
はじめまして!
2023年7月に CA Tech JOB 生としてインターンシップに参加させていただきました、東桔也です。私は、ABEMA の Cloud Platform チームにて resource-label-checker というクラウドのリソースラベル監視ツールを設計・開発しました。
このブログでは、1ヶ月間のインターンシップで経験したことを中心に
- Cloud Platform チームとは
- なぜリソースラベルの監視が必要なのか
- 設計・開発の流れと工夫点
- インターンシップで得たもの
の4点についてお話ししていきます。
1. Cloud Platform チームとは
取り組んだタスクの具体的な説明に入る前に、配属部署である Cloud Platform チーム(通称:クラプラ)を簡単に紹介させていただきます。
Cloud Platform チームは、名前の通りクラウド(GCP, AWS, SaaS, etc.)を活用し、ABEMA における事業成果の最大化を担っています。また、高可用性かつ生産性の高いシステムの構築に向けて、開発グループにベストプラクティスを立案・浸透させたり、新しいクラウドソリューションの適切な活用を推進させたりしています。
個人的には「ABEMA の縁の下の力持ち」という印象を持ちました。
2. なぜリソースラベルの監視が必要なのか
ABEMA には、複数のプロジェクトに大量のクラウドリソースが存在しています。全てのリソースに一貫したリソースラベルを付与することで、コスト管理を楽にすることができます。
また、ABEMA では Cloud Platform チームが GCP や AWS の全てのリソースに共通して付与するラベル(AWS の場合はタグ)のルールを決めてコスト管理に役立てています。単純な例としては、owner=”api-team” や env=”dev” のようなリソースの所有者や環境を識別できるルールが考えられます。
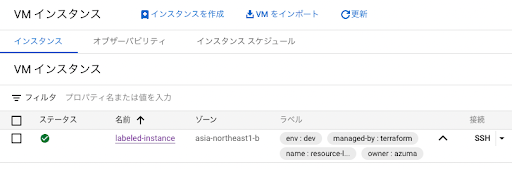
しかし、共通ラベルのルール策定以前から存在していたリソースや、共通ラベルを付与するのを忘れてしまったリソースが現状としてまだまだ多く存在しています。人手で探すには膨大すぎる量のリソースから、共通ラベルが付与されていないリソースを抽出し、Cloud Platform チームや各開発チームが把握できるようにするのが、resource-label-checker の役割です。
その特性から、会社やプロジェクトに依らず導入できるツールになっているので、次章に示す具体的な実装もぜひ参考にしてください。
3. 設計・開発の流れと工夫点
設計・開発の流れについては
① リソースラベルを列挙できる方法を調査する
② 共通ラベルをチェックするプログラムを作成する
③ クラウド上にデプロイして定期実行する
④ ドキュメントを作成して未導入のプロジェクトで検証する
という4つのステップに分けて紹介します。インターンシップ中のメイン目標として「GCP で『すぐに使える』システムを完成させること」を掲げたので、まずは GCP に絞って流れを紹介します。
① リソースラベルを列挙できる方法を調査する
GCP では全てのリソースの情報を取得するための便利な API が用意されています。
Cloud Asset API の SearchAllResources メソッドを使用すれば、各リソースについて以下のようなレスポンスが得られます。
{
"name": string,
"assetType": string,
...
"labels": {
string: string,
...
},
...
}
このレスポンスから、リソースタイプ(assetType)ごとにラベルのキーをチェックして、ルールを満たさないリソースを特定できるだろうという見込みが立ちました。
② 共通ラベルをチェックするプログラムを作成する
使用言語は Go で、Cloud Asset API 用に自動生成された cloud.google.com/go/asset/apiv1 をメインで使用し、結果の Slack 通知のために github.com/slack-go/slack を使用しました。
結果の表示方法は、共通ラベルが付与されていないリソースの数によって望ましい表示方法が異なるため2通りの方法を併用しました。
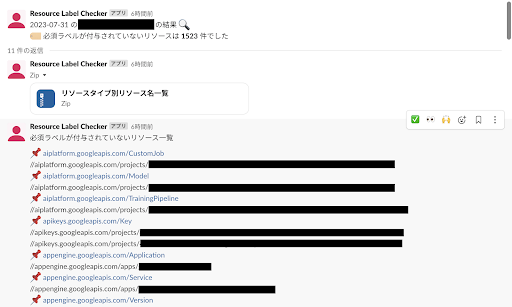
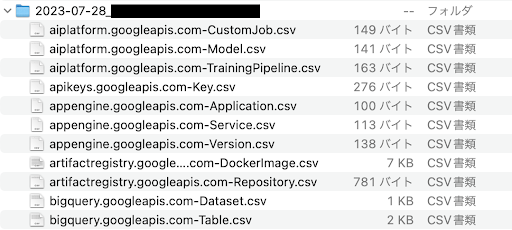
共通ラベルが付与されていないリソースが少ない場合にはスレッド内に直接表示されるリソース名を確認する方が早いです。一方でそのようなリソースが多い場合にはスクロールが大変になるため、リソースタイプごとのリソース名一覧を CSV ファイルに出力し、見通しが良くなるように工夫しました。
③ クラウド上にデプロイして定期実行する
resource-label-checker はクラウド上にデプロイして定期実行させます。
定期実行の方法として GKE のようなフルマネージド Kubernetes サービスを使う方法も考えられますが、全ての GCP プロジェクトに GKE クラスタが存在するわけではありません。そこで、統一して利用できるマネージドサービスを利用して resource-label-checker を稼働させることを検討しました。
一番最初に思いつく方法として、GCP が提供する FaaS である Cloud Functions を使用した下図のような構成が挙げられます。
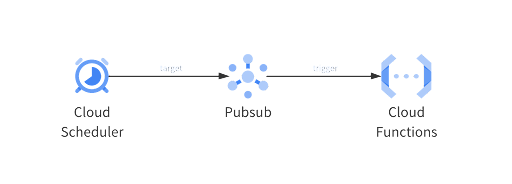
しかし、Cloud Functions(第2世代)の最大タイムアウト時間は、Pub/Sub などを使用したイベントドリブン関数の場合は9分です。playground 環境で既に3分弱かかっており、導入を検討している prod 環境や dev 環境ではリソース量が大幅に増加することも考慮して、関数の実行がタイムアウトしてしまう可能性が高いと考えました。
最終的には、Cloud Run jobs を使用する構成を採用しました。

Cloud Run jobs のタスクはデフォルトで最大10分間実行されますが、最長24時間まで延長することができます(ただし1時間を超える時間はプレビュー機能)。
ソースコードや共通ラベルのルールに変更があった場合には、GitHub Actions が変更を検知してイメージをビルドし、共通の Artifact Registry にイメージを push します。Artifact Registry 側では、各プロジェクトの Cloud Run サービスエージェントにリポジトリの読み取り権限を与えます。
GitHub Actions から GCP へ認証を行う方法としては、OpenID Connect(OIDC)を使用してキーなしで認証する枠組みを Cloud Platform チームが既に整備してくれていました。シークレット管理や漏洩時のセキュリティリスクを抑えるためにも、このような戦略の徹底は改めて大切だと感じました。
④ ドキュメントを作成して未導入のプロジェクトで検証する
インターンシップ終了後も Cloud Platform チームが運用・開発できるようにドキュメントを作成し、再現性があるかどうかをトレーナーさんに検証していただきました。
インフラの構成は Terraform によってコードで宣言されており、Atlantis によって GitHub の PR コメント上で Terraform の plan や apply ができるようになっています。トレーナーさんが resource-label-checker を複数のプロジェクトに新規導入する時も、合計5分以内に完了させてくださいました。
検証段階での新たな発見として、「プロジェクトごとに Cloud Run jobs の実行時間が大きく異なる」ということが分かりました。特に、CI/CD などで Docker イメージを継続的にpush する Container Registry や Artifact Registry がある場合はリソース数が膨大になる可能性があります。この場合は、以下のように Terraform で Cloud Run jobs の最大タイムアウト時間を調整するなど工夫が必要です。
resource "google_cloud_run_v2_job" "default" { ... template { template { containers { ... } ... timeout = "3600s" # デフォルトは10min } } }
EX. AWSにresource-label-checkerを導入する
残念ながら AWS への導入は、手順③のデプロイの途中でインターンシップ期間が終了してしまいました。番外編として、設計・開発に取り組む上で感じた AWS 独特の難しさを以下にまとめます。
(1) 全リソースのタグを取得できるAPI
私が調査した範囲では、GCP の Cloud Asset API のような便利な API は AWS に用意されていませんでした。AWS の Technical support ケースにも問い合わせましたが、依然としてピッタリな解決策は見つかっていません。
例えば、AWS Resource Groups Tagging API の GetResources は「タグ付けされている or 過去にタグ付けされた」リソースのみを取得するため、タグが全く付いていないリソースがチェックから漏れてしまいます。また、AWS Resource Explorer を使えばリソースの ARN に対してタグを取得できますが、サポートされているリソースタイプがまだ少ないというのが現状です。
インターンシップでは、AWS Config の ListDiscoveredResources でリソース ID を取得して BatchGetResourceConfig でリソースに紐付く configuration フィールド(文字列)から頑張ってパースしてタグを取得していました。
インターンシップで書いたプログラムとは少し異なりますが、終了後に再実装したソースコードを https://github.com/Kitsuya0828/resource-label-checker にアップロードしたので参考にしてください。
(2) 定期実行を実現するデプロイ方法
AWS でも、GCP の Cloud Run と同じようなマネージドサービスを利用できればベストです。AWS サービスと Google Cloud を比較すると、サービスの候補として以下の3つが挙げられます。
- AWS Lambda
- AWS App Runner
- AWS Fargate (Amazon ECS)
2.の AWS App Runner はフルマネージド型のコンテナアプリケーションサービスであり最適であるように見えますが、web アプリケーション向きのため強引な方法を使わなければスケジューリングは難しいです。そこで、1. と3. の構成について実際に Terraform を書いて検証を行いました。
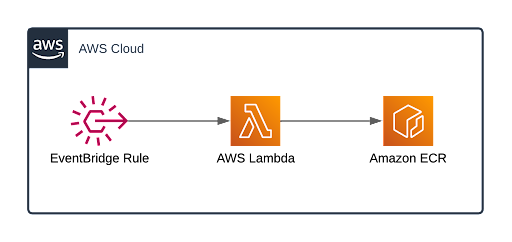
まずは、EventBridge Rule を作成して Lambda 関数を定期実行する方法です。Lambda はサーバーレスでコードを実行できるサービスですが、コンテナもサポートしています。ECR をクロスアカウント許可にすれば複数アカウントでイメージを共有できるため、resource-label-checker を導入するアカウントが大幅に増えても CD の負担にならないと考えました。
ただし、AWS Lambda を利用する際の注意点として、最長実行時間(タイムアウト)が15分であることが挙げられます。リソース数が膨大な環境での検証はできていませんが、15分をオーバーしないように注意が必要です。
次は、EventBridge Scheduler を使って ECS Task を定期実行する方法です。
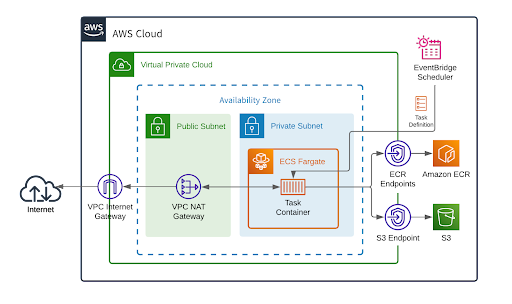
Fargate では awsvpc ネットワークモードが必要となるため、構成がかなり複雑になってしまいました(イメージをpullする時はVPCエンドポイントを使用し、NAT Gateway の通信コストを削減しています)。この方法にタイムアウトはありませんが、VPC やサブネットの IP アドレス範囲を考慮しなければならず、シームレスに複数アカウントに導入することは難しいだろうと考えました。
この2つの方法について、インターンシップ終了後に Terraform のサンプルを作成したのでhttps://github.com/Kitsuya0828/resource-label-checker-terraformを参考にしてください。
今後は AWS Step Functions と AWS Lambda を組み合わせて、「全リソースを検索し終える state まで Lambda 関数を呼び出す」ような構成について検討する予定です。
4. インターンシップで得たもの
私が1ヶ月のインターンシップで得られたものは、大きく分けて2つあると考えています。
圧倒的な量のフィードバック
配属された Cloud Platform チームのメンバーから、たくさんのフィードバックをいただくことができました。
まずトレーナーさんは、タスクをいくつか用意した中で私がやりたいタスクを尊重してアサインしてくださり、インターンシップとは思えないほど裁量権を与えてくださったのでびっくりしました。さらに、私が小さな選択をする各ステップで、セキュリティ・コスト・設計に関する適切なフィードバックをいただけたのがとても嬉しく、大変充実した時間になりました。
また、Cloud Platform チームのメンバー複数人がご厚意で Go のソースコードレビューをしてくださいました。私は趣味以外で Go を書くのが初めてだったので、いただいたレビューの数々から今後に活かせそうなスキルや考え方を持ち帰ることができました。
現場でしか見られない大規模なインフラ構成
私は技術を見るのがかなり好きなので、滅多にお目にかかれない企業のインフラ構成を見ることができた時間はとても貴重でワクワクするものでした。
Cloud Platform チームはチャレンジングなタスクを本当にたくさんこなしていて、1ヶ月でそれをキャッチアップするのは流石に無理でした。しかし、現場で活躍しているエンジニアたちの姿を見て、自分に足りないスキルを再認識したり、今後のモチベーションが高まったりしました。
面談時は漠然とクラウドやインフラに興味があった私ですが、インターンシップが終了して改めて「クラプラに配属されて良かった」と実感しています。
おわりに
1ヶ月の CA Tech JOB はあっという間でした。
私は週3日、ほぼリモートワークでインターンシップをさせていただきましたが、全くと言ってよいほどストレスなく、楽しく全力でタスクに取り組むことができました。
お世話になったトレーナーさん、Cloud Platform チームの皆さん、技術人事の皆さん、本当にありがとうございました。