
はじめに
AI事業本部で23卒 DS/MLエンジニアとして内定者アルバイトをしている大石です.舘山さんと渡部さんをはじめ,極予測AI 予測開発チームの皆様には大変お世話になりました.また,半年跨ぎにはなりますが脇本さん,黒田さんをはじめとする極予測AI 素材開発チームの皆様にも大変お世話になりました.本当にありがとうございました.
今回,AI事業本部の極予測AI 予測開発チームで広告効果予測モデルの精度改善に関して着手したのでレポートにさせていただきました.少しでも予測開発チームやAI事業本部の雰囲気が伝われば幸いです.
AI事業本部 極プロダクト
AI事業本部には極予測AI,極予測LP,極予測TDなどの様々な極プロダクトが存在しており,各プロダクトごとにAI×クリエイティブをテーマにした研究および開発を行なっています.
私は極予測AIの中で予測開発と素材開発の2つのチームに合わせて半年間ほど所属していましたが、実務を通じてAIが主軸として活用されるアドテクの最前線を肌で感じることが出来ました.
関連記事
効果予測AIで広告クリエイティブの効果最大化を図る「極予測AI」導入で、CVR170%改善・CV数も大幅拡大
予測モデルの現状と課題
私が極予測AI 予測開発チームで就業し,着手していた広告効果予測モデルはこれまでにサイバーエージェントが配信してきた広告及びその配信実績のログデータから広告の Cost をマルチモーダルなモデルを用いて推定するといったものです.
このモデルは広告が配信されている Twitter や LINE などの各媒体毎に存在し,その媒体に設定されている画像やテキスト,配信設定のデータが特徴量として用いられています.これによって,クリエイティブの視覚的情報や具体的な内容といった情報からクリエイティブの価値を考慮しているのですが,動画広告に含まれているBGMなどの音響情報は考慮されていません.
音響情報はユーザーに対して動画広告の印象を与えるための重要な要素になります。そこで,動画を用いた広告効果予測モデルにおいて音響特徴量を組み込んだモデルを構築し、既存モデルとの精度を比較する実験を行いました.
余談ですが,サイバーエージェントでは「音声」に関しての研究はここ最近で力を入れてますが「音響」に関してはまだAI事業本部内でも取り組みもないにも関わらず,内定者バイトに新しい挑戦を行わせて頂ける所に改めて社風の良さを感じました.
音響特徴量の追加
音響特徴量を加えるにあたり,複数の前処理やモデル機構を検討しました.
具体的には,音響全体を横軸が時間・縦軸が周波数であるメルスペクトログラムに対して,2D CNNモデルにかける手法や一定時間の一定フレームレートで抽出した音響信号に対して1D CNNモデルを用いる手法などを実験的に試していきました.
作成したモデルの評価として、ある期間でのデータセットから既存で運用されているモデルで学習したものをベースラインとして,音響特徴量を加えたモデルとそれぞれを比較していきました.
まず始めに音響情報はどのタイミングでも全てが重要であると仮定し,音響信号全体をスペクトログラムの画像として捉え MobileNet v2[1] などの転移学習モデルで特徴を抽出してマルチモーダルモデルを学習させた所,下の図のように過学習してしまうような傾向が見られました(横軸: Epoch, 縦軸: Loss)
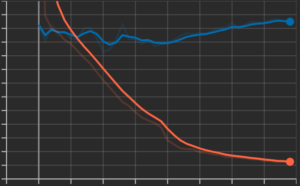
その後,過学習対策を色々試しつつ,浅いCNNモデルを用いて特徴を抽出することを試みると今度はLossが転移学習モデルを用いた場合と比べると下がらないといった結果になりました.
これらの結果を踏まえて今回のデータではスペクトログラムに対して画像処理的な手法ではあまり精度改善が見込めないことが分かりました.そこで,次に音響信号に対して特徴を抽出するようなアプローチに変更して再度実験を行いました.内容としては元の音響信号からある固定長分切り出した音響信号に対して,Conv 1D を複数回繰り返すような浅いモデルを用いて特徴を抽出してモデルの学習を行いました.
すると,下の図のように過学習の傾向が少なくなるような結果が得られました(横軸: Epoch, 縦軸: Loss)
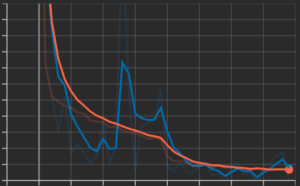
しかし,Lossとは別に計測している評価指標の精度はベースラインから横ばいであまり向上しませんでした.これらの結果から広告に特化した音響特徴というものがそもそも上手く抽出できていないのではないかという仮説が現れました.
そこで,音響に関する事前学習モデルを用意し,音響情報をある程度理解した上でのモデルであれば精度の向上を図れないかを検討していきました.
音響に関する事前学習モデル
前節の実験で現れた広告に特化した音響特徴というものが, 上手く抽出できていないのではないかという仮説に対して音響の事前学習モデルを作成することで解決できないかを実験しました.
音響を理解するような事前学習モデルを作成する上でラベルを付与する難しさやコストがあったため、教師が不要である自己教師あり学習モデルを選ぶ必要がありました.その中でもここ最近に発表され,高い性能を示していた COLA [2] を今回は試していきました.
このモデルをサイバーエージェントがこれまでに制作および配信されたデータセットを元に学習を行うことで、Fitすることができました.
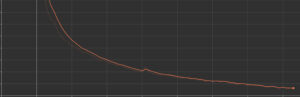
事前学習モデルの作成が完了した所で,このモデルを音響特徴器として効果予測のマルチモーダルモデルに組み込み,ベースラインとのValidation の損失関数(Val Loss) およびTest データでの評価指標(Offline Index)について比較をしました.
すると,ベースラインと比べてVal Loss(↓) は 4.9% 低下し,Offline Index(↑)は 6% 向上しました.このことから,広告に特化した音響特徴をうまく抽出することが効果予測を行うマルチモーダルモデルにおいて有効である可能性が示しました.
今後の課題としては,広告音響をより特徴づけられる事前学習モデルの検討や作成した大規模事前学習音響モデルを AI事業本部でどのように活用していくのかの検討が挙げられます.
最後に
内定者アルバイトを通じて,入社前からサイバーエージェントに抱いていた挑戦できる環境というのは間違っていなかったと強く感じました.
理由としては私はこれまで画像とグラフのデータ分析をそれぞれ単体でしか扱ったことがなく,配属の段階ではマルチモーダルおよび音響情報処理に関しては全くの知識がない状態でしたがそんな私に学びながら実際に触ることができる環境を与えて貰え,前例がないことでもどんどんチャレンジしていける文化があったからです.
そんな環境の中で今回,AI事業本部で就業して2つの難しさを感じました.
- 1つ目が広告ドメインの難しさです
- 近年発展してきている機械学習において通常の自然なデータとは異なる広告データの特徴を取ることを目指した解決済みタスクが極めて少ないからです
- 2つ目が仮説を立て,仮説を検証するための目的変数策定の難しさです
- 実務においてはどこでも重要な話であり,何をしたいのか何を叶えたいのかを考え,それを実現させるためにはどんなデータが必要でどのデータを追っていけば良いのかを考える必要があります
- 今回の実務においても仮説の甘さが出た場面などがあり,今後重点的に鍛えていかなければならないと感じました
このように学びが沢山あった一方で,楽しさも勿論沢山ありました.業務内容以外のお話で今回の内定者アルバイトでは自分は関西に住んでいるため基本的にフルリモートの形だったのですが,頻繁に 1on1 などを行なって頂き要所要所で相談しながら楽しく進めていくことができました.
また,数日現地に出社する場合があったのですが,極チームの方や他の 23卒内定者,人事の方との交流がたくさんありとても楽しかったです(めっちゃ肉食べた)



また,極予測AI トレーナーの舘山さんに前処理パイプライン1発実行記念にアイスを食べに連れていって貰ったり,極予測AI 素材開発の脇本さんにボルダリングに連れていって貰ったりと入社前から先輩社員と関わりを持てるのもとても良かったです.

改めまして,多くの知識と経験を積ませていただいた舘山さんと渡部さんをはじめ,暖かく迎えてくださった AI事業本部 極プロダクトの皆様には大変お世話になりました.
ありがとうございました.
■出典
- Sandler, Mark, et al. “Mobilenetv2: Inverted residuals and linear bottlenecks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
- Saeed, Aaqib, David Grangier, and Neil Zeghidour. “Contrastive learning of general-purpose audio representations.” ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021.