
はじめに
はじめまして、同志社大学大学院 修士2年のbe3(@Blossomrail)です。
2023年4月の1ヶ月間(週3日稼働)、サーバーサイド領域のエンジニアとしてインターンシップに参加させていただきました。
本記事では、私のインターンシップでの経験についてお伝えしたいと思います。
サイバーエージェントには様々なプログラムやインターンシップがありますが、今回私が参加させていただいたものはCA Tech JOBというインターンシップです。
インターンシップで立てた目標について
CA Tech JOBではインターンシップに参加する前に、自身が今後成長していきたい点やインターンシップでの目標を記入します。
私が立てた目標は、「技術的な仕様が決まっていない段階のタスクに対して主体的に取り組むこと」でした。
これまで様々なインターンシップに参加させていただいていたものの、これまでの私は技術的な仕様を期間内に満たすことで精一杯でした。
そのため、この内容を目標として掲げた理由は、私が取り組んできたタスクは技術的な仕様がある程度決まっているものが多かったためです。
将来的にプロダクトを開発するエンジニアを目指す上で、今の自分には要件から技術的な仕様に落とし込む能力が足りていないと感じていたため、こうした目標を掲げようと思いました。
インターンタスクについて
インターンシップ期間、私はCL事業部に配属されました。
CL事業部は、CL というLDH所属のアーティストがライブ動画やオンデマンド動画を配信するサービスを開発・運営する部署です。
前述した目標に沿うようにチームからいただいたタスクは、「オンデマンド番組に字幕があることを示すタグを表示する」という機能の実現でした。
CLではオンデマンド番組を配信していて、番組のプレビューには様々なタグが添えられています。
このタグの一つとして「SUBTITLES」と表示するタグ(以下、字幕タグ)を追加するために、サーバーサイドエンジニアとしてAPIに機能を追加することが今回のインターンシップでの目標になります。
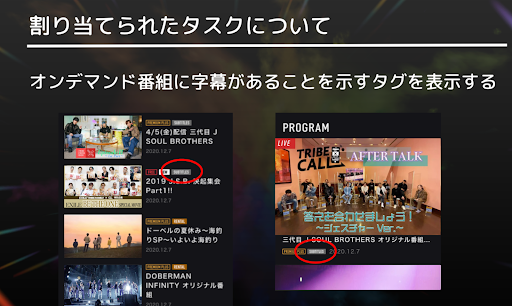
CLは国外のユーザーも利用しているため、一部のオンデマンド番組には字幕が付与されています。
これまでは字幕タグがなかったため、動画が一覧表示された場合に、動画に字幕が付与されているのかどうかが実際に動画を開いてみるまで判断できませんでした。
字幕の制作にも費用がかかっているため、せっかく字幕を付与していても、その存在に気付いてもらえなければ機会の損失になってしまいます。
そこで字幕タグを導入することで、より多くの国外ユーザーに字幕付き動画があることを知ってもらうことが、今回のタスクの意義になります。
施策実現に向けた要件整理
以上のようなタスクをいただいて、まずは機能要件を明確にするところから始めました。
具体的には、ビジネスサイドの方が作成した字幕タグに関する検討書を読み進めて、実装に先立ってビジネスサイドの方と以下のようなやり取りをしました。
- 検討書をもとにリストアップしたページは字幕タグの追加対象か
- 検討書に記載されている、字幕タグ関連のその他機能も実装の対象か
やり取りの結果、番組を一覧表示するページが字幕タグの追加対象となることが分かりました。
外部仕様が明確になったところで、次に技術的な仕様を明確にするために、対象ページでオンデマンド番組の表示にどのAPIが利用されているかを調査しました。
調査は以下のような方法で行いました。
- API仕様書からオンデマンド番組を表示するためのAPIを特定
- ブラウザのデベロッパーツールを使って、開発用のサービスサイト上で該当ページで特定したAPIにアクセスしていることを確認
API仕様の変更
以上のように機能要件を整理したところで、番組一覧の情報がレスポンスに含まれるAPIに対して、字幕一覧の情報もレスポンスに加えれば良いことが分かりました。
そこで次に、実際にAPI仕様を定義するファイル(protoファイル)を編集して、該当のAPIが字幕情報もレスポンスするような仕様に変更しました。
これにより、フロントエンドは、レスポンスに字幕一覧の情報が含まれていれば字幕タグを表示するという制御が実現できることになります。
gRPC
CLではバックエンドのシステム間通信にはgRPCを使用し、grpc-gatewayを通じてiOSやAndroid、WebにREST APIを提供しています。
gRPCとは、RPC(Remote Procedure Call)と呼ばれるシステム間の通信方式を実現するプロトコルです。
gRPCではProtocol Buffersと呼ばれるシリアライゼーション技術を用いており、Protocol Buffersではprotoファイルでデータ構造(今回だとレスポンスのデータ構造)を定義します。
つまり、CLでAPI仕様を変更する場合、protoファイルを編集する必要があるということです。
具体的には、計10種類のAPIのレスポンスに字幕情報を加えました。
一例ではありますが、例えば番組一覧を返すAPIを定義するprotoファイルは以下のようになりました。
```Protobuf
message ListProgramResponse {
repeated Program
string
map<string, LiveVideo>
map<string, CastVideo>
map<string, OndemandVideo>
map<string, OndemandSubtitles>
}
```
新たに追加した箇所は、map<string, OndemandSubtitles> の部分です。
ここで、番組IDを示す文字列と字幕情報となるデータ構造の対応関係を加えることで、番組一覧を取得するAPIのレスポンスに字幕情報を加えています。
スキーマ駆動開発
API仕様の変更に伴って、フロントエンドのチームと仕様変更に対する合意を取る必要がありました。
CLでは、いわゆるスキーマ駆動開発と呼ばれる開発手法を採用しています。
スキーマ駆動開発とは、予め合意を取って定義したAPI仕様に基づいて、フロントエンドとサーバーサイドのチームが並走して開発を行う開発手法です。
そのため、Web、iOS、Androidそれぞれのチームの方々に対して、機能追加の内容と更新した場合のAPI仕様をお伝えし、字幕タグをフロントエンド側で表示する上で必要な情報が更新後のAPI仕様から得られるかを判断していただきました。

実装
合意が取れ、満たすべきAPI仕様が確定した段階で、サーバーへの機能追加に向けた実装に進みました。
まずは、CLのサーバー(以下、cl-server)がどのようなシステムアーキテクチャになっているか、そして、どの構成要素に対して機能追加をすれば良いかを把握するところから始まりました。
マイクロサービスアーキテクチャ
cl-serverは、いわゆるマイクロサービスアーキテクチャと呼ばれる構成で実現されています。
マイクロサービスアーキテクチャとは、小さな機能単位で分割された複数のサービスが通信し合って1つのアプリケーションを構成する、というシステムアーキテクチャです。
つまり、以下に示す図のように、cl-serverという1つのサーバーを実現するために、フロントエンドが利用するAPI(図中だとgateway_uesr)の裏側には複数のサービス(図中だとmicroservices)があるということです。
そして、各サービスが担当するデータを管理し、サービス間で通信して連携し合うことで、フロントエンドのリクエストに対するレスポンスを返すことができます。
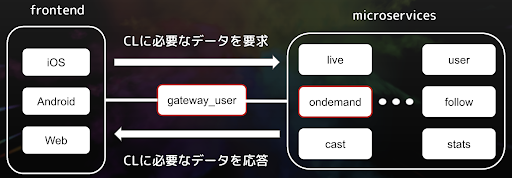
前置きが長くなりましたが、cl-serverにおけるマイクロサービス群のうち、実装対象となったものは、上記に示す図で赤枠で囲っている ondemand と gateway_user と呼ばれるサービスでした。
ondemand は字幕に関するデータを管理するサービスで、 gateway_user はフロントエンドからのリクエストに合ったサービスをマイクロサービス群から呼び出して、レスポンスを送るサービス(API)です。
責務に応じて分離されたレイヤー毎に処理を追加
ここからは、実装についてお話したいと思います。
実装対象である構成要素にだけ焦点を当てると、以下の図のように3つの層で分けることができます。
各層の説明は以下の通りです。
- gateway_user:上述の通り
- ondemand/api: ondemand が他サービスと通信する際に必要なAPIを提供する層
- ondemand/db: 字幕に関するデータを管理するDB処理をする層
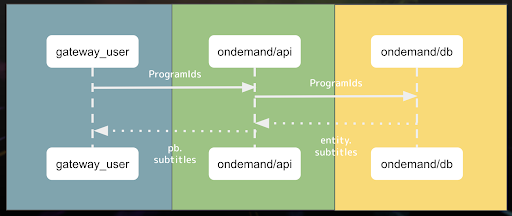
上記のシーケンス図より、gateway_userは番組IDのリスト( ProgramIds )を ondemand/api に渡し、 ondemand/api は受け取った番組IDのリスト( ProgramIds )を ondemand/db に渡してDBから字幕エンティエティのリスト( entity.subtitles )を取得する、そして順にデータを整形して返していく、という処理のリレーになります。
シーケンス図で言うところの右方向に向かって層が依存していることになるため、以下のような順番で実装とPRの分割を進める方針を立てました。
- ondemand/db :番組IDのリストから字幕エンティティのリストを取得する
- ondemand/api :字幕エンティティのリストをgRPCにおけるRPCが満たす形式に変換する
- gateway_user : 当該APIのレスポンスに字幕エンティティのリストを追加する
ただ、10日間の稼働日数の中で残された時間があまりなかったため、ondemand/db の実装に対するPRだけがマージされ、ondemand/api の実装が途中で終わることになりました…。
そのため、ここからは ondemand/db の実装にだけ焦点を当ててお話します。
cl-serverではDBにGCPのCloud Spannerを利用しています。
Cloud Spannerでデータを読み取る方法は、SQL文を直に渡す方法とRead APIを使う方法の2種類がありますが、今回は後者で実装しました。
以下のドキュメントに記載の通り、Read APIでデータを読み取る場合、SQL文を書く必要はありませんがインデックスを明示する必要があります。
Read using the index
Getting started with Spanner in Go | Google Cloud
処理の全体像はこちらのサンプルコードを読んでもらえればと思いますが、今回の実装におけるRead APIの使い方に関して説明します。
ReadUsingIndexという関数を使用して、インデックスを指定したデータを読み取りました。
シグネチャは以下の通りです。
func (t *ReadOnlyTransaction) ReadUsingIndex(ctx context. Context, table, index string, keys KeySet, columns [] string) (ri *RowIterator)
Read APIの関数を使用する場合、ユニークなキーの集合である KeySet を指定する必要があります。
今回は番組IDのリストを KeySet 型に変えて、 ReadUsingIndex の引数として渡しました。
学びや気付き
あっという間の1ヶ月でしたが、事業会社のソフトウェアエンジニアとしての学びや気づきを色々と得ることができたと思います。
まず、インターンシップ初期に目標として掲げていた「技術的な仕様が決まっていない段階のタスクに対して主体的に取り組むこと」は、メンターをはじめとしたチームの方々からの手厚いサポートがあり、何とか達成することができたと思っています。
その結果、仕様決めの大変さや仕様決めまでの段取りを考える重要性を身に沁みて実感することができました。
また、ビジネスサイドの方とのやり取りを通して要件を考える経験ができたため、規模に関係なく機能追加の背景にはビジネス的な施策としての価値があることが実感できました。
この気づきは、事業を支えるソフトウェアエンジニアとして成長するために技術だけでなく事業への影響にも関心を寄せていく上で、大事な気づきだったんじゃないかと思っています。
これまでの私は技術や技術の扱い方を学ぶことが多かったですが、事業の施策をどう技術に落とし込むのかという視点でエンジニアリングに携わることができ、有意義な1ヶ月を過ごすことができました。
まとめ
以上が私のインターンシップ体験になります。
こうした学びや気づきのある体験ができたことは、CL事業部という環境がビジネスサイドの方と活発に連携してプロダクト開発に尽力している環境だったためだと思います。
本当にお世話になりました!
本記事を通してサイバーエージェントのプロダクト開発に興味が湧いた方は、CA Tech JOBにぜひエントリーしてみてください!