
WINTICKET の Web 版(以降 WINTICKET Web)のテックリードを担当している @dora1998 です。
サービス開始以来、WINTICKET Web は Google Kubernetes Engine(以下 GKE)へデプロイして稼働していました。2022 年 10 月に Cloud Run を採用した構成へリアーキテクチャを行ったので、この記事ではその背景や具体的な構成、付随して行った改善について紹介します。
抱えていた課題
WINTICKET Web ではリアーキテクチャ前のバックエンド構成について、大きく 3 つの課題を抱えていました。
リリースの安定性
これまでのリリースフローでは段階的なリリース手段がなく、リリース内容に不具合が含まれていた場合にほぼ全てのユーザーが影響を受ける問題がありました。
加えて、WINTICKET はレース情報を提供する競輪システムをはじめ、ポイントや決済など多くの外部システムと連携しています。そのため、開発環境で動作を確認していても、本番環境固有のデータが表示できないといった不具合が稀に起きていました。
安定した品質を担保しながら柔軟な機能追加や改修に取り組むために、安全にリリースできる基盤は必要不可欠でした。
単一リージョンへの依存
東京リージョンの単一 GKE クラスタで稼働していたため、グローバルはもちろん、リージョン障害が起きてもサービス継続が難しい状態でした。
レースは朝から深夜にかけてほぼ毎日開催されており、サービスが常に安定して稼働することは極めて重要です。事業全体で可用性を高める取り組みが進んでおり、このタイミングでマルチリージョン化を進めることとなりました。
要件に対する GKE の運用コスト
前述した 2 つの課題は GKE で解決できるものではありますが、Web チームが主体的に取り組むには必要なスキルセット面でのハードルが高く、改善しづらい状況でした。
WINTICKET Web は単一の Docker コンテナで稼働するアプリケーションです。そのため、バックエンド構成に対して求められる要件は比較的シンプルでした。
GKE は柔軟な運用が可能なサービスですが、より簡素なマネージドサービスを選ぶことで運用コストを抑えられると考えました。
リアーキテクチャ後の Web バックエンド構成
WINTICKET Web のリアーキテクチャ前後におけるバックエンド構成を以下の図に示します。
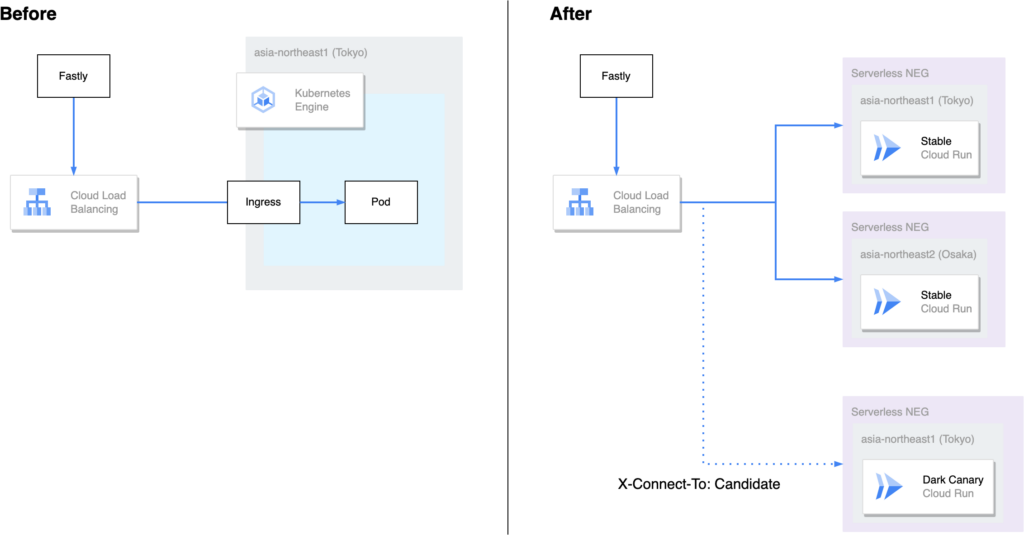
前段にある CDN の Fastly から Cloud Load Balancing でリクエストを受けるところまでは、リアーキテクチャ前後で共通となっています。Cloud Load Balancing に接続するバックエンドを GKE から Cloud Run へと移行したのが今回の主な変更です。
それでは、リアーキテクチャ後の構成について、主に先ほど挙げた課題に対応する形でポイントを 3 つお話しします。
マルチリージョン対応
東京と大阪それぞれのリージョンに Cloud Run サービスを作成しました1。この 2 つを Cloud Load Balancing にバックエンドとして設定することで、簡単にマルチリージョン対応を行うことができます。
Canary リリースの実現
Cloud Run には、トラフィックを流す割合についてリビジョンごとに指定できる機能があります。これを操作することで、新しいリビジョンへトラフィックを徐々に増やしていく Canary リリースを実現できます。マルチリージョンとして複数の Cloud Run サービスを配置した構成の上で、Canary リリースを実現するために Release Manager というツールを内製したのですが、このツールについては別の記事にて紹介する予定です。
Dark Canary の実現
Dark Canary とは、特定のアクセス条件に合致する一部のユーザーのみに対してリリースする仕組みです。今回は、主に一般ユーザーへリリースを始める前のタイミングで、社内の開発者が動作を確認するために整備しました。
構成としては、Dark Canary としてもう一個 Cloud Run サービスを作成し、Cloud Load Balancing の URL マップを用いることで、特定の HTTP ヘッダーを含む社内ユーザーからのリクエストのみが接続できるようになっています2。
通常の本番環境と同じ URL でアクセスできるため、認証や外部連携でコールバック先が固定されている機能についても確認できるのが大きな特徴です。
リアーキテクチャに付随して行った改善
デプロイやメトリクスの送信といった GKE で稼働していた際の方法をそのまま引き継げない箇所が存在したこともあり、リアーキテクチャに伴って取り組んだ改善についてもいくつか紹介します。
CI/CD パイプラインの改善
リリースフローに大きな変更が入ったこともあり、合わせて CI/CD パイプラインにいくつかの改善を取り入れました。
Docker イメージのビルドパイプライン最適化
従来、CircleCI でテストや型検査を全て通過したのちに Docker イメージのビルド・プッシュを行なっていましたが、以下のようにビルドとプッシュのジョブを分割しました。
jobs:
run_build_image:
steps:
- run:
command: |
docker buildx build -t web:latest -o type=docker,dest=- . > image.tar
- persist_to_workspace:
root: ~/web
paths:
- image.tar
run_push_image:
steps:
- attach_workspace:
at: ~/web
- run:
command: |
docker load --input image.tar
docker push web:latestこのようにジョブを分割することで、テストや型検査の結果を待たずにビルドを実行できます。テストや型検査の通過後はプッシュのみを行えばよく、リリースにかかる時間を短縮することができました。
改善前は main ブランチにマージしてから開発環境に新しいバージョンがデプロイされるまで 30 分〜 1 時間程度要していましたが、レイヤーキャッシュの最適化やマシンスペックの強化も合わせて行った結果、15 分弱まで短縮されました。
semantic-release を使ったタグ打ち
権限管理などの都合から、これまで Docker イメージのプッシュとタグ打ちのジョブをそれぞれ異なる CI で実行していました。しかし、連続してマージした場合に、タグが指すコミットと Docker イメージをビルドした際のコミットが一致しないなどの問題が起きていました。
そこで、リアーキテクチャのタイミングで、イメージのビルド・プッシュと同時にタグを打つように改修を行いました。バージョン管理に semantic-release を採用し、コードフリーズ期間に develop ブランチへマージした変更は prerelease としてタグを打つといった柔軟な運用も容易に実現できました。
ロギング・モニタリング環境の改善
Cloud Run へ移行するにあたって、GKE 環境で構築していたログやメトリクスの収集方法を一部見直す必要があり、Cloud Run のベストプラクティスに沿った形で改善を行いました。
トレース ID でログのトレーサビリティ向上
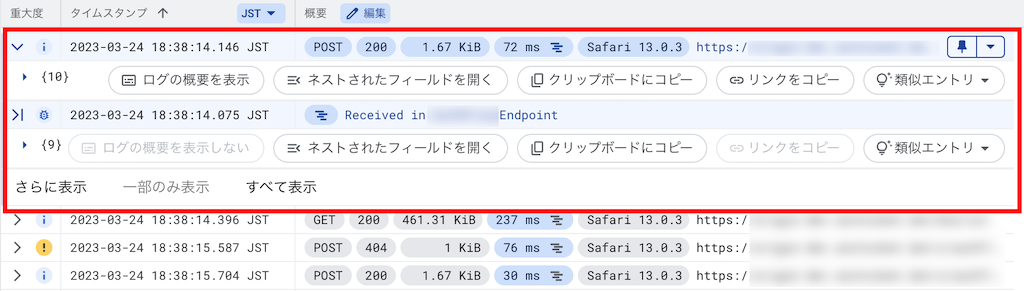
Web アプリケーションにおいて、特定の HTTP リクエストを調査する際に関連するアプリケーションログを探すケースは多々発生します。
同時リクエスト数が少なければ時系列で探すことができますが、同時刻に複数のリクエストが行われている場合、確実に特定のリクエストに関連するログを探すことは困難です。
Cloud Run への HTTP リクエストには Cloud Trace で使用できるトレース ID が標準で割り振られており、トレース ID を構造化ログに含めることでリクエストとアプリケーションログを紐付けて記録することができます。
具体的な実装例は Cloud Run のドキュメントに掲載されいてるソースコードにありますが、Cloud Run への HTTP リクエストには以下の形式で X-Cloud-Trace-Context ヘッダが含まれています。
X-Cloud-Trace-Context: TRACE_ID/SPAN_ID;o=TRACE_TRUEここから TRACE_ID のみを抽出し、下記のように構造化ログの logging.googleapis.com/trace フィールドに設定します。なお、このようなフィールドは「特殊フィールド」として、Cloud Logging のリファレンスに記載されています。
{
"severity": "INFO",
"message": "Hello",
"timestamp": "2023-01-01T12:00:00.000Z",
"logging.googleapis.com/trace": "projects/example-project/traces/0123456789abcdef0123456789abcdef"
}トレース ID で HTTP リクエストとログの紐付けが行えていると、Cloud Logging でこのように特定のリクエストに関連するログを一挙に確認できます。
ちなみに、WINTICKET Web では bunyan で実装したロガーが既にあったため、ロガーの初期化時にトレース ID を渡すことで、出力箇所によらずログにトレース ID を含むことができました。
Managed Service for Prometheus でメトリクス収集をマネージドに移行
これまで 各種メトリクスは Prometheus で収集し、サービス全体で共用している Grafana のダッシュボードで確認していました。
Cloud Run では CPU やメモリの使用率をはじめとする基本的な指標が Cloud Monitoring から標準で確認できます。しかし、 Fastly のメトリクスも Grafana へ統合していたため、Cloud Run 移行後も Grafana で一貫して管理したいと考えました。
調査を行ったところ、Cloud Monitoring が PromQL 形式でメトリクスを取得できる Managed Service for Prometheus を提供していたため、これを使って引き続き Grafana からメトリクスが確認できるように整備しました。
例えば、Cloud Run で稼働しているインスタンス数をリビジョンごとに取得する場合、以下のような PromQL で取得することができます。
sum(run_googleapis_com:container_instance_count{state="active"}) by (revision_name)また、renderToString の処理時間といった独自の指標もいくつか送信していましたが、それらは標準出力経由で Cloud Logging に送り、ログベースの指標として取得できるようにしました。
リアーキテクチャを終えて
WINTICKET Web を GKE から Cloud Run へリアーキテクチャを行うまでの背景や構成、付随して取り組んだ改善について紹介しました。
リアーキテクチャから約半年が経ち、1 年で最もアクセスが集中する年末の大会期間も含め、オートスケールで安定して稼働しています。
加えて、当初課題に感じていたリリースの安定性などは既に改善の手応えを感じています。例えば、リリース前の Dark Canary による確認で、新機能に関してバックエンド側のデータが一部揃っておらず、ページのレンダリングに失敗するといった事例を実際に防ぐことができました。
次回は、リアーキテクチャに際してどのようにゼロダウンタイムで本番環境の切り替えを行ったか紹介予定です。お楽しみに!