
はじめに
株式会社 WinTicket の @wadackel(わだまる)です。
WINTICKET の Web 版(以降 WINTICKET Web)で 2022 年に取り組んだ Web バックエンドリアーキテクチャについて 2 本の記事を公開しました。
本記事はこれらの続編に位置付けたもので、リアーキテクチャ後のリリースにまつわる具体的な手法に焦点を当てた内容を扱います。単体で読めるよう適宜補足を加えながら進行しますが、前述した 2 本の記事と合わせて読んでいただけるとスムーズに読み進めることができるはずです。
WINTICKET Web の新アーキテクチャでは、リリースの安定性を向上するための仕組みとして Canary 及び Dark Canary リリースを持ちます。マルチリージョンとして展開された Cloud Run サービス群を対象に Canary 及び Dark Canary リリースを安定して行うために内製した Release Manager というツールについて紹介します。
記事の構成としては、前半に前提となるアーキテクチャとリリース手順について、後半にかけて Release Manager の仕組みと技術的な工夫や課題についてまとめています。
WINTICKET Web バックエンドのアーキテクチャ
リリースにまつわる具体的な内容の前に、前提として WINTICKET Web がどのようなバックエンドの構成としているのかについて触れておきます。前々回公開した記事である 「WINTICKET Web の GKE 脱却と Cloud Run の採用」 の内容と重複する部分もありますが、特にリリースに関連したものに絞って整理します。より詳細な構成や、リアーキテクチャの背景については過去記事を参照いただけると幸いです。
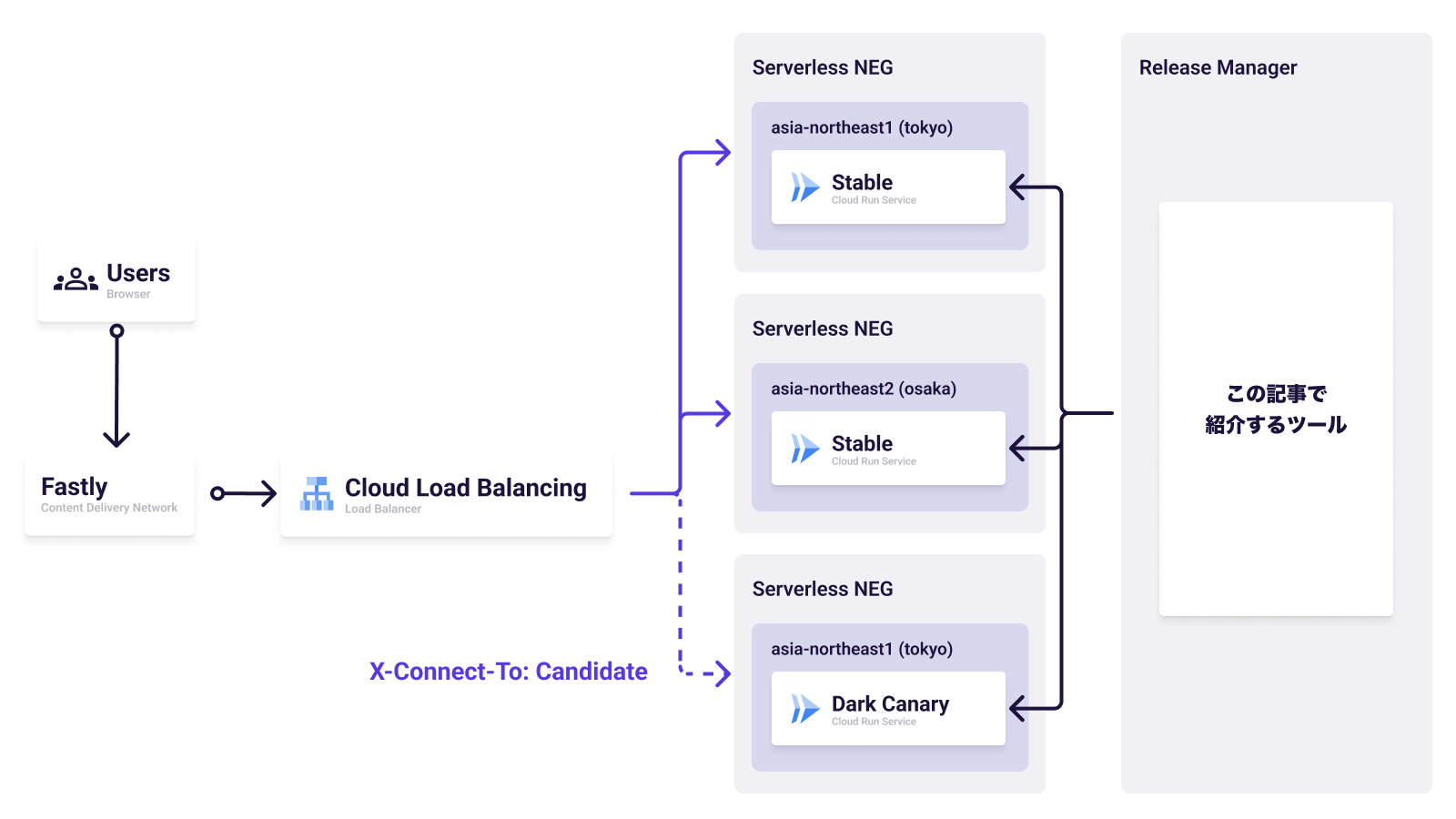
東京リージョン(asia-northeast1)と大阪リージョン(asia-northeast2)、それぞれにデプロイした Cloud Run サービスに対して Serverless NEG を設定、Cloud Load Balancing のバックエンドサービスとして登録することでマルチリージョン対応を行っています。
通常のトラフィックは CDN として利用している Fastly を経由し、Cloud Load Balancing がリクエストを受けた後は画像内 Stable と記述した Cloud Run サービスへリクエストが到達します。
通常のトラフィックではリクエストが到達しない Dark Canary として、もう一つ Cloud Run サービスが存在します。Cloud Load Balancing の URL マップを用いることで、特定の HTTP ヘッダーを含むリクエストのみがこのサービスにルーティングされます。主に社内から開発者の検証目的として運用されています。
ここまででバックエンドがどのように構成され、Dark Canary リリースがどのように実現されているかについては整理できました。ここからは日々の運用においてどのような手順で Canary 及び Dark Canary リリースがされるかについてまとめます。
リリース手順
リアーキテクチャ後、原則すべてのリリースを Canary リリースとしています。また、マルチリージョン対応を経て複数存在する Cloud Run サービスでありつつも、日々のリリースに関するオペレーションは各リージョンの存在は透過的に扱えるように工夫しています。
これから紹介するリリースオペレーションは、Slack(ChatOps)、GitHub Actions(以降 GHA)、ローカル環境の 3 つから実行可能となっています。運用の中で主に利用するのは Slack です。それでも 3 つの実行環境を用意しているのは、Slack や GHA が障害やメンテナンス中でも同等のオペレーションが行えるように冗長化する目的があります。
Canary リリース
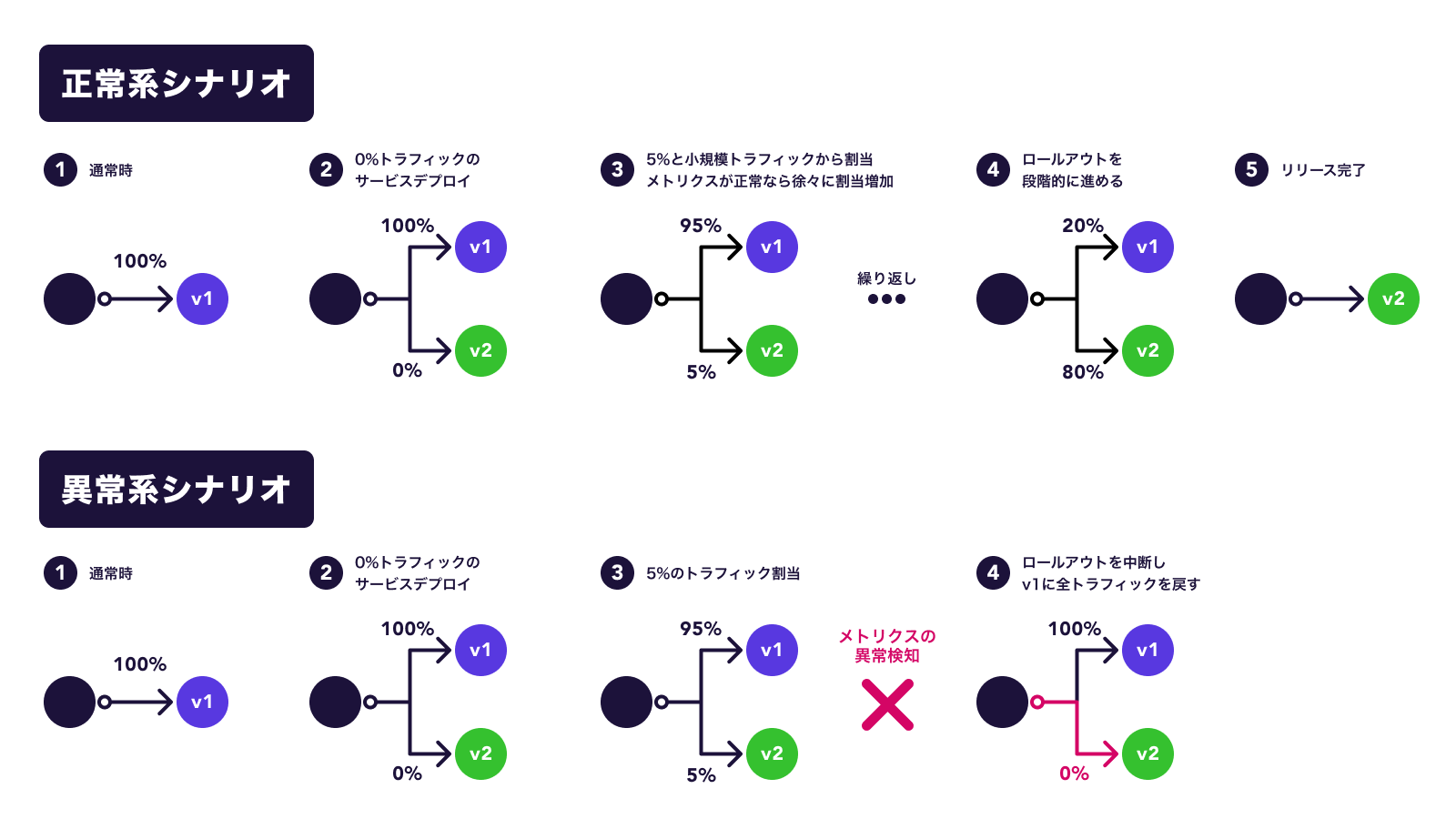
前述したようにすべてのリリースが Canary リリースを前提として、時間経過に応じて新規のリビジョンが 5%、20%、50%、80%、最後は 100% と段階的にロールアウトしていきます。トラフィックの割当を変更する前に、監視対象としているメトリクスの基準を超えていないかの確認を行います。監視するメトリクスは現状 3 つで、最小限のリクエスト回数、レイテンシー、エラーレートです。監視対象のメトリクスで異常検知をした場合は自動的にロールバックを行います。
そして、実際にトラフィックが切り替わるタイミングで Slack へ通知されます。
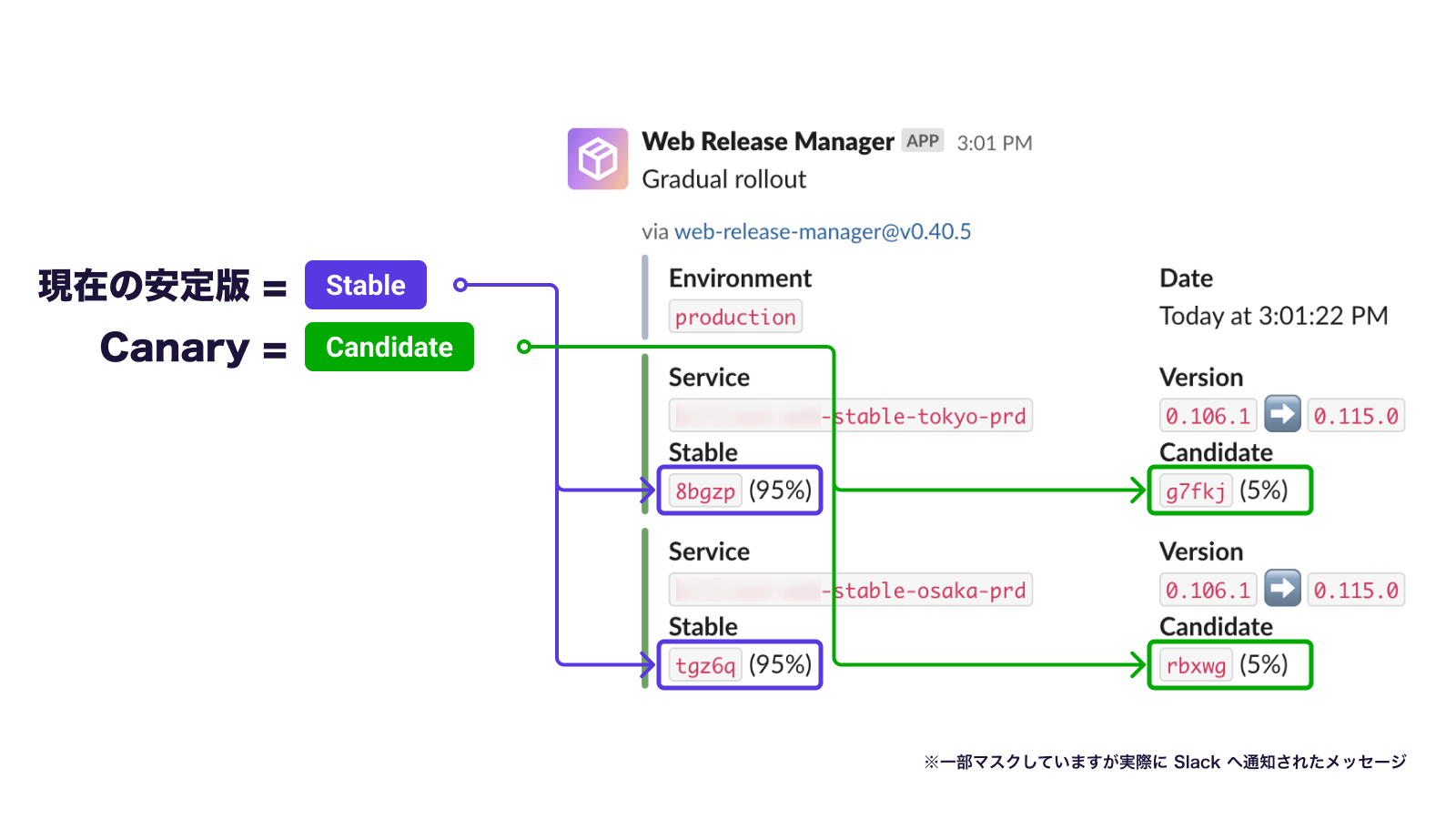
WINTICKET では本番、ステージング、開発環境の 3 つが動作環境として存在します。環境変数やスケーリングルール、リリースバージョンなど、実行環境に依存した設定値は YAML ファイルとして各環境向けに保持しています。
YAML ファイルで設定値が管理されていることを前提知識として、段階的ロールアウトが開始される契機は次のとおりです。
- 開発環境:main ブランチの変更後
- ステージング環境:ステージング環境用の YAML 設定変更時
- 本番環境:GHA から workflow_dispatch を実行
Dark Canary リリース
Dark Canary リリースは、特定のヘッダーがついているリクエストを Cloud Load Balancing が受けた場合、Custom HTTP header-based routing を用いて Dark Canary 用の Cloud Run サービスへルーティングすることで実現しています。
Canary リリースとは異なり、Dark Canary リリースの場合はどの環境かに依らずリリースオペレーションを行うまで自動的にリリースされることはありません。しかし、main ブランチに変更を加えたタイミングで、トラフィック割当が 0% の状態で全環境向けに新規リビジョンが作成されます。
このままではアクセス可能な Dark Canary のリビジョンは切り替わらないため、明示的にリビジョンの切り替えを指示する必要があります。例えば、Canary リリースが開始されるより前に本番環境で動作検証をしておきたいアプリケーションバージョン v1.2.3 を Dark Canary リリースしたい場合、Slack にて次のようなスラッシュコマンドを実行します。
/web prd dark rollout version 1.2.3スラッシュコマンド実行後、処理が完了したら指定したバージョン番号に対応するリビジョンにアクセス可能となります。
その他のオペレーション
通常のリリースは Canary リリースとして自動的に処理され、Dark Canary リリースは適宜利用したいタイミングで手動処理します。その他にも、日々の運用において必要となるオペレーションをいくつか用意しています。ここでは詳しく紹介はしませんが概要だけまとめておきます。
- Cloud Run サービスの状況確認:トラフィックの割当状況や現在のリビジョン、バージョン情報などを Slack 上に通知します。
- 段階的ロールアウトのスキップ:新旧リビジョンを一気に切り替えます。多用こそしないものの、過去バージョンと整合性を保つことが難しい変更が含まれる場合や、Dark Canary の実施を経て、影響がほぼないことがわかっている変更などで利用します。
- 段階的ロールアウトの一時停止:特定のトラフィック割当(5% など)でしばらく監視を続けたいようなケースで利用します。
- 特定バージョンへの即時切り替え:指定バージョンへトラフィックを切り替えます。過去バージョンへの切り戻しを行う場合に利用します。
- リリース可能なバージョンの一覧確認:指定できるバージョンの一覧を表示します。バージョン切り替えを行うための確認として利用します。
Release Manager の設計
ここからは、前述したリリース周辺のオペレーションを支える Release Manager についてです。
大枠の設計は GoogleCloudPlatform/cloud-run-release-manager(現在は archived されています)を踏襲したものです。マルチリージョン対応や Dark Canary リリースのオペレーションなど、他にも WINTICKET Web の満たしたい要件を叶えるには機能不足で、あくまで参考とはしつつも内製することとしました。
具体的に機能不足を感じた要件は次のようなものが挙げられます。
-
- マルチリージョン対応
- cloud-run-release-manager はシングルリージョンを前提としているため
- Dark Canary リリース
- WINTICKET Web 固有の実装であるため
- 段階的ロールアウトの監視メトリクスカスタマイズ
- リクエスト回数、エラーレート、レイテンシーの 3 つがサポートされていますが、将来的に他のメトリクスを運用に応じて追加していきたかったため
- リリースに付随タスクの一本化
- SpeedCurve のリリース番号ノート追加、Fastly のキャッシュパージ、Slack への通知など、リリースに付随するタスクを一本化したかったため
- マルチリージョン対応
- ChatOps への対応
- Cloud Run サービスとして動かすこと前提としているため、Slack App として稼働させること自体は可能でしたが、設計上の大幅な見直しが必要だったため
また、cloud-run-release-manager は Go による実装がされていますが、チーム内で議論をした結果 Node.js & TypeScript を採用しました。Go、Rust、Deno、Node.js & TypeScript と候補を上げて比較検討しましたが、Web チームのメンバーが保守していくにあたり最も通常業務で利用している技術スタックに親和性が高かったことと、実運用に耐える SDK が存在したためです。
全体像
Release Manager の技術的な構成や工夫について触れていきます。
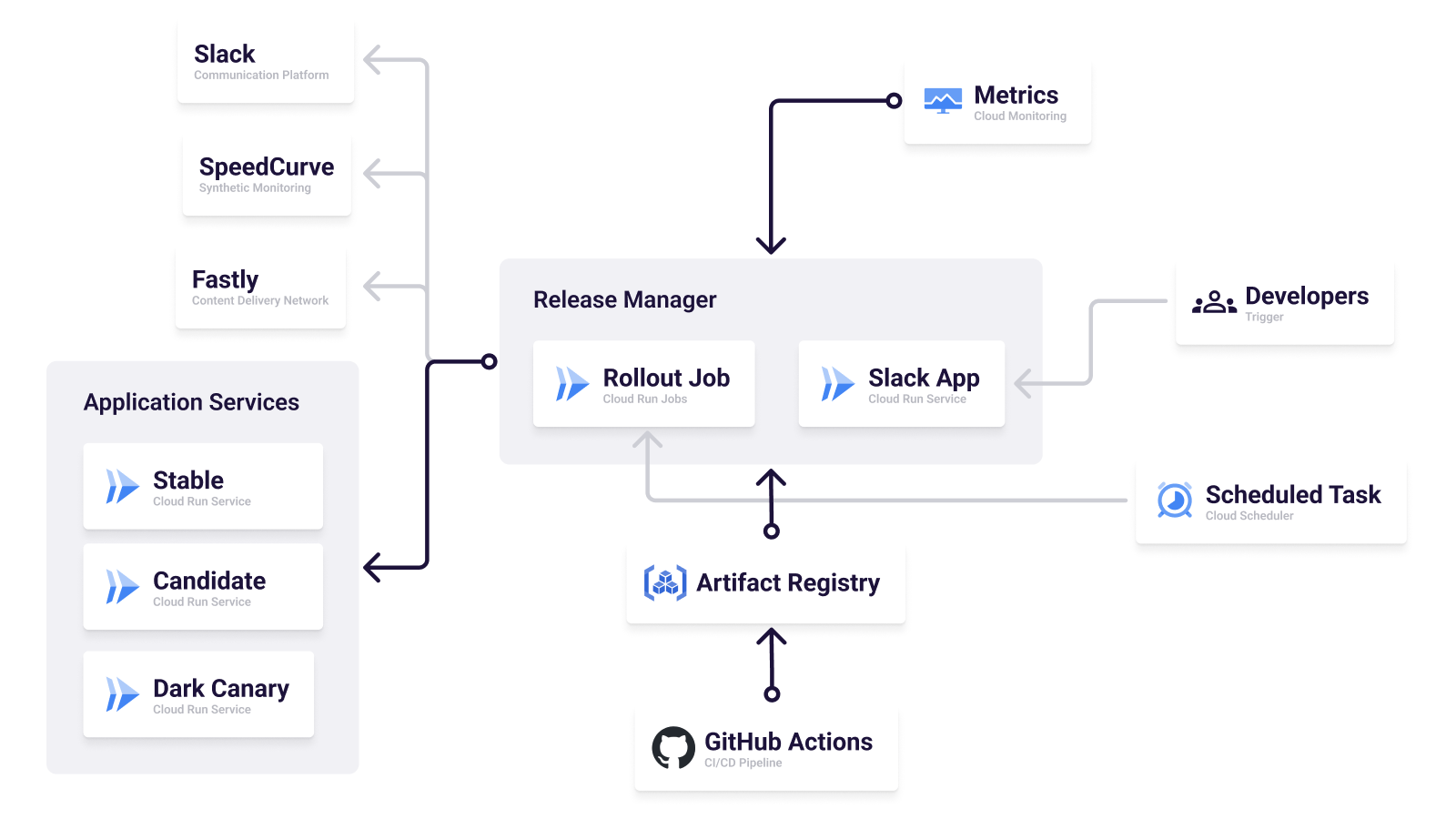
Release Manager がオペレーションを処理するトリガーは CLI 及び Slack の 2 種類です。
CLI は Cloud Run Jobs にジョブとして登録され、段階的ロールアウトの実行を Cloud Scheduler を契機として一定時間ごとに実行されます。参考とした cloud-run-release-manager は Cloud Run サービスとして動かすことを想定したものでしたが、タスクとして単発で処理さえできればよかったため、開発検討時点でまだ GA ではなかったものの Cloud Run Jobs を採用しました。
その他、CLI として GHA の workflow_dispatch やローカル環境での実行も可能ですが、前述したとおり運用の中でメインとして利用するのは Slack からの実行のため、あくまで予備的な位置づけです。
Slack は Cloud Run サービスとして稼働する Slack App です。主に開発者起点でのオペレーションを処理するためのスラッシュコマンドを提供します。Slack App としての実装は npm パッケージとして公開されている Bolt を採用しています。
大別すると 2 種類のトリガーに対応する Release Manager ですが、設計上の工夫として monorepo を採用しています。
.
├── apps/
│ ├── slack-app # ChatOps 用の Slack App(Cloud Run サービスとして稼働)
│ └── cli # CLI インターフェース(Cloud Run Jobs として稼働)
└── packages/
├── core # Release Manager のコア実装
└── ... # その他共通パッケージがいくつかロールアウトやデプロイ処理、その他のオペレーションで紹介したすべてのロジックは core パッケージとして切り出されています。apps 以下に存在する各実行環境向けのパッケージでは、あくまで実行環境固有の実装(起動 + リクエストの I/O 処理)がメインとなり、共通ロジックは core パッケージを利用するのみとなる構成をとっています。
annotations を利用した状態管理
ロールアウトやロールバックなどのオペレーションは、対象となる Cloud Run サービスが最後いつトラフィック割当を更新したか、ロールバックが発生した際にどのリビジョンに戻すか、などの状態管理が必要となります。外部に DB を持つことで解決することもできますが、metadata.annotations を利用することで Cloud Run のみで完結できる構成を採用しています。これは参考とした cloud-run-release-manager の実装でも採用されている手法です。
具体的には release-manager.cloud.run 接頭辞をつけたフィールドで、各リージョン毎の Cloud Run サービスに必要な状態を metadata として含めています。次の例示ではリビジョンは xxxx でマスクしていますが、雰囲気を掴むことはできるかと思います。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
...
annotations:
release-manager.cloud.run/lastRollout: '2023-01-01T00:00:00.000Z'
release-manager.cloud.run/lastHealthReport: |-
status: HEALTHY
metrics:
- STACKDRIVER_REQUEST_COUNT: 100 >= 250
- STACKDRIVER_ERROR_RATE: 0 < 0.005
- STACKDRIVER_LATENCY: 1234 <= 3000
lastUpdate: 2023-01-01T00:00:00.000Z
release-manager.cloud.run/lastFailedCandidateRevision: xxxx
release-manager.cloud.run/previousStableRevision: xxxx
release-manager.cloud.run/stableRevision: xxxx
release-manager.cloud.run/candidateRevision: xxxx
release-manager.cloud.run/rolloutState: ready
...
アプリケーションバージョンとリビジョン管理
WINTICKET Web の本体アプリケーションは Semver に沿ったバージョニングを採用しています。一方で、Cloud Run のトラフィック割当などのサービス管理は、主にリビジョンを使った操作が行われます。
シングルリージョンで稼働したサービスであれば、リビジョンの識別子を直接オペレーション対象とすることが可能です。しかし、マルチリージョン対応した構成では各リージョン毎に異なるリビジョンを持つため煩雑なオペレーションが必要となってしまいます。これが 2 リージョン程度であれば許容できそうですが、3 つ 4 つと増やしてしまうと骨が折れることが想像できます。
そのため、オペレーションの対象はあくまでアプリケーションバージョンを採用し、リビジョンの存在は透過的に扱うようにしています。
/web prd dark rollout version 1.2.3そこで必要となるのが、アプリケーションバージョン番号と、それに対応する Cloud Run サービスのリビジョンとの対応表です。この対応表に関しても annotations で管理する方針をとっています。
release-manager.cloud.run/versions: |-
1.2.6:xxxx-8w267
1.2.5:xxxx-txf9b
1.2.4:xxxx-5xqkx
1.2.3:xxxx-6q2jwannotations に対応表を残す方針を採用する前は、v1-2-3 などのリビジョンタグを Cloud Run サービスの各リビジョンに付与することで、アプリケーションバージョンとリビジョンの翻訳を行おうとしていました。実装コストも低く、挙動としてわかりやすいためです。しかし、Cloud Run サービスは min-instances を 1 以上に設定した状態で、リビジョンタグが振られていると課金対象となってしまうため方針変更を行いました。
WINTICKET Web は min-instances を 1 以上にした設定を行うため、コスト肥大化を防ぎつつオペレーションを直感的に行うために、やや複雑ではありますが上記のような工夫をしています。
余談ですが、この方針は annotations に記述されるコード量がリリースの度に無限増殖する課題を抱えているため、過去 50 バージョンに限定して対応表を残すことにしています。50 程度過去バージョンが遡ることができれば、通常の運用でまず困ることはないだろうという判断のもとです。
リージョン間の整合性を担保する疑似トランザクション
例えば、ロールアウトやロールバックのオペレーション中に東京リージョン(asia-northeast1)でのみ何らかのエラーが発生し、大阪リージョン(asia-northeast2)がうまく処理されてしまった場合、各リージョン間で状態の差分が発生します。前述した通り、各リージョンの存在は透過的に扱われるため内部状態に差分が出てしまうと復旧に一手間掛かってしまいます。この問題を避けるために擬似的なトランザクションを実装しカバーしています。
具体的には更新前の Cloud Run サービス状態をオンメモリで保持しつつ、サービス状態の更新処理中にエラーが発生した場合は、保持しておいた更新前の状態に戻すように試みます。
擬似的なコードにはなりますが、Cloud Run サービスを更新するようなロジックを実装する際は、次のようなイメージとなります。
// Cloud Run サービスの各リージョンサービス名
const refs = ['tokyo', 'osaka'];
// サービス名を渡すことで、Cloud Run サービスを解決しオブジェクトに展開する
// さらに更新前のサービス状態を内部的に保持する
$operation.transaction(refs, async (service) => {
// 各リージョンの Cloud Run サービスにあたるオブジェクトが `service` として引数に渡る
// このコールバック内で例外が投げられた場合、元の状態に復旧を試みる
});Cloud Run SDK が提供する機能ではなく、自前のロジックとして実装しているが故に完全な復旧が叶わないケースがでてきます。そのためこれを便宜上「疑似トランザクション」と呼称しています。
擬似的なものではあるものの、現状ほとんどのケースで復旧することができています。
オペレーションの排他制御
リリースに関連したオペレーションは、Cloud Scheduler を契機として 5 分間に 1 度段階的ロールアウトの処理が実行されたり、Slack 契機で処理が発生します。
そのため、単一のオペレーションが完了する前に、別のオペレーションが同一 Cloud Run サービスに対して更新をかけようとするケースが頻発します。同時に Cloud Run サービスを更新しようとして、状態がちぐはぐになってしまうことを避けるために独自の排他制御を実装しています。
実装としてはフラグを用いた簡易的な制御を行っています。annotations に release-manager.cloud.run/locked というフィールドを持ち、Cloud Run サービスが Release Manager によるオペレーション中であるかどうかを真偽値で保持します。オペレーション中である場合は次のような状態となります。
release-manager.cloud.run/locked: 'true'このフラグが立っている場合、つまりロック状態の処理はオペレーション種別によって異なります。
開発者が実行するオペレーション(バージョン切り替えなど)の場合は、ロック状態が解消されるまで一定時間待機を行い、オペレーション実行者が複数回指示を出すことを可能な限り避けます。
一方ジョブとして実行されるオペレーション(段階的ロールアウト)の場合は、5 分後に実行される次のジョブに処理を委ね実行中のジョブは即時終了します。
Cloud Run サービスは Condition を参照することで「更新可能か否か」という状態を知ることができます。しかし、Release Manager のオペレーションは終始 Cloud Run サービスを更新し続けるわけではないため、独自の管理機構が必要となります。
疑似トランザクションでも紹介したとおり、やはりこれも完全な整合性を担保することが難しく、Cloud Run 自体の障害中や実装上の想定ミスがある場合、意図せずロック状態のままとなってしまうことがあります。ロック状態になってしまうと Cloud Run サービスに対する更新が行えなくなるため、ロック解除用のスラッシュコマンドを提供することで日々の運用を凌いでいます。
監視メトリクス
段階的ロールアウトの際に基準として利用するメトリクスは Cloud Monitoring API を通じて次の 3 種類を取得しています。
- リクエスト数:最低リクエスト数として利用、一定のサンプル数が欲しい
- エラーレート:異常なリクエスト(5xx)が急激に増えていないか
- レイテンシー:極端な性能劣化が起きていないか
これらの閾値は本番、開発環境などの各実行環境向けの設定値を持った YAML ファイルに定義しています。
rollout:
...
health:
offset: 1200000 # 20min
criteria:
# 右辺3つ目の真偽値は、超えるべきメトリクスなのか否かのフラグ
# リクエスト回数は最低限の値として扱いたいためこのようなフラグを持ちます
STACKDRIVER_REQUEST_COUNT: ['>=', 250, true]
STACKDRIVER_ERROR_RATE: ['<', 0.005, false]
STACKDRIVER_LATENCY: ['<=', 3000, false]メトリクスは 20 分間隔のデータとして集計し基準と照らし合わせます。基準に満たない場合はロールバックを行った上で Slack へ通知します。
現状抱える課題と今後の展望
ここまでで Release Manager が行っているオペレーション、さらにそれを実現している技術的な側面の紹介をしてきました。
最後に内製した Release Manager を導入後、半年ほど運用してみて見えてきた課題と展望について、すべてを挙げられないにしても主要なものについて触れたいと思います。主に段階的ロールアウトにまつわるトピックが中心です。
リージョン毎の段階的ロールアウトの基準設定
WINTICKET Web で行っているマルチリージョン構成は、東京、大阪の 2 リージョンを拠点としています。そして現状、段階的なロールアウトの基準はリージョンに依らず同一のものを参照する仕組みとなっています。
当初想定していたよりも東京、大阪リージョンのリクエスト規模に開きがありました。具体的には東京リージョンと比べて、大阪リージョンのリクエストが少ない状態です。 その状態で東京リージョンに合わせたリクエスト数の基準を設けていると、大阪リージョンのロールアウトがなかなか進行しないケースが起きてしまっています。
大阪リージョンの基準に合わせてしまうと十分に信頼できる基準として成立しないため、各リージョンのリクエスト規模に対して個別に適切な基準を設けられるように改修を計画しています。
段階的ロールアウトの基準にクライアントメトリクスを追加
WINTICKET Web は Server Side Rendering(以降 SSR)を行ったあと、Single Page Application(以降 SPA)として動作する Isomorphic Web Application です。
一度 SSR した後は SPA として様々なページ遷移を繰り替えしていく性質上、Cloud Run サービス標準で取得できるバックエンドのメトリクスだけでは、アプリケーションの健康状態を正しく把握できたとは言い切れません。
クライアントで収集可能なメトリクスを段階的ロールアウトの基準に設定することで、リリース対象バージョンの健康状態をより広く測ることが可能となるはずです。
エラーレポートの収集には Sentry を採用しているのですが、残念ながら現状エラーレートを正しく活用できる状態ではありません。そのため、クライアントの監視強化を行った後、段階的ロールアウトの基準に取り入れることを検討中です。
クライアントメトリクスを、バックエンドメトリクスと合わせて基準化することが、Release Manager を内製するにいたった大きな要因でもあったため、そう遠くない未来に実現させたいと考えています。
まとめ
WINTICKET Web が行った Web バックエンドのリアーキテクチャ後に導入した Canary 及び Dark Canary をはじめ、リリースに関連した様々なオペレーションを支える Release Manager について紹介しました。
弊社が開発、運用している PipeCD でも Cloud Run サービスの Canary リリースに対応しています。しかし WINTICKET Web では、更に運用最適化をしたものを求めていたため内製という手段をリアーキテクチャのタイミングでとりました。
課題と展望の章でも書いたとおり、まだ発展途上な点もあるため日々の運用の中で更に改善を続けていければと思います。