
AI事業本部の広告配信プロダクトDynalystでMLエンジニアをしている長江(@nsakki55)です。
今回はMLワークフローツールをPrefectへ移行した話と、AWS上でPrefectのMLワークフロー環境を構築する方法を紹介しようと思います。
国内ではまだ導入事例が少なく、日本語によるドキュメントも少ないので、Prefectを検討してる方の助けになれば幸いです。
本文中ソースコード:https://github.com/nsakki55/prefect-ml-workflow
ProfectによるMLワークフロー管理
Prefectとは
![]() PrefectはAirFlowやArgoWorkflowのようなワークフロー管理ツールで、2018年にリリースされました。
PrefectはAirFlowやArgoWorkflowのようなワークフロー管理ツールで、2018年にリリースされました。
CEOのJeremiah Lowin氏が元Airflowの開発者ということもあり、Airflowのイケていない部分を解決する思想の元作られています。
公式ドキュメントでも、Why Not Airflow?という強気な内容でAirflowと対比してPrefectの特徴を取り上げています。
Airflowと同様、PrefectでもPythonを用いてワークフローを記述します。
AirflowとPrefectを比較すると以下のようになります。
| Airflow | Prefect | |
| API | Airflow独特の文法 | Pythonらしい文法 |
| 実行スケジュール | 実行時刻とDAGが密結合 | 実行時刻とDAGが疎結合 |
| スケジューラー | Airflow schedulerによる中央管理 | ワークフローごとに分散管理 |
| データフロー | タスク間のデータ受け渡しが困難 | タスク間のデータの受け渡しが容易 |
| ワークフローパラメータ | DAG定義は不変を想定 | DAG実行時に任意のパラメータを渡せる |
| 動的なワークフロー構築 | 実装時にDAGが固定 | 実行時にDAGを動的に作成 |
| バージョン管理 | DAGは暗黙的に更新 | DAGはバージョン番号を持つ |
| ローカルテスト | 実行してDAGの状態が決まる | 任意にDAGの状態を設定できる |
| UI | データベースのようなUI | ユーザーフレンドリーなUI |
Airflow(画像左)とPrefect(画像右)のUI比較。
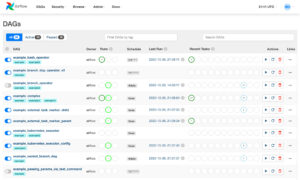
導入背景
DynalystではMLワークフローツールにDigdagを使用していたところ、以下の点から運用に限界を感じてきました。 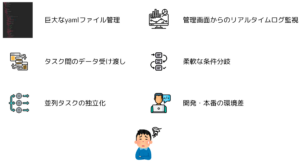 特にyamlファイルの管理と、タスク間データの受け渡しが困難で、ワークフローツールのためにアプリケーション側の実装を変更することになり、開発の妨げとなってきました。
特にyamlファイルの管理と、タスク間データの受け渡しが困難で、ワークフローツールのためにアプリケーション側の実装を変更することになり、開発の妨げとなってきました。
上記の問題から、Digdagの代替となるワークフローツールの調査を、以下5つの選定基準を軸に行いました。
- 既存システムとの相性
- リアルタイムログ監視
- 開発しやすさ
- ワークフローの柔軟性
- コスト
もともとAirflowの導入を検討していましたが、コスト面や開発のしやすさを重視してPrefectを導入することを決めました。
| 既存システムとの相性 | リアルタイムログ監視 | 開発しやすさ | ワークフローの柔軟性 | コスト | |
| Prefect | ⭕️ | ⭕️ | ⭕️ | ⭕️ | ⭕️ |
| Airflow (AWS) ※ | ⭕️ | ⭕️ | 🔺 Operatorの記述が独特 | 🔺 Operator間のデータ渡しが困難 | 🔺 500~$/month |
| SageMaker Pipeline | ❌ SageMakerを利用してない | 🔺 Cloud Watchで見る必要あり | 🔺 独特の記法で学習コストがある | 🔺 動的にタスクを作成するのが難しい | ⭕️ |
| StepFunctions | ⭕️ | 🔺 Cloud Watchで見る必要あり | 🔺 YAML管理が必要 | 🔺 YAMLでの記述が困難 | ⭕️ |
| Kubeflow・Argo | ❌ kubernetesの運用が必要 | – | – | – | – |
※ DynalystではAWSを全面的に採用しているため、AirflowもManaged版を調査しています。
導入後の状態
Prefect導入後は、以下の構成となりました。 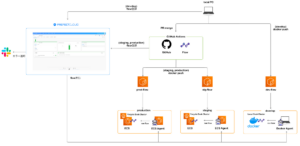 ポイントは以下の点です。
ポイントは以下の点です。
- ワークフローをDocker Image化することで、開発・本番環境の差を軽減
- staging・productionはECS Taskとしてワークフローを実行、開発ではローカルPC上でコンテナ実行
- ML基盤のGitHubレポジトリへのマージで、最新ワークフローが管理画面であるPrefect Cloudへデプロイ
従来のyamlベースのdigdagから、DSに馴染み深いPythonベースのPrefectに移行したことで、コード量が減り開発負荷が軽減しました。
Prefect 入門 ~ 基礎 ~
注意: 本記事ではPrefect 1系を扱います。Prefect 2系が2022年7月にリリースされています。
Prefectのワークフロー構成要素
 Prefectでワークフローを組むには, FlowとTaskが基本的な骨組みになります。
Prefectでワークフローを組むには, FlowとTaskが基本的な骨組みになります。
- Task: ワークフローを構成する処理の単位(ex. ETLのE, T, Lの部分)
- Flow: Taskの組み合わせたワークフロー全体(ex. ETL全体)
TaskとFlowに対して、オプション機能を追加していく流れになります。
Task
ワークフローの構成単位をTaskと呼びます。AirflowのOperatorに対応します。[1]
Taskの作成は2つの方法があります。
Python関数に@taskデコレーターを付与する方法
from prefect import task
@task
def multiple(x: int, y: int) -> int:
return x * y
Taskクラスを継承し、run関数を記述する方法
from prefect import Task
class MultipleTask(Task):
def run(self, x: int, y: int) -> None:
return x * y
外部サービス用のTaskが公式から提供されているため、0から自分で実装せずに利用することができます。[2]

Flow
Task間の依存関係を記述したワークフロー全体をFlowと呼びます。AirflowのJobに対応します。[3]
FlowはDAGであり、Task間に実行順序を与えます。
Flowの作成は2つの方法があります。
Functional API
Flowコンテクストマネージャー内で、Taskを呼び出すことでprefectのFlowを構築できます。
通常のPythonコードのように、Taskの出力を別のタスクの入力として渡すことができます。
import random
from prefect import Flow, Task, task
@task
def get_random_number() -> int:
return random.randint(0, 100)
@task
def multiple(x: int, y: int) -> int:
return x * y
with Flow("Functional API Flow") as flow:
x = get_random_number()
y = get_random_number()
z = multiple(x=x, y=y)
Imperative API
Airflowのように命令型の形式でFlowを書くことができます。
Functional APIと比較した場合のメリットは、Task間でデータの受け渡しができないため、データ依存関係ではなく、状態依存関係でタスク同士の厳密な順序を作成できることです。
from prefect import Task, Flow
@task
def first_task() -> None:
print("first task is running")
@task
def second_task(x: int, y: int) -> int:
return x * y
flow = Flow('Imperative API Flow')
flow.set_dependencies(
task=first_task,
upstream_tasks=[first_task],
keyword_tasks=dict(x=1, y=2))
オプション機能
PrefectにはTask・Flowに対してオプション機能をカスタマイズできます。
たくさんあるため、主要な機能のみを紹介します。
パラメータ
Prefectでは、事前に設定したパラメータをFlow実行時に渡すことができます。[4]
ParameterクラスはTaskクラスを継承してるため、FlowのTaskの1つとして認識されます。
変数名・デフォルト値を設定することができます。
from prefect import task, Flow, Parameter
@task
def multiple(x: int, y: int) -> int:
return x * y
with Flow('Parameter Flow') as flow:
x = Parameter('x')
y = Parameter('y', default = 3)
z = multiple(x=x, y=y)
マッピング
動的に複数Taskを実行するためのMapReduceモデルと公式では紹介されています。入力が異なる同一Taskを並列で実行したい場合に使用します。[5]
この機能を使用すれば、複数モデルの学習の並列化・ハイパラチューニング並列化が実現できます。
from prefect import Flow, task
numbers = [1, 2, 3]
@task
def map_task(x) -> int:
return x + 1
@task
def reduce_task(x_list: List[int]) -> int:
return sum(x_list)
with Flow('Map Flow') as flow:
mapped_data = map_task.map(numbers)
reduced_data = reduce_task(mapped_data)
上記のコードは以下のようなワークフローを表しています。
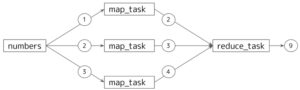
スケジュール
Flowを定期的に実行したい場合、実行スケジュールをFlowに設定できます。[6]
Flowクラスにscheduleを渡すことでスケジュール設定を行えます。
Cronによる設定や、複数のスケジュール設定を組み合わせることも可能です。
from prefect import task, Flow
from datetime import timedelta
from prefect.schedules import IntervalSchedule
schedule = IntervalSchedule(interval=timedelta(minutes=2))
@task
def say_hello()-> None:
print("Hello, world!")
with Flow("Schedule Flow", schedule=schedule) as flow:
say_hello()
リトライ
Taskが失敗した際に、自動で再実行させることができます. リトライ回数や、失敗してから何秒後に実行するかを設定できます。[7]
@taskデコレータにリトライ設定を渡します。
@task(max_retries=3, retry_delay=datetime.timedelta(minutes=10))
def plus_task(x: int) -> int:
return x + 1
トリガー
他のTaskの状態に応じて実行するかどうか判定を行えます。特定のタスクが成功したときに実行したいタスクがある場合に便利です。[8]
@taskデコレータにトリガーとなる条件を渡します。
from prefect.triggers import any_successful
@task
def first_task(x: int) -> int:
return x + 1
@task(trigger=any_successful)
def second_task(x: int) -> int:
return x + 2
条件分岐
前のTaskの出力値に応じて、次に実行するTaskを分岐させることができます。[9]
case文で判定を行い、mergeで分岐後の結果をまとめることができます。
from prefect import task, Flow, case
from prefect.tasks.control_flow import merge
with Flow("Condition Flow") as flow:
condition = condition_task()
with case(condition, True):
val1 = true_task()
with case(condition, False):
val2 = false_task()
val = merge(val1, val2)
another_task(val)
上記のコードは以下のようなワークフローを表しています。
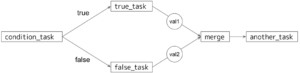
Slack通知
Flowの状態に応じてSlack通知する機能が提供されています。[10]
Taskごとに設定でき、メッセージ内容や通知条件を細かく設定できます。
from prefect import Flow, task
from prefect.utilities.notifications import slack_notifier
@task(name="1/x task", state_handlers=[slack_notifier])
def div(x):
return 1 / x
with Flow('Slack Notification Flow') as f:
res = div(x=add(0))
以下のようなSlack通知が送られます。エラーメッセージが出て、エラー部分のリンクに飛べるようになっています。
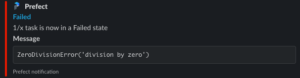
Prefectを本番運用するための要素
Prefect Cloud
Prefectを本番運用する際は、Prefect Cloudと呼ばれるWeb UI 管理画面の利用が推奨されています。
Prefect Cloudはハイブリッドモデルと呼ばれる、ワークフローの管理はPrefectが行い、コードの実行管理はユーザーが行う構成をとっています。[11]
例えばAWSのAirflowマネージドサービスは、DAGの実行インフラ環境を提供しますが、Prefect Cloudはワークフローの管理のみを行い、実行インフラ環境は提供しません。
一見不便に思えるかもしれませんが、自社コードを第三者に渡すことなく、柔軟に計算リソースを選択をできるため、自分はむしろ使いやすいと感じました。
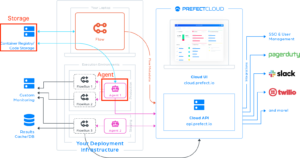
上図はPrefect Cloudの構成を表した図です。[12]
構成要素が多く見えますが、重要なのは2つの要素です。
- Storage : FlowをPrefect Cloudへ登録する時のユーザーのコード管理場所
- Agent : ユーザーが管理する計算リソース上でFlowの実行と監視を行う
Prefect Cloudでワークフローを本番運用する際は、StorageとAgentの設定が必要となります。
Storage
Flowのコードを保管する場所をStorageと呼びます。
Flowの保管場所としてLocal, S3, GCS, GitHub, Dockerなどがサポートされています。[13]

Flowクラスにstorageを渡すことでStorageの設定を行うことができます。
例えば以下のFlowをPrefect Cloudに登録すると、自動的にFlowのコードがS3に保存されます。
from prefect import Flow
from prefect.storage import S3
s3_storage = S3(bucket="")
with Flow("Storage S3 Flow", storage=s3_storage) as flow:
...
Agent
Flowの実行・監視を担う機能をAgentと呼びます。[14]
Prefect Cloudを利用する時に、恐らく最も難しいのがAgentの設定です。
上述の通り、AgentはFlowをユーザーの計算リソース上で実行・監視するための機能を担います。
Flowの実行環境としてGCP, AWS, Azure上での実行環境が提供されていて、AgentとしてLocal, Docker, Kubernetes, ECS, Vertexなどがサポートされています。

例えば、FlowをECSTaskとして実行するためのECS Agentを起動するためには、以下のようにprefectのコマンドを実行します。[15]
ECS AgentをユーザーのAWS環境で本番稼働するにはECS Serviceとして以下のコマンドを実行する必要がありますが、詳細は後半の発展パートで解説します。
$ prefect agent ecs start
Flow側でどのAgentを利用するかを設定する必要があります。
Flowクラスにrun_configを渡すことで、実行環境の設定を行えます。
AgentとRunConfigはペアとなるため、ECS Agentを使用する場合はECSRunを呼び出す必要があります。
from prefect import Flow
from prefect.run_configs import ECSRun
ecs_run_config = ECSRun(cpu="2 vcpu", memory="4 GB")
with Flow("ECS Run Flow", run_config=ecs_run_config) as flow:
...
Prefect 入門 ~ 発展 ~
今回はMLの学習ワークフローでよくある、データ取得→前処理→学習→評価→モデル保存を行うワークフローをPrefectで組んでみます。
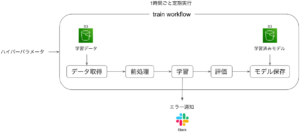
データ・前処理・モデルは以下を用います。
- データ: avazu-ctr-prediction データセット
- 前処理: Feature Hashing
- モデル: SGDClassifier
任意のハイパーパラメータを実行時に渡すようにし、1時間ごとに定期実行するスケジュール機能をつけます。また、モデル学習の失敗時にエラー通知をSlackへ送るようにします。
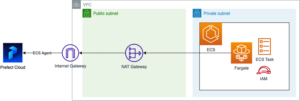
AWS上でPrefectを本番運用することを想定し、以下のようにワークフローをimage化し、ローカル環境・ECS環境で実行できるような構成を作成します。
Prefect Cloudの登録
Web UIでワークフローを管理するために、Prefect Cloudのアカウントを作成します。
自身でPrefect Serverとしてホストできますが、本番運用する場合はPrefect Cloudを利用することが推奨されています。
https://universal.prefect.io/ でサインアップを行います。
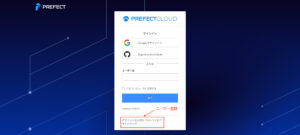
Prefect Cloudの認証キーの作成
Prefect Cloudの管理画面にログインした後、Team→Service Accounts→CREATE API KEYで、Prefect Cloudの認証キーを作成できます。
一度発行した認証キーを再びPrefect Cloud管理画面から確認することはできないので、Secret Managerなどで管理するようにしましょう。
管理画面から作成した認証キーを利用して、ターミナルからPrefect Cloudにログインします。
$ prefect auth login -k pcs_XXXXXXXXXXXX
Logged in to Prefect Cloud tenant "XXXXXXXX's Account" (XXXXXXX-s-account)
Project作成
Projectと呼ばれるグループにFlowを紐づけてPrefect Cloudに登録します。
develop, staging, productionごとのProjectを作成し、Projectごとに使用するリソースを分けるようにすることで、実行環境を分けることが可能です。
Dashboardページの右上 New Project で新しいプロジェクトを作成できます。
今回はdevelop, productionの2つのProjectを作成します。
Agent登録
Flowを実行する環境を提供するために、Prefect CloudにAgentを登録する必要があります。
develop環境用にDocker Agent, production 環境用にECS Agentの設定を行います。
FlowがどのAgentを使用するかは、Agentに割り当てた label で制御します。
Agent を起動するには prefect agent Agent名 start コマンドを実行します。[16]
Agentに対して識別子であるlabelを与えることができ、今回はdevelop・productionというlabel名をDocker Agent, ECS Agentにそれぞれ設定します。
以下はDocker Agentを起動させる例です。
$ prefect agent docker start --label develop
[2022-10-12 10:24:09,492] INFO - agent | Registering agent...
[2022-10-12 10:24:09,736] INFO - agent | Registration successful!
____ __ _ _ _
| _ \ _ __ ___ / _| ___ ___| |_ / \ __ _ ___ _ __ | |_
| |_) | '__/ _ \ |_ / _ \/ __| __| / _ \ / _` |/ _ \ '_ \| __|
| __/| | | __/ _| __/ (__| |_ / ___ \ (_| | __/ | | | |_
|_| |_| \___|_| \___|\___|\__| /_/ \_\__, |\___|_| |_|\__|
|___/
[2022-10-12 10:24:09,951] INFO - agent | Starting DockerAgent with labels ['develop']
[2022-10-12 10:24:09,951] INFO - agent | Agent documentation can be found at https://docs.prefect.io/orchestration/
[2022-10-12 10:24:09,951] INFO - agent | Waiting for flow runs...
ECS Agentを本番運用する場合、公式ドキュメントではECS Serviceとしてホストすることが推奨されています。[17]
下図のような、ECS AgentをPrefect Cloudに登録するAWS環境を作成するTerraformを用意したので、興味ある方はご確認ください。
実行コマンドはREAMEに記載しています。
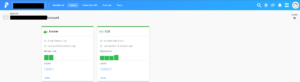
Prefect CloudからAgentが登録されていることを確認できます。
各Agentに対してlabelが設定されていることがわかります。
Flow作成
最終的に以下のようなファイル構成を作成しました。
/src
├── ml_workflow.py.........# Flowファイル
├── Dockerfile.............# Docker Storage用のDockerfile
├── requirements.txt.......# Flow実行に必要な依存関係
├── config.toml............# ユーザー変数・設定ファイル
│
└──/flow_components
├── task.py..........# Taskファイル
├── executor.py......# Task実行環境の設定
├── storage.py.......# Flowコードの管理
├── run_config.py....# Flow実行環境の設定
├── schedule.py......# 定期実行スケジュール管理
├── handler.py.......# 状態変化時の実行関数設定
├── model_entity.py..# MLワークフロー構築用の自作クラス
├── environment.py...# 実行環境の値オブジェクト
└── __init__.py
Configファイル設定
Prefectではユーザー独自の変数や設定を config.toml ファイルで管理できます。[18]
develop, production環境ごとに変数値を使い分けたいは場合、 config.toml で環境ごとの値を管理しておくのが便利です。
configファイルに設定した値は、Flow中で prefect.config.{変数名} のように読み込むことができます。
system_env = "$SYSTEM_ENV"
# Project
labels = "${project.${system_env}.labels}"
[project]
[project.develop]
labels = ["develop"]
[project.production]
labels = ["production"]
[context.secrets]
SLACK_WEBHOOK_URL = "https://hooks.slack.com/services/*****"
デフォルトでは $HOME/.prefect/config.toml が読み込まれるため、自身で設定したconfigを使用するには PREFECT__USER_CONFIG_PATH 環境変数にconfigファイルのパスを設定する必要があります。
$ export PREFECT__USER_CONFIG_PATH="$PWD/config.toml"
Storage設定
Flowをimageとして管理するため、DockerStorageを使用します。
自作関数をFlow中で使用する場合は、Dockerfileを用意しておくとスッキリかけます。[19]
import prefect
from prefect.storage import Docker, Storage
from .environment import Environment
def docker_storage(image_tag: str) -> Storage:
"""Flowをdocker imageとして管理するための設定"""
return Docker(
image_name=prefect.config.image_name,
image_tag=image_tag,
registry_url=prefect.config.ecr_repository,
dockerfile=prefect.config.dockerfile,
env_vars={"SYSTEM_ENV": prefect.config.system_env},
)
def set_storage(image_tag: str = "latest") -> Storage:
if Environment.from_str(prefect.config.system_env) in [Environment.DEVELOP, Environment.PRODUCTION]:
return docker_storage(image_tag=image_tag)
Flowを実行するための依存関係を含めたDockerfileを用意しました。
自作関数などをimportする場合は、 PYTHONPATH 環境変数に対象のフォルダのパスを通す必要があるので注意してください。
FROM python:3.8.6-slim
WORKDIR /opt/prefect
COPY config.toml /opt/prefect/config.toml
COPY flow_components /opt/prefect/flow_components/
COPY requirements.txt /opt/prefect/
RUN pip install --upgrade pip \
&& pip install -r /opt/prefect/requirements.txt
ENV PYTHONPATH="${PYTHONPATH}:/opt/prefect/flow_components/:"
RunConfig設定
FlowをどのAgentを使用して実行するかをRunConfigを用いて設定します。
今回は、developではDockerAgent,、productionではECS Agentを使用するように設定します。
ECS Agent用のRunConfig設定の詳細はこちらを参考にしてください。
import prefect
from prefect.run_configs import DockerRun, ECSRun
from prefect.run_configs.base import RunConfig
from .environment import Environment
def set_run_config(flow_name: str, cpu: int = 1024, memory: int = 2048) -> RunConfig:
if Environment.from_str(prefect.config.system_env) is Environment.PRODUCTION:
return ECSRun(image=prefect.config.image_name)
if Environment.from_str(prefect.config.system_env) is Environment.DEVELOP:
return DockerRun(image=prefect.config.image_name)
Schedule設定
1時間ごとに定期実行するスケジュールを設定します。
Cron表記で1時間ごとの実行を設定します。
import pendulum
import prefect
from prefect.schedules import Schedule
from prefect.schedules.clocks import CronClock
from .environment import Environment
def set_schedule(cron: str = "0 01-23/1 * * *") -> Schedule:
if Environment.from_str(prefect.config.system_env) is Environment.PRODUCTION:
return Schedule(clocks=[CronClock(cron, start_date=pendulum.now("Asia/Tokyo"))])
if Environment.from_str(prefect.config.system_env) is Environment.DEVELOP:
return None
Executor設定
Taskの実行を担う機能をExecutorと呼びます。並列でTaskを実行したい場合はExecutorの設定を行うことでリソースを拡張できます。[20]
PrefectではDaskを使用して並列化を実現しています。詳しいDaskの設定はこちらを参考にしてください。
import prefect
from dask_cloudprovider.aws import FargateCluster
from prefect.executors import DaskExecutor, Executor, LocalDaskExecutor
from .environment import Environment
def set_executor(n_workers: int = 2) -> Executor:
if Environment.from_str(prefect.config.system_env) is Environment.PRODUCTION:
return DaskExecutor(cluster_kwargs={"n_workers": n_workers})
if Environment.from_str(prefect.config.system_env) is Environment.DEVELOP:
return LocalDaskExecutor(n_workers=n_workers)Handler設定
ハンドラーと呼ばれる、オブジェクトの状態変化に応じて呼び出される関数をFlowとTaskに設定することができます。[21]
ハンドラーは自分で構築することが可能なため、Slack通知の内容をカスタマイズしたり、実行Flowの命名規則をカスタマイズすることができます。
今回は実行Flowの命名規則とSlack通知用のハンドラを用意します。
import prefect
from prefect import Flow
from prefect.engine.state import Failed, State
from prefect.utilities.notifications import slack_notifier
from pytz import timezone
from .environment import Environment
def run_name_handler(flow: Flow, old_state: State, new_state: State) -> None:
"""実行Flowの命名規則のハンドラ"""
if new_state.is_running():
client = prefect.Client()
name = (
f"{flow.name}-"
f"{prefect.context.scheduled_start_time.astimezone(timezone('Asia/Tokyo')).strftime('%Y-%m-%d-%H-%M-%S')}"
)
client.set_flow_run_name(prefect.context.flow_run_id, name)
def notification_handler(state: State = Failed) -> State:
"""Slack通知用のハンドラ"""
if Environment.from_str(prefect.config.system_env) is Environment.PRODUCTION:
return slack_notifier(only_states=[Failed])
if Environment.from_str(prefect.config.system_env) is Environment.DEVELOP:
return None
Task設定
Flowの要素となるタスクを実装します。
S3に保存してある生データをダウンロードし、特徴量の前処理にFeatureHasingを行い、モデルにSGDClassifierを用い学習を行います。
通常のPythonの関数を実装した後、@taskデコレータをつけてTaskとする実装の流れになります。
import io
import pickle
from typing import Any
import boto3
import numpy as np
import pandas as pd
import prefect
from prefect import task
from prefect.tasks.aws import S3Download
from sklearn.feature_extraction import FeatureHasher
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import log_loss
from .model_entity import Dataset, feature_info
s3_download_task = S3Download(bucket=prefect.config.s3_bucket)
@task(name="upload to s3 task", log_stdout=True)
def upload_s3_task(s3_bucket: str, s3_key: str, file_path: str) -> None:
"""S3にローカルファイルをアップロード."""
s3 = boto3.resource("s3")
bucket = s3.Bucket(s3_bucket)
bucket.upload_file(Key=s3_key, Filename=file_path)
@task(name="convert string to dataframe task", log_stdout=True)
def convert_string_to_dataframe_task(data: str) -> pd.DataFrame:
"""文字列データをDataFrameとして読み込み."""
df = pd.read_csv(io.StringIO(data))
return df
@task(name="preprocess task", log_stdout=True)
def preprocess_task(data: pd.DataFrame) -> Dataset:
"""生データをFeatureHasherにかけ,学習用データを作成"""
feature_hasher = FeatureHasher(n_features=2 ** 24, input_type="string")
hashed_feature = feature_hasher.fit_transform(
np.asanyarray(data[[feature_name for feature_name in feature_info.names]].astype(str))
)
return Dataset(X=hashed_feature, y=data[feature_info.target])
@task(name="save pickle task", log_stdout=True)
def save_as_pickle_task(data: Any, path: str) -> None:
"""オブジェクトをpickleとして保存"""
with open(path, "wb") as f:
pickle.dump(data, f)
@task(name="train model task", log_stdout=True)
def train_task(dataset: Dataset, **kwargs: Any) -> SGDClassifier:
"""SGDClassifierの学習を実行"""
model = SGDClassifier(loss="log", **kwargs)
model.partial_fit(dataset.X, dataset.y, classes=[0, 1])
return model
@task(name="validate model task", log_stdout=True)
def validate_task(model: SGDClassifier, dataset: Dataset) -> None:
"""テストデータでモデル評価"""
y_pred = model.predict_proba(dataset.X)
print(f"Finished validate model.logloss: {log_loss(dataset.y, y_pred)}")
本筋からずれますが、学習ワークフローを記述するためにデータオブジェクトを用意しています。
Flow設定
MLの学習ワークフローをPrefectで実装します。
ポイントは以下となります。
- FlowクラスにStorage, RunConfig, Schedule, Executorを設定
- Parameterタスクを使用してハイパーパラメータを実行時に渡す
- 学習・テストデータのダウンロード・前処理を、マッピングを使用して並列実行
- タスクの出力である生データ・前処理データを、次のタスクの入力として渡す
import prefect
from flow_components import set_run_config, set_schedule, set_storage
from flow_components.model_entity import DataType, model_info
from flow_components.task import (
convert_string_to_dataframe_task,
preprocess_task,
s3_download_task,
save_as_pickle_task,
train_task,
upload_s3_task,
validate_task,
)
from prefect import Flow, Parameter
FLOW_NAME = "ml-workflow"
with Flow(
name=FLOW_NAME,
storage=set_storage(image_tag="latest"),
run_config=set_run_config(flow_name=FLOW_NAME, cpu=1024, memory=2048),
schedule=set_schedule(cron="0 01-23/1 * * *"),
executor=set_executor(n_workers=2),
) as flow:
# ハイパーパラメータ設定
fit_intercept = Parameter("fit_intercept", default=True)
penalty = Parameter("penalty", default="l2")
random_state = Parameter("random_state", default=42)
# データ読み込み
raw_str_data = s3_download_task.map([datatype.value.raw_data_s3_key for datatype in DataType])
raw_data = convert_string_to_dataframe_task.map(raw_str_data)
# 前処理
preprocessed_data = preprocess_task.map(data=raw_data)
# 学習
model = train_task(
dataset=preprocessed_data[DataType.TRAIN.value.index],
fit_intercept=fit_intercept,
penalty=penalty,
random_state=random_state,
)
# 評価
validate_task(model=model, dataset=preprocessed_data[DataType.TEST.value.index], upstream_tasks=[model])
# モデル保存
save_model = save_as_pickle_task(data=model, path=model_info.path, upstream_tasks=[model])
upload_s3_task(
s3_bucket=prefect.config.s3_bucket, s3_key=model_info.s3_key, file_path=model_info.path, upstream_tasks=[save_model]
)
ローカルデバッグ
PrefectのFlowを開発する手順は、通常のPythonスクリプトを開発する場合のように、トライアンドエラーでFlowを実行しながら実装を追加していく流れになります。
ローカル実行時はStorage・Agent設定は反映さえれず、ローカル環境でコードが実行されます。[22]
Flowの実行は prefect run コマンドで行えます。
標準出力される文字がPrefectのログとして出力されます。
$ prefect run -p ml_workflow.py
Retrieving local flow... Done
Running flow locally...
└── 23:40:25 | INFO | Beginning Flow run for 'ml-workflow'
└── 23:40:25 | INFO | Task 'fit_intercept': Starting task run...
└── 23:40:25 | INFO | Task 'fit_intercept': Finished task run for task with final state: 'Success'
└── 23:40:25 | INFO | Task 'penalty': Starting task run...Flow登録
Prefect CloudにFlowを登録します。
事前準備として、Docker StorageでECRへimageを保存するため、ECR へloginを行います。
$ aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin *****.dkr.ecr.ap-northeast-1.amazonaws.comFlowの登録は prefect register コマンドで行えます。[23]
SYSTEM_ENV環境変数をdevelopに設定して、develop用のprojectに登録を行います。productionも同様です。
Docker Storageを使用するため、登録時に自動的にECRへimageがpushされます。
$ prefect register --project develop -p ml_workflow.py
Collecting flows...
Processing 'ml_workflow.py':
Building `Docker` storage...
[2022-10-14 11:10:30+0900] INFO - prefect.Docker | Building the flow's Docker storage...
Step 1/15 : FROM python:3.8.6-slim
....
Successfully tagged *****.dkr.ecr.ap-northeast-1.amazonaws.com/prefect_introduction/prod-prefect-flow:latest
[2022-10-13 23:17:33+0900] INFO - prefect.Docker | Pushing image to the registry...
Pushing [==================================================>] 590.2MB/578MBkB
Registering 'ml-workflow'... Done
└── ID: 519d3844-087a-44ef-8432-9804f06df1c5
└── Version: 1
======================== 1 registered ========================ECRにFlowのimageがpushされていることを確認できます。

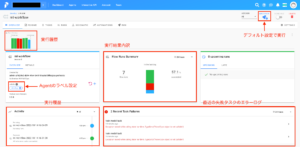
projectの管理画面からFlowが登録されていることを確認できます。
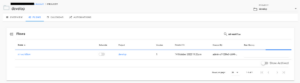
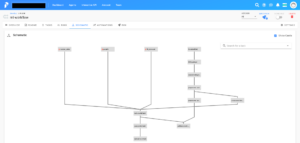
Flowの詳細ページでは、過去の実行履歴やFlowの設定を確認することができます。
タスクの依存関係を視覚的に表現してくれて、今回のケースだと、ハイパーパラメータがモデルの学習タスクへ入力されていることを確認できます。
Flow実行
Flowを管理画面から手動実行する場合、使用するAgentのlabelを設定する必要があります。
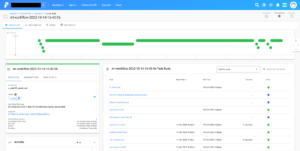
右上のQUICK RUNを押すと、デフォルト設定ですぐに実行できます。
実行中のFlowの詳細画面を見ると、現在実行中のタスクの状況をリアルタイムで確認することができます。
Flowの実行進捗状況を、視覚的に確認することもできます。タスクを選択すると、そのままタスクのログページに飛べます。
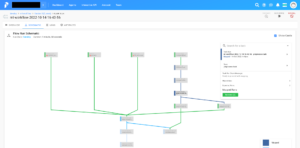
Prefect Cloud上でアプリケーションログを監視できます。ECS Agentを使用してる場合でも、Agentがログを収集し、リアルタイムでPrefect Cloud上でログを見ることができます。
ログの検索が可能で、エラーレベルで絞ることが可能となっています。
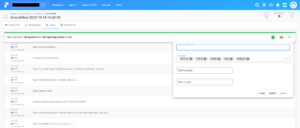
Runタブを開くと、詳細な実行設定を行うことができます。
パラメータの値、CPU・メモリなどを任意の値に設定して、実行することができます。
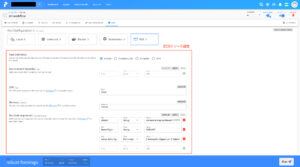
不正な値をハイパーパラメータに設定して、エラー通知を確認してみます。
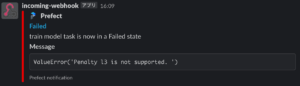
web_hook_urlを設定したSlack チャンネルに、エラー文と一緒に通知が届いてます。
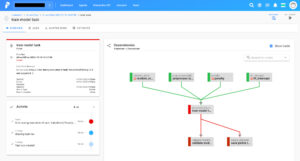
エラー通知のリンクをクリックすると、エラーが発生した箇所に直接飛んでくれます。
今回はSGDClassifierに不正なハイパーパラメータが渡されたため、学習タスクへリンクされます。
まとめ
Prefectを本番環境で運用するための方法を紹介しました。
Airflowに比べてまだまだ日本語記事が少ないですが、Slack Communityが用意されているため、気楽に質問を投げることができます。
https://prefect-community.slack.com/
Airflowに不便さを感じた方は、国内での導入事例の一つとしてPrefectを検討してみてはいかがでしょうか。
本文中ソースコード:https://github.com/nsakki55/prefect-ml-workflow
参考文献
- https://docs-v1.prefect.io/core/concepts/tasks.html ↵
- https://docs.prefect.io/collections/catalog/ ↵
- https://docs-v1.prefect.io/core/concepts/flows.html ↵
- https://docs-v1.prefect.io/core/concepts/parameters.html ↵
- https://docs-v1.prefect.io/core/concepts/mapping.html ↵
- https://docs-v1.prefect.io/core/concepts/schedules.html ↵
- https://docs-v1.prefect.io/core/concepts/tasks.html#retries ↵
- https://docs-v1.prefect.io/core/concepts/tasks.html#triggers ↵
- https://docs-v1.prefect.io/core/idioms/conditional.html ↵
- https://docs-v1.prefect.io/core/advanced_tutorials/slack-notifications.html ↵
- https://medium.com/the-prefect-blog/the-prefect-hybrid-model-1b70c7fd296 ↵
- https://docs-v1.prefect.io/orchestration/#architecture-overview ↵
- https://docs-v1.prefect.io/orchestration/flow_config/storage.html ↵
- https://docs-v1.prefect.io/orchestration/agents/overview.html ↵
- https://docs-v1.prefect.io/orchestration/agents/ecs.html#ecs-agent ↵
- https://docs-v1.prefect.io/api/latest/cli/agent.html ↵
- https://docs-v1.prefect.io/orchestration/agents/ecs.html#custom-runtime-options ↵
- https://docs-v1.prefect.io/core/concepts/configuration.html#environment-variables ↵
- https://docs-v1.prefect.io/api/latest/storage.html#docker ↵
- https://docs-v1.prefect.io/api/latest/executors.html ↵
- https://docs-v1.prefect.io/core/concepts/notifications.html ↵
- https://docs-v1.prefect.io/api/latest/cli/run.html ↵
- https://docs-v1.prefect.io/api/latest/cli/register.html ↵