成結果を見せその結果を検証する効果検証を行います。
等が挙げられます。特筆すべきはやはり2つ目、3つ目の所かと思います。研究などにおいても1つ目は実際に行う物かと思いますが実サービスの利用に耐えうる・継続的なモデルの改善の為に実際のフィードバックを用いて検証する事はやはり実務レベルの話であり中々経験する事も無いかと思います。
コンペでは「どれだけ実際に効果(反応)の良い生成ができたか」という点も評価の対象になります。
モデルの選定や実装・最終的な分析はML/DSとしての挑戦ポイントかと思います。また最新の深層生成モデルなどを実装し生成サーバーに載せるという貴重な体験が学生の間にできるのは個人的には羨ましいです。
また本コンペではモデルのベースライン実装を用意しているので、NLP(自然言語処理)の経験がない方でもご気軽に参加いただけます!
サーバーサイド×ML/DSの連携
ここも本コンペの特徴的・一番重要な部分です。書き連ねると長々となってしまう上に当日のネタバレにもなってしまうので一言で
「お互いの要件を理解した上で最善と考えられる技術選定・実装を共に行う」
フローの図からも分かるようにこれに尽きるかと思います。この部分を学生の時点で体験できるのは良い機会だったなと思うので、是非皆さんにも体験頂ければと思います。
コンペを通して得られる物
今回のコンペ(インターン)にて持って帰って頂けそうな物を挙げて締めたいと思います。
技術的な面においては
- 難易度の高い条件において、安定したサーバーの構築とそのインフラ構成
- 最先端のモデルを用いた生成モデルの実装と本番を想定したデプロイ
- 実際のフィードバックを用いたモデルのA/Bテスト(効果検証)
これらは実際の機械学習や深層学習をサービスで活用するプロダクトではマストとも呼べるタスクやスキルだと思います。
擬似的にでもこれらを体験出来る様に運営も実装をしていますので是非ご参加ください。
本番のメンター陣も豪華なメンバーが揃っています。
メンターの詳細な情報についてはこちらの募集ページをご覧ください。
最後に
ここまでは実務レベルの技術的な見識を深めるという点を重視した物でした。
今回のコンペに参加して、スキル的に上手く行かなかった所・失敗してしまった事はその後にしっかり振り返り、技術的インプットをして貰えれば良いと思います。
しかし学生時代に何のしがらみや立場も関係無く純粋に技術的な挑戦を共に楽しみ、関係性を築くのは学生の時しか出来なかった事だと社会人の今となって痛感しています。実際に同じチームで開発をした同期とは今でも連絡を取り、技術的な話やそれ以外の話もします。
何でも気兼ねなく話せる関係性の方が居るのは何より変え難い物です。今回のコンペ以外にもその様な繋がり持てる機会は勿論あるかと思いますが、
「他職種と連携しながら挑戦的な課題に立ち向かう」
という同じ境遇で関係性を深めつつ、技術的なインプットもする一石二鳥なこのインターンで皆さんに出会える事を楽しみにしております!
今年度の極コンペの参加者の方の中から、未来のアドテクコンペの運営の方が出たらこれまた感慨深いなあと妄想しております。
 過去のコンペの設計などの様子、実際に自分と同じチームのサーバーサイドの同期は入社後も
過去のコンペの設計などの様子、実際に自分と同じチームのサーバーサイドの同期は入社後も
仲良くバリバリ頑張っております