
データ集計では簡単に事実と異なる結果を導き出すことができます。しかし、その結果が事実と異なるかどうかを判別することは容易ではありません。なぜ、間違いに気づくことが難しいのでしょうか。
それは、データが誤っているという判断をするためにはドメイン知識が必要になるからです。
そして、ドメインを理解している場合でも、データ量の増加やドメインの複雑化などによって、データにおける品質劣化を特定するのは困難であるからです。
そこで、データの正確性を阻害する原因箇所を早期検知するために、私たちはデータにおけるオブザーバビリティ(Observability)、つまりデータの可観測性を提供するしくみについて考えました。
自己紹介
メディア統括本部 > 技術本部 > Media Data Tech Studio(MDTS)の斎藤と申します。
Media Data Tech StudioはABEMAやAmebaなどサイバーエージェントにおけるメディア事業において、データを用いた事業貢献をミッションとする横断組織です。少し前までは秋葉原ラボと呼ばれていた部署でしたが、一年前にMDTSとして再編されました。
私個人としては秋葉原ラボの時からユーザ行動ログ収集基盤、ストリーム処理システム、ステートフルデータ処理基盤など、データ処理のためのシステムの開発・運用を主に担当してきました。
ここ数年はシステム開発から、データマネジメントの方に軸足を移して業務を行なっております。
今回はデータマネジメントにおいて重要なデータ品質を担保するために取り組んだことについて紹介いたします。
データの異常を検知するのがなぜ難しいのか
最近、Twitter社で三年間DAUの値を誤って算出していたというニュースがありました。
このケースは三年も誤った集計を行っていたということですが、なぜすぐに問題に気づかないのでしょうか。
データの異常を検知するのが難しい理由について以下が考えられます。
データに異常が生じていることに気づかないため
集計や機械学種のモデルのような集約されたデータはビジネスの施策・システムの変更・ユーザーの変化などさまざまな要因の影響を受けます。
その様々な要因が潜むデータの中でバグが発生しても、気づかずにいてしまうというケースはかなり多いと思われます。
データ異常を検知するにはドメイン知識が必要であるため
前述のとおりデータはさまざまな影響を受けて変化します。
その中でデータの変化の原因が品質劣化であると判断するためには、ドメイン知識が必要となります。
逆に言えば、ドメイン知識が無い状態では劣化が原因だと判断することができないのです。
ドメイン知識があっても異常と判断するのは困難であるため
開発が進むほどシステムやデータは複雑化していきます。それに伴いドメインも複雑化し、全体像を把握するのがどんどん難しくなっていきます。
また、品質劣化は様々な原因によって生じます。
-
- 実装のバグ
- 実行環境の変化
- 仕様漏れ
- 想定外の値の入力
- システムへの悪質な攻撃
- etc.
なので、複雑化するドメインを把握した上で、データの中から様々な要因を考慮した上で品質劣化の原因を判断しなければならないのです。
これらの理由から、データの品質劣化を特定するには、まず異常を検知し、ドメイン知識を理解した状態でデータの中身を把握することが必要であることがわかります。
データの品質劣化を検知する手法として、Json SchemaのようなログデータのスキーマバリデーションやDeequのようなデータのユニットテストなど、ルールベースで検知することは可能です。
しかし、ルールを定義するのにもドメイン知識が必要であり、全てのデータに対し網羅的にルールを定義するのは困難です。また、ルールベースの難しい理由としてルールの仕様漏れ、ルールの曖昧性などが考えられます。
では、どうやってデータの品質劣化を検知すればいいのでしょうか。そこで、一度基本に戻って一般的なソフトウェアシステムでの監視について考えてみます。
一般的なソフトウェアでの監視について
障害を判断するのが難しいのは、データだけの話だけではなく一般的なソフトウェアシステムでも同じです。
ソフトウェアシステムの障害の原因を判断する場合でもドメイン知識が必要であり、開発が進む上でドメインは複雑化していきます。
では、一般的なソフトウェアシステムではどうやって障害を検知するのでしょうか。
ソフトウェアシステムでは、まず基本メトリクスを取得します。
基本メトリクスとは、CPU利用率やディスクI/O、ネットワークI/Oなど、ソフトウェアのドメインと関係なくシステムの構成要素によって取得できる観測値です。
ソフトウェアに障害が発生すると、基本メトリクスの値に変化が生じます。
例えばディスクが破損すると、読み取り・書き込みができなくなり、ディスクI/Oの値が0に変化します。このようなメトリクスの変化を観測することで障害を検知することができます。
基本メトリクスの変化を観測するのに、ドメイン知識は必要ありません。
このようにシステム内部で何が起こっているかを観測できるような性質をオブザーバビリティ(Observability、可観測性)と呼びます。
そして変化の検知後、障害の原因を特定します。原因を特定するためには、ドメイン知識が必要になります。
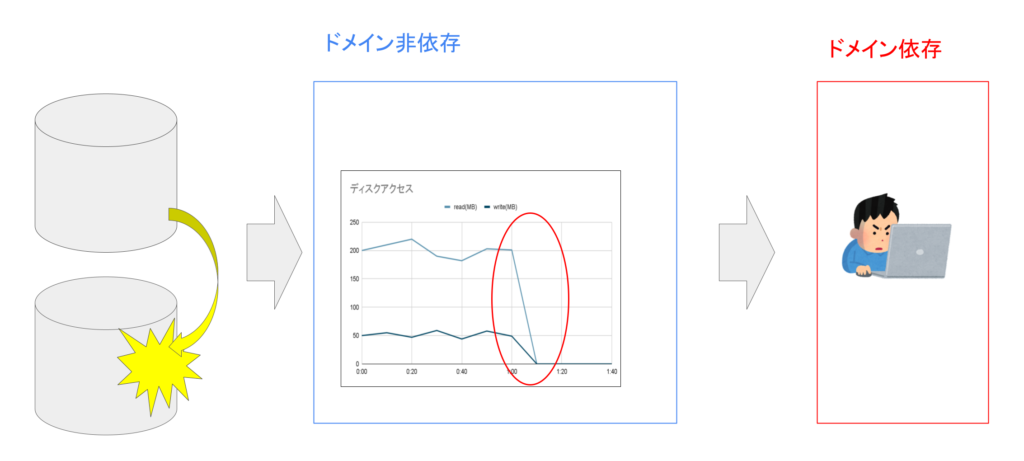
このようにソフトウェアシステムでは、構成要素によって決まるメトリクスを収集し、メトリクスの変化を観測することで、ドメイン知識がなくても障害の検知を実現しています。
そこで、我々はデータにおいても同様の手法を用いることができないかと考えました。
提案手法
「データに対しても基本メトリクスを定義することで可観測性を備えることができ、メトリクスの変化をみることでデータにおける品質劣化の検知が可能になるのではないか。」というのが我々のアイディアになります。
データの構成要素
まず、データの構成要素について定義します。
データはレコードの集合であり、レコードはフィールドの集合です。
フィールドの構成要素は下記のようなものが考えられます。
- 値
- フィールド名
- データ型
- Required/Optional
- 値域
- フォーマット
- etc.
フィールドの構成要素のうち、値以外はカラムによって規定されます。
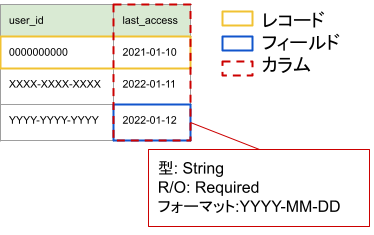
これらの構成要素から得られる情報を元に基本メトリクスを定義します。
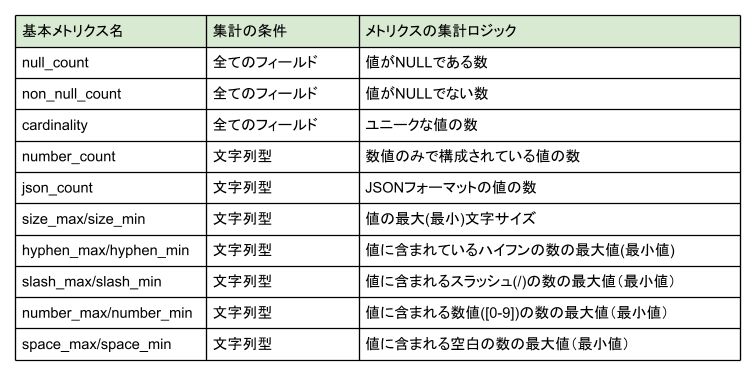
基本メトリクス
基本メトリクスはフィールドの構成要素に基づいて決めることができます。
基本メトリクスはメトリクスを集計可能かどうかを判断する構成要素の条件と、フィールドからメトリクスを集計するためのロジックを与えられます。
基本メトリクスの例
例えば、下記のような三つのレコードがあったとします。
このレコードからメトリクスを集計するケースについて考えます。
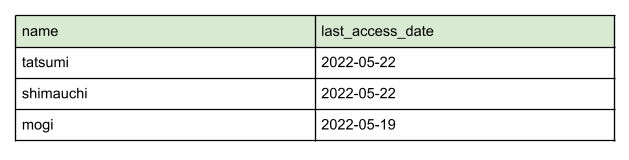
nameフィールドのsize_maxとsize_minメトリクスを算出することを考えます。
このとき各nameフィールドの値の長さをみると、len(”tatsumi”) = 7、len(“shimauchi”) = 9、len(“mogi”) = 4となります。よって、nameフィールドのsize_maxは9、size_minは4となります。
また、last_access_dateフィールドのcardinalityメトリクスを集計する場合はどうなるでしょうか。
last_access_dateフィールドには”2022-05-22″と”2022-05-19″の二種類の値のみが存在します。よってlast_access_dateフィールドのcardinalityは2となります。
これらの基本メトリクスはデータに不具合が生じると値の傾向が変化します。
なので、発想を転換して不具合や障害内容から集計するメトリクスを考えることもできます。
例えば、nameフィールドに「SELECT * FROM users WHERE name = “a” OR 1=1」のようなSQLインジェクションを狙ったと思われる値が入ることを検知するためにはどのようなメトリクスが有効でしょうか。
このようなSQLクエリの値には、必ず空白文字が入ります。
なので、SQLインジェクションを狙った値では、値に含まれる空白の数が変わるのでspace_maxやspace_minに変化が生じると考えられます。
システムアーキテクチャ
基本メトリクスを使って、品質の劣化を検知するシステムについて紹介します。
システムのアーキテクチャは図のようになります。
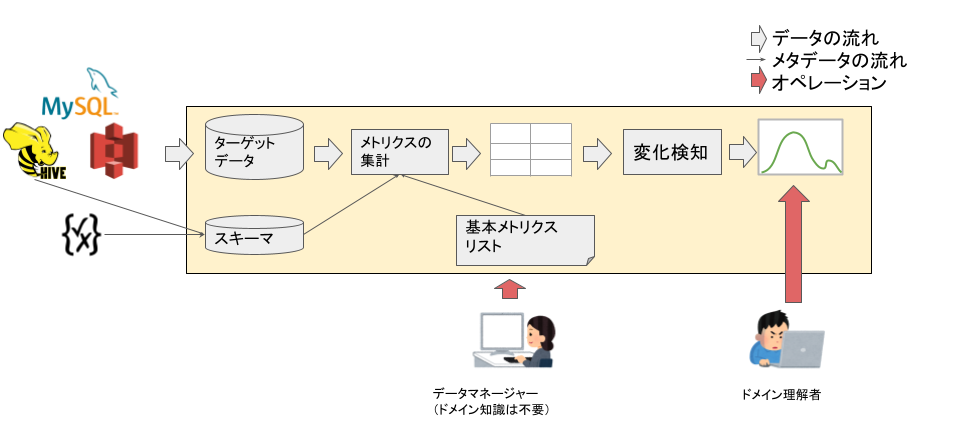
品質検知を行う前の準備として必要なデータと情報を用意します。まず、品質メトリクスの入力となるデータをターゲットデータと呼び、データの構成要素のメタデータをスキーマと呼びます。
DWHやデータカタログなどに存在するこの二つのデータを、品質検知システムから参照できるようにします。
そして、集計したい基本メトリクスのリストを用意します。図中ではリストを作成するのはデータマネージャーとしていますが、この基本メトリクスはデータに関するドメイン知識とは関係がないので、データの品質を監視したい人であればだれでも定義できます。
データが用意できたらメトリクスを集計します。スキーマと基本メトリクスリストを照らし合わせ、基本メトリクスの集計条件に合うフィールドに対し網羅的に基本メトリクスを集計します。当たり前ですが、データサイズとメトリクス数が増えるとその分メトリクスの集計時間がかかるので注意してください。
そして集計したメトリクスに対して、変化検知を行います。メトリクスが大きく変化したフィールドが検知できたなら、ドメイン理解者がその原因を判断します。
検知の実例
メトリクスをつかったデータの変化検知の実例を紹介します。
実際のデータを使っているので具体的な数字や名称をお見せするのが難しいのでかなりボカした表現となりますが、ご了承ください。
環境
- 弊社の提供するサービスにおけるユーザーの行動ログデータ
- 基本メトリクスは一日ごとに集計
- 一日あたりの基本メトリクスの総数は約11万個
- 基本メトリクスリスト
- 前述の基本メトリクス一覧のメトリクスを集計
- 異常検知ロジック
- 過去14日分で各メトリクスごとに移動平均・移動標準偏差をとり、当日のメトリクスで偏差値を算出する
- たとえば2022/04/15の偏差値を出すには2022/04/01~2022/04/14の間のメトリクスが必要となる
- 偏差値の乖離が大きいフィールドを変化が生じたとみなしレポーティングする
- 過去14日分で各メトリクスごとに移動平均・移動標準偏差をとり、当日のメトリクスで偏差値を算出する
変化検知の例
この変化検知でフィールドfield_a(偽名)のsize_maxメトリクスにおいて著しく高い偏差値を観測しました。つまり、2022/05/15のfield_aフィールドの文字数サイズに大きな変化が生じていることを表します。
下の図は2022/04/01〜2022/04/15の間でのsize_maxの変化になります。2022/04/15が著しく変化しているのがわかります。

この後、フィールドの値を精査したところ2022/05/15のfield_aには、著しく長いURL形式の値が入っていたのが確認できました。この値が異常値かどうかについては、ドメイン理解者が判断する領域で記事の範囲外になります。
また、他のフィールドfield_b(これも偽名)においてはメトリクスの値がそれまでの傾向と比較して大きく下回るケースもありました。
field_bではnumber_count(値の中身が数値型である値の数)が2022-04-01に突然それまでと比べて大きく下がっています。
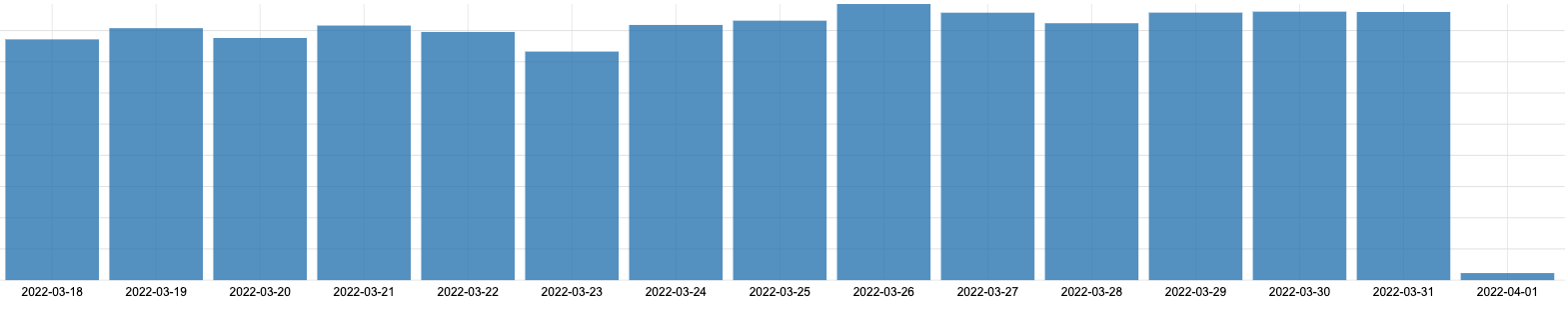
ドメイン理解者はこの値を見て、例えば先月の月初(2022-03-01)も同様に大きく値が下がっていたかを調査したり、あるいは2022-04-01にサービスで何かリリースがあったのかを確認したり、原因を探求するためのアクションをとります。
考察
このようにデータ異常検知システムによって、データの品質が劣化している可能性があるところを特定することができるようになります。
しかし、このシステムにはまだ考えなければならないことが多く存在します。
- メトリクスの種類の拡充
- 例にあげたのは型情報のみだったが、型情報以外のメタデータを使った基本メトリクスも考えられる
- またフィールド間の相関性など、複数フィールドを入力とする基本メトリクスも考えられる
- 集計するメトリクス数が増えると集計に時間がかかる
- メトリクスの同じ処理は一度だけ行うようにする最適化
- 例えば各フィールドの文字サイズを計測し、その結果の最大値と最小値をとればsize_maxとsize_minの二つのメトリクスが取得できるので、文字サイズの計測は二度行う必要はない
- メトリクスの選定
- 前述の通り、障害とメトリクスには相関性があるので、障害検知の面で有益なメトリクスとそうでないものがあると考えられる
- しかし、メトリクスを限定すると検知できなくなる品質劣化のケースがあるので集計コストと検知性能はトレードオフの関係にあると考えられる
- メトリクスの同じ処理は一度だけ行うようにする最適化
- 基本メトリクスの変化が全てデータ劣化に関係するとは限らない
- 例えばシステムリリースによってもデータの傾向は変わることがありえる
- なので、データ劣化と基本メトリクスの変化にどのような関連性があるのかも考慮
今後はこれらの課題をどう改善していくかを考えていきたいと思います。