
こんにちは、メディア事業本部DP(Developer Productivity)室で3ヶ月インターン生として働かせていただきました南波陽平(@kevin-namba)と申します。
インターンシップ概要
自分が参加したプログラムは「CA Tech Mission」というもので、3ヶ月間、週3〜5日で社員の方と同様に機能開発を行います。
比較的難易度の高い機能開発(Mission)を任せていただきますが、メンターの方に丁寧にフィードバックしていただけるので、スムーズに開発を進めることができます。開発の他に、進路相談や、他のチームや事業部の方にお話を聞くためのランチ、面談をセッティングしていただけました。自分はこのインターンシップに参加する前に、TerraformやKubernetesなどのIaC(Infrastructure as Code)の経験やCI/CDの運用経験があったこともあり、PipeCDというOSSのCDツールの開発チームでインターンさせていただきました。
PipeCDとは?
PipeCDとはDelivery Infrastructureのためのツールで、TerraformやKubernetes、AWS ECSやGCP Cloud RunへのデプロイをGitHub上の設定ファイル(tfファイルやManifestファイルなど)に従って自動で行うことができます。この手法はGitOpsと言われ、GitHub上のファイルを更新(コミット)を検知すると自動でインフラにデプロイが行われ、失敗すると直前の状態にRollbackされます。
メトリクスの閾値や特定のユーザーのapproveに基づいた制御、canaryやblue greenを用いたdeployを設定することも可能です。
OSSではありますが、CyberAgentのPipeCDチームがメンテナンスしており、ABEMAを始め多くの社内のプロダクトにPipeCDを使っていただいています。
PipeCDの詳細な使い方や説明については、以下の記事 や公式サイトを参考にしてください。
自分のMissionについて
さて、ここから本題の自分に課されたMissionについての説明をしたいと思います。
PipeCDの一番の特徴は、実行環境やデプロイ対象のインフラの自由度が高いことが挙げられます。例えばGitOpsを用いたDelivery Infrastructureのツールとして有名なものでArgoCDやFluxCDが挙げられますが、これらのツールはKubernetesにしか対応していない一方、PipeCDはTerraformやAWS ECS・Lambdaなどにも対応しています。一方で自分がインターンシップを始めた当初はtemplatingの方法はKustomizeとHelmに限定されており、それ以外のtemplatingを用いてKubernetes Manifestをapplyすることはできませんでした。また、AWS ECSやlambdaもPipeCDの内部でAWS SDKを用いていて、ユーザーはPipeCDの定めた設定を書くことでそれらをデプロイするので、PipeCDでTerraformを用いることはできますが、CloudFormationやAWS SAM(Serverless Application Model)を用いてECSやlambdaにデプロイすることはできませんでした。実際社内でPipeCDでSAMを利用したいという声や、HelmとKustomize以外のtemplatingツールを導入したいというissueが寄せられています。一つずつ対応していくのは簡単ですが手間がかかってしまいます。
そこで自分のMissionは、「ユーザー定義でtemplatingやデプロイの手段を拡張できるようにしよう」ということになりました。
Templatingツールの調査とCustom Templatingの実装
Templatingツールとは、yamlやjsonなどの設定ファイルのフィールドや設定値を変数として管理できるようにして、バージョン管理などを楽にするためのツールです。
例えば、KustomizeやHelmでは
kustomize build [directory] | kubectl apply -f -
helm template [name] [directory] | kubectl apply -f -
といったコマンドで、変数がセットされた一つのManifestファイルとして出力することができ、そのファイルをKubernetesにapplyすることができます。
PipeCDではloader関数でtemplatingが必要な場合はhelmやKustomizeのtemplatingを行なってapplier関数に一つのmanifestファイルとして渡して、applier関数内でapplyを実行しています。そのためHelmやKustomize同様にユーザー定義のtemplatingツール用のloader関数を作ってあげれば実装できることがわかります。
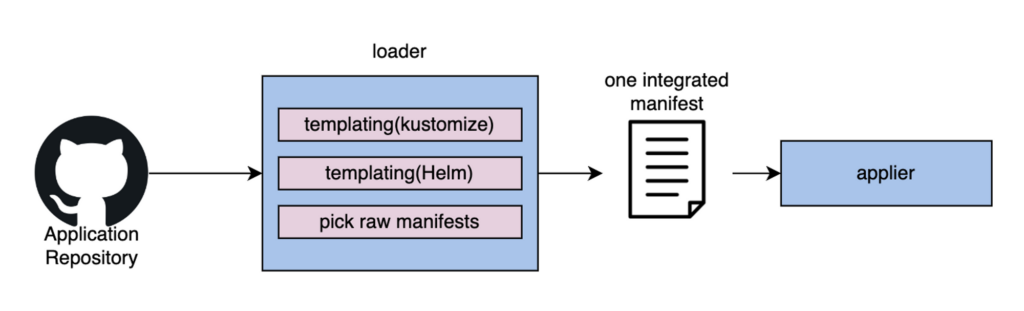
issueにあるとおり、KustomizeとHelm以外だとCUEやjsonnetが有名なようです。
CUEやjsonnetはKubernetesに特化されたtemplatingツールではないので、kubernetesに対応させるために少し工夫する必要があるそうです。CUEではKubernetesで用いる際の公式チュートリアルがあったので、それを参考にしました。
CUEやjsonnnetでもkubernetes用の設定ファイルを書いてあげることで、
cue dump ./…
jsonnet -y -e (import "dev.libsonnet").all
のような形で一つのManifestファイルとして出力することができます。
そのため、下のような形で、Kubernetes用の設定ファイルを書き、loader関数内でユーザーが指定したコマンドとコマンド引数でtemplatingを実行し、Manifestをapply関数に渡すことで、ユーザー定義のtemplatingを可能にすることに成功しました。
apiVersion: pipecd.dev/v1beta1 kind: KubernetesApp spec: … input: customTemplating: command: "cue" args: - "dump" - "./..."
Deploymentについて
さて、Custom Templatingの実装も終わったので、本題のデプロイ手段の拡張について書くのですが、その前にPipeCDの重要な概念であるDeploymentとstageについて説明します。PipeCDではGitHub上にApplication Configと呼ばれる設定ファイルを置き、そのファイルに基づいてPipeCDで行うデプロイの設定を行います。Application Config上で監視下に置くインフラの設定ファイル(tfファイルやManifestファイル)を管理し、Application Configで管理される単位をApplicationと呼びます。PipeCD上にApplicationが最初に登録されたときや、Application内の変更を検知したとき、すなわちcommitしたときにインフラにデプロイが行われます。このデプロイ単位のことをDeploymentと呼びます。DeploymentにはQuick SyncモードとPipelineモードの二種類あります。
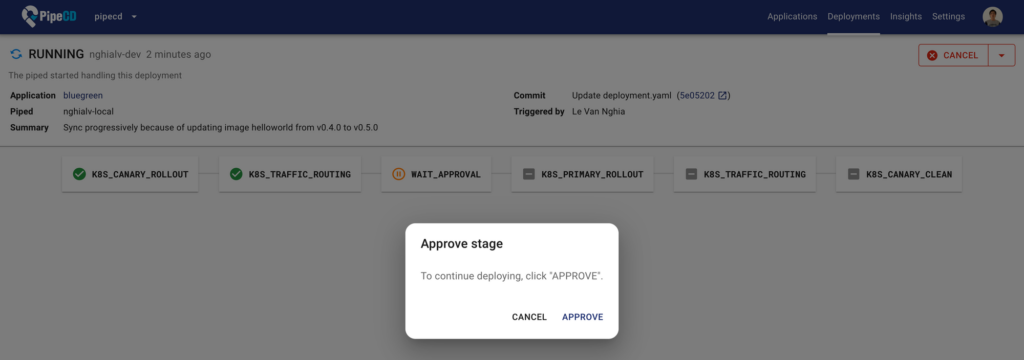
pipelineモードは複数のstageの遷移によって構成され、canaryやblue-greenなどの設定や、approveによる実行制御を行うことができます。
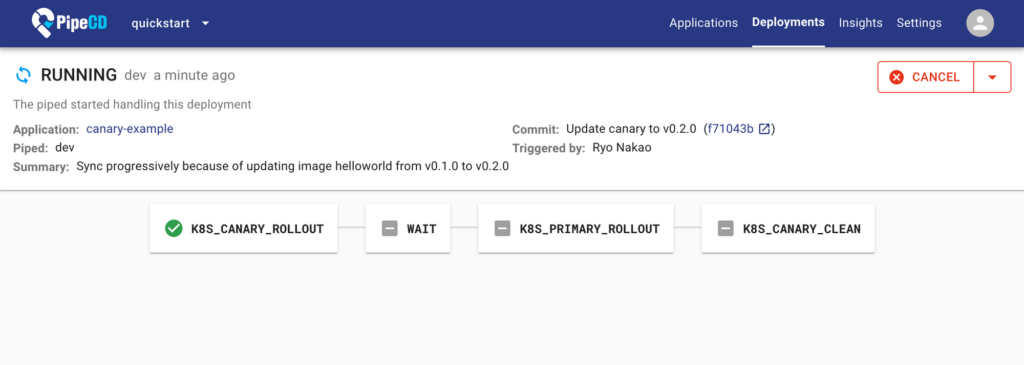
Application作成時は指定しない限りはQuick Syncモードになります。Quick SyncモードはSyncのステージのみから構成され、選択したPlatform Provider(Kubernetes, Terraform, ECS, Lambda, Cloud Runのいずれか)のデプロイ処理のみが行われます。
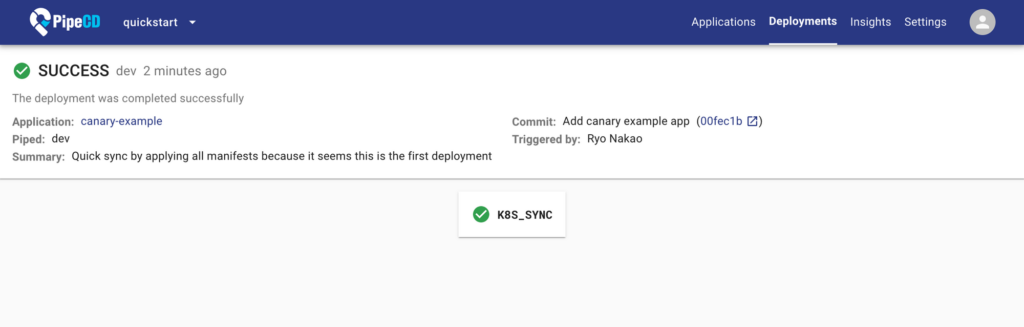
どちらのモードの場合も、ステージの処理が失敗した場合は前の状態に戻すのためのRollback処理が行われ、最後に通常に動いていたcommitのインフラの設定が適用され直します。
Custom Stageの設計について
最初デプロイ手段を拡張するための方法として以下の3つの方法が挙げられました。
案1.既存のPlatform ProviderのQuick Syncにデプロイするためのスクリプトを実行する機能を実装する
案2.パイプラインの中でユーザー定義スクリプト実行するようなステージ(Custom Stage)を作成する
案3.スクリプトを実行するような新たなQuick Sync(Custom Sync)を作成する
まず案1についてですが、Quick SyncはPlatform Providerに対応してstageが自動生成されます。例えば、Kubernetesを選択している場合KUBERNETES_SYNCという名前のステージが作成され、そのステージ内部でapply処理が行われます。しかし、新たなデプロイ手段を用いたい場合は元々のSyncの処理ではなく、スクリプトで定義された方の処理を実行する必要があります。一つのステージに複数の処理を行う可能性をユーザーを混乱させてしまいます。
次に案2についてですが、パイプラインの中でユーザー定義スクリプト実行するようなステージとなると、下の3つの例のようなかなり自由度の高いことができるようになります。
1.デプロイするためのステージ1つのみを持つパイプライン
pipeline:
stages:
- name: CUSTOM_STAGE
with:
run: |
- "echo y | sam deploy"
2.Custom Stageを使ってcanary rolloutを行うようなパイプラインを組む場合
lambdaではバージョンごとにエンドポイントを設定することができ、それらのエンドポイントへのトラフィックのウェイトを変えることでcanary deployを実現できます。そのため、SAMやCloudFormationで実装する場合、FUNCTION_WAIT フィールドをparameter-overridesするといった運用で、Custom Stageを用いてcanary deployを行うことができます。
pipeline:
stages:
- name: CUSTOM_STAGE
with:
run: |
"echo y | sam deploy"
- name: CUSTOM_STAGE
desc: "50%"
with:
run: |
"echo y | sam deploy --parameter-overrides FUNCTION_WAIT=0.5"
- name: WAIT
with:
duration: 1m
- name: CUSTOM_STAGE
desc: "100%"
with:
run: |
"echo y | sam deploy --parameter-overrides FUNCTION_WAIT=1"
3.Custom Stageを用いてweb hookを行うような、デプロイとは関係のない処理を行う場合
pipeline:
stages:
- name: K8S_CANARY_ROLLOUT
with:
replicas: 10%
- name: CUSTOM_STAGE
desc: "webhook"
with:
run: |
"curl https://hooks.slack.com/services"
- name: WAIT
with:
duration: 10s
- name: K8S_PRIMARY_ROLLOUT
- name: K8S_CANARY_CLEAN
しかし、実装の途中で自由度が高くなりすぎるとrollbackの実装で問題があることがわかりました。
Rollback
Custom Stageでも他のstageと同様に実行に失敗した場合はrollback処理をする必要があります。
Rollbackでは全てのdeployに関わるstageについて、最後に通常に動いていたcommit(running commitと呼びます)のインフラの設定が適用され直します例えばQuick Syncに失敗した場合は失敗する前のmanifestやtfファイルの内容がインフラに反映され、canary deployのtrafic weightの値を更新してパイプラインが失敗した場合は失敗する前のcanaryのweightの値に適用され直されます。
Custom Stageではどのようにrollbackを設定すればいいのでしょうか?
Quick SyncのようなデプロイするためのCustom Stageを1つのみを持つパイプラインの場合は、Custom Stageで実行されたスクリプトと同じスクリプトを、runnning commitのインフラの設定で適用すればいいということになります。しかし、canaryなどの処理を行うことを想定すると、stageの実行時とrolloutの実行時でスクリプトが異なる場合も想定されます。また、webhookなどの処理ではrollbackの処理が必要ありません。例えばデータベースのmigrationファイルのように、stageの設定に通常の処理とrollbackの処理の両方を書くようにしてあげることによって自由度の高いrollbackが可能になりますが、ユーザーの手間が二倍になってしまいます。また、Rollbackで最も厄介なのは、rollbackを行うかどうかの制御は最新のcommitで作成されたconfigに起因して決定されるのに対して、rollbackの処理自体は最後に通常に動いていたcommitの設定で行われます。そのため、pipelineの構成がcommitの前後で変更された場合、rollbackがどのような挙動をするのかは複雑になり、ユーザビリティを大幅に損ねます。
そのため、今回の実装ではとりあえずデプロイするためのCustom Stageである「Custom Sync」のユースケースのみに対応することにしました。
Platform Providerとの対応
Quick SyncモードはSyncのステージのみから構成され、選択したPlatform Provider(Kubernetes, Terraform, ECS, Lambda, Cloud Runのいずれか)のデプロイ処理のみが行われます。ではCustom StageはどのPlatform Providerと対応させれば良いのでしょうか?
PipeCDではApplicationの作成時必ずPlatform Providerを指定する必要があります。前述した通り、PipeCDはECSやLambdaは内部でAWS SDKを使ってデプロイしています。そのため自分は、SAMやCloudFormationを用いてlambdaやECSをデプロイするために用いても、Platform ProviderにLambdaやECSを選択することはできない、という考えでした。しかしPlatform Providerの種類を増やすことは大幅にユーザビリティを損ねることになります。内部的にはAWS SDKを使っているということはユーザーの知るところではないので、「どうしてLambdaにデプロイしようとしているのに、他のPlatform Providerを選択する必要があるのだろう?」という混乱を招くことになります。そのため、Custom SyncはどのPlatform Providerを選択しても同様に実行できるようにするということになったので、Custom SyncはQuick SyncモードではなくPipelineモードの1stageとして扱って、どのPlatform Providerでも実行できるようにしますが、Custom Syncを用いるときはPipelineにはCustom Sync1つのStageしか持つことができないというルールを作り運用することにしました。
stage実行の仕組みとCustom Syncの実装
設計仕様も固まったので実装に移っていきたいと思います。
PipeCDではplannerとexecutorというものを用いてdeploymentを作成し、stageを実行しています。以下にその流れを示します。
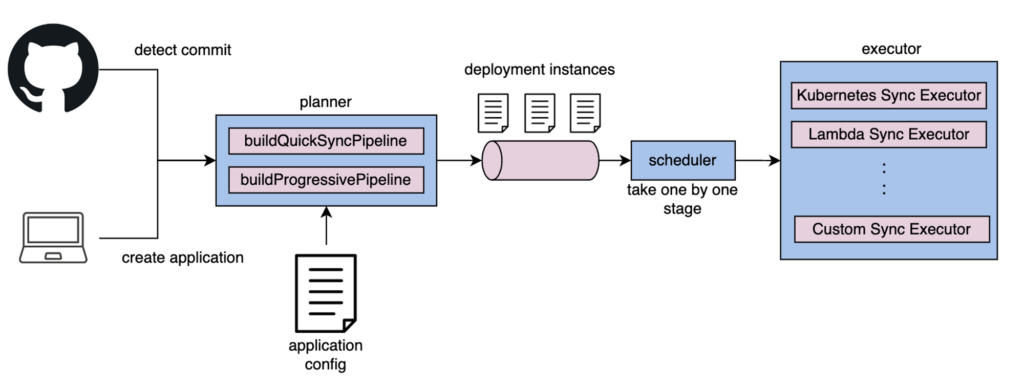
PipeCDのコンポーネントであり、デプロイを制御するプロセスであるpipedが起動するとcontrollerが作成されます。controllerはscheduler関数とplanner関数を定期実行しています。plannerがapplicationの作成やcommit、syncのリクエストを検知すると、plannerはconfig fileを元にQuick Syncやpipelineにより構成されるDeploymentを作成します。schedulerは作成されたDeploymentから1つずつstageを取り出し、executorにその情報を渡し、executorがstageを実行します。
つまり、deployment instance内で用いられるCustom Syncのステージの定義とCustom Syncのexecutorを作成し、その中でスクリプトを実行することで、PipeCDで任意のスクリプトを実行することができました。
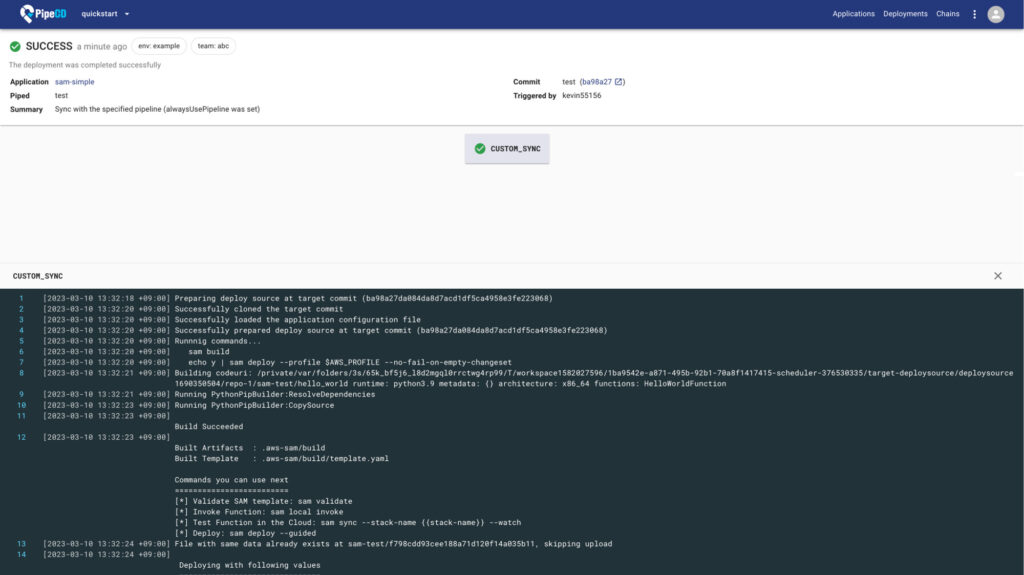
Custom Sync(SAMによるdeploy)の実行の様子
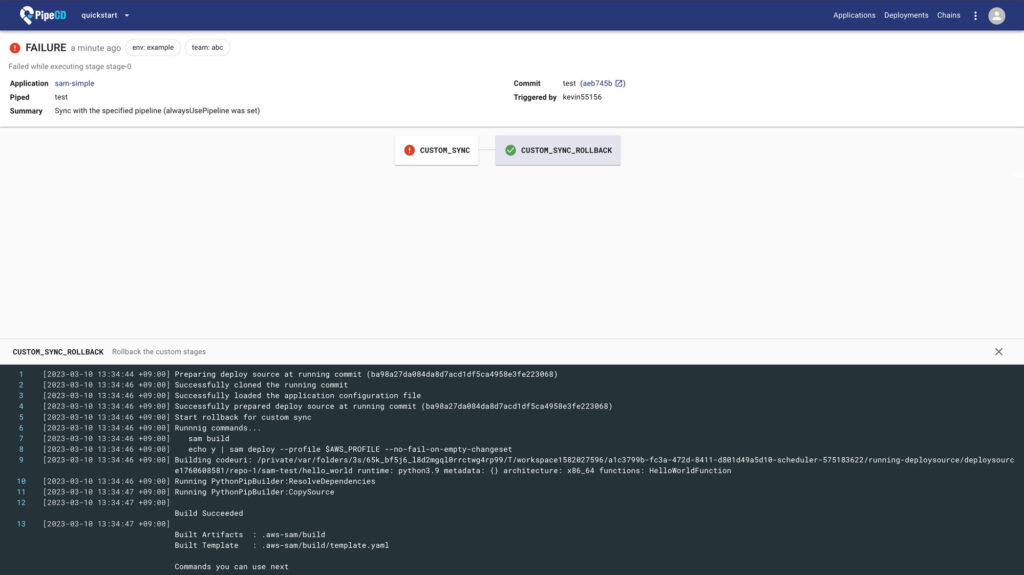
Custom Syncのrollbackの様子
asdfを用いた外部ツールの管理について
Custom TemplatingもCustom SyncもPipeCDが想定していないツールやコマンドを使うことが想定されます。
PipeCDが使うツールはPipeCDが管理できるようにするべきです。例えば、kubectlやhelmなどはApplication Configで指定されたバージョンがインストールされていない場合は自動でインストールされます。デプロイを制御するプロセスであるpipedがそれらのツールをインストールスクリプトを保持しており、piped用のディレクトリにインストールしてバイナリが配置されます。Custom Templating やCustom Syncではどのように設定してどのようにインストールされるべきでしょうか?
まずはどのように設定できるようにするべきかについて考えます。外部ツールを使うためにはコマンドとバージョン、そしてインストールするためのスクリプトが必要です。
externalTools:
- command: cue
version: 0.4.3
installScriptTemplate: |
curl -L https://github.com/cue-lang/cue/releases/download/v{{ .Version }}/cue_v{{ .Version }}_darwin_arm64.tar.gz | tar xvz
mv cue {{ .BinDir }}/cue-{{ .Version }}
chmod +x {{ .BinDir }}/cue-{{ .Version }}
mv cue {{ .BinDir }}/cue-{{ .Version }}
chmod +x {{ .BinDir }}/cue-{{ .Version }}
問題はこの設定をどこで定義するかです。piped起動時の設定ファイルに書くか、GitHub上に置くApplication設定ファイルに書くかの2つ考えられます。GitHub上の設定ファイルに書く場合は、Application単位で設定するのか、stage単位で設定するかの2つがあります。全てに対応させるのは難しくないですが、どちらの設定が優先されるかなど考えることが多くなってしまい、ユーザーの混乱を招いてしまいます。
参考に他のツールを見てみましょう。例えばGitHub Actionsではstepの中でusesを使うことで、あらかじめactionsやmarket placeに登録されているスクリプトが実行されインストールを行います。
steps:
- uses: actions/checkout@v3
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v3
with:
node-version: ${{ matrix.node-version }}
- run: npm ci
GitHub Actionsに倣い、Application設定ファイルの可読性を考慮して、使用する外部ツールの定義自体はGitHub上に置くApplication設定ファイルで行い、インストールするためのスクリプトはpipedが起動時に読み込む設定ファイルに書く、という運用にすることにしました。
しかし、実証の途中でSAMのバイナリをpiped管理のディレクトリに置かないと動かないということを発見しました。Pythonで作成されたバイナリファイルは指定されたディレクリに( /usr/local/bin / )バイナリを置かないとうまく動かないことがあるようです。GitHub ActionsやCircleCIなどのCI/CDツールでは使い捨てのコンテナ上でスクリプトが実行できるので、環境が汚れるといったことを考えることなく、ツールのインストールを行うことができます。しかし、pipedが動いている環境はコンテナとは限らず、使い捨ての環境にするのは簡単ではありません。なるべくpipedが /usr/local/ bin/ のバイナリを管理するということは避けたいです。そのため、今回はasdfという外部ツールを使って管理することにしました。
asdfは言語だけでなくkubectlやAWS CLIなどのツールにも対応したバージョン管理ツールです。今回想定しているようなCUEやSAMもasdfで管理することができます。asdf自体のバイナリはホームディレクトリ直下の .asdf の中に含まれます。
また、Application設定ファイル上で外部ツールを設定したときは
asdf local [name] [version]
を実行することにより、Applicationのディレクトリのみに適用されるようにし、piped起動時の設定ファイルで設定したときは
asdf global [name] [version]
を実行することにより、asdfを使ったことのあるユーザーは直感的に設定場所の使い分けができるような設計にすることができました。
まとめ
大きな新機能について設計から実装まで一貫して関わることができました。抽象度の高いタスクで最初はどのように設計すればいいかわからないことも多かったです。試行錯誤する中で以下の2つの重要性に気づきました。
1.言語化してpros/consを明確にしよう
今回のような設定ファイルやUIが関わってくるタスクでは、その設計がユーザビリティや仕様に大きく関わってきます。今回は候補となる設定ファイルの設計を全て列挙して、そのpros/consをslackの自分の分報で整理したり、丁寧に文書(design doc)にまとめました。文書を元に議論をすることで円滑に進めることが出来ました。
2.まずはユースケースをひとつに絞ろう
抽象度の高いタスクでは、なるべく多くのユースケースに対応しようとしがちです。しかし、想定するユースケースを増やせば増やすほど、どう実装すればいいか迷走します。実際今回のケースでも、ユースケースを増やし過ぎたせいでrollbackの実装で迷走してしまいました。最初は1つのユースケースに絞ってとりあえず実装し、必要なユースケースに応じて後から拡張するという考え方が大切であることがわかりました。もちろん、interfaceやクラス分けは意識して後々に拡張しやすいコードにしておくことも大切です。
3.実装と実証のフェーズと設計のフェーズを往復しよう
実装や実証のフェーズで設計のミスや実現不可能であることに気づくことはよくあります。今回の場合、Rolloutの実装や外部インストールの検証の際に気づくことがありました。このケースのように実際にコードを書いたり、実装してから検証しないと気づけないことはよくあると思います。踏み台となる設計を作ったらとりあえず実装して、うまくいかなかったら設計に立ち返るといったことの重要性に改めて気づきました。
最後に
インフラの知識からバックエンドやフロントエンドの知識までをフルに活かすことができ、とてもやりがいのあるインターンシップでした。特に、一つの機能について設計から実装まで行うという経験は初めてだったので、とても成長できたと思います。今回のMissionのような抽象的なタスクでは、自分はさることながら、チームの社員さんも正解を持っているわけではありません。実装と議論を繰り返しながら、時には社員さんのフィードバックを、時には自分の意見を取り入れながら一つの設計を完成させることができました。迷走することも多かったですが、メンターやチームの社員さんに丁寧にサポートしていただくことができたので、安心して進めることができました。
自分が作った機能によってPipeCDを使えるチームが増えたので、生産性向上に貢献することができたという点でも、とてもやりがいを感じる3ヶ月間でした。