
AI事業本部の黒崎( @kuro_m88 )です。
MySQL、PostgreSQLのようなRDBとAmazon DynamoDBやCloud SpannerのようなNoSQL、NewSQL系のDBを比較したときに、後者はRDBのauto incrementのような機能を実装しようとすると前者と比較して性能が出ない問題があります。この問題に対してRedisのLua Scriptingを用いて採番用のキャッシュを実装し、併用することで高速化した事例を紹介します。
本記事ではAmazon DynamoDBやCloud Spannerが採用されている環境を想定します。特に特定のDBに依存した考え方ではないので、その他のKVSやKVSベースのNewSQLにも応用できる考え方かと思います。手法を検討するのに使ったコードはGoで実装しました。
前提
前提としてKVSのような分散DBにおいて、auto incrementを積極的に利用するのは避けるべきです。
分散環境で単調増加するグローバルで一意な値を取得するには何かしらのロックを取得する必要があり、採番のパフォーマンス面でボトルネックになる可能性を完全に排除することはできません。
本記事ではこの前提がありつつも、止むに止まれぬ事情によってDBのレコード作成時に単調増加する値が必要だったため、我々のユースケースにとって現実的に問題が起きない程度の採番の性能を得ることを目的としています。
と、おおげさなことを書いてしまいましたが、実のところは小売(ドラッグストア、家電量販店など)向けのシステムでDynamoDBを使っている環境において、「受付番号」のようなものを発行するときに外部連携先の仕様との兼ね合いで番号が単調増加することが要件で、秒間数百〜数千件くらいの採番性能が欲しいという事情でした。本記事の手法では最終的に秒間10万件以上の採番性能を得ることができました。
一般的なauto incrementの代替の実装方法
まずシンプルな実装方法を紹介します。
Cloud Spannerに関してはこちらのドキュメントに手法が書いてありました。テーブルの行を使ってカウンタ(シーケンスジェネレータ)を実装しています。
https://cloud.google.com/solutions/sequence-generation-in-cloud-spanner?hl=ja
同期モード、非同期モードどちらもIDの生成の数が秒間100未満程度のようです。
並列アクセスやリクエスト量が増えると更新の競合が発生しやすくなり、その場合レイテンシが大幅に悪化することが注意点として書かれています。
Amazon DynamoDBにはincrementの仕組みがあります。しかしこれは特定のレコードのattributeの値をアトミックにincrementする仕組みであり、そのままではレコード追加時の自動採番としては利用できません。基本的にはSpannerのドキュメントのように採番用のテーブルを作成することになるかと思います。
ちなみに
ちなみにTiDBでは各ノードにauto increment用のキャッシュを持たせる(例: ノード1は1-19999, ノード2は20000-3999を割り当てておく)ことでそれぞれのノードで独立してauto incrementを行いつつ、全体で値が一意になるような実装を行なうことで極力ロックを取らずに複数ノードで同時に採番できるようになっています。そのため、常に最新のレコードのIDが単調増加し最大のIDの値を保つ状態は担保されません。
IDをキャッシュするサイズを1にすることで実質的に全体で単調増加をするようにすることもできるようです。v6.4.0以降でIDのキャッシュの割り当てが高速化されたようなので、本記事と似たような工夫がされているかもしれません。
調べきれていないのですが、auto incrementの需要に応えるための工夫を実装しているDBは他にもあるかもしれません。
https://docs.pingcap.com/ja/tidb/stable/auto-increment/
Redisを採番用のキャッシュとして使う
Redisを選択した理由は、AWSやGCPでRedisのマネージドサービスがあり、自前で運用する手間が少ないからです。あえてキャッシュという書き方をしているのは、Redisに保存される値に永続性を求めないようにしたいという意図があります。
Redisに保存する値に永続性を求めてしまうと、新たに維持管理するDBが増えることになり、障害発生時のデータリカバリの仕組みやバックアップなどの運用コストが増えてしまいます。
あくまでも永続化すべきデータはDB内で完結していて、Redisは採番の補助をする存在であり障害時は再起動やRedisサーバの入れ替えで済む構成を目指します。
アイデア
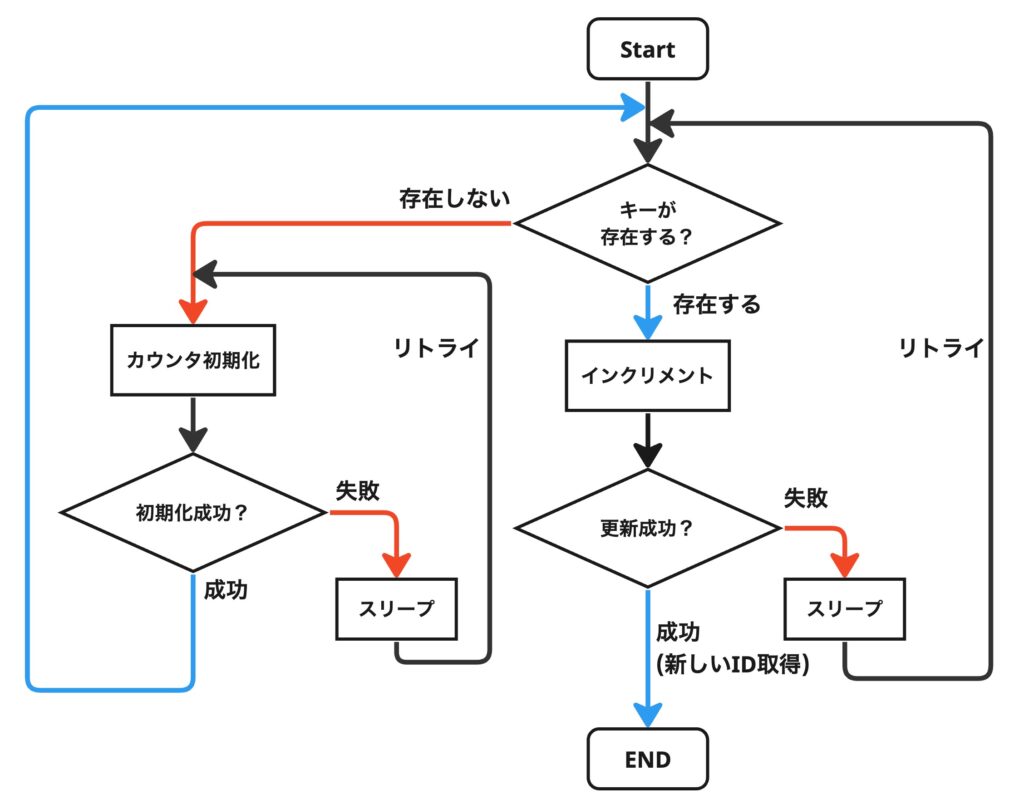
最初にキャッシュ(Redis)にカウンタ用のキーが存在するかチェックし、なければDBに値を取得しにいきます。DB側では既存のレコードのIDの最大値を取得します。その値をキャッシュにセットしカウンタを初期化します。
キャッシュ側の値が消えなければDBにアクセスすることはないため、基本的にはキャッシュヒット率はほぼ100%となりDBへの負荷はほぼ発生しません。
キャッシュにカウンタの値が保存されていた場合はその値をインクリメントし取得することで新たなIDとして利用します。
フローチャートを見ながらキャッシュの使い方を想像していただければと思います。
アイデアを検証するために実装したコードが以下です。後述する2種類の実装をしています。
go test -bench . でベンチマークが実行されます。
https://gist.github.com/kurochan/f4165816f070426917af873b9cd00b54
Redisは存在しないキーをインクリメントしてもエラーにならず、0として扱われてしまうため、必ずキーが存在するかチェックしないといけないのが注意点です。
懸念
この時点で二点ほど懸念がありましたが、それぞれ今回の用途に照らした結果問題ないという判断をしました。
採番したもののinsertしなかった場合にIDに欠番ができてしまう
IDを採番したものの、何らかのエラーでinsertをしなかったり失敗した場合にそのIDは使われません。
しかしこれはMySQLなどのRDBでも発生しうる挙動なので、まれにIDに欠番が発生することは許容しました。
自動インクリメント値を生成したトランザクションがロールバックされると、これらの自動インクリメント値が「失われます」。 「INSERT のような」ステートメントが完了したかどうか、およびそれを含むトランザクションがロールバックされたかどうかに関係なく、自動インクリメントカラムの値は一度生成されたら、ロールバックできません。
https://dev.mysql.com/doc/refman/8.0/ja/innodb-auto-increment-handling.html
auto incrementの値の大小関係がinsertの時系列と逆転しうる
本記事の手法ではinsertする前にIDを事前に採番しているため、複数のクライアントが並列してIDを採番した時に、採番した時点ではIDの値の大小関係と時刻の前後関係は保証されますが、insertするタイミングでは前後関係が保証できません。ある程度(かなり近い時刻においては)前後関係のズレが発生することは許容しました。
また、この問題はRDBでもトランザクションを張っている場合にも起き得えます。
DB上のレコードの整合性がとれていればよい場合は、採番した時刻をテーブルにinsertすることで解決が可能そうです。
余談ですが、この記事を書いているときにRedisにTIMEというコマンドがあることを知りました。これを組み合わせると採番と同時に一貫性のある時刻を取得することもできそうです。
https://redis.io/commands/time/
はじめに試した実装
カウンタを初期化する処理は頻繁に実行される処理ではないため、ここではカウンタをインクリメントし返却する処理に注目します。
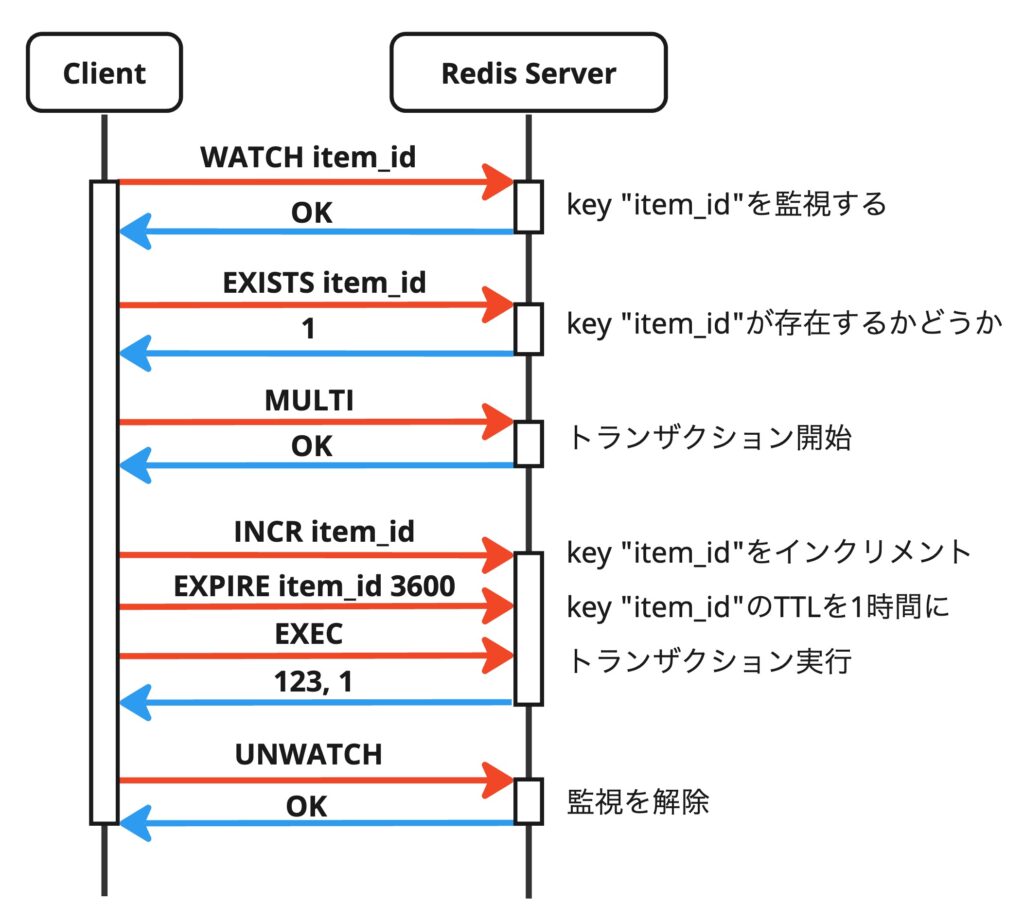
はじめに考えた実装はRedisのWATCHコマンドを利用し楽観的ロックを実装しています。
最初に更新対象のキーをWATCHコマンドで監視し、その後の操作をMULTIコマンドでトランザクションとして実行し、その間に他のクライアントが更新対象のキーを更新しなければ実行が成功します。
正常系のシーケンス図がこちらです。
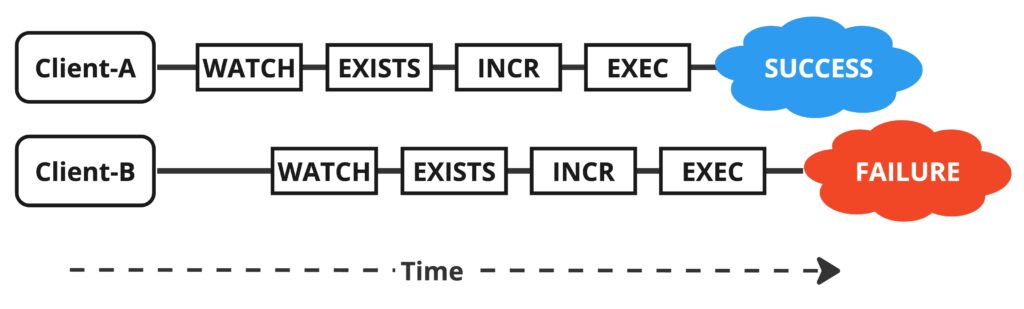
他のクライアントが更新した場合は実行が失敗し、競合が発生したことがわかります。失敗した場合は値はインクリメントされないので、数ms程度時間をあけてから再実行します。
最後にUNWATCHコマンドで監視対象をリセットしていますが、EXECコマンドを実行すると監視対象はリセットされるため、本来なら不要です。実環境だとコネクションプーリングによってRedisとのセッションが使いまわされる可能性があるため、不要なWATCHが残らないようにクライアントライブラリによってUNWATCHが実行されています。
ベンチマーク結果が以下です。CPUはAMD EPYC 7R13、32コアのVMの上でクライアント(Goのアプリ)とRedisを起動しました。実環境に近づけるため、クライアントとRedisの間には1msの通信のレイテンシが発生するようにしています。
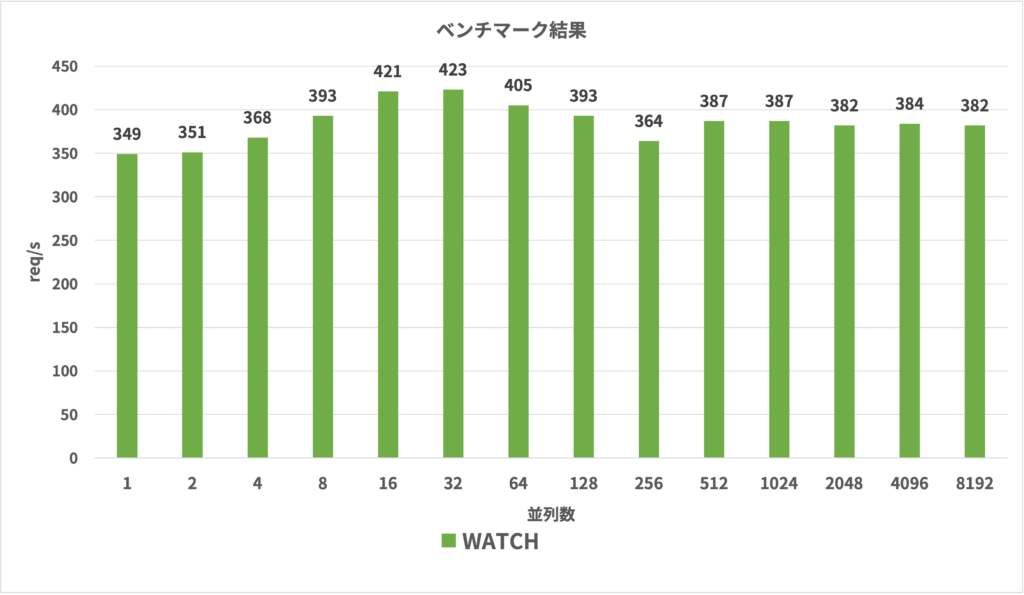
縦軸が秒間に採番できた数で、横軸が同時接続数を変えて試行した結果です。
クライアントの並列度が高まっても性能がほぼ一定になっていることがわかります。
楽観的ロックの失敗によるリトライが増加し、接続数に対してスケールしなくなっています。
サンプルの実装コードでは、当初リトライ回数の上限を100回にしていたのですが、それではベンチマークが完走できず、上限を1000回にしています。1000回リトライした場合は1秒以上のレイテンシが発生するため、許容はしずらいなという印象です。
また、一連の処理の最低のレイテンシが想定以上にあることも判明しました。正常系で5往復回通信が発生するため、1回の通信に1msのレイテンシがあると合計で5msのレイテンシが最低でも発生します。
速度改善した実装
これを解決するためにRedisのLua Scriptingを使いました。
Redisは全てのコマンドを直列に処理します。Lua Scriptingを利用して1つのコマンド内で複数のコマンドを実行しても、それらはアトミックな操作になるということです。
複数の処理を一度に実行することでレイテンシの問題と整合性の問題両方を解決しています。
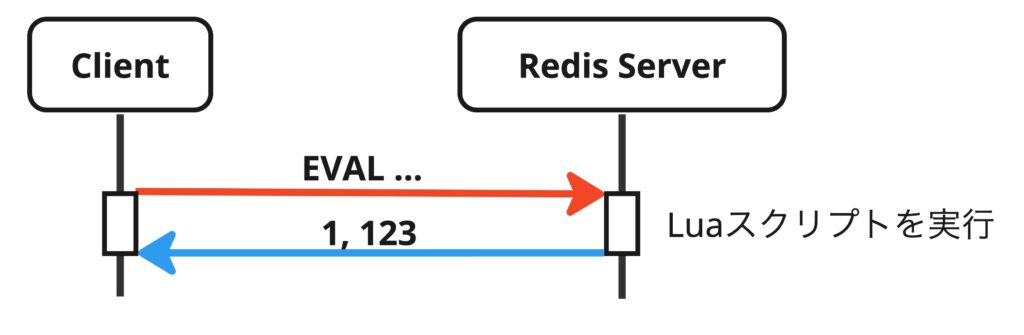
インクリメントした値をかえす
Luaスクリプトの実装です。
local e=redis.call("EXISTS", KEYS[1])
if e==0 then
return {0, 0}
end
local n=redis.call("INCR", KEYS[1])
redis.call("EXPIRE", KEYS[1], ARGV[1])
return {1, n}
前述の手法とやっていることはほぼ同じですが、1つのスクリプトの中でアトミックに実行される点が異なります。そのため楽観的ロックが不要になっています。
呼び出し方
LuaスクリプトはGoのコード中では文字列として扱い、EVALコマンドでスクリプトと操作対象のキー、スクリプトの引数をまとめて送信します。
Redisはスクリプト自体をキャッシュすることもできるのですが、スクリプトがキャッシュされているかどうかのチェックに通信の1往復分のレイテンシが増加してしまうのと、今回のスクリプト自体のサイズはそこまで大きくないことからあえてキャッシュさせずに毎回スクリプトを送信しています。
ベンチマーク結果はこちらです。
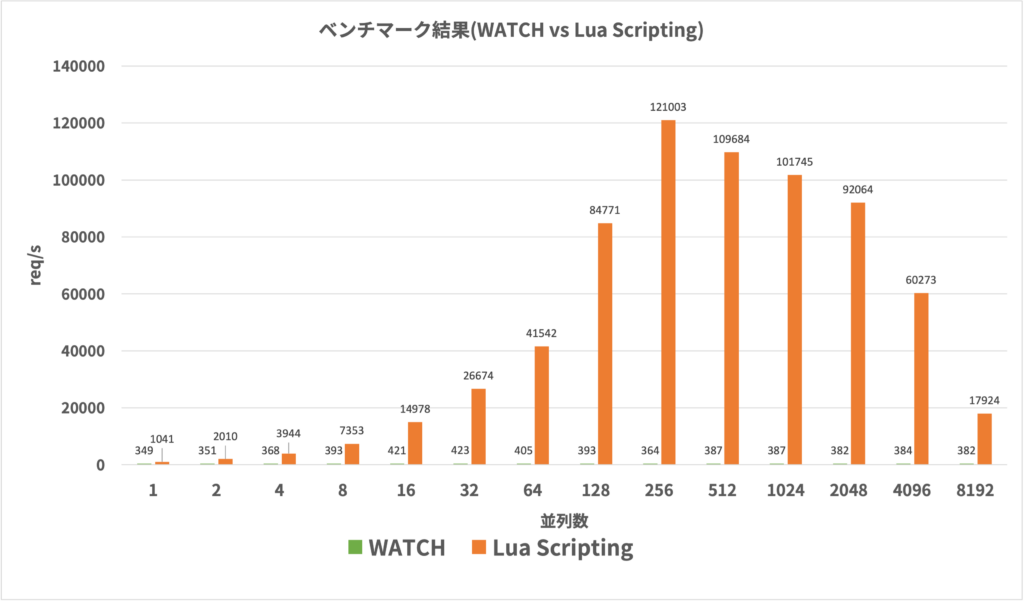
前述の手法に比べてかなりスケールしていることが見てとれます。256並列のケースでは秒間12万リクエストを超えていました。それ以降は性能が悪化しはじめています。
4096並列のケースあたりからコネクションのエラーも出はじめていたので、Redisのチューニングなどでもう少しピーク性能を伸ばすことはできるかもしれません。今回は秒間数千リクエスト程度に耐えることが目標だったため、これ以上の性能は追求しませんでした。
まとめ
RedisとLua Scriptingを利用して採番用のキャッシュを実装することで、KVSやKVSベースのNewSQL DBでauto incrementな採番を高速化する手法を紹介しました。
この機能のためだけにRedisを導入するケースにおいてはインフラコストの面でもったいないような気はしているので、コストパフォーマンスの観点ではもう少し追求したいと思っています。