

サイバーエージェントグループには、様々なSRE組織があり、日々サービスの信頼性向上に取り組んでいます。 6月27日〜28日にかけて開催した「CyberAgent Developer Conference 2023」では、当社のDeveloper Experts(SRE領域)を務める柘植が、サイバーエージェントグループのSRE組織やSREsの活動についてもご紹介しました。
柘植 翔太
2014年新卒入社。インフラエンジニア、SREとして、AMEBA、AWA、社内基盤など50以上のメディアサービス・システムへのSRE推進、リスク改善、サービス立ち上げを経験。現在は、横断SRE組織のマネージャーとして、SREのプラクティス開発やEnablement、人材育成へ注力している。
サービスリライアビティグループというメディア事業横断のSRE組織のマネージャーをしている柘植と申します。本日はデータで見るサイバーエージェントグループのSREと横断的なSRE推進の取り組みというテーマでお話しさせていただきます。本題に入る前に、本セッションで話すことと表記の注意についてです。
本セッションでは大きく分けて以下3つのことをお話しさせていただきます。

また本セッションでの表記については下記の通りとします。

少し前置きが長くなりましたが、ここからは本題の「データで見るサイバーエージェントグループのSREと横断的なSRE推進の取り組みについて」お話しさせていただければと思います。本セッションのアジェンダは下記の通りです。

サイバーエージェントグループのSRE組織俯瞰
サイバーエージェントグループでは幅広い事業を展開しており、大きく分けるとメディア事業、インターネット広告事業、ゲーム事業の3つとなります。各事業で提供しているサービスに対して求められる品質は年々高くなっていると感じています。そして品質の担保や向上は事業を継続する上で必要不可欠なものであり、品質担保ができていないというのはリスク管理が行えていない状況だといえます。
現在サイバーエージェントグループでは40名以上のSREsが活躍しており、サービスの信頼性向上に日々向き合っています。ここからはサイバーエージェントグループで活躍しているSREsの組織や実装パターン、組織俯瞰、そしてSREsが活用している技術の傾向についてお話しします。
まずはSREの組織や実装パターンについてお話しします。現在サイバーエージェントグループで活躍しているSRE組織は3つの組織パターンに分類できます。

1つ目は単一プロダクト専任のSRE組織で、SRE組織とプロダクトは1対1の関係になります。 2つ目は子会社専任のSRE組織で、SRE組織とプロダクトは1対Nの関係となります。 3つ目は事業部横断のSRE組織で、子会社専任のSRE組織と同じで、SRE組織とプロダクトは1対Nの関係となりますが、複数の子会社をまたいでのSRE推進も行います。
この組織パターンはサイバーエージェントグループのように子会社やプロダクトが多い組織であればあるほどメリットを感じることができます。ちなみにSRGはこの組織パターンに該当します。
次にSREの実装パターンについてお話しします。

各SRE組織での取り組みは向き合っている課題や事業が異なるため分類することは難しいのですが、Product SRE、Embedded SRE、Platform SRE、SRE Center of Practice、Movable Embedded SREの5つの実装パターンに分類できます。Movable Embedded SREの実装パターンは案件ごとに必要なスキルセットを持っているSREsでチーム編成を行い、完遂とともにチームを解散させるためEmbedded SREよりも流動的かつ組織をまたいだ活動に適しています。案件の多くが半年以内に完遂するものであり、案件例としては負荷対策などが挙げられます。
次はSREの組織俯瞰についてお話しします。
先ほどお話ししたSREの組織と実装パターンを俯瞰してみるとこちらのスライドの通りになります。
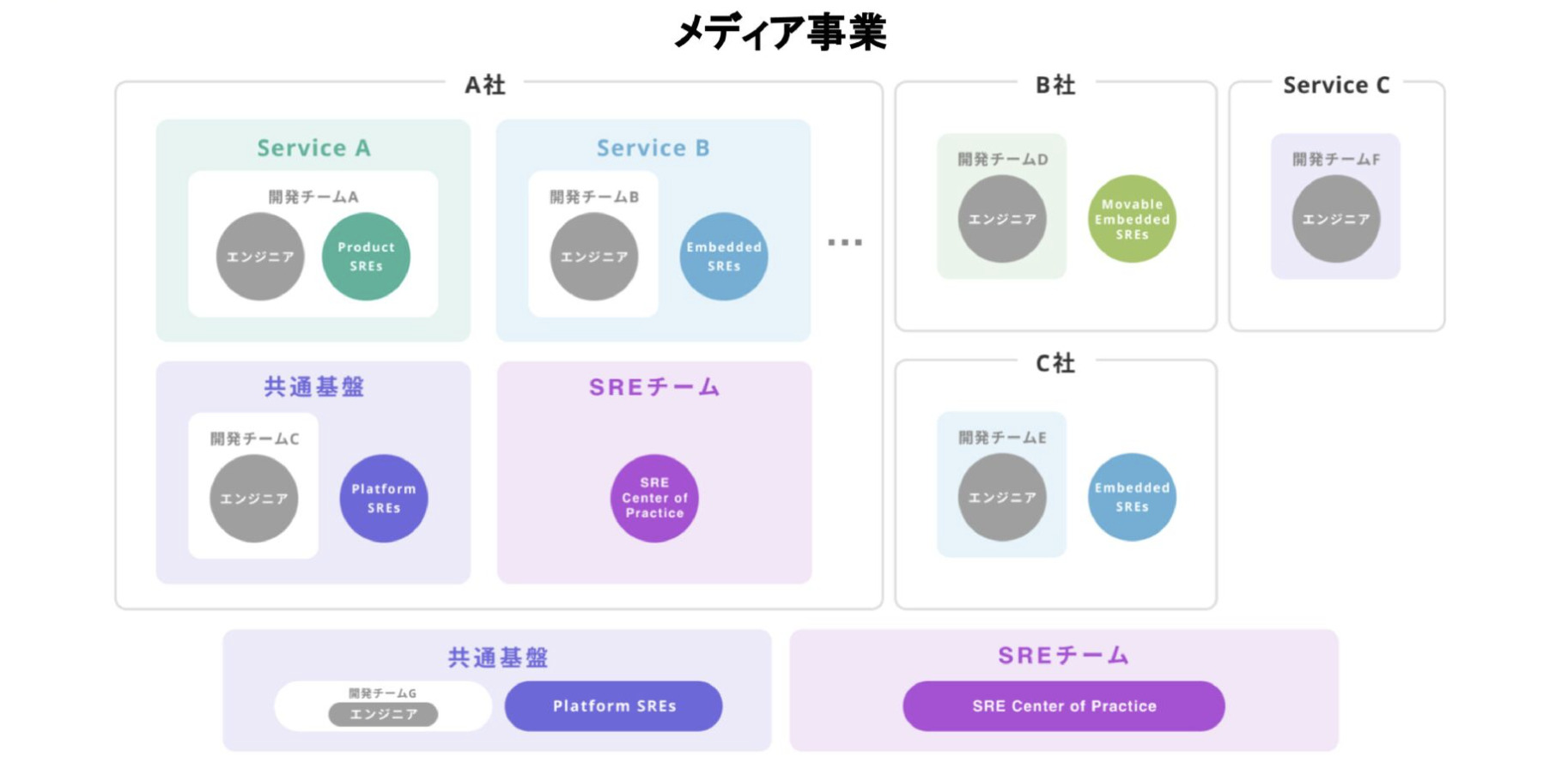
ここからはサイバーエージェントグループのSRE組織とSREsの傾向についてデータを基にご紹介します。サイバーエージェントグループで活躍するSREsの入社形態としては、新卒と中途の割合がおよそ半々で、社員の6割以上が、勤続年数が5年以上です。
SREの事業部比率としては、現在はメディア事業が多い傾向にありますが、近年ではゲーム事業やAI/DX事業での需要も増えてきています。
チーム立ち上げ年数は、7割以上のSRE組織が4年以上となっており、各SRE組織内でのプラクティスも蓄積されてきています。
SRE実装パターンでは、プロダクトSREとイネーブリングSREが多い傾向があります。特にゲーム事業では、プロダクトSREが多い傾向が見られました。
また、全ての事業部横断SRE組織がSREセンターオブプラクティスを実装していました。これはSRE組織としてSRE推進するプロダクト数が多ければ多いほど、SREセンターオブプラクティスのメリットを感じることができるからだと思います。
SREsのファーストキャリアとしては、8割以上がバックエンドエンジニアやインフラエンジニアでしたが、近年ではWebフロントエンジニアや、iOSエンジニアなどからSREsになる人も増えてきています。またSRE職の新卒採用も強化しているので増加傾向にあります。
次はサイバーエージェントグループのSREsが活用している技術傾向について、データを基にお話しさせていただきます。
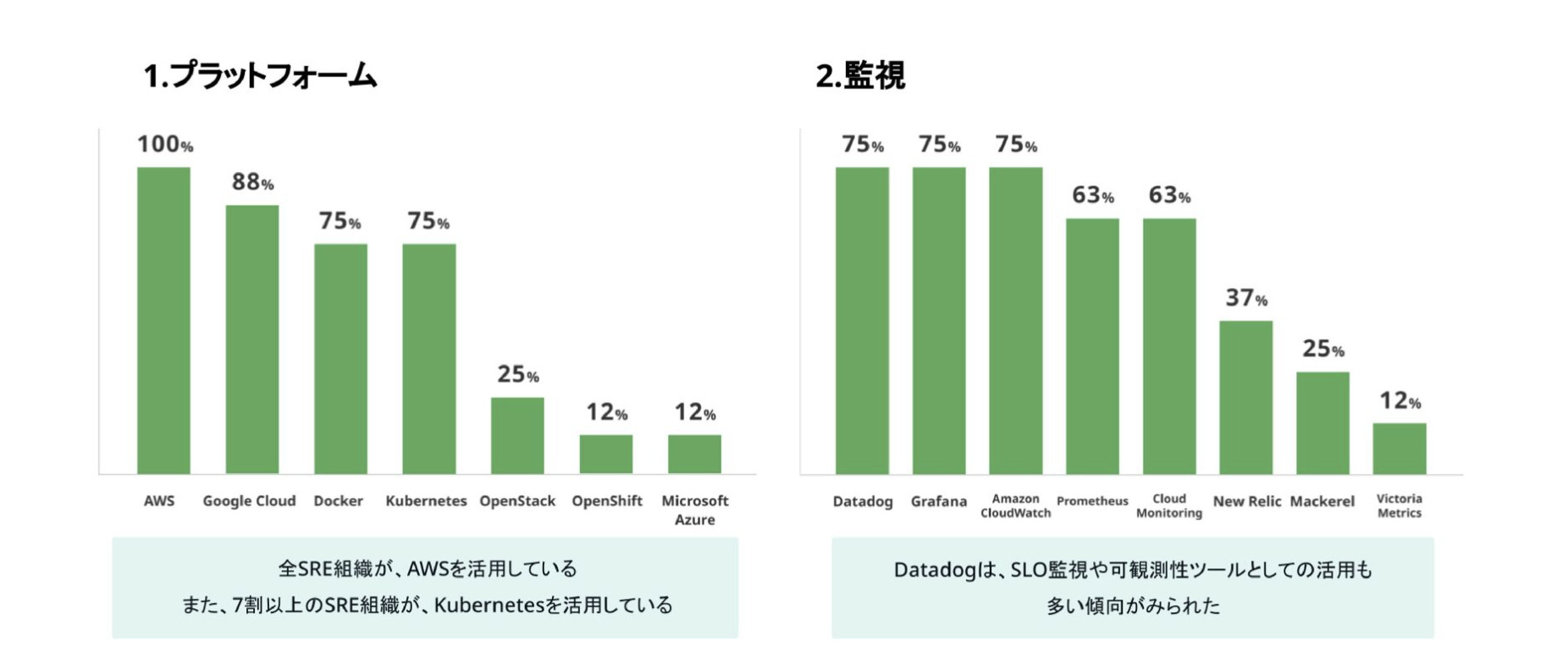
今回調査協力を得られたSRE組織の7割以上で、Kubernetesを活用していることが分かりました。また監視としてはDatadogの活用が多く、SLO監視や可観測性ツールとしての活用も多い傾向が見られました。

On-Callは機能が豊富なPagerDutyの活用が多い傾向にあり、一部のSRE組織ではインシデント管理ツールとしても活用されています。CI/CDでは、長期運用しているサービスで、Jenkinsの活用が多い傾向にありましたが、近年ではArgoCDや先日CNCF Sandbox Projectに採択された、弊社OSSであるPipeCDの活用も増加傾向にあります。このセッションを視聴している方々も、ぜひPipeCDの活用を検討していただけると幸いです。
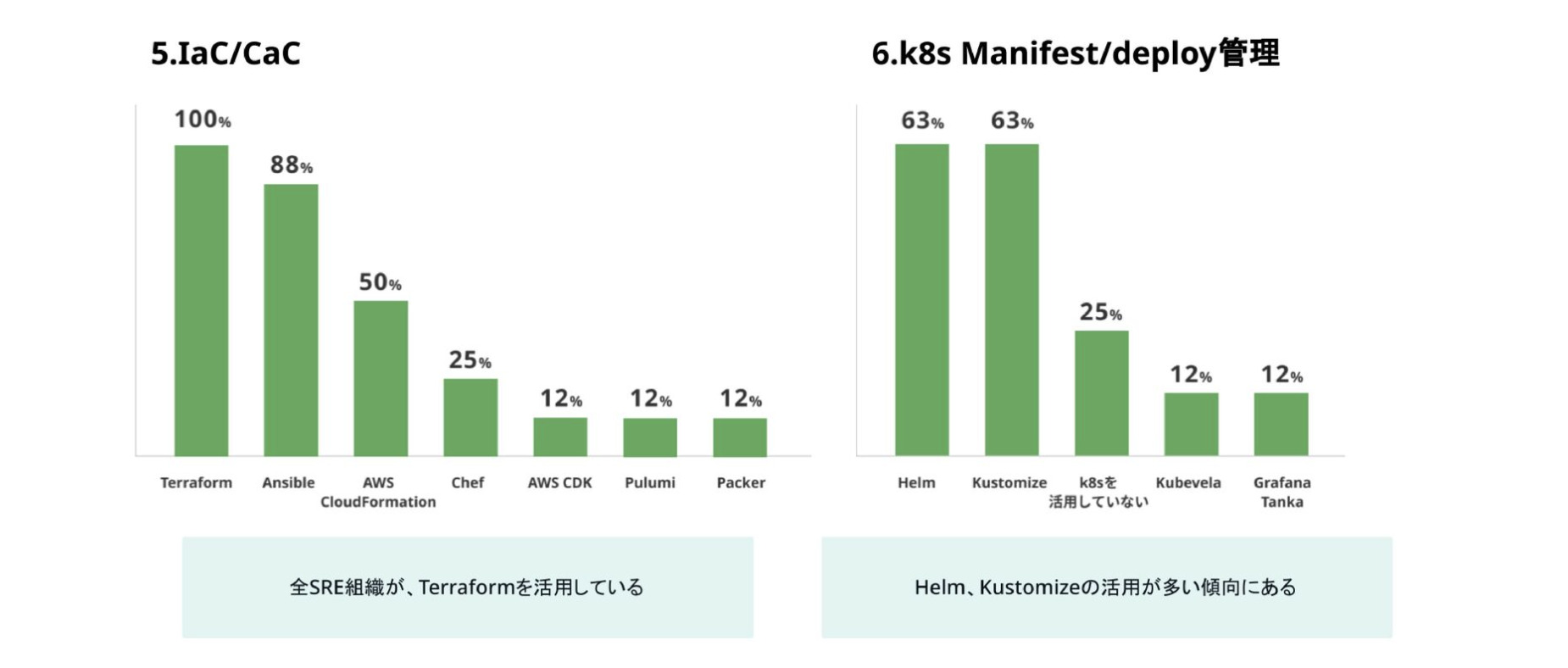
IaC、CaCでは複数プラットフォームを活用している組織が多いからか、全SRE組織がTerraformを活用していました。またKubernetesのマニフェスト管理は、Helm、Kustomizeの活用が多い傾向にありました。
データベースは、全SRE組織がユーザ体験の向上やコスト削減などの用途で、Redisを活用していました。またMySQLとMongoDBの活用が多い傾向にあり、特にメディア事業ではMongoDBの活用が多い傾向にありました。
CDNでは、全SRE組織がAmazon CloudFrontを活用していました。そして最後になりますが、SREsが業務で使っている開発言語としては、シェルスクリプト、Go、Pythonが多い傾向にあり、近年では特にGoの活用が増加傾向にあります。
本セッションでは時間が足りないので紹介できないのですが、SREsが負荷試験、インシデント管理、ポストモーテムなどで活用しているソリューションの傾向や、各SRE組織の情報や取り組みなどについてまとめたものをSRE Technology Mapとして公開しているので、ぜひご覧ください。
事業部横断SREsとしての組織戦略
ここからは事業部横断SREsであるSRGの組織としての成り立ちや、組織フェーズごとの変化について触れながら、横断組織としてプロダクトチームへSREを推進するために行ってきた、組織開発や戦略についてお話しします。
現在SRGはAmebaやAWAなどのメディアサービスや、社内基盤サービスを中心に、大小を合わせて100弱のプロダクトへのSRE推進や、リスク改善、サービス立ち上げなどのサポートを行っています。過去にはABEMAやタップル、新R25なども担当しており、多い時では200弱のプロダクトのサポートを行っていました。
それでは組織としての成り立ちについてお話ししていきます。

組織の成り立ちについてですが、大きく分けると3つのフェーズに分けることができます。まずはSRGの前身となるインフラ組織についてお話しします。今のSRGになる前はメディア事業のインフラ組織をしていました。役割としてもデータセンターへ行ってサーバーのラッキングや OSS、ミドルウェアのセットアップやチューニングなどを行っており、オンプレ中心の昔ながらのインフラエンジニアという感じでした。
また組織としては横断組織の時代もあれば、サービス所属の時代もありました。この時代の組織課題としては、インフラエンジニアしかインフラ領域を把握していないことが多く、普段の運用やアラートノイズに疲弊していました。
そして、個々のサービス知識やスキルセットへの依存が大きく、担当者以外は運用できない状態のものもあったりしました。スキルセットへの依存が大きいのは、特定プロダクトでしか使っていない技術が多かったのもあったと思います。
そういった課題や社内でのクラウド活用が増加傾向にあったのもあり、クラウド活用中心のサービスインフラエンジニアへシフトしていきました。そして今後のクラウド活用の普及を踏まえて、サービスインフラエンジニアとしてこれまで担当していたインフラ領域から、信頼性を軸に事業貢献できる組織に変化することを考え始め、SREを目指そうと2015年末に、今のサービスリライアビティグループという組織名に変更しました。
ここからはメディア事業横断のSRE組織へシフトした後のお話になります。
SRE組織へシフトした当初は、個々のサービス知識やスキルセットへの依存が大きかったこともあり担当チーム制をとっていました。
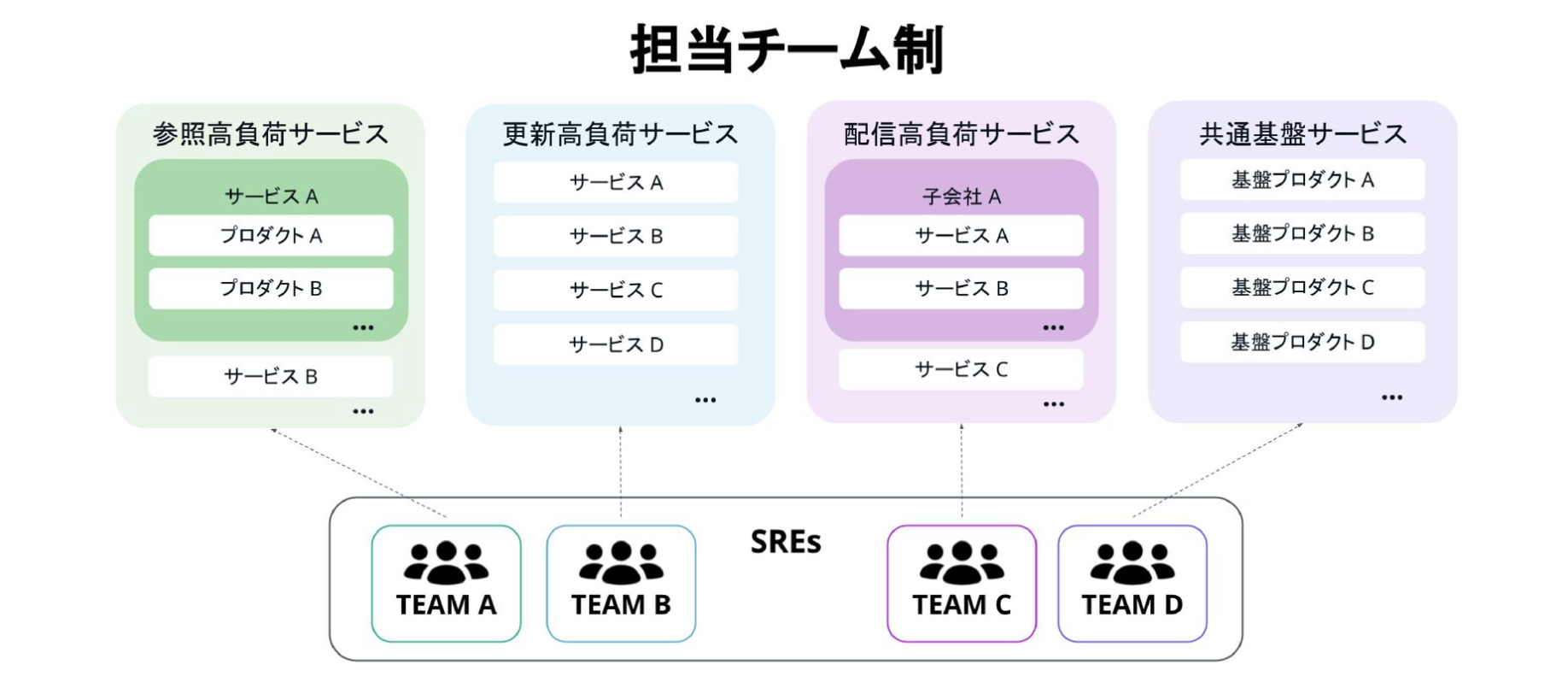
上記のように、負荷パターンやドメインなどのサービス特性ごとにチーム編成をしており、参照高負荷サービスのチームではAmebaなどを担当していました。また更新高負荷サービスではゲーム系のメディアサービスを担当しており、MySQLやMongoDBに強いエンジニアが多い傾向がありました。ちなみに私は更新高負荷サービスのチームに所属していました。
そして配信高負荷サービスのチームでは、AWAやABEMAなどのサービスを担当していました。SRE組織へシフトするために、Google SREsとのディスカッションやSREに関する書籍の臨読会などを実施しソフトウェアエンジニアリング、システムエンジニアリング、オーバーヘッド、トイルの4つの分類を中心に学んでいき、学んだことをもとにトイル撲滅運動やRunbookの整備、ポストモーテム文化の醸成、障害対応フローの再設計などの取り組みを進めていきました。
担当チーム制のSRE組織の役割としては、サービスインフラエンジニアの時と同様に、インフラ領域のサポートをしながら学んだSREプラクティスをプロダクトへ実行していました。
直接的なサービスの信頼性向上という意味では、サービスインフラエンジニアの時と大きな変化はありませんでした。少なくともポストモーテムや障害対応フローなど改善したものはあったのですが、サービス特性ごとの担当チーム制だったこともあり、退職や組織変更による影響が大きく、組織としてスケールしにくいという課題がありました。
またチームをまたいでの活動が少なかったこともあり、チームごとでの活動が中心となり 横断組織としてのシナジーが出しにくいという課題もありました。
そういった課題を踏まえて、これまでの担当チーム制からプロジェクトチーム制にシフトしていきました。
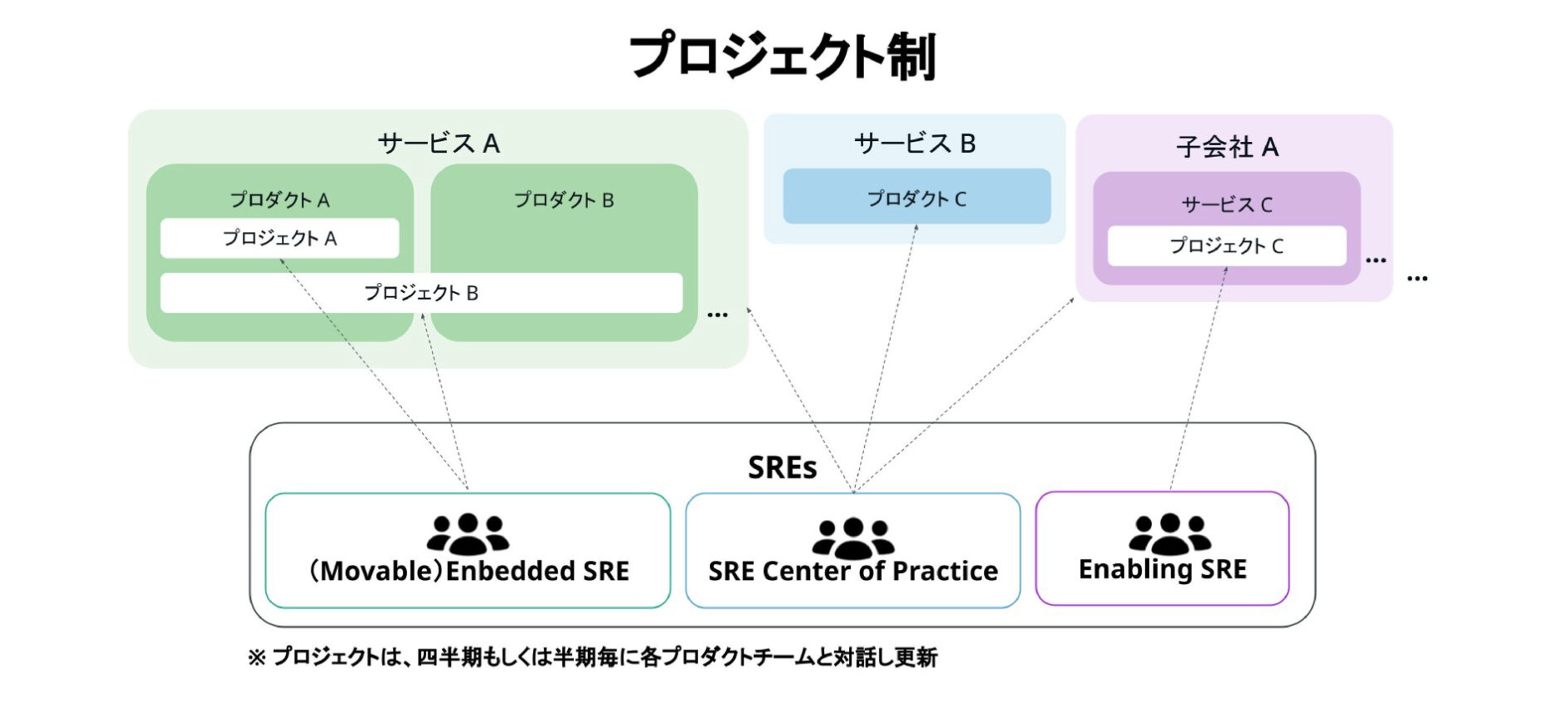
プロジェクトは四半期もしくは半期ごとに、各プロダクトチームと対話し更新していきます。またプロジェクト制にシフトするにあたり、よりSREとしての価値を提供していくために専門性が低い既存アーキテクチャへの新規構築などの、運用保守やOn-Call対応などは、なるべく各プロダクトチームで完結できるように、技術責任者と合意形成を取った上でエスカレーションしていきました。
そしてプロダクトチームが自律的にSRE改善が行える体制づくりへシフトするために、改めて組織としてのミッション・ビジョン・バリューの言語化や解決したい課題などを整理しつつ自分たちの組織に合ったSREを再定義していきました。
また、組織としてのスケールを考えてSRGのSREsはプロダクトチームへSREをインストールすることが役割であると再定義しました。そしてSREsとして提供する価値を明確にし社内向けのSRE as a ServiceをSRGは提供しています。
社内向けのSRE as a Serviceとして大きく分けるとプロジェクトニーズへのコミットメントとSREサポートの2つを提供しています。

今回は時間の都合で各取り組みについては話しませんが、また別の機会にご紹介したいと思います。プロジェクト制やSREsとして提供する価値を明確化することにより、担当チーム制と比べてSREを推進することができるようになりました。
ですが横断組織としてSREを推進するためには、まだ課題に感じることがありました。SRE推進はしやすくなりましたが、各プロダクトの信頼性が適切であるのか、何から始めればよいのか、優先順位が決めにくいという課題がありました。
また物理的に全プロダクトへEmbeddedすることは難しいので、事業部全体を俯瞰しデータ化することで、事業としての力点を見極められないかと考えました。
そこでサービス信頼性の断層を参考にしつつ各断層に対してに理想状態を把握した上で、アクションが決められるような横断アプローチを開発しました。
横断アプローチによるSRE推進
ここからは横断的にSRE推進するために開発した。SRE成熟度評価を紹介するとともに、活用によって得られたことや、今後の展望についてお話しさせていただきます。
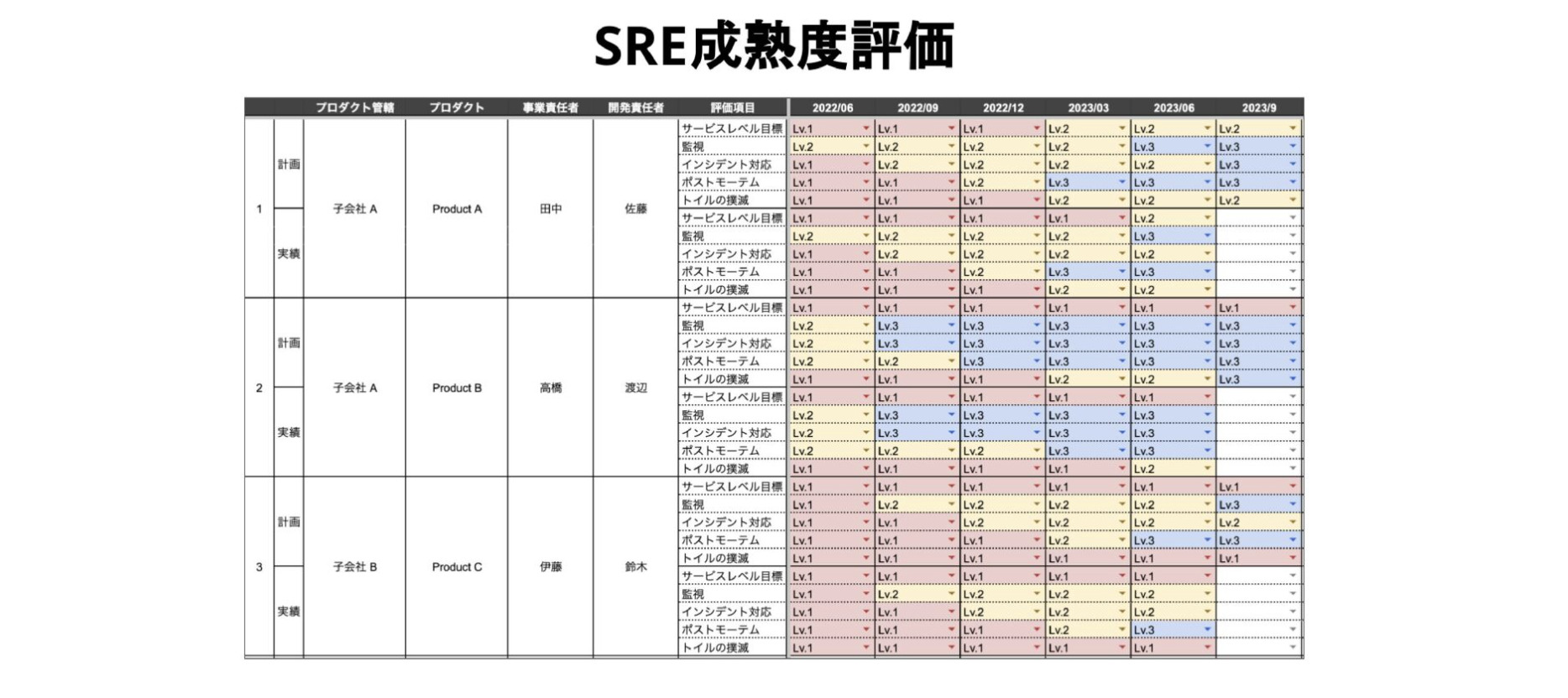
上記は実際にSRE成熟度評価で活用している、Google Sheetsのサンプル画像になります。各プロダクトの評価項目ごとにSRE成熟度の計画と実績を管理しています。SRE成熟度評価は能力成熟度モデル統合をベースに作成しています。また、サービス信頼性の断層などを参考に、SREに必要な項目をリスト化し評価しやすくするために極力シンプルにしています。

項目としてはサービスレベル目標、監視、インシデント対応、ポストモーテム、トイルの撲滅の5つとなっています。成熟度としては3段階で評価しており、プロセスが定義されておらず場当たり的な状態をLv.1と定義しています。
Lv.1はプロダクトとしてリスクが高い状態なので、該当する場合は優先的に改善するようにしています。次にチーム内でのプロセスが定義、共有されている状態をLv.2と定義しています。
この状態はプロダクトとしてはリスク管理ができている状態だといえます。そして最後にベストプラクティスに基づいたプロセスで運用できている状態を、Lv.3と定義しています。
この状態は他プロダクトとしても参考にしたい状態だといえます。SRE成熟度評価の流れとしては 準備、評価と計画、改善実施の3ステップに分けられます。
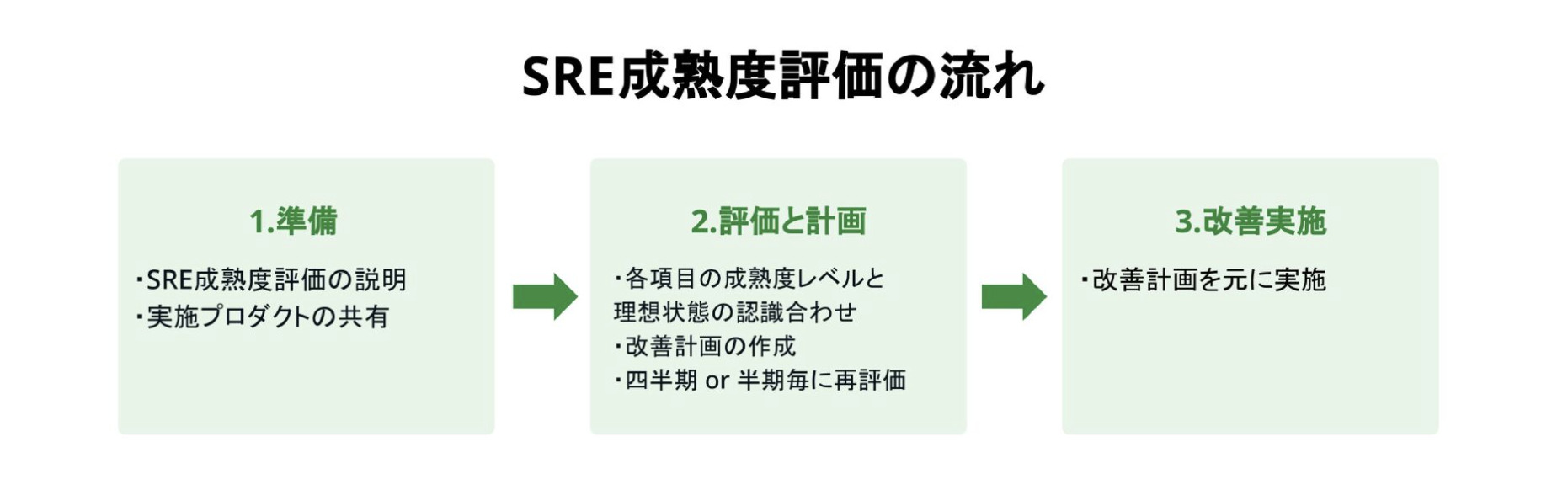
まず初めの準備では、SRE成熟度評価の説明と実施するプロダクトについて、プロダクトチームから共有してもらいます。
SRE成熟度評価の概要については、先ほど説明したので省きますが、Lv.3 ガイドラインについて少し説明させていただきます。サービスレベル目標、監視、インシデント対応、ポストモーテム、トイルの撲滅の項目ごとに、ベストプラクティスを考える上での観点を質問にしたものを、Lv.3 ガイドラインとして用意しています。
なるべく汎用化するためにあえて抽象的な質問にしています。またSRE成熟度評価をしていく過程で、プロダクトチームへのEnablementをしていきたいからでもあります。そしてここが重要なのですが、各プロダクトにおいての理想状態は違うので、ガイドラインすべてを満たす必要があるわけではありません。
Lv.3の評価基準が違ったら、データとして活用できないのではないかと思う人がいるかもしれないですが、事業部としてはLv.1を把握し、Lv.2へ改善することができれば、最低限のリスク最小化とEnablementには活用できるので問題ないと考えています。現時点ではLv.3を計測することによって、他プロダクトでも参考になり得るプラクティス発掘やナレッジの展開に貢献できています。
次は評価と計画について説明します。評価と計画では各項目の成熟度レベルと理想状態の認識合わせを行い改善計画を作成します。評価は四半期もしくは半期ごとに行います。SRE成熟度評価の導入初期は、四半期ごとの実施をお勧めしますが、改善が進み、Lv.1がない状態であれば、半期ごとに評価するので問題ないと思っています。
ここからは各項目のLv.3ガイドラインの質問を一部抜粋しながら紹介していきます。まずはじめにサービスレベル目標のLv.3ガイドラインについて説明します。サービスレベル目標のLv.3ガイドラインとしては、定義 計測 振り返りの三つの分類の観点で成熟度を評価します。SLO導入に関しては正直難しいと思う人が多いかもしれません。
なぜ難しいと思うかというと、多くの人がはじめから完璧なSLOを導入しようとするからだと私は思います。なのでまずは小さく始めてみることが重要だと思います。そして定期的にSLOについて振り返りを実施し、ブラッシュアップしていくのをお勧めします。
またユーザーが近い位置から計測した方が、SLO悪化とサービス影響やユーザーの満足度と関連付けしやすいので、SRE成熟度評価を実施したプロダクトの中には、iOSやWebフロントなどからSLO導入を始めているところも最近では増えていっています。
次は監視のLv.3ガイドラインについて説明します。監視のLv.3ガイドラインとしては 要件定義、メトリックス、アラート、コストの4つの分類の観点で成熟度を評価します。監視の改善について難しいのは、メトリックスの取得品では保存期間、アラート、ダッシュボードなどが適切に設定されているかだと思います。
メトリックスの取得頻度や保存期間については、プロダクトの要件によっても違うとは思いますが 監視にかかっているコストを可視化することによって、適切かどうかを判断する基準の一つにすることはできると思います。
アラートについては通知されたアラートを、GoogleSheetsなどにまとめ定期的に見直しすることでノイジーアラートを削減することができます。またその際にアラートメッセージに情報が足りているかの確認も、一緒に行うことをおすすめしています。アラートメッセージを整理することで、障害の推定検出時間を短縮することができるからです。最後にダッシュボードは用途や要件を整理することで、ダッシュボードの過不足が確認できるようになります。
次はインシデント対応のLv.3ガイドラインについて説明します。インシデント対応のLv.3ガイドラインとしては、インシデントレベルと役割、On-Call、検知と取り合わせ、情報共有、 事後対応の5つの分類の観点で成熟度を評価しています。
インシデント対応の導入・改善する上で、まず初めにやることは既存のインシデント対応に関する情報を整理することです。整理する情報としては、インシデント検知ルートやインシデントレベル、エスカレーションフロー、On-Call体制、ユーザー告知、ポストモーテム、恒久対応などが該当します。
そして既存の情報が整理できたら、それぞれに対しての理想状態を整理し、導入や改善を進めていきます。インシデントレベルを定義するにあたり、ユーザー影響やサービス継続性とひも付いているかや業務時間外対応、メンテナンス、ユーザー告知などのアクションの有無などが、インシデントレベルごとに考慮する必要があります。
エスカレーションフローなどを整備した際は、インシデントが実際に起こる前に避難訓練をしておくと良いです。次はポストモーテムのLv.3ガイドラインについて説明します。
ポストモーテムのLv.3ガイドラインとしては、インシデント発生時、記載内容、振り返りの3つの分類の観点で成熟度を評価します。ポストモーテムを導入、改善する上で重要なことは、そもそも何でポストモーテムを書く目的が定義されているかです。目的の認識をあせた上で、ポストモーテムの管理場所や書く基準や振り返りのルールなどを定めていきます。
基準や定義は必ずドキュメントとして残しておきましょう。ポストモーテムを初めて導入する際は ポストモーテムのテンプレートファイルをSRGとしても提供していたりもします。
書いたポストモーテムの振り返りを実施しているのはあると思いますが、ポストモーテム自体の振り返りをしているところは少ないと思います。ポストモーテムの記載内容の過不足や、書くことが負荷になっていないかも定期的に振り返りをすることをお勧めします。
SRE成熟度評価を実施したプロダクトの中には、書く負荷を軽減するためにインシデントレベルによって必須の記載項目を変更しているプロダクトもあったりします。
次はトイルの撲滅のLv.3ガイドラインについて説明します。トイルの撲滅のLv.3ガイドラインとしてはトイルの整理、トイルの改善の2つの分類の観点で成績度を評価します。トイルの撲滅にあたり、まず始めにするべきことは、プロダクトチームの中でトイルに該当する運用作業を定め共通認識できている状態を作ることです。今後、新しいメンバーが増えても共通認識できるように、基準や定義はドキュメントとして残すことが重要になります。
そしてトイルに該当する運用作業を定めたら継続的に可視化します。可視化する際にトイルを放置することや、ビジネス影響が分かるようになっているとさらに良いと思います。可視化はGitHub Issuesや、普段開発で使っているタスク管理ツールを活用するケースが多いです。
最後に、機能開発と同じ枠組みで計画的に、トイルの改善が行えているかが重要になります なぜ機能開発と同じ枠組みにする必要があるかというと、トイルの改善は多くの組織で後回しにされる傾向が見られるからです。本気で改善したいのであれば、機能開発と同じ枠組みにすることをお勧めしています。
また、定量的に測れる指標でトイルバジェットを設定しバジェットを超えたらトイル改善の優先度を上げるなどのルールを追加することもお勧めしています。
各項目のLv.3ガイドラインを参考に、現在の成熟度と理想状態の認識を合わせながら、四半期もしくは半期ごとの改善計画を作成していきます。改善計画が作成できたら、それをもとに改善を実施していきます。現在の推進状況としては SRGが担当している全主要サービスへの導入が完了しており、SRG担当外サービスやSRG以外のSRE組織とも連携して、他事業部のプロダクトへの導入を進めています。
改善を推進する上で工夫した点としては、SRGが担当する全主要プロダクトのポストモーテム、インシデント対応・監視を1年以上にLv.2以上へ改善するという横断的な改善計画を作成し 目標を定量化して改善を行いました。
そして1年での改善実績として、SRGが担当する全主要プロダクトのポストモーテム、インシデント対応・監視をLv.2以上へ改善するという目標は達成することができました。

SRE成熟度が改善されることによって実際にプロダクトの信頼性向上にも貢献できました。
いくつか例を挙げるとノイジーアラートの削減やインシデント対応フローの整備などによって 障害の推定検出時間や推定復旧時間を短縮することができました。またポストモーテムの改善や障害が発生してから、次の障害が発生するまでの時間延長にも貢献できています。
プロダクトチームが行っているポストモーテムの振り返り会に参加し振り返り会のレビューを行うなどして、ポストモーテムの改善をしてきました。SRE成熟度評価と改善をサポートしたプロダクトの多くからは「やってよかった」というポジティブな声をたくさんいただくこともできています。SRE成熟度評価をしてみてさまざまな気づきがありました。
初めは、回答のしやすさからSRE成熟度評価をチェックリスト方式にすることも検討したのですが、プロダクトの理想状態へ向かうことよりも、いつの間にかチェックリストを埋めることが目的となりやすいことが分かりました。
またそういったことからもチェックリストはEnablementに不向きだということに気づきました。
その他にも成熟度評価を通して、改めて共通言語化やドキュメントの大切さを学ぶこともできました。そして素晴らしいプラクティスやナレッジを知ることができたのも非常によかったです。
当事者にとっては当たり前のことでも知らない人からすると、真似したいと思う取り組みはあったりするのでそういった取り組みを発掘できたのは非常によかったと思います。
今後の展望
SRE成熟度評価としてはサイバーエージェントグループ全体への導入を目指しているので、それに向けてSRE成熟度評価者による評価の差異を可能な限り最小限にし、スケール可能な体制にしていきたいと考えています。
またSRG以外のSREsや組織との連携を強化していき、各項目のLv.3のブラッシュアップやテンプレートファイルやツールなどのSRE成熟度改善を促進させるためのパッケージを追加提供していければと考えています。
そして最終的には、サイバーエージェントグループへSREがインストールされている状態を実現したいです。
組織としての今後の展望としてはビジネスオブザーバビリティ、Enabling SRE、Cloud FinOpsの3領域を特に強化していきたいと考えており、現在も推進しているところです。以上で発表を終わりにします。ご視聴ありがとうございました。
INFORMATION
SRE Technology Mapは以下よりご覧いただけます。
https://www.cyberagent.co.jp/techinfo/info/detail/id=28998

CyberAgent Developer Conferenceのアーカイブはこちらからご覧いただけます。
https://cadc.cyberagent.co.jp/2023/
