
AI事業本部Dynalystのデータサイエンティスト長江(@nsakki55)です。今回はDynalystで取り組んでいるML監視について紹介します。
MLOpsにおける監視
なぜML監視は難しい?
ML Test Scoreの論文では、ML監視の難しさを従来のソフトウェア開発とMLシステム開発を対比して説明しています。
従来のソフトウェア開発ではコードに依存してシステムの挙動は決定論的に決まります。一方、MLシステムはコードに加えデータと機械学習モデルに依存するため、MLシステムの挙動は確率的に変化します。この違いから従来のソフトウェア開発の監視にはなかった、MLシステム特有の監視が必要となってきます。
下右図はMLシステムのテストと監視項目を表しています。従来のシステム監視に加え、データと予測に関する監視項目が加えられています。
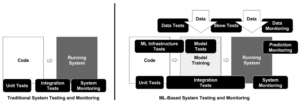
MLシステムの監視を複雑にしている要因に、MLシステムの開発に様々な専門性を持った人が集まっていることが挙げられます。
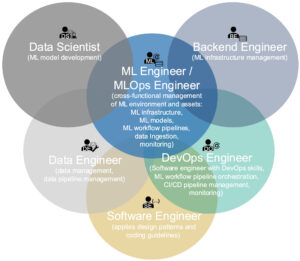
以下の図はMLOpsについて体系的にまとめた論文Machine Learning Operations (MLOps): Overview, Definition, and Architectureに記載されている、ML(Ops)エンジニアが関わる専門分野になります。
ML(Ops)エンジニアは複数の専門分野にまたがっていることがわかります。
このように異なる専門分野の人たちがMLシステムを作るため、それぞれの技術領域で関心のある監視項目が異なってきます。このような状況がML監視項目を決めるのを難しくしています。
何を監視すればいいのか?
MLシステムを定量的に評価したML Test Scoreの中に監視に関する項目があります。
ML Test Scoreではデータサイエンスに関わる監視(データ・モデル・予測値の監視)と、システム運用に関わる監視 (システムの監視)に大きく分類し、7つの監視項目を取り上げています。
| 分類 | 監視項目 |
|---|---|
| データ | MLモデルの依存先の変化 |
| 学習時と推論時の入力データの普遍性 | |
| 学習時と推論時の特徴量計算の普遍性 | |
| モデル | 本番環境のモデルバージョン |
| モデルの数値的安定性 | |
| 予測値 | MLモデルの入力データに対する予測性能 |
| システム | MLシステムの計算性能 |
ML Test ScoreはMLシステム開発の指針となる一方、抽象度が高く具体的に何を行えばいいか分かりにくい印象があります。
neptune.aiが公開してるA Comprehensive Guide on How to Monitor Your Models in Production がML監視項目を具体的に紹介して分かりやすいので取り上げます。
上記事の監視項目をまとめると以下のようになります。
| 大分類 | 小分類 | 項目 |
|---|---|---|
| データ | データ品質 | データの重複 |
| データの欠損 | ||
| コードの構文エラー | ||
| データ型・データ形式のエラー | ||
| スキーマエラー | ||
| 上流・下流データの整合性 | ||
| データドリフト | データの記述統計量 | |
| 連続特徴のデータ距離指標 | ||
| カテゴリ特徴のデータ距離指標 | ||
| 外れ値監視 | 大きなデータドリフトの発生 | |
| 重要度の高い特徴の大きな変化 | ||
| 教師なし学習による外れ値検出 | ||
| モデル | モデルドリフト | 過去と現在の予測値のデータ分布距離 |
| 予測精度の時間変化 | ||
| ラベルドリフト(正解ラベルの分布変化) | ||
| モデル設定 | 学習時のメタデータ | |
| 敵対的攻撃 | 異常イベントの発生 | |
| 予測 | モデル評価指標 | 本番環境の予測値に対する評価指標 |
| 予測ドリフト | 予測値の分布変化 | |
| システム | システムパフォーマンス | CPU/GPU使用率 |
| メモリ使用率 | ||
| 失敗リクエスト数 | ||
| 推論リクエスト数 | ||
| 推論リクエストのレイテンシー | ||
| システム信頼性 | インフラ・ネットワーク指標 | |
| パイプライン | データパイプライン | 入力データ |
| DAGタスクの状態 | ||
| 出力データ | ||
| データの記述統計量・距離指標 | ||
| データパイプラインジョブの実行状態 | ||
| モデルパイプライン | 実行環境のメタデータ | |
| 学習ジョブの実行状態 | ||
| コスト | ホスティング費用 | |
| 推論コンピューティング費用 |
ML監視は従来のソフトウェア開発の監視要素に加え、モデルや予測値、データに関する監視が必要とされています。
監視の優先順位
上述のようにML監視項目は数多くあり、いきなり全ての監視項目を導入するのは難しいです。
クラウドベンダー各社のMLOpsの成熟度モデル [3]のように、ML監視も段階的に取り組んでいくことが望ましいと言えます。
A Comprehensive Guide on How to Monitor Your Models in Productionの記事ではGoogleのMLOps成熟度モデルに合わせた監視項目を取り上げています。

EVIDENTLY AIが公開してるMonitoring ML systems in production. Which metrics should you track?の記事では、ML監視項目を段階的に積み上げていく状態をピラミッド構造になぞらえています。
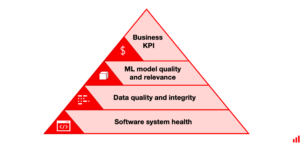
どちらの例も、まずシステムの監視から始まり、次いでデータ監視、モデル監視、ビジネスKPIの監視の順に行っていくことを推奨しています。
MLシステムの監視を取り組む場合、まずDevOps的な監視を整えた後、ML特有の監視に取り組むのが手堅いと思えます。
監視ツール
ML監視システムを作っている各社の事例や、クラウドベンダー、SaaS・OSSが提供する監視ツールを紹介します。
自社開発のML監視基盤を構築してる例では、UberのMichelangelo、AirbnbのZipline(Bighead)、LinkedInのPro-MLがあります。
機能としては特徴量ごとのデータ分布の可視化、特徴量重要度の計算などが目立ちます。
データサイエンティストがデータの理解を視覚的に得られるよう作り込まれている印象をうけます。
UberのMichelangelo
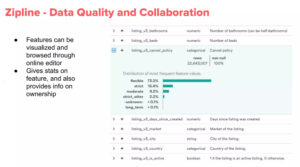
LinkedInのPro-ML
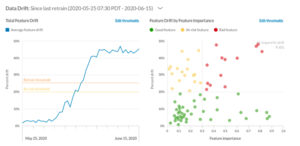
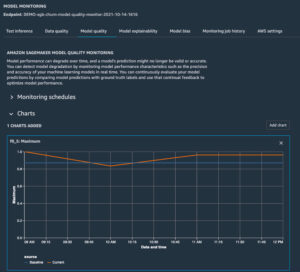
クラウドベンダーからはVertex AI Monitoring, Amazon SageMaker Model Monitor, Azure Machine Learning Dataset Monitorが提供されています。
ML監視の中でもデータドリフト検知は、2つのデータ分布の差を定量的に評価することを指しますが、データドリフト検知の自社開発は工数がかかるためMLマネージドサービスと連携すると良いでしょう。
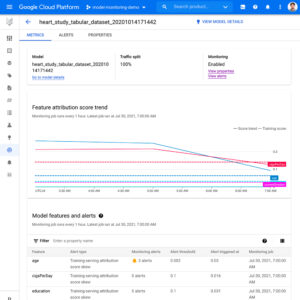
Vertex AI Monitoringを使用したのML監視の事例としては、Google を支える機械学習サービス監視の MLOpsの動画がわかりやすいです。
Vertex AI Monitoring
SageMaker Model Monitor
SaaS・OSSのML監視ツールは WhyLabs, Datadog, Prometheusが有名です。
WhyLabsはMLシステムに特化した監視ツールです。様々なOSSやクラウドベンダーと連携できるため、既存のシステムに組み込みやすくなっています。
LLMに関する監視機能も提供されていて、機能開発のスピード感の速さが伺えます。
Datadogはシステムのリアルタイム監視とデータ分析を提供するSaaSの監視プラットフォームです。
DevOpsの監視ツールとして知名度が高く、送信した独自のメトリクスを可視化できます。
データドリフトのようなML特有の監視を実現する場合、Datadogだけで実現するのは難しいため、自社開発の機能を導入する必要があります。
Prometheusは監視対象のサーバー情報などのメトリクスを収集するOSSの監視ツールです。OSSのデータ可視化ツールのGrafanaと組み合わせることで、リッチなダッシュボードを作成することが可能です。
PrometheusとGrafanaを用いたML監視について書かれた A simple solution for monitoring ML systems. の記事が参考になります。
DynalystのML監視の取り組み
ML監視の取り組み方
DynalystではML監視を取り組み始めるにあたって、どのようにML監視を導入していくか議論がありました。
Dynalystでは以下のような方針はとらないようにしました。
- ML Test Scoreの監視項目にやみくもに取り組む
- とりあえずML監視ツールを入れてみる
これは以下の理由からです。
- ML Test Scoreの方法がプロダクトの課題解決からはオーバーエンジニアリングだった
- 誰にも見られないダッシュボードができると予感した
- ML用ツールの導入がソフトウェアエンジニアとデータサイエンティストの責任範囲を分断する可能性があった
DynalystではML監視を以下のような手順で進めました。
- 実際にあった課題を整理
- ML監視施策で実現したい状態を決める
- 監視項目の選定
- 監視のための技術選定
MLOpsでよく取り上げられる項目をやみくもに監視するのではなく、プロダクトの課題を解決することに着目し、必要最低限の監視を行うことにしました。
1. 実際にあった課題を整理
DynalystではML監視に取り組む前では以下のような課題がありました。
- 学習データの特定の特徴量が意図しない値のまま運用されていた
- 特定のモデルの学習データ量が徐々に減っていたことに気づかなかった
- 学習時のモデル精度指標をログ出ししてるだけで、見られることがなかった
- 本番稼働しているモデルの予測値の値をSQLで確認していた
- モデルのオンライン評価が行われておらず、モデル精度の悪化をビジネス指標の変化でしか気づけなかった
- 学習時と本番環境の特徴量に関する指標が監視されておらず、モデル精度が悪化した時の原因究明が困難
2. ML監視施策で実現したい状態を決める
プロダクトが抱えている課題を元に、ML監視施策が完了した後どのような状態を実現すれば良いか決めました。
エンジアリングを実施する人だけで施策の目標を考えると、技術に偏った視点となったり、プロダクトが本当に解決したい課題から外れていってしまう危険があります。
このような状況を回避するために、DSメンバー全員の合意を取った上で、ML監視施策後に次の状態になっていることを目標としました。
- 学習時の状態の変化を認知できる
- 学習データ・モデル精度の大きな変化にすぐに気付ける(アラート機能)
- 本番環境で動いているモデル精度を担保できる
3. 監視項目の選定
実現したい状態を達成するために、オフライン・オンライン評価の2つの観点で見る指標の整理を行いました。
| オフライン・オンライン | 監視項目 | 対象 |
|---|---|---|
| オフライン評価 | 検証データの予測精度指標 | logloss, AUC…etc |
| 学習データの分布 | データ数, 特徴量の内訳 | |
| オンライン評価 | 予測値の記述統計量 | 平均, 分散…etc |
| 本番環境の予測精度指標 | logloss, AUC…etc | |
| モデルの予測値の再現率 | オンライン予測値の再現率 | |
| モデルの予測値の偏り度合い | 同じ予測値の割合 |
上記の指標を元に以下のアラートを追加しました。
- オフライン精度が直前のバージョンより大きく悪化
- 学習データ数が直前のバージョンより大きく減少
- 学習データ数が1ヶ月前のバージョンより大きく減少
- オンライン精度指標が悪化
- オンライン予測値を取得不能
- オンライン予測値が大きく変化
指標を選定する過程で、以下の指標を検討しましたが採用しませんでした。
- データドリフト指標
- 広告ドメインではデータの流動性が高く、問題となるドリフトか判断が難しい
- ドリフト指標が抽象的で、人間が理解するには難しい
- 特徴量重要度
- 学習データ分布の変化を見る方が、モデル理解に役立つと考えた
- ヒストグラムなどの特徴量のEDA
- 新しくダッシュボードを作成する必要があり、導入コストが見合わない
4. 監視のための技術選定
DynalystではAWSを使用しているため、SageMaker Model Monitorの機能を使えないか検討しました。
他にもML監視ツールを使えないか検討しましたが、最終的に自前で指標の集計を行い、既に監視ツールとして使用していたDatadogで監視を行う方法に落ち着きました。
理由は以下が挙げられます。
- SageMaker Model Monitorと既存システムとの相性が悪かった
- ML監視用のDashboardを新しく作成することによる、継続的なメンテナンスコストをDSが担いたくなかった
- チーム全体で見る習慣がついてないと、監視にならないと思った
SageMaker Model Monitorの強みであるデータキャプチャ機能を利用したデータドリフト検知を行う場合、SageMaker Endpointの利用が必須となっています [15]。Dynalystでは推論レイテンシー要件の関係から、SageMaker Endpointを利用していませんでした。可視化できる項目がデータ分布の記述統計量やドリフト指標に関するもので、直感的に理解できる内容ではありませんでした。
これらの状況からSageMaker Model Monitorの導入は見送りました。
実現したML監視の状況
上記の監視項目をDatadogのダッシュボードで監視しています。実際に作成したダッシュボードの例を紹介します。
予測値の記述統計量
モデルごとの予測値の時系列変化を見ています。

オフライン予測精度
モデルごとの学習時の精度指標の変化を見ています。

オンライン予測精度
モデルが本番稼働していた時間の実績を元に、オンライン精度指標の変化を見ています。

学習データ分布
各特徴量のモデルバージョンごとの変化が分かるにしています。
特定の特徴量の値が大きく変わったか、瞬時に判断できるようになりました。
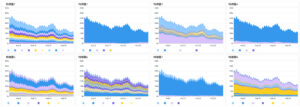
特徴量ごとの内訳
特定のモデルバージョンの特徴量の内訳を出力しています。

予測値の再現率
本番稼働しているモデルの予測値を、オフラインで再現できるかチェックしています。
予測値の乖離についての取り組みは本番環境で動く機械学習モデルの性能を追試することの重要性の記事で詳しく記載しています。

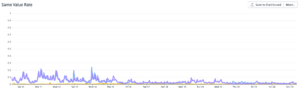
予測値の偏り
本番環境の予測値が特定の値に偏っていないかチェックしています。
システムに関する指標
以下の指標をDatadog上で監視しています。
システムに関する指標の整備はソフトウェアエンジニアチームが担当してくれています。
- 推論キャッシュヒット率
- CPU使用率
- メモリ使用率
- リクエスト数
- レイテンシー
- エラー数
- インスタンス台数
…etc
まとめ
MLOpsの一般的な監視項目について調査し、DynalystのML監視の取り組みについて紹介しました。
ML監視は大きく分けてシステムに関する監視と、データサイエンスに関する監視に分けられます。今回はデータサイエンスに関する監視を中心に取り組みを紹介しました。
ML監視の要素は幅広く、どこから手をつけていいか迷うと思います。
Dynalystではプロダクト課題を元にして、ML監視施策を進めていきました。監視は既存システムとの相性を考えDatadogで実現させました。
各種クラウドベンダーやSaaSが提供するML監視ツールの機能が充実してきているので、ML監視のハードルは下がっていくと思われます。
参考文献
- The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction
- Machine Learning Operations (MLOps): Overview, Definition, and Architecture
- A Comprehensive Guide on How to Monitor Your Models in Production
- 3大クラウド各社の MLOps 成熟度モデルの比較
- Monitoring ML systems in production. Which metrics should you track?
- Google を支える機械学習サービス監視の MLOps
- 機械学習システムデザイン ―実運用レベルのアプリケーションを実現する継続的反復プロセス
- The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction ↵
- Machine Learning Operations (MLOps): Overview, Definition, and Architecture ↵
- 3大クラウド各社の MLOps 成熟度モデルの比較 ↵
- A Comprehensive Guide on How to Monitor Your Models in Production ↵
- Monitoring ML systems in production. Which metrics should you track? ↵
- Meet Michelangelo: Uber’s Machine Learning Platform ↵
- ML Platform Q1 Meetup: Airbnb’s End-to-End Machine Learning Infrastructure ↵
- Model health assurance platform at LinkedIn ↵
- Feature Attributions の監視:Google はいかに大規模な ML サービスの障害を乗り越えたのか ↵
- Amazon SageMaker Model Monitor: A System for Real-Time Insights into Deployed Machine Learning Models ↵
- データセットでデータ ドリフトを検出する (プレビュー) – Azure Machine Learning ↵
- whylabs.ai ↵
- インタラクティブなリアルタイムダッシュボード | Datadog表示 ↵
- A simple solution for monitoring ML systems. ↵
- データをキャプチャ – アマゾン SageMaker ↵