
この記事はCyberAgent Developers Advent Calendar 2016 24日目の記事です。23日目はdekatotoroさんの「Apple TV – tvOS入門」でした。
こんにちは、AbemaTVサーバサイドエンジニアのギアです。
去年は新卒のiOSエンジニアとして、「ReactiveCocoaとMVVMモデル」という記事を書きましたが、今年はサーバサイドに関することを書きます。
はじめに
この前にAbemaTVはモニタリング・アラートのため、主にStackdriver, Bugsnag, StatusCakeというサービスを使っています。しかし、Stackdriverはデフォルトである程度のGCP (Google Cloud Platform) 上のリソースに対するメトリクスしかありません。各マイクサービス間の通信やサービスのカスタマイズメトリクスなどのアプリケーションレベルのメトリクスも収集し、監視したいので、良い時系列データベース、良いモニタリングサービスを探しました。
その時にTop10 Time Series Databasesの記事を読みました。この記事では現在有名な時系列データベースの比較について述べました。DalmatinerDB, InfluxDB, Prometheus, OpenTSDBなどの様々な時系列データベースについてのパフォーマンスから、サンプルのサイズ、クエリ言語、データモデルまで具体的な比較は記事内に述べたOpen Source Time Series DB Comparison スプレッドシートに掲載されています。 それらの時系列データベース中にDalmatinerDBは一位ですが、我々はAbemaTVにPrometheusの導入を選択しました。
今日Prometheusを選択した理由も含めて、Prometheusで何ができるか、AbemaTVでどのように設定・利用しているか、Prometheus内部のアーキテクチャまでも話したいと思います。
Prometheus紹介
Prometheusは、オープンソースのサービスモニタリングシステムです。開発は音楽のソーシャル・プラットフォームを展開しているSoundCloud社によって2012年から行われています。現在の最新バージョンは1.4.1です。Githubでのリポジトリを見てみると、現在でも活発に開発されているようです。
Prometheusの特徴としてまずはメトリクス収集方式としてPull型を採用していることです。おそらくほとんどのモニタリングシステムはPush型だと思います。
Push型はモニタリング対象サービスからモニタリングサーバにメトリクスをpushするというモデルです。この型だとモニタリング対象が増えてもモニタリングサーバの設定変更などをしなくても良いというメリットがあります。しかし、モニタリング対象ではないホストがメトリクスをpushしても受け入れてしまいますし、メトリクスを受け取れない場合に障害なのか、pushを止めただけなのか、判断できないというデメリットが存在しています。
逆に、Pull型はそいうデメリットを解決できますが、モニタリング対象サービスを変更するとモニタリングサーバの設定を変更する必要が発生します。PrometheusはHTTP経由でモニタリング対象サービスへ定期的にメトリクスを取りに行くPull型です。そう言っても、PrometheusはService Discoveryを提供しているため、GCP, AWS, Azureなどで動いているサービス対象を自動検知することができ、設定の変更をする必要がなくなります。
次の特徴は多次元データモデルです。全ての時系列はメトリクス名とkey-value pair(ラベル)セットから構成されます。
http_requests_total{method="POST", handler="/tracks"} -> 35
例として、上の時系列はhttp_requests_totalのメトリクス名とmethod="POST", handler="/tracksのラベルで識別しています。 実際の内部にはメトリクス名も__name__というラベルキーとしてハンドルしているようです。
{__name__="http_requests_total", method="POST", handler="/tracks"} -> 35
ということは上の時系列は __name__="http_requests_total, method="POST", handler="/tracksのラベルセットで識別します。 つまり、全ラベル集合の中にあるラベルセットから一つの時系列を表現することができます。
Prometheusは上記の多次元データモデルを基づいて設計されているので、PromQLという独自のクエリ言語を提供し、ラベルベースにクエリを行っています。多次元データモデルのおかげで、クエリにのフィルタリングやアグリゲーションが簡単にできると書かれています。そして、スカラー、ベクトルの演算子、sum, rateなどのようなクエリに役に立つ関数もたくさん用意されています。
Prometheusは時系列データベース以外に、AlertManagerも提供しています。AlertManagerはアラートのgrouping, deduplicatingなど設定でき、emailやslackなどの外部サービスに通知できるものです。
Prometheus選択した理由
上にも言いましたが、Top10 Time Series Databasesによると、DalmatinerDBは一位ですが、今回我々はPrometheusを選択しました。次に選択の理由について説明します。
一つ目の理由として、PrometheusはKubernetesの友人です。Kubernetesで動いているPrometheusは設定がシンプルで、下の図のように、アプリケーションレベルからコンテナ、ホストまでの色々なメトリクスを収集することができるようになります。そこで、各メトリクスレベルは別々のモニタリングサービスを利用するのは要らなくなり、すべてのメトリクスはPrometheusで収集を行えます。
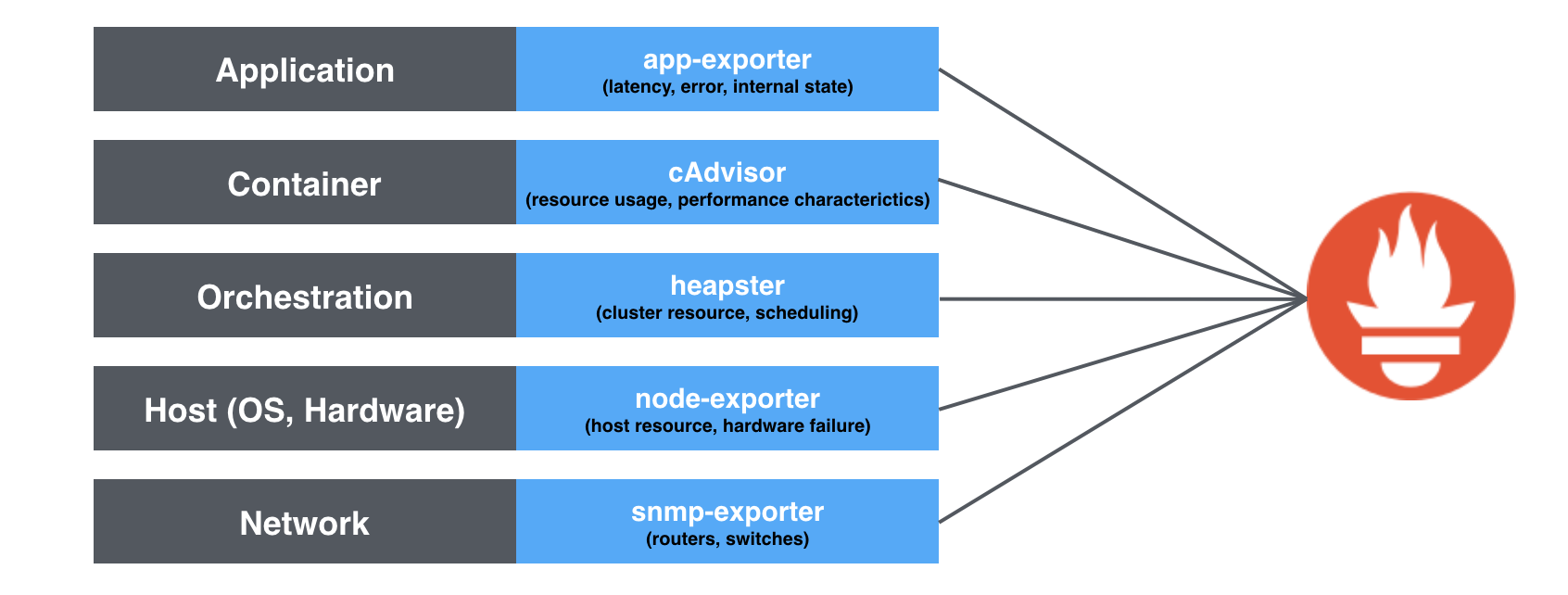
PrometheusはPull型ですが、Kubernetes向けのService Discoveryが優秀すぎて、pod, nodeの自動検知に便利です。特にクラウドのようなダイナミックな環境にpod, nodeはいつでも削除・再作成される可能性があるので、PrometheusのService Discoveryの役割は非常に重要です。 現在AbemaTVではGoogleクラウドとKubernetesを積極的に利用しますので、これは一つの大きな理由です。
二つ目はPrometheusの性能です。 パフォーマンス面で言うと、一つのPrometheusサーバは800K samples/sまでハンドルできると書かれています。例えば、一つのモニタリング対象は800時系列があり、かつ10秒の間隔でメトリクスを収集している場合にも、10000対象まで扱えます。さらに、Prometheus Federationも提供しているので、もっとスケールしたい場合にもすぐできると思っています。 データ量の面でも素晴らしいです。普通圧縮していない場合は1 sampleあたり16bytes(timestamp: 8bytes, value: 8bytes)が必要です。OpenTSDBは12bytes/sampleです。Prometheusは1.3bytes/sampleだけです。圧縮率は12.3倍は素晴らしい数字です。
三つ目はPrometheusがPromQLという素晴らしいラベルベースのクエリ言語を持っています。 PrometheusはSQLクエリを利用するではなく、独自開発したクエリ言語を使います。「へ、なんでSQL使わないの?」という質問がありましたら、Prometheusの作者は以下の回答がありました。
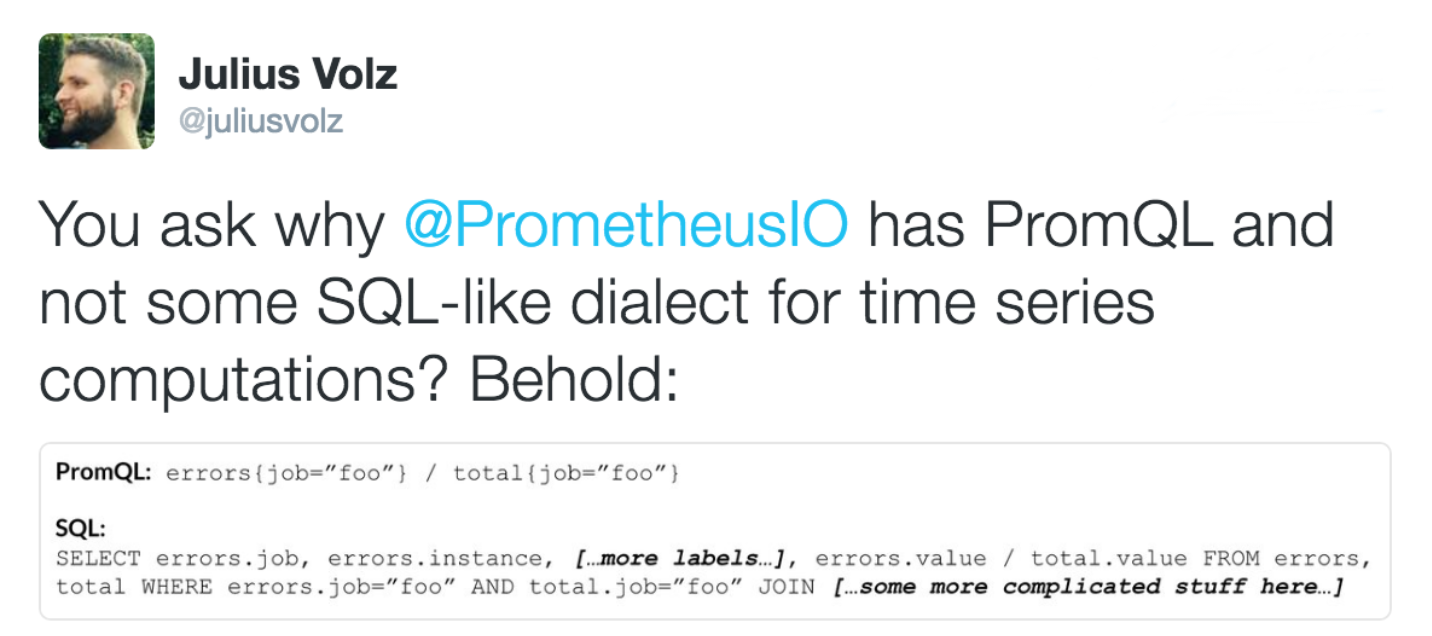
確かに初めて使いますが、クエリ書きやすくて、見やすいです。 直近5分間でのrequests/secondを計算するのは以下のようなクエリです。
rate(http_requests_total[5m])
もうちょっと複雑なクエリを見てみましょう。あるサービスの直近5分間での500系で結果としたrequests/secondをhandler毎にグルーピングすると以下のようなクエリです。
sum(rate(http_requests_total{service="service-name",status=~"^5..$"}[5m])) by (handler)
上のクエリで、結果の以下のような感じです。
{handler="/v1/search/slots"} 0.000137931034482758
{handler="/v1/slotAudience"} 0
{handler="/v1/slots/:slotId/comments"} 0
{handler="/v1/announcements"} 0
四つ目はPrometheusとGrafanaは友人です(やっぱり友人は多い方がいいですね)。現在、Grafanaのbuilt-inデータソースはPrometheusが入っていますので、PrometheusのデータをGrafanaで可視化するのは簡単です。
五つ目はアラート機能とAlertManagerです。最近Grafana4.0もアラート機能を提供していますが、それを使うとPrometheusへのクエリ数がだいぶ増えるじゃないかな個人的に考えています。Prometheus自身のアラート機能はアラートルールに基づいて、アラート検知を行っています。自分自身の機能なので、内部に何か最適化できているかなと考えて、Prometheusのアラート機能を使ってみたかったです。さらに、PrometheusはAlertManagerも提供し、アラートのgrouping, deduplicatingなどを行った後の結果のみをemailやslackなどに通知します。そこで、同じサービスの似ているアラートをたくさんの通知が来るのを避けることができます。
最後の理由としてはPrometheusがGolangで書かれていることです。AbemaTVもGolangを使っていますので、Prometheusの資料に述べていないことがある時やPrometheus内部みたい時などにすぐわかるので、良いと思います。
AbemaTVでのPrometheus
次はAbemaTVでPrometheusをどいう設定、どいう感じに使っているかについて説明します。
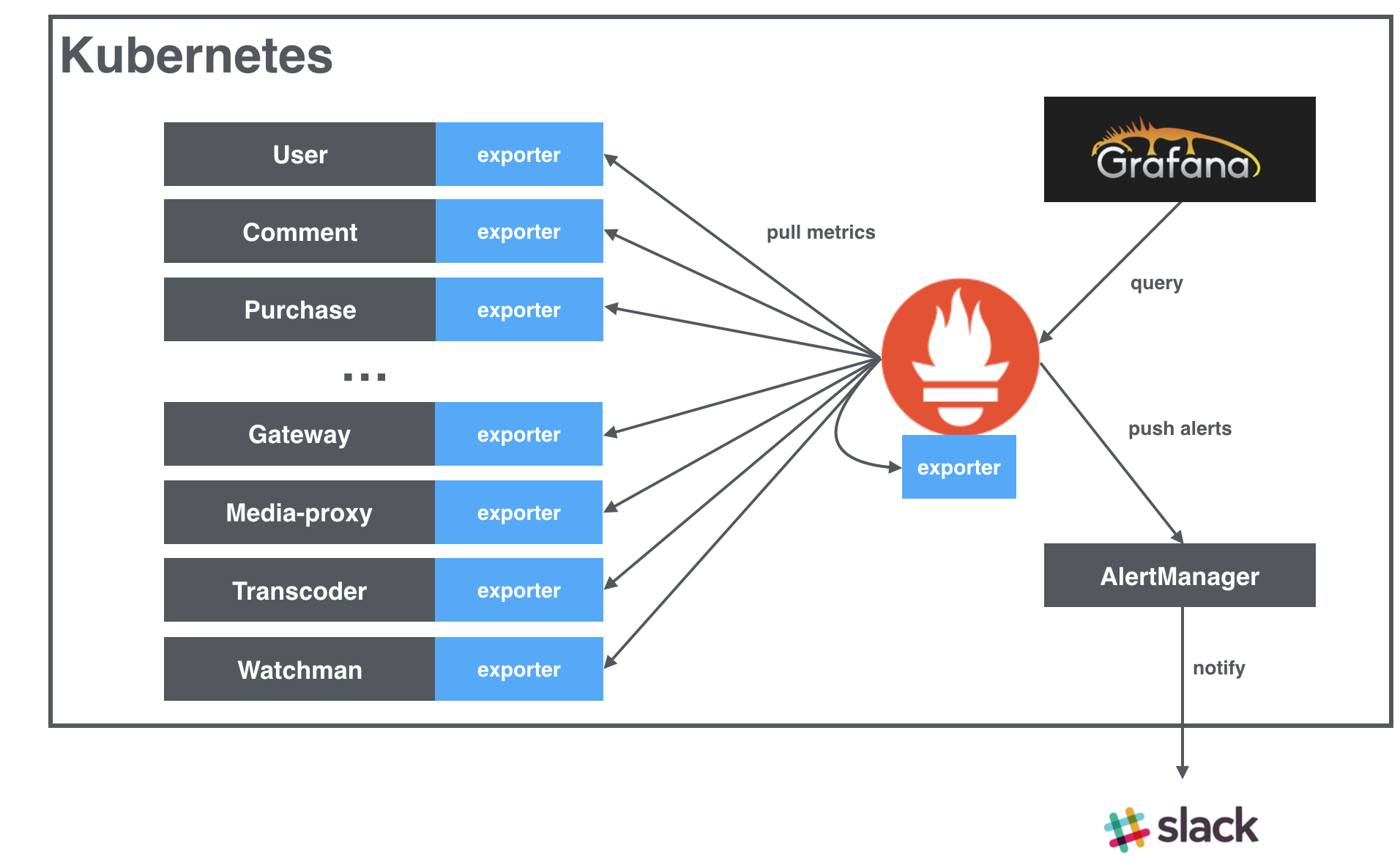
AbemaTVではGCPとKubernetesを利用していますので、全てのPrometheus, AlertManager, GrafanaのコンテナーはGCPの上にKubernetesで管理を行われています。また、PrometheusはAbemaTVの他のマイクロサービスと同じクラスタ内に動いています。
上の図のとおり、Prometheusは自分自身も含めて、クラスタ内の各マイクロサービスからexporterを通して、アプリケーションレベルのメトリクスを収集しています。アプリケーションレベルのメトリクスなので、サービスによって異なり、exporterは自分で実装する必要があります。AbemaTVでは基本的にGRPCのメトリクスのexporter、HTTPのメトリクスのexporter、Batchのメトリクスのexporter、動画処理・配信のメトリクスのexporterなどを作成しました。そして、各マイクロサービスでは必要なexporterを利用し、メトリクスを出力しています。
Prometheusで各マイクロサービスのpodsからアプリケーションレベルのメトリクスを取集するために、以下のようにKubernetes向けのService Discoveryを設定しています。
global:
scrape_interval: 30s
scrape_timeout: 30s
rule_files:
- '/etc/prometheus-rules/*.rules'
scrape_configs:
- job_name: 'endpoints'
scrape_interval: 10s
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: (.+)(?::\d+);(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_service_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
上の設定の大事なところは2つがあります。
- 一つ目は
role: endpointsです。一つのサービスは複数podsで動いていますので、サービズの全てのendpointsのexporterからのメトリクスを収集するための設定です。 - 二つ目は
relabel_configsの最初の3行です。この設定の意味はクラスタ内のscrape=trueを設定しているサービスのみをメトリクスを取集することです。
そして、メトリクスを取集したいサービスのservice.ymlに以下のようなのannotationsを追加するだけです。
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "30001"
それではアプリケーションレベルのメトリクスの収集の設定は以上です。PrometheusのService DiscoveryはKubernetes APIを利用し、新く作成されたpod、削除されたpodを自動的に検知し、収集ターゲットリストを更新します。
コンテナーやホストなどの他のレベルのメトリクスのexporterの実装は不要です。収集したいものは上のconfig.ymlに適切なroleを設定し、メトリクスを収集できます。
ディスク・メモリの設定
まずはPrometheusで必要なディスク量についてです。ディスク量は以下のことに依存しています。
- 時系列数
- メトリクスの収集間隔 (
scrape_interval) - メトリクスの保存時間(
storage.local.retention) - エンコードタイプ
例えば、1週間のデータを保存し、メトリクスの取集間隔は10sを設定すると
storage.local.retention = 168h (1w) = 168 * 60 * 60s
scrape_interval = 10s
==> number_of_samples = 168*60*60/10 = 60480 (samples)
→ 保存必要のサンプル数は 60480 samplesです。
また、時系列数は130kの場合とデフォルトのエンコード(Double Delta: 3.3 bytes/sample)を利用すると
130k * 60480 * 3.3 ~= 26GB
→ 必要なディスク量は約26GBです。
上の設定で実際に使ってみてからディスク量を見てみると、26.3GB でした。 ラベルなどのメタデータもありますので、少し違いますが、こういう感じで正確に計算できると思います。 (Varbitというエンコードタイプを利用すると 1.3 bytes/sampleなので、10GBぐらいになります。すごいですね。)
ディスク量の計算は上のように正確に計算できますが、現在のPrometheusは利用するメモリ量の計算は正確に出来ません。現在のPrometheusではメモリ内に保存するchunk数の制限は以下のパラメータで設定できます。
storage.local.memory-chunks: デフォルトは 1024*1024 = 1048576 chunks
→ chunkのサイズは1024 bytesなので、デフォルトでchunkの必要のメモリ量は1GBです。
しかし、利用するメモリは来たメトリクスの一時保存のためだけではなく、オバーヘッドやPromQLで利用するのも必要となリます。 後者の分は現在正確に計算が難しくて、Prometheusの資料によると、トータル必要なメモリはchunkの必要なメモリの3倍ぐらいで設定することをお勧めしています。 私のケースは4倍(4GB)を設定してみたんですが、たまにメモリのlimit値を超えて、リスタートされることがあったので、現在7GB設定しています。
もちろん、時系列数によってstorage.local.memory-chunksを変更することが必要です。最低限で一つの時系列は3chunksぐらいのお勧めがありましたので、130k 時系列の場合は 390000chunksぐらいで良いらしいです。
また、適切なchunk数を判断するときに、Grafanaなどの可視化サービスからのクエリはクエリtime rangeも含めて考えた方がいいと思います。例えば、Grafanaのデフォルトのクエリ time rangeは6時間(last 6h)なので、一つのクエリの各時系列は2160 samples ~= 7 chunks ぐらい必要になり、storage.local.memory-chunksを上げた方がいいかもしれないです。
Grafanaとの連携
Prometheus自身でもグラフ化機能を持っていますが、可用性と機能についてGrafanaと比べられないと思います。Grafanaはダッシュボード、テンプレート、アノテーションなどの良い機能があります。今回我々もGrafanaを導入し、Prometheusと連携し、Prometheusのデータをグラフ化しています。 GrafanaのダッシュボードのjsonファイルはKubernetesのConfigMapとして扱っています。そして、dockerfileにコンテナー起動時にGrafana APIでダッシュボードをインポートするスクリプトを実行させています。
以下は幾つかのダッシュボードの写真を投稿しています。
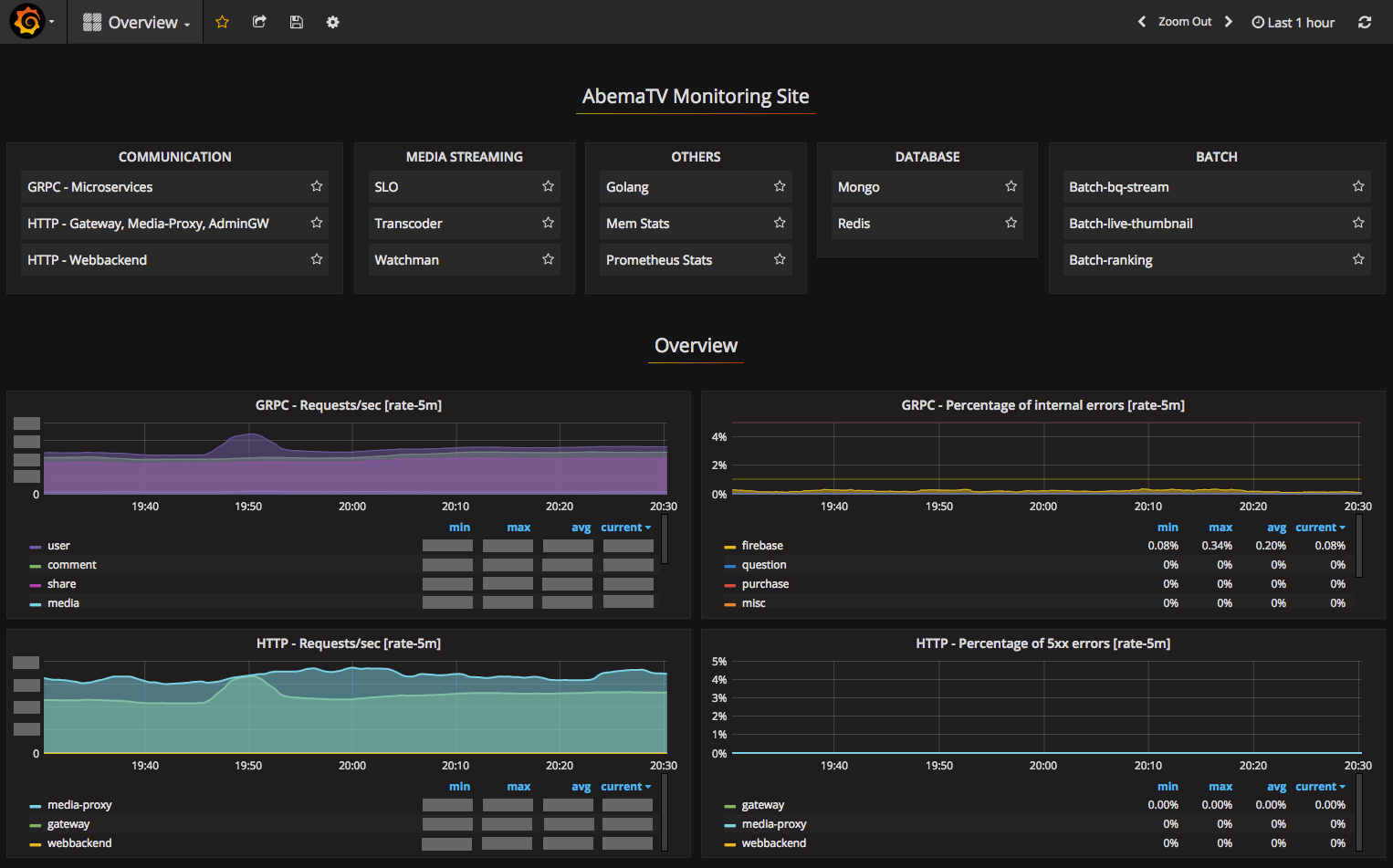
AbemaTVでは色々なメトリクスを収集・監視を行っています。
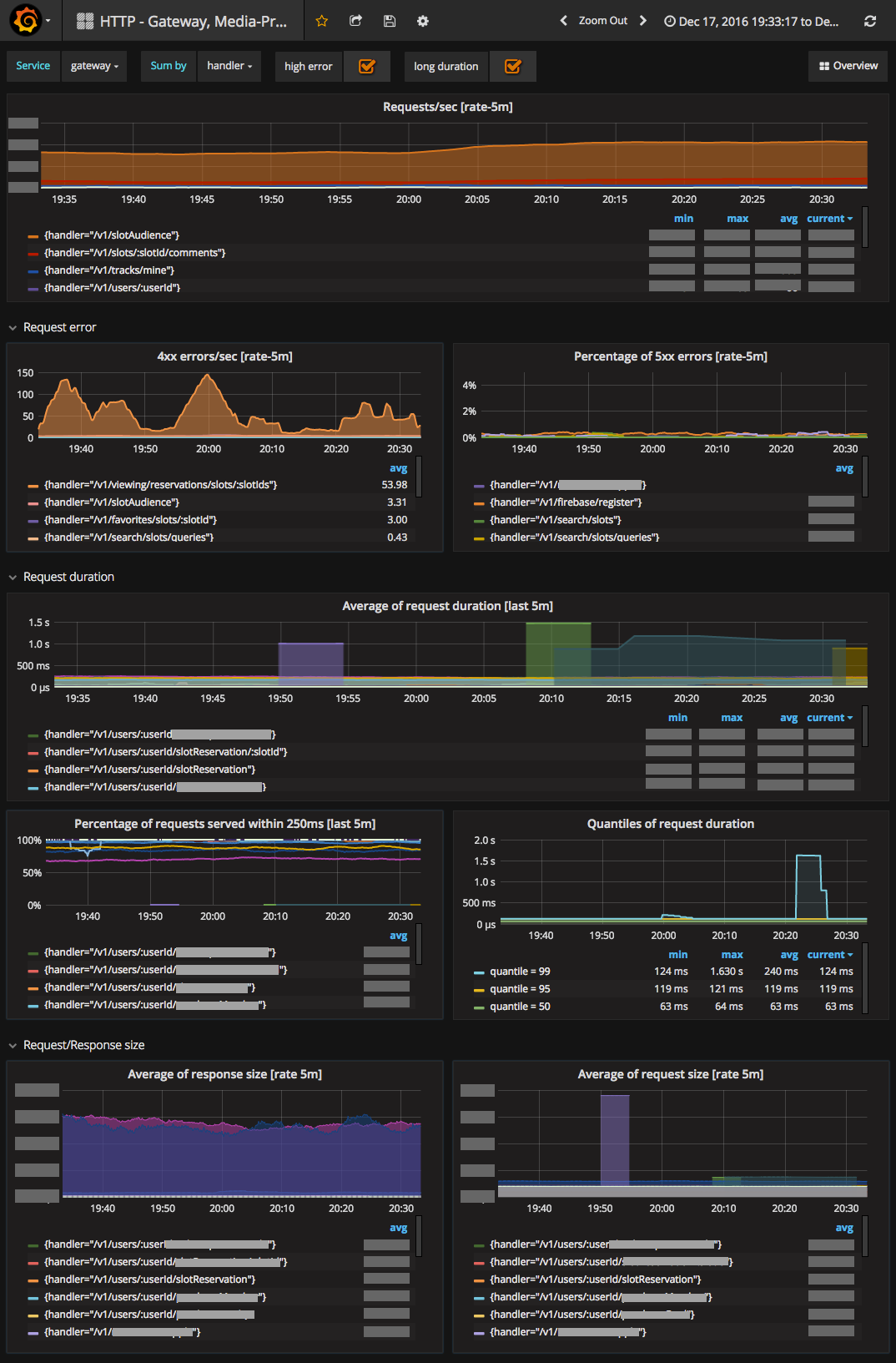
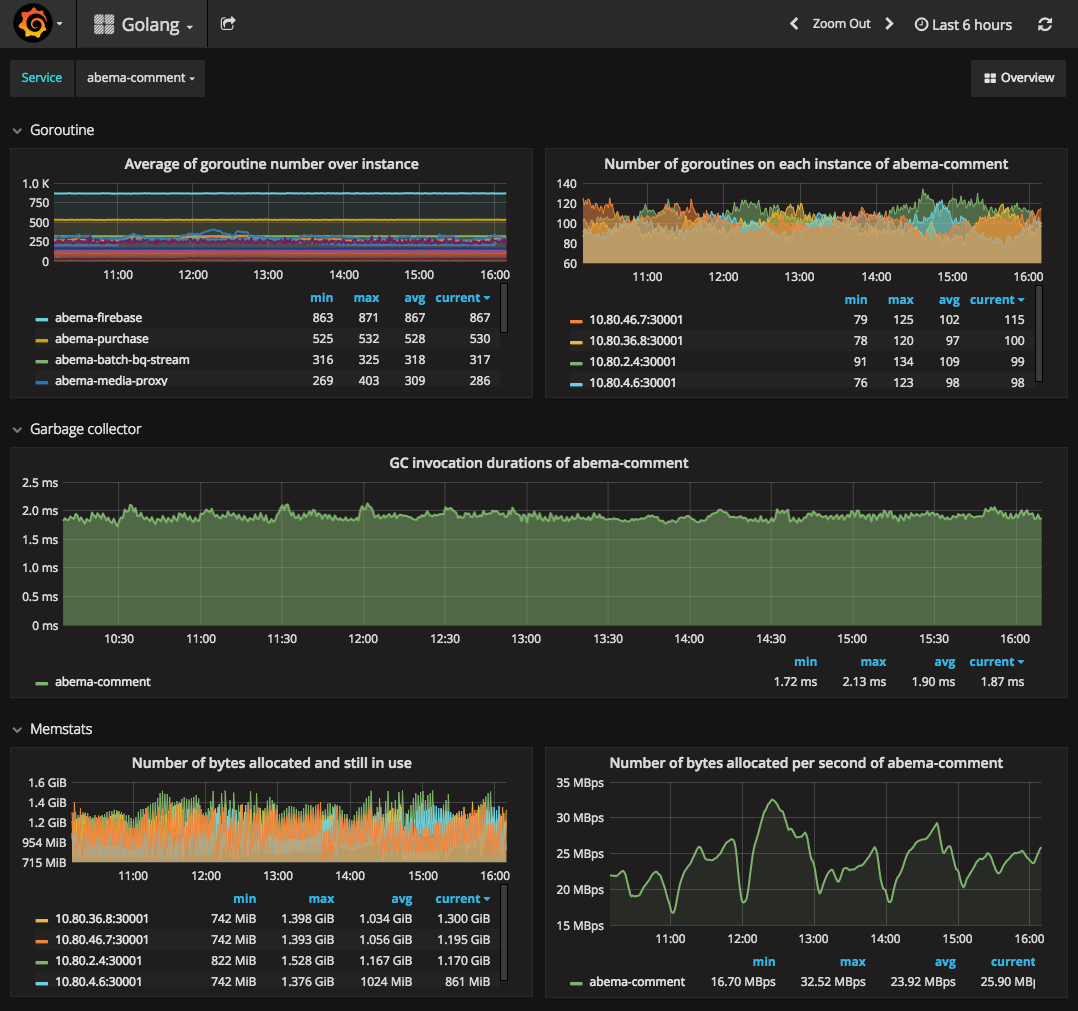

左)HTTPのメトリクスのグラフは上のような感じです。 中央) Golangメトリクスも便利です。 右) Prometheus自身のメトリクスも収集・監視しています。
AlertManager
Prometheusのアラートの機能を使うために、Prometheus側にアラートルール定義が必要です。我々はアラートルールは以下のように、rulesフォルダーに保存し、KubernetesのConfigMapとして扱っています。
$ tree prometheus
prometheus
├── Makefile
├── configs
│ └── config.yml
├── prometheus-rc.yml
├── prometheus-svc.yml
└── rules
├── alert_batch_worker.rules
├── alert_http_internal_error.rules
├── alert_http_request_duration.rules
├── grpc_request_duration_quantile.rules
└── http_request_duration_quantile.rules
rulesフォルダー内の全てのファイルをConfigMapとしてapplyする時に以下のコマンドで行えます。
kubectl create configmap prometheus-rules --from-file=rules -o json --dry-run | kubectl replace -f -
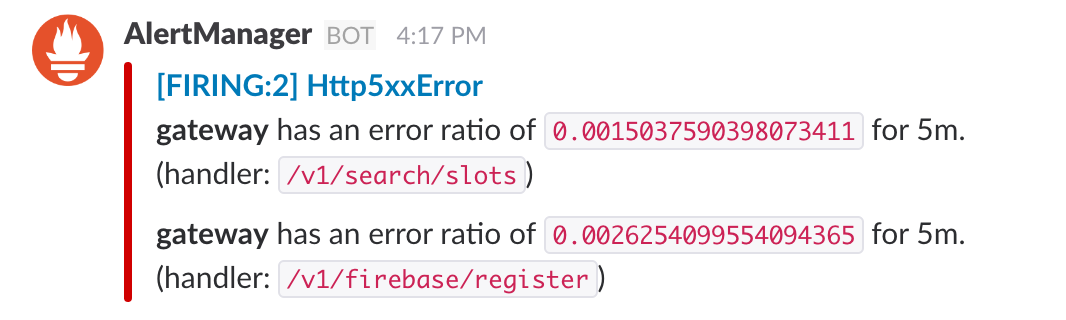
# Alert for any service that has a high ratio of 5xx error.
ALERT Http5xxError
IF (sum(rate(http_requests_total{status=~"^5..$"}[5m])) by (service,handler)) / (sum(rate(http_requests_total[5m])) by (service,handler)) > 0.001
FOR 1m
ANNOTATIONS {
description = "*{{ $labels.service }}* has an error ratio of `{{ $value }}` for 5m.\n(handler: `{{ $labels.handler }}`)",
}
上のアラートルールで以下のような通知がSlackに来ています。
Prometheus内部のアーキテクチャ
エンジニアにとってすごいサービス・ツールを使ってみるのは楽しいですが、内部の設計・すごかった理由の理解ももっと楽しいではないでしょうか。 今回私もPrometheusのコードを読んでみると、勉強になったことが多くて、ドキュメントに述べていないことも理解でき、すごく楽しかったです。
記事が長くなってしまいますので、Prometheusのローカルストレージについてのみ書きます。
Prometheusの資料を初めて見る時に、自分自身に以下の二つ質問がありました。
- 時系列データをどいう感じで保存しているのか
- 16 bytes/sampleから1.3 bytes/sampleまでエンコードできているが、どうやってできるのか
皆さんもそんな質問がありませんでしたか。
PrometheusはLevelDBとロカールのファイルシステムにデータの保存を行っています。時系列データをメタデータとサンプルデータの2つ種類に分割され、前者はLevelDBに保存し、後者はファイルシステムに保存しています。
以下のメトリクスで見てみましょう。
http_requests_total{method="GET", handler="/tracks", status="200"} -> 15
http_requests_total{method="GET", handler="/tracks", status="500"} -> 2
go_goroutines{instance="10.8.6.3:30001", service="comment"} -> 126
上の3つメトリクスは以下の3つレベルセットから識別しています。
{__name__="http_requests_total", method="GET", handler="/tracks", status="200"}
{__name__="http_requests_total", method="GET", handler="/tracks", status="500"}
{__name__="go_goroutines", instance="10.8.6.3:30001", service="comment"}
各メトリクスのラベルセットからFNV-1A-64bitを用いて、唯一のhash値(フィンガープリントと呼ばれています)を作成します。
fingerprint({__name__="http_requests_total", method="GET", handler="/tracks", status="200"}) = 5f1642a34576aa87
fingerprint({__name__="http_requests_total", method="GET", handler="/tracks", status="500"}) = 5f1ada6de8c7cbd8
fingerprint({__name__="go_goroutines", instance="10.8.6.3:30001", service="comment"}) = de86e7778f8ba16c
上のフィンガープリントはメトリクスのサンプルデータの保存場所を決定しています。現在、フィンガープリントの最初の2文字はフォルダー名、残り分はファイル名としてしていますので、
- 1番目のメトリクスのサンプルデータは
5f/1642a34576aa87.dbところに保存 - 2番目のメトリクスのサンプルデータは
5f/1ada6de8c7cbd8.dbところに保存 - 3番目のメトリクスのサンプルデータは
de/86e7778f8ba16c.dbところに保存
ところで、LevelDBに保存するメタデータは
- ラベルのキーとバリュー
- ラベルセットとフィンガープリントのmap
Prometheusは定期的に各収集ターゲットまで現在のメトリクスのデータを取りに行って、(timestampe, metric_value)ペアをサンプルポイントとして適切なファイルに追加します。
// 5f/1642a34576aa87.db
1482303340 125.0000000
1482303350 128.0000000
1482303360 152.0000000
ポイント1)メトリクスデータの特徴は時間順次に来るので、writeオペレーションは基本的にファイルにappendだけなので、速いですね。
Prometheusではサンプルデータを1024bytesの固定サイズのchunkに分けて、保存しています。
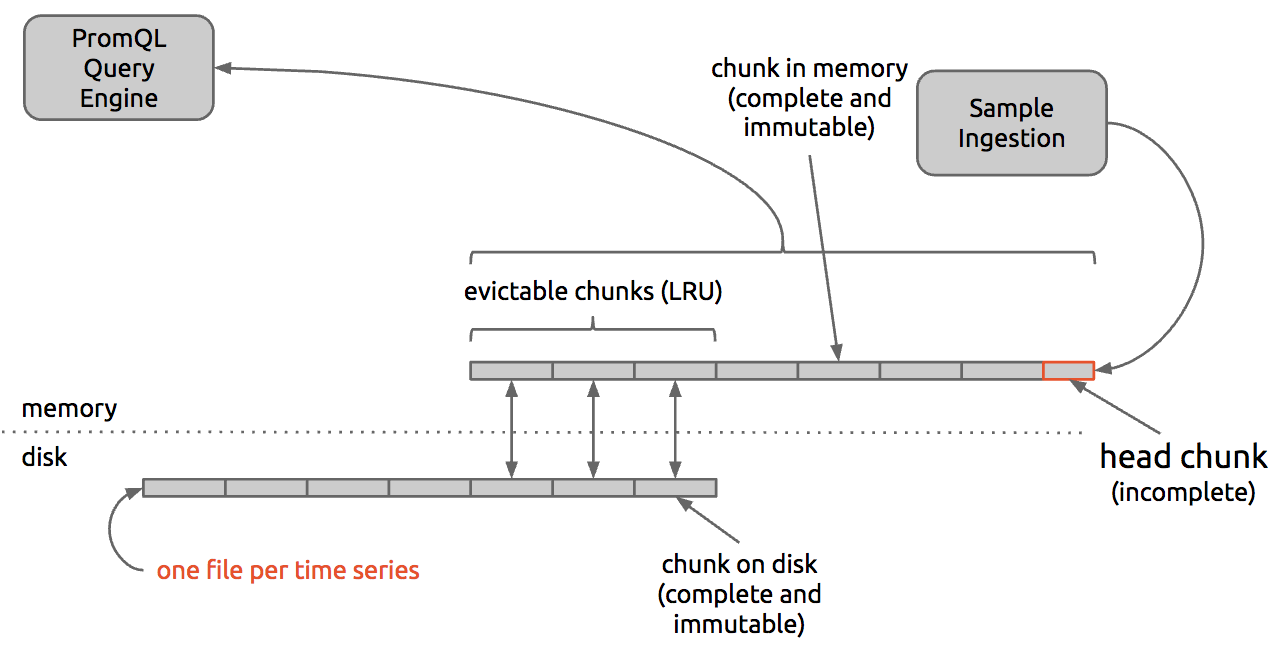
新サンプルーデータが来た時に最新のchunkに入れて、chunkがfullになったら、新しいchunkを作成し、追加します。メモリ内に各メトリクスは何個かのchunkがあり、storage.local.memory-chunks/number_of_timeseries値を超えると、古いchunkをディスクファイルにappendします。
PromQLエンジンはLevelDB内のメタデータを用いて、クエリを解析し、必要な時系列サンプルーデータのchunksをメモリにロードし、演算を行います。
ポイント2)固定サイズのchunkでファイル内のchunkにランダムアクセスできるようになります。
ここまででPrometheusのデータ管理は理解できましたね。
次はデータ圧縮の話です。圧縮が必要なところは基本的にサンプルデータです。Prometheusはメトリクスデータは全て16 bytesで扱っています。つまり、一つのサンプルポイントは32 bytes必要です。(timestamp: 16byte, metric_value: 16byte)。 現在、PrometheusはDelta, DoubleDelta, Varbitという3つのエンコード方法を提供しています。使う時に適切なエンコード方法を指定できます。
- Delta
この方法は一番シンプルな方法なので、圧縮率は一番低いです。timestampとmetric_valueをそのまま保存するではなく、delta値を保存する方法です。
15001000
15001015 dx 15
15001029 dx 29
15001046 dx 46
15001060 dx 60
しかし、Prometheusで利用するdeltaは直前の値との差分(sliding delta)ではなく、chunkの最初値との差分のdeltaです。そこで、indexからすぐ元の値を逆算することができます。メトリクスデータは元の値と比べて、delta値の方が小さいということで、値の表現必要なbit-widthがより小さくなり、データ圧縮できます。0, 1, 2, 4, 8のbit-widthの中にdelta値を表現できる最小bit-witdhを選択しています。ランダムアクセスのために、chunkの中に全てのサンプルは同じbit-widthでエンコードする必要ですが、異なるchunkは異なるbit-widthでエンコードすることが可能です。chunkのbit-widthはchunkヘッダに保存されています。chunkの途中に必要なbit-widthが高くなる場合には高いbit-widthでchunkを最初から再エンコードするか、新chunkにするかを行っています。
ポイント3)chunk毎に異なるbit-widthでエンコードできるので、データが壊れる時にdelta値の変化は急に大きくになっても、そのchunkのみに影響することです。
この方法はservice_upのような、基本的に変更しないメトリクスは0 bit-widthで表現できます。
- DoubleDelta
DoubleDeltaはdelta値をもう一回deltaをするというイメージです。以下の式で計算しています。
ddx(t) = x(t) - (x(0) + t * dx(1))
15001000
15001015 dx 15
15001030 dx 30 ddx 0
15001046 dx 46 ddx 1
15001060 dx 60 ddx 0
delta値と比べて、double-delta値はもっと小さくなるので、表現に必要なbit-widthがより少なくなります。それ以外はDelta方法と同じです。indexから上の式ですぐ元の値を計算できるので、chunk内のランダムアクセスは可能ですね。 Prometheusは定期的に収集ターゲットからメトリクスを取りに行くので、double-delta値がほどんと0になり、必要なbit-widthが0になります。
DoubleDelta方法は平均1サンプルあたり3.3bytes必要で、圧縮率は約5倍です。現在、DoubleDeltaはデフォルトのエンコード方法として設定されています。
- Varbit
上の二つのエンコード方法はchunk毎に別々のbit-widthでエンコードできますが、chunk内の全サンプルは同じbit-widthでエンコード必要です。Varbit方法はchunk内の各サンプルが異なるbit-widthでエンコードできるようになる方法です。名前からでもそういう意味ですね。Varbit = Variable bit-width encoding. この方法はFacebookが公開された 「Gorilla: A Fast, Scalable, In-Memory Time Series Database」という論文から参考されていると書かれています。
メトリクスの時系列データはある時の値が前後値と大きく変更していないという特徴があり、前後値と比べるとIEEE754で表現されるFloatのバイナリはSign, ExponentとMantissaの頭が同じです。説明はちょっとわかりづらいので、15.5, 14.0625, 8.625の64bitバイナリを見てみましょう。
// sign: bit 32 (left-most bit)
// exponent: bits 24-31
// mantissa: bits 1-23
12.5 = 01000000 00101111 00000000 00000000 00000000 00000000 00000000 00000000
14.0625 = 01000000 00101100 00100000 00000000 00000000 00000000 00000000 00000000
8.625 = 01000000 00100001 01000000 00000000 00000000 00000000 00000000 00000000
12.5と14.0625, 14.0625と8.625のXOR結果見てみましょう。
12.5 XOR 14.0625 = 00000000 00000011 00100000 00000000 00000000 00000000 00000000 00000000
14.0625 XOR 8.625 = 00000000 00001101 01100000 00000000 00000000 00000000 00000000 00000000
ということは、直前の値とXORした結果は以下の特徴があります。
- ほとんどのbitが0です
- meaningfull bitsの場所は近いところにいます
meaningfull bitsはXOR結果bitsの中にleading zero bitsとtrailing zero bitsを除いた残り部分です。
meaningfull_bits(12.5 XOR 14.0625) = 11 001
meaningfull_bits(14.0625 XOR 8.625) = 1101 011
上の特徴がありますので、サンプルの値をそのまま保存する代わりに、以下のようなアルゴリズムでエンコードし、保存時に必要なデータ量が少なくなります。
XOR結果は
- 0ならば、’0′ bitを保存
- meanigfull bits ブロックが前回のmeaningfull bits ブロックにフィットすると、以下のフォマートで保存:
’10’ (control bit) と meaningfull bits - meaningfull bits ブロックが前回のmeaningfull bits ブロックにフィットしないと、以下のフォマートで保存:
’11’ (control bit) と leading zerosの長さ(5 bits) と meaningfull bitsの長さ(6 bits) と meaningfull bits
デコードする時には、chunkの頭から順次に行う必要です。Control bitsで保存しているフォマートがわかり、leading zerosの長さとmeaningfull bitsからXOR結果を計算できます。そして、XORの逆算はXORですので、前の値とXOR結果からXOR演算で現在値を計算できます。
この方法は平均1サンプルあたり1.3bytes必要で、圧縮率は約12.3倍です。圧縮率は一番高いですが、chunk内のランダムアクセスはできないので、他の方式と比べて、エンコードとデコードコストがちょっと高くなります。
考察
AbemaTVにPrometheusを導入し、運用してみて多くのメリットを感じ、また楽しかったです。
特にKubernetesとの連携はすごいので、クラスタ内のサービスからメトリクスの取集するための設定はシンプルです。すべてのレベルのメトリクスの取集はPrometheusのみでも可能になっています。
PromQLも使いやすいです。現在他のメンバーは自分でメトリクス追加・ダッシュボード作成までやっています。 システム障害発生時にダッシュボードが事前に用意されていないデータを見たかったら、チームメンバーはすぐにクエリを書くことができます。 また、Prometheusが利用するディスク量も少なかったです。
上記のような色々なメリットがありましたが、もちろんこれから期待している事も存在しています。特にPrometheusが使用するメモリ周りです。 まずは、現在Prometheusではメモリ内のchunk数を制限するための設定ができますが、オーバーヘッドやPromQLエンジンで使うメモリもあるので、必要なメモリ量の正確な数字がわかりません。現段階では大体chunk数 x chunkサイズの3倍ぐらい書かれていますが、そうではない場合もありました。実際はメモリ制限のissueもありました。

次の期待はGolangのGCにもうちょっと優しくなることだと考えています。 上のグラフを見てみると、OSから貰うメモリサイズは実際に利用しているサイズの3倍ぐらいでした。Heap idleの量はかなり大きいです。そこで、将来のバージョンはメモリをもうちょっと節約して欲しいです。
まとめ
本記事はPrometheusの特徴、AbemaTVにPrometheusを導入した理由、AbemaTVでのPrometheus, Prometheus内部のストレージなどについて説明しました。
記事が長くなってしまいまして、申し訳ないですが、読んで頂きありがとうございました。 もし何かご意見がありましたら、是非コメントを頂ければ嬉しいです。
明日はshigemk2さんの記事で最後なんですが、是非読んでください。