
こんにちは。システムセキュリティ推進グループの花塚です。本記事は、AWSにおける脅威検知のために取り組んだ内容について紹介します。
AWS上で脅威検知といえば、GuardDutyなどのサービスを使って実装するのが一般的だと思いますが、仕組みは構築できても以下のような悩みを持たれることはありませんでしょうか。
- 仕組みは完成したけど、結局アラートが対応されずに放置されている
- 限られた人的リソースの中で大量のアラートを捌ききれない
仕組みは構築できても、上記のような運用面に関する難しさを感じる事は少なくないと思います。そこで、この記事では、構築した仕組みとその仕組みを生かすまでの運用方法の変遷について詳しくご紹介します。
大規模なクラウド環境に対して、セキュリティをスケールさせたい方にとって少しでも参考になれば幸いです。
目次
背景
話を進める前に、取り組みを始めた背景について説明します。取り組み開始前、大きく2つの課題がありました。
各アカウントごとのセキュリティインシデントに気づける早さのばらつき
サイバーエージェントには、歴史的な背景から複数のAWS Organizationが存在し、AWSアカウント数は約700ほどです。
アカウント全体を眺めると、高い水準でセキュリティに関することができているアカウントもあれば、そうではないアカウントも存在しました。(各サービスにセキュリティ要件があるはずなので、必ずしも同じである必要はないですが)
そのため、セキュリティインシデントに気づける早さが各アカウントごとに大きくばらついてしまう可能性がありました。
アラート対応の負荷と属人化
私が所属しているシステムセキュリティ推進グループ(以降、自部署)は、会社全体に対する横断組織という位置付けで、以下の図の通り、各事業の柱ごとに数名のセキュリティエンジニアが担当する形で運用してきました。
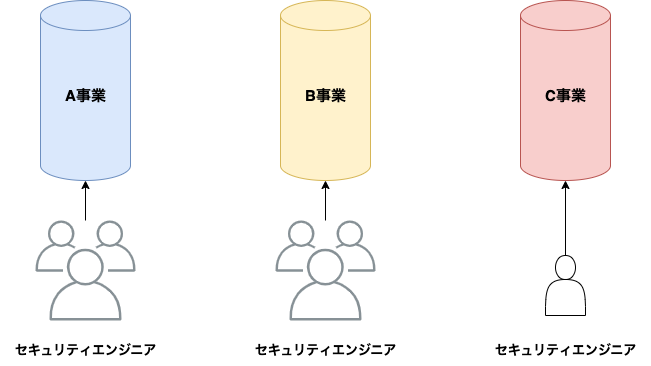
アラートが来た場合は、基本的に開発者と担当のセキュリティエンジニアが協力して対応するこの形は、セキュリティエンジニア同士の分業がされていて良い部分もありましたが、アラートの対応において以下のような問題点もありました。
- アラートが多い事業部の柱やAWSアカウントでは、負荷が特定のセキュリティエンジニアに偏る
- 担当のセキュリティエンジニアが退職した場合や長期不在の時に、対応を継続しにくくなる
構築した仕組み
上記2つの課題を解決するために、自部署の運用の変更とAWSアカウント全体のベースラインを向上させることを目標に仕組みを構築したいと考えました。
具体的な目標としては、「各エンジニアが、セキュリティインシデントに関する通知を漏れなく受け取り、原因を特定できる状態にする」という目標です。アラートだけできるようになっても、調査を行える状態になってなければ対応がうまくいきませんので、各エンジニアが調査する環境もできる限り整えました。
以降は、構築した仕組みを紹介します。構築した仕組みは、アラートに関する仕組みと調査するための仕組みの大きく2つに分かれます。
アラートに関する仕組み
まずは、アラートに関する仕組みについて説明していきます。構築した仕組みを一言で言うと、イベントやログが来たら、フィルター後にアラートを通知するシンプルな仕組みです。対応の自動化などは役割に入っていません。
簡単な全体像と各コンポーネントの説明は以下の通りです。
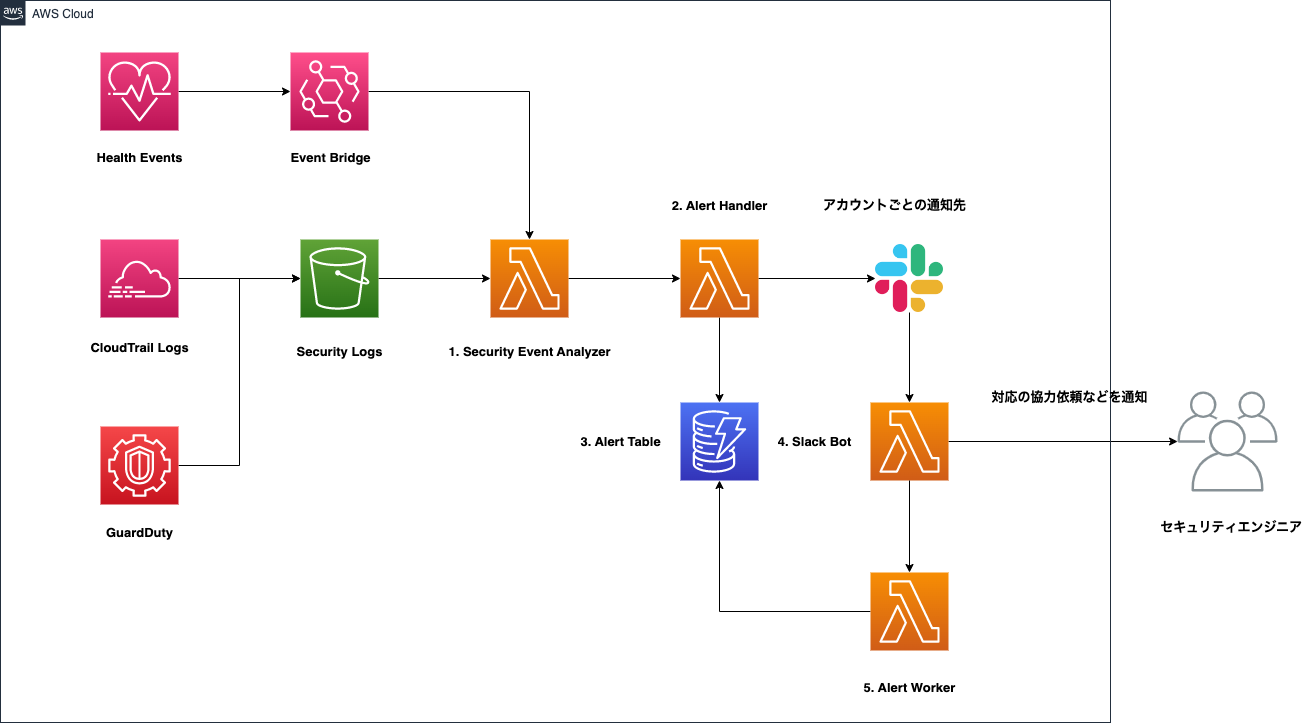
各コンポーネントについて説明します。
1. Security Event Analyzer
以下のようなログやイベントをRegoとOpen Policy Agentを使って、フィルターにかけています。
- CloudTrail
- GuardDuty
- Abuse Report
2. Alert Handler
Slackなどのインテグレーションに通知を行います。
各アカウントの通知先の管理などは、yamlで行なっており、アカウントが作成された時点で以下のような内容を含んだPull Requestが発行されます。
- accountID: "0123456789012"
slackConfig:
channelID: C00000000
channelName: aws-0123456789012-test
enabled: true
webhookOverrides: []
3. Alert Table
アラートの状態を保持したり、通知を抑制するために使われます。
4. Slack Bot
アラートの対応を助けるためのBotです。アラートのアーカイブやセキュリティエンジニアとの連携がSlack上でできるようになっています。
5. Alert Worker
アラートの状態を管理し、非同期で行われるタスクを処理します。
調査するための仕組み
次は、調査するための仕組みについて説明しています。
SIEM on Amazon OpenSearch Service
弊社では、調査するための環境として、SIEM on Amazon OpenSearch Serviceを使用しています。
こちらのOSSは、ログの正規化を行い、相関分析可能な見やすいダッシュボードを提供してくれます。
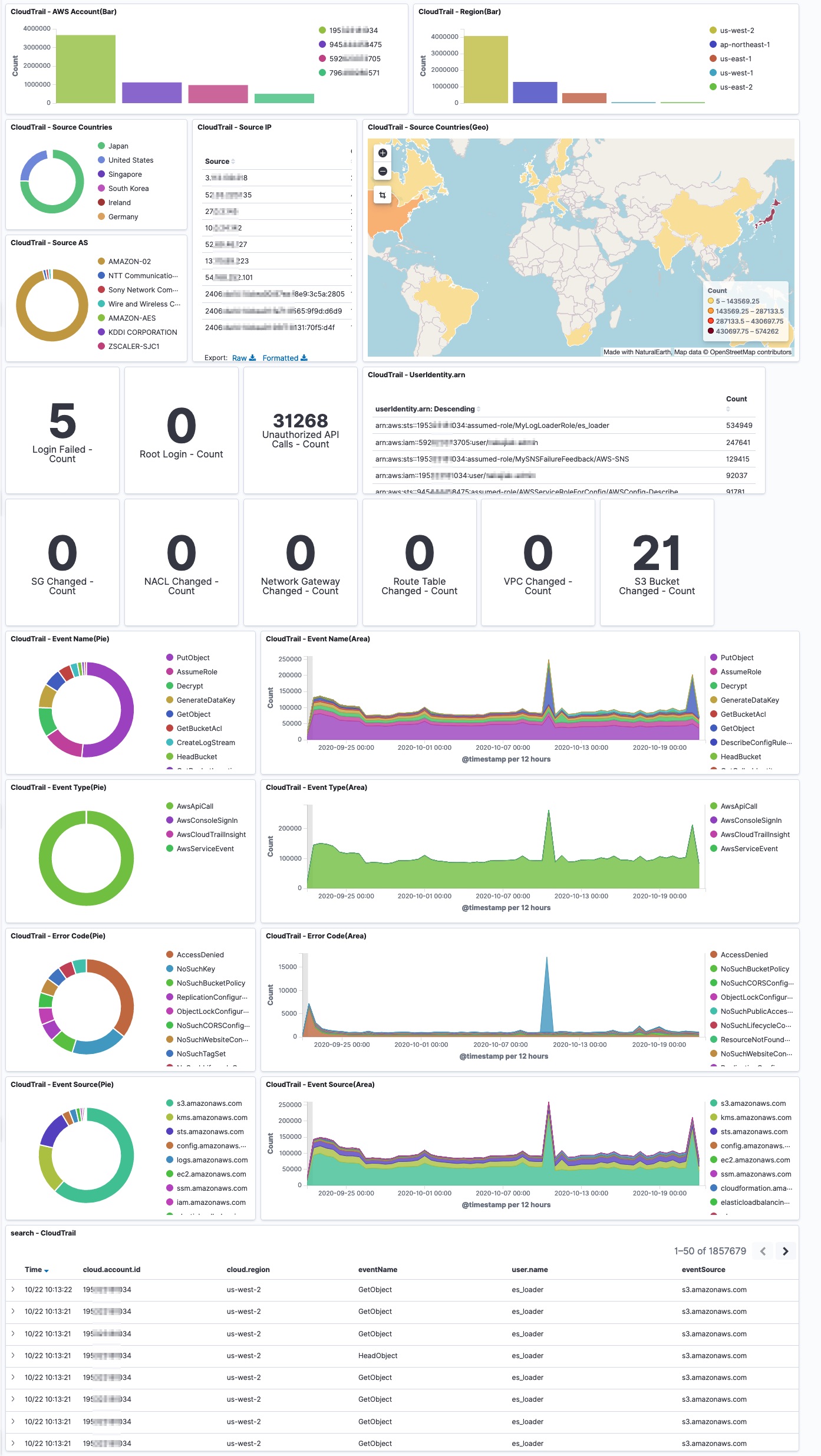
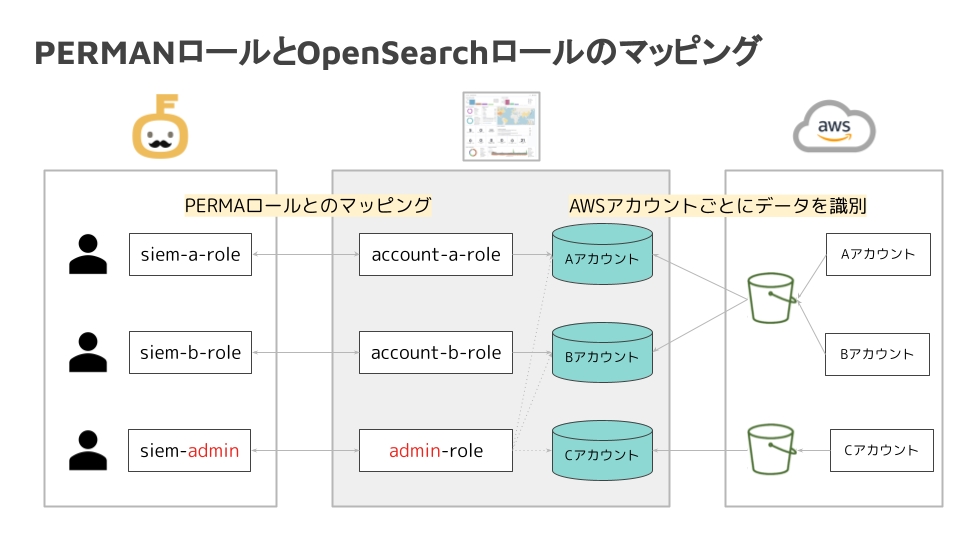
ただ、数百アカウントのログを、まとめて1つのOpenSearchドメインに集約すると、自分とは関係ないアカウントのログまでも見えてしまう問題があります。
この問題は、自社で内製しているPERMANと呼ばれるRBAC志向の認証認可基盤とOpenSearchのロールを組み合わせることで解決しています。
以上が構築した仕組みの簡単な紹介となります。
余談ですが、OpenSearch 2.4.0からはSecurity Analytics Pluginが登場しており、SigmaのRuleをインポートできるようなので、ログをフィルターする自前の実装から移行を検討するかもしれません。(とても便利そう)
運用とその変遷
さて、ここからは構築した仕組みをどのように運用してきたかを説明していきたいと思います。運用も構築した仕組みも時間と共に変化してきましたので、移り変わりが分かるように変化があった時期ごとにまとめています。
初期(取り組み開始以前)
この時期は、まだ本記事の取り組みを開始していない段階です。
背景でも説明したように、対応が各セキュリティエンジニアに委ねられ、対応の負荷も特定のセキュリティエンジニアに偏っていました。
人海戦術期(運用開始たて)
「初期」の対応の属人化や特定のセキュリティエンジニアに負荷が偏ることをなくすために、まずはアラートを通知する仕組みと調査できる環境を整えました。
ただ、この段階では、アラートに関する仕組みで紹介した図までは作っておらず、Slack Botなどの対応を手助けするコンポーネントはまだありません。運用を開始したばかりでしたので、最初から作り込み過ぎないことを意識しました。
この運用をはじめたての時期は、開発者にもアラートを通知していますが、基本的には自部署のセキュリティエンジニアが声をかけて対応を完了するという流れでした。
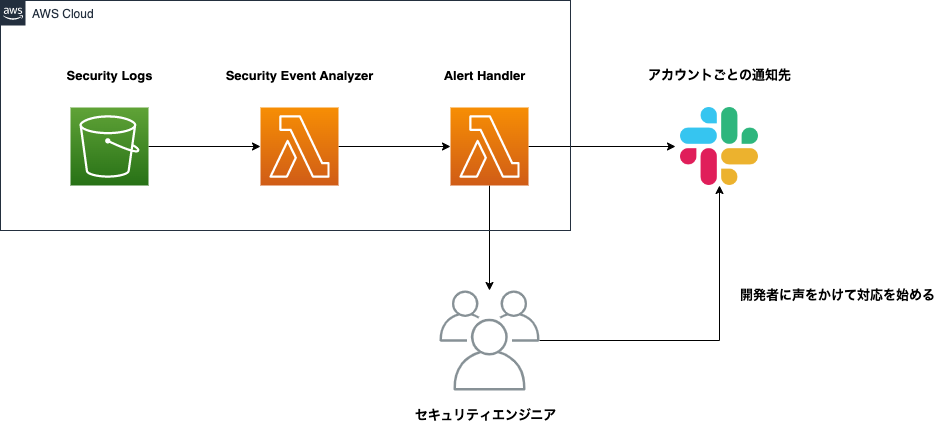
「初期」と比べて、対応の属人化や特定のセキュリティエンジニアに負荷が偏ることをなくすことができました。しかし、運用を継続している中で以下のような問題が出てきました。
- 大量のアラートが通知された場合は、手が回らなくなる時がある
- 手動で対応する部分が多く、対応に一定のストレスがかかる
これらを解決するための運用が、現在の運用方法です。
運用を開始したばかりは、このように色々と改善点が見つかるので、最初から作り込み過ぎずにしておくことがおすすめです。
現在
現在の運用では、基本的に開発者にアラートの対応をしてもらい、自部署はそれをサポートする形となりました。これにより、アラートが大量に通知された場合でも、各アカウントに分散されるため、「人海戦術期」よりも対応にかける時間が少なくなっています。
また、ただ開発者に対応を任せるだけでなく、開発者がアラートの対応をしやすい工夫を4つほど紹介します。
Slack Botの導入
対応をスムーズに行えるようにSlack Botを開発しました。
Slack上からアーカイブやセキュリティエンジニアとの連携が可能となっています。
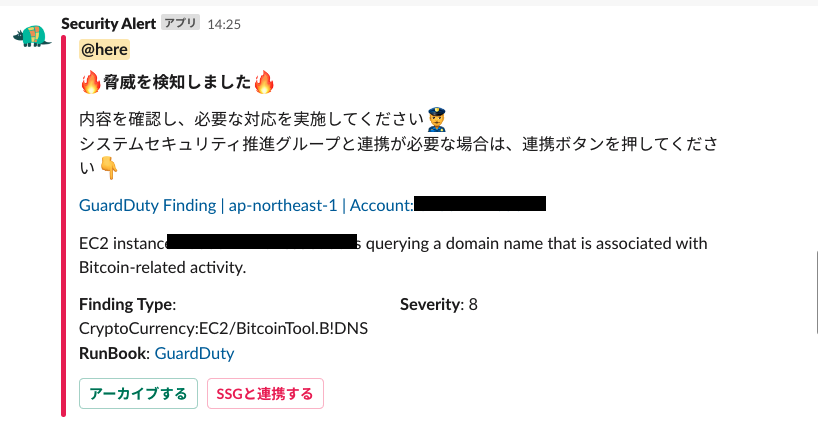
Slack上からアーカイブされた場合、開発者が記載したアーカイブの理由がセキュリティエンジニアに通知され、後ほど非同期で自動アーカイブされます。
Security Runbookの作成
開発者が対応すべきことをGitHubリポジトリにまとめています。誤検知の場合もあるので、その旨を書いたりもしています。
対応時間の計測
上記で紹介したSlack Botでは、イベントごとに時間を計測しています。
計測することで、対応が始まらない場合は声をかけたり、対応完了後の振り返りに活用することが可能です。
インシデント対応に備えるための社内イベントの開催
AWSさまと協力し、SIEM on Amazon OpenSearch Serviceの使い方をCTFライクな形式で学ぶイベントを社内イベントの一環として開催しました。
攻撃の痕跡が残されているログとそれに関する問題をAWSさまに提供していただき、SIEMを活用して参加者がそれらの問題を解きました。
イベントは大盛況に終わり、社内での告知もとても上手くいきました。
このようなハンズオン形式のイベントは、実際にアラートが通知された場合に役立つので、定期的に開催したいなーと思っています。
最後に
いかがでしたでしょうか。大規模なクラウド環境における脅威検知の取り組みを、構築した仕組みとその運用の変遷に分けて説明させていただきました。
脅威を検知してから対応が終わるまでの流れの中には、自動化できることもあれば、人間による手作業が必要な部分も存在します。仕組みを作っただけで終わらせずに、何回も試行錯誤を重ねて、自分達の組織にあった運用方法を見つけていただければと思います。
また、いきなり自前の検知ルールを導入するのではなく、AWSであれば、まずはGuardDutyから始めて対応までの形を作ってから検知ルールを拡張することをおすすめします。クラウド環境に対する攻撃や検知ルールに関する情報は、以下のような資料が役に立つので参考にしてみてください。
最後になりますが、システムセキュリティ推進グループでは、一緒に働く仲間を募集しています。興味がある方は、下記のリンクよりご応募お待ちしております!