
みなさんどうもこんにちは、AI事業本部の「極予測TD」というプロダクトで2023年2月から2ヶ月間、機械学習エンジニアとしてインターンシップ「CA Tech JOB」に参加させていただいた、高橋駿一と申します。本記事では、インターンシップで行った、MLOps基盤の開発についてご紹介します。
極予測TDとは
極予測TDとは、レスポンシブ検索広告(RSA)を自動生成する「広告テキスト自動生成AI」と、広告配信効果を事前に予測する「効果予測AI」を掛け合わせることで、効果的なRSAを制作するプロダクトです。
本インターンシップでは、効果予測AIのMLOpsに取り組みました。
背景
チームに参加した際、以下のような状況にありました。
- 複数の予測モデルが運用されているうち、一部、MLパイプラインが未実装のものがあった
- 上記モデルはリリース当初からモデルが更新されていなかったが、時間が経過したことでデータが蓄積した
上記を踏まえ、上記モデルにおいて継続的なモデルの改善を行うためのMLOps基盤を実装することを目標としました。
技術選定
インフラとして既にGCPを採用していたことを踏まえ、Vertex AIで統一したMLOps基盤を作成することで、メンテナンスを比較的容易にしました。なお、実装はVertex AI SDK for Pythonのaiplatformを用いました。
アーキテクチャ
作成したMLOps基盤のアーキテクチャは以下の画像の通りです。
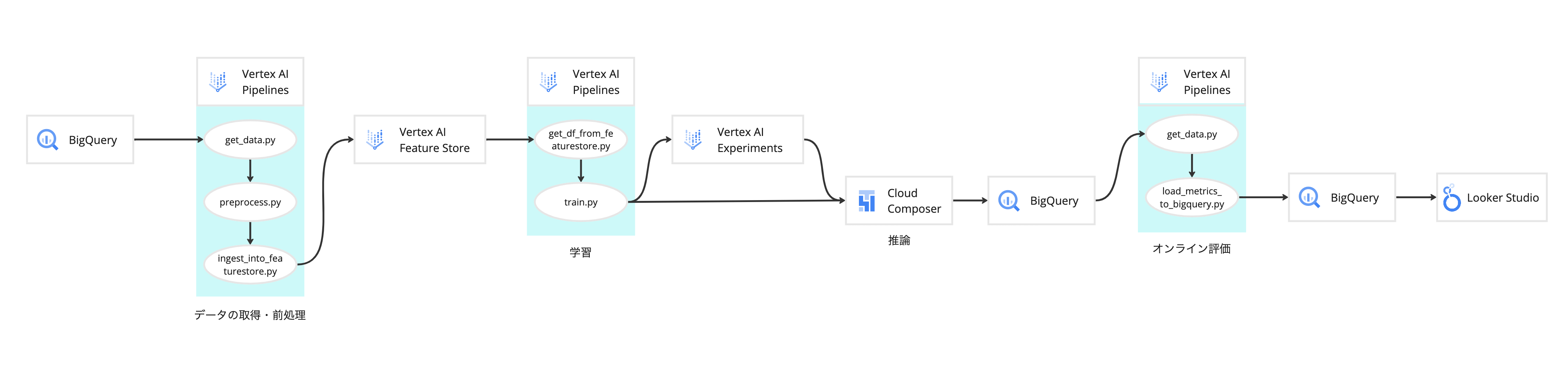
このMLOps基盤は以下3つのパイプラインからなります。
- 【特徴量管理】BigQueryからデータを取得し、前処理を行い、特徴量をVertex AI Feature Storeに登録するパイプライン
- 【実験管理】Feature Storeからデータを取得し、学習を行い、ハイパーパラメータや利用した特徴量、評価指標などをVertex AI Experimentsに登録するパイプライン
- 【オンライン性能モニタリング】オンラインの予測性能を計算し、Looker Studioでモニタリングできるようにするパイプライン
実際に運用する際には、【オンライン性能モニタリング】パイプラインにより運用中のモデルのオンライン性能をモニタリングし、再学習やモデル改善の必要性を考えます。再学習やモデル改善の際は、【特徴量管理】パイプラインでFeature Storeに登録した特徴量を使い、【実験管理】パイプラインで実験管理することで、より良いモデルを効率よく作成できるようになります。
パイプラインの作成にはVertex AI Pipelinesを活用しました。
特徴量管理(Vertex AI Featrure Store)
Vertex AI Feature Storeでは特徴量を管理することができます。
具体的には、特徴量をタイムスタンプを付与して保存することで、その時点の特徴量を取得することができます。
ここからはFeature Storeへの登録を行うingest_into_featurestore.pyについて説明します。
ユーティリティとして、Feature Storeへの登録を行うための一連の処理を管理するFeaturestoreManagerクラスを作成しました。
from datetime import datetime, timezone
import pandas as pd
from typing import Dict, List
from google.cloud import aiplatform
from google.api_core.exceptions import AlreadyExists
class FeaturestoreManager:
def __init__(
self,
project: str,
location: str,
featurestore_id: str,
entity_type_id: str,
feature_configs: Dict[str, Dict[str, str]]
) -> None:
self.project = project
self.location = location
self.featurestore_id = featurestore_id
self.entity_type_id = entity_type_id
self.feature_configs = feature_configs
# Feature Store 作成
def create_feature_store(
self,
online_store_fixed_node_count: int = 1,
sync: bool = True
) -> None:
aiplatform.init(project=self.project, location=self.location)
try:
aiplatform.Featurestore.create(
featurestore_id=self.featurestore_id,
online_store_fixed_node_count=online_store_fixed_node_count,
sync=sync
)
except AlreadyExists as err:
print(err)
print(f'Featurestore `{self.featurestore_id}` already exists'
f' in projects/{self.project}/locations/{self.location}')
# Entity type 作成
def _create_entity_type(self) -> None:
featurestore = aiplatform.Featurestore(
project=self.project,
location=self.location,
featurestore_name=self.featurestore_id
)
try:
featurestore.create_entity_type(self.entity_type_id)
except AlreadyExists as err:
print(err)
print(f'EntityType `{self.entity_type_id}` already exists'
f' for Featurestore `{self.featurestore_id}`')
# Feature 作成 (特徴量の名前や型を登録するだけで実際にデータが入るわけではない)
def create_features(self) -> None:
featurestore = aiplatform.Featurestore(
project=self.project,
location=self.location,
featurestore_name=self.featurestore_id
)
entity_type = featurestore.get_entity_type(self.entity_type_id)
# Entity Typeに既に登録されている特徴量を除く
exists_column_set = {feature.name for feature in entity_type.list_features()}
new_feature_configs = {
k: v
for k, v in self.feature_configs.items()
if k not in exists_column_set
}
if len(new_feature_configs) == 0:
print(f'already exists in Featurestore'
f' `{self.featurestore_id}` EntityType `{self.entity_type_id}`')
return
entity_type.batch_create_features(
feature_configs=new_feature_configs
)
# FeatureをFeature Storeに取り込み
def ingest_feature(
self,
df: pd.DataFrame,
columns: List[str],
entity_id_field: str = 'entity_id'
) -> None:
featurestore = aiplatform.Featurestore(
project=self.project,
location=self.location,
featurestore_name=self.featurestore_id
)
entity_type = featurestore.get_entity_type(self.entity_type_id)
# 標準時をnaiveで渡す必要あり
feature_time = datetime.now(timezone.utc).replace(tzinfo=None)
entity_type.ingest_from_df(
feature_ids=columns,
feature_time=feature_time,
df_source=df,
entity_id_field=entity_id_field
)流れとしては、Feature Storeの新規作成(create_feature_store)→エンティティタイプの新規作成(create_entity_type)→特徴量の新規作成(create_features)→特徴量のFeature Storeへの取り込み(ingest_feature)となっています。エンティタイプとは、複数の特徴量を1つのグループにまとめたものです。また、特徴量の具体的な値を取り込むには、create_featuresで行っているように、Feature IDとしてエンティティタイプに紐づく特徴量の名前と型を登録する必要があります。
# Feature ID 定義例
EXAMPLE_FEATURE_CONFIGS = [
'int_feature_example': {'value_type': 'INT64', description: 'int feature'},
'float_feature_example': {'value_type': 'DOUBLE', description: 'float feature'},
]今回は1日に1回の頻度で定期実行されるパイプラインで、前日に新たにBigQueryに格納されたデータに対して前処理を行いFeature Storeへの登録を行えるようにしました。
また新たな特徴量が追加されるケースに対応するために、手動実行で指定した期間にBigQueryに格納されたデータに対してパイプライン実行できる機能も実装しました。
実験管理(Vertex AI Experiments)
Vertex AI Experimentsで実験管理機能を実装しました。
モデルの改善を行う際、計算手法や特徴量、ハイパーパラメータなどを細かく変更し、それらの性能を比較しますが、実験実行の数が多くなればなるほど、その管理が難しくなります。Experimentsを用いることでこれらの管理を容易にしました。
パイプラインの実行1回で1つの実験条件での学習を行うようにし、パイプライン実行を容易にするために、.ipynbファイルで実験条件の設定と実験の実行を行えるようにしました。
FEATURE_COLUMNS = [
"int_feature_example",
"double_feature_example"
]
PIPELINE_PARAMETERS = {
'created_date_from': '2022-09-01',
'created_date_to': '2023-02-15',
'featurestore_time': '2023-02-15 16:00:00', # 日本時間で渡す
'hyperparameters': {
'train_weight': 0.6,
'valid_weight': 0.3,
'test_weight': 0.1,
'random_state': 42
},
'feature_columns': FEATURE_COLUMNS,
}
PIPELINE_PARAMETERSでFeature Storeから取ってくるデータに関する値や、ハイパーパラメータ、学習に利用する特徴量などを管理します。
def exec_experiment_run(
experiment_name: str,
run_name: str,
display_name: str=None
) -> None:
"""
arguments
- experiment_name: 実験名
- run_name: 実行名
- display_name: 表示名
※ 実験のディレクトリ構造は、experiment_nameというフォルダの中でrun_nameという個別の実験が入っている構造。
"""
aiplatform.init(experiment=experiment_name, project=PROJECT, location=LOCATION)
aiplatform.start_run(run=run_name)
pipeline = aiplatform.PipelineJob(
display_name=display_name,
template_path=f'./{PIPELINE_NAME}.json',
parameter_values={
'experiment_name': experiment_name,
'run_name': run_name,
**PIPELINE_PARAMETERS
},
enable_caching=ENABLE_CACHING,
project=PROJECT,
location=LOCATION
)
pipeline.submit()
pipeline.wait()
aiplatform.log(pipeline_job=pipeline)
experiment_run = aiplatform.ExperimentRun(
run_name=run_name,
experiment=experiment_name,
project=PROJECT,
location=LOCATION
)
experiment_run.end_run()
Vertex AI Experimentsでは実験名experiment_nameと実行名run_nameを指定して実験実行を行います。1つのexperiment_nameに対して複数のrun_nameを指定する対応になっています。
aiplatform.initで実験を初期化し、aiplatform.start_runで実験実行を開始します。そして、事前にコンパイルした学習用のパイプラインの定義を書いた.jsonファイルのパスtemplate_pathを指定し、このパイプラインの中で、実験実行に紐づくハイパーパラメータなどの登録を行います。最後にパイプライン中で行った実験実行を取得し、実験実行をend_runで終了します。なお、ハイパーパラメータなどの登録は、aiplatforomのExperimentRunクラスが持つlog_paramsやlog_metricsを用いて行っています。
このファイルを.ipynbにすることで、PIPELINE_PARAMETERSの値を書き換えてexec_experiment_runを実行するというプロセスを容易に繰り返すことができ、高速で実験を回すことができるようになりました。
オンライン性能モニタリング(Looker Studio)
オンライン性能をLooker Studioでモニタリングできるようにし、運用中のモデルの性能を確認し、再学習やモデルの変更を行うかを意思決定できるようにしました。
Looker Studioでは、BigQueryに格納されているデータを定期的に参照し、それを可視化することが可能です。これにより、BigQueryの正解データと推論結果を格納したテーブルを参照→評価指標を計算し、その結果を評価指標格納用のテーブルに格納→Looker Studioで可視化というフローでモニタリング機能を実現できました。
パイプライン(Vertex AI Pipelines)
3つのパイプラインはいずれもKubeflowを使って構築し、Vertex AI Pipelinesで実行するという方法で実現しました。
Kubeflowを使ったパイプライン構築の流れは、先ずパイプライン内で実行するコンポーネントを公式のディレクトリ構成に基づいて作成し、コンポーネントの組み合わせや変数の埋め込みなどを行うことでパイプラインの具体的な処理フローを定義する.jsonファイルをコンパイルするという流れになっています。作成された.jsonファイルはVertex AI Pipelinesで実行することができます。
ここでは、実験管理用のパイプラインでkubeflowを利用する流れを説明します。このパイプラインは、Feature Storeからデータを取得するget_df_from_featurestoreと、学習を行うtrainというコンポーネントからなります。
name: get_df_from_featurestore
inputs:
- {name: created_date_from, type: String}
- {name: created_date_to, type: String}
- {name: featurestore_time, type: String}
outputs:
- {name: get_df_from_featurestore_output_path, type: Dataset}
implementation:
container:
image: ${image_name}
args: [
python,
-m,
kubeflow.training.get_df_from_featurestore.src.get_df_from_featurestore,
--created_date_from,
{inputValue: created_date_from},
--created_date_to,
{inputValue: created_date_to},
--featurestore_time,
{inputValue: featurestore_time},
--get_df_from_featurestore_output_path,
{outputUri: get_df_from_featurestore_output_path}
]
name: train
inputs:
- {name: get_df_from_featurestore_output_path, type: Dataset}
- {name: hyperparameters, type: JsonObject}
- {name: feature_columns, type: JsonArray}
- {name: experiment_name, type: String}
- {name: run_name, type: String}
outputs:
- {name: train_output_path, type: Model}
implementation:
container:
image: ${image_name}
args: [
python,
-m,
kubeflow.training.train.v1.src.train,
--get_df_from_featurestore_output_path,
{inputUri: get_df_from_featurestore_output_path},
--hyperparameters,
{inputValue: hyperparameters},
--feature_columns,
{inputValue: feature_columns},
--experiment_name,
{inputValue: experiment_name},
--run_name,
{inputValue: run_name},
--train_output_path,
{outputUri: train_output_path},
]
先ずはそれぞれのコンポーネントごとに入力と出力、実行の詳細に関する定義を書いたテンプレートの.yamlファイルを用意します。
from pathlib import Path
from string import Template
from typing import Callable
import kfp
from kfp.v2 import dsl
from kfp.v2 import compiler
from kubeflow.training.config import PROJECT, PIPELINE_NAME, COMPILED_PIPELINE_PATH, CONTAINER_IMAGE
def get_component_from_yaml(component_name) -> str:
component_image = CONTAINER_IMAGE
yaml_path = Path(f"kubeflow/training/{component_name}/{component_name}.yaml")
yaml_text_template = Template(yaml_path.read_text())
yaml_text = yaml_text_template.substitute(image_name=component_image)
return yaml_text
def _op(component_name: str) -> Callable[..., dsl.ContainerOp]:
component_spec = get_component_from_yaml(component_name)
return kfp.components.load_component_from_text(component_spec)
@dsl.pipeline(
pipeline_root=f"gs://{PROJECT}_vertex_ai/traininig/pipeline_output",
name=PIPELINE_NAME,
)
def pipeline(
created_date_from: str,
created_date_to: str,
featurestore_time: str,
feature_columns: list,
hyperparameters: dict,
experiment_name: str,
run_name: str,
) -> None:
get_df_from_featurestore = _op("get_df_from_featurestore")(
created_date_from,
created_date_to,
featurestore_time
)
train = _op("train")(
get_df_from_featurestore.outputs["get_df_from_featurestore_output_path"],
hyperparameters,
feature_columns,
experiment_name,
run_name
)
train.after(get_df_from_featurestore)
compiler.Compiler().compile(
pipeline_func=pipeline,
package_path=COMPILED_PIPELINE_PATH
)
そして、.yamlで作成したテンプレートに値を埋め込み、コンポーネントの順序関係を指定することでパイプラインを定義し、その定義書を.jsonファイルとして保存します。これでKubeflowパイプラインが完成しました。
最後にこの.jsonファイルを指定して、実験管理(Vertex AI Experiments)の章で説明したようにパイプラインをVertex AI Pipelinesで実行します。
その他にやったこと
ここまで説明した機能で、運用中のモデルのオンライン性能をモニタリングし、再学習やモデル改善の必要性を考え、それらが必要であれば、Feature Storeに登録されている特徴量を使い、Experimentsで実験管理することで、より良いモデルを効率よく作成できるようになりました。既存実装で、単一のモデルをバッチサービングするためのワークフローがCloud Composer(Airflow)で実装されていたので、モデルの改善を継続的に行うための一連の処理が一先ず完成しました。
ただ、サービングできるモデルが1つのみだと、ABテストを行うことができません。そこで、作成したモデルをABテストで比較するために、サービング部分の既存実装の編集を行いました。具体的には、Experimentsで作成した実験実行を複数指定し、それぞれのモデルに推論させるデータ量の比を定義するだけで複数モデルをサービングできるようにしました。さらに、オンライン性能モニタリングでは、複数のモデルそれぞれの性能を可視化できるようにしました。
まとめ
今回は、極予測TDの効果予測AIのMLOps基盤の作成をVertex AIを活用し実装しました。具体的には、特徴量管理、実験管理、オンライン性能モニタリングを実現するパイプラインを作成し、さらに、ABテストを行うために、複数モデルのサービングもできるようにしました。
インターン期間中は、トレーナーの西村さんやメンターの藤田さんを含め、多くの方に質問や相談に乗っていただき、2ヶ月という期間の中で目標としていたところまで完成させることができました。成長の機会をくださった極予測TDチームの皆さん、本当にありがとうございました。