
この記事は CyberAgent Developers Advent Calendar 2023 17日目の記事です。
株式会社WinTicketで競輪事業のキャペーン設計や運用、分析を担当しています。2023年ビジネスコース新卒入社の村瀬拓登です。
私はエンジニア職ではありませんが、社内の課題を解決するにあたり生成AI活用にチャレンジしたので、僭越ながらその記録を投稿させていただきます。
今回、CyberAgentメディア事業部 Data Science Centerの若松さん(機械学習エンジニア)の全面サポートにより実現できました! この場を借りて御礼申し上げます!ありがとうございました!
はじめに
弊社では現在、競輪・オートレースの投票サービス「WINTICKET」を提供しており、業界最後発ながらシェアNo.1まで事業を拡大してきました。

弊社は日々のデータドリブンな意思決定でグロースしてきましたが、多くの場合、データを抽出するにはSQLを書く必要があります。弊社ではこのステップを「書ける人に頼む」スタイルで運用してきました。
しかし、 これでは依頼が集中した際にどうしてもデータ抽出や評価までの時間が長くなり、その結果、意思決定のスピードも遅くなるというデメリットがあります。
そこで、誰でもデータ抽出できる状態を目指して、自然言語から、自社のデータ構造(テーブル構成/スキーマ/外部テーブルとの結合)に合わせたSQLを生成することにチャレンジしたので、本記事で紹介します。
作ってみた
今回はSQLや自社で蓄積しているデータベースへの知識を持たない人が活用することを目的としているため、2つのステップに分けて構築しました。
- STEP① ユーザーが欲しいデータの所在を検索できるようにする
- STEP② プロンプトからGPTにSQLを出力させる
ここからは、各ステップの構成や実装内容について紹介します。
本記事ではBigQueryが公開しているbigquery-public-dataプロジェクトからthelook_ecommerceというデータセットを使用しています。 データセットの概要は公式サイトをご確認ください。
STEP① ユーザーが欲しいデータの所在を検索できるようにする
今回はLangChain、GPT-3.5のEmbedding、検索ライブラリのFassisを使用しました。
全体のイメージは下記の通りシンプルで、BigQueryから取得したテーブル情報に補足情報を付加したものをEmbeddingして、保管しています。
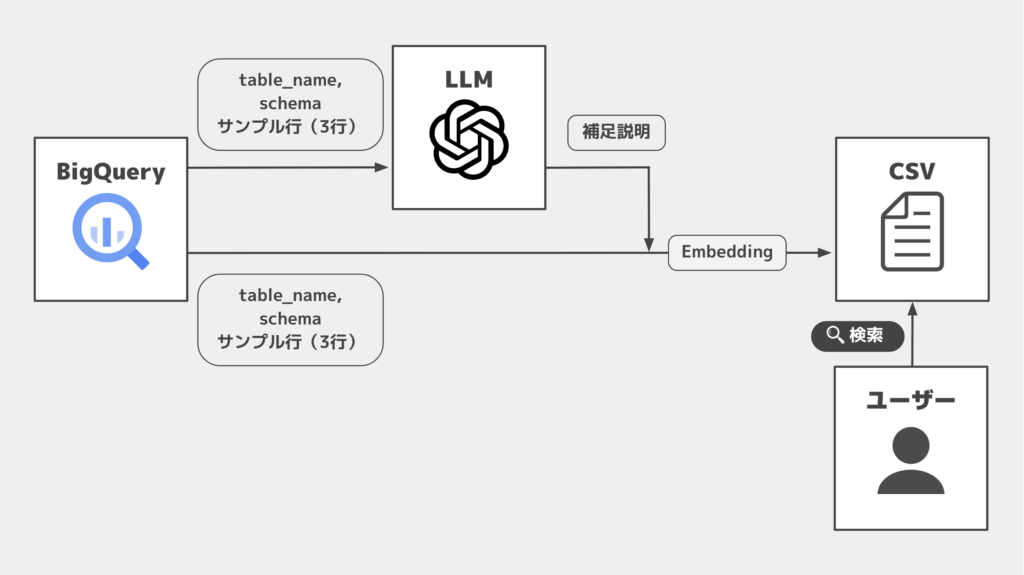
1. BigQueryのデータセットにあるテーブル情報を一括で取得
下記でデータセット内に存在する全テーブルの情報を取得します。
from langchain.sql_database import SQLDatabase
project_id = "bigquery-public-data"
dataset = "thelook_ecommerce"
sqlalchemy_url = f"bigquery://{project_id}/{dataset}"
db = SQLDatabase.from_uri(sqlalchemy_url)
dbの中には、各テーブルのCREATE文と3行のサンプル行が入ります。(下記はproductsテーブルの情報)
CREATE TABLE `products` (
`id` INT64,
`cost` FLOAT64,
`category` STRING,
`name` STRING,
`brand` STRING,
`retail_price` FLOAT64,
`department` STRING,
`sku` STRING,
`distribution_center_id` INT64
)
/*
3 rows from products table:
id cost category name brand retail_price department sku distribution_center_id
28646 8.73562987972319 Accessories 4 Panel Large Bill Flap Hat W15S48B (One Size Fits Most/Khaki) MG 19.989999771118164 Men 789334DE6DAA80D83AB4ACB6A4BF5AC7 1
28670 2.6759399153566363 Accessories Low Profile Dyed Cotton Twill Cap - Black W39S55D MG 6.179999828338623 Men E74843B99DA8B29775C6AA9080436844 1
28714 2.275000000372529 Accessories Low Profile Dyed Cotton Twill Cap - Khaki W39S55D MG 6.25 Men 8CA33D44648CC9FEECEF21E5A7123291 1
*/
2. 取得したテーブル情報にLLMで補足情報を加える
人間の入力に対して適切なテーブル情報を検索しやすくするため、今回はGPT-4にテーブルの補足情報を生成してもらいました。
生成結果はテーブル情報と合わせて、以降のステップのためにcsv形式で保存しておきます。
import pandas as pd
import openai
data_list = []
for t in db.get_usable_table_names(): # BigQuery上にあるすべてのテーブルを対象にする
try:
info = db.get_table_info([t])
response = client.chat.completions.create( # LLMで補足情報を追加
model="gpt-4",
messages=[
{
"role": "user",
"content": f"次のテーブルについて、内容と分析する際の利用用途を推測し、日本語でわかりやすく説明してください. ### table: {info}"
},
],
)
except:
print(f'failure: {t}')
continue
data_list.append({
'name': t,
'info': info,
'sub_info': response, # 補足情報
})
# 任意の方法で保存
df = pd.DataFrame(data_list)
df.to_csv('./tables.csv', index=False)
3. 作成したリストをDocument形式へ変換
検索のindexを作成する際ににはlangchain.scheme.Documentオブジェクトを生成する必要があり、今回は langchain.document_loaders.csv_loader.CSVLoaderを利用します。
from langchain.document_loaders.csv_loader import CSVLoader
file_path='./tables.csv'
loader = CSVLoader(file_path=file_path)
docs = loader.load()
4. DocumentをEmbeddingし、検索用のインデックスを作成
EmbeddingにはOpenAIのOpenAIEmbeddings、検索にはfaiss-cpuを使用しました。
import openai
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
faiss_index_path = "index_path"
embeddings = OpenAIEmbeddings(client=openai.ChatCompletion(model='gpt-4'))
faiss_index = FAISS.from_documents(docs, embeddings)
faiss_index.save_local(faiss_index_path)5. 検索
下記を実行すると検索できました。出力結果の整形すれば、社内で運用していけそうです。
import openai
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
faiss_index_path = "./faiss_index"
embeddings = OpenAIEmbeddings(client=client)
faiss_index = FAISS.from_documents(docs, embeddings)
faiss_index.save_local(faiss_index_path)▼出力結果(一部)
CREATE TABLE `products` (
`id` INT64,
...
`distribution_center_id` INT64
)
/*
3 rows from products table:
id cost category name brand retail_price department sku distribution_center_id
28646 8.73562987972319 Accessories 4 Panel Large Bill Flap Hat W15S48B (One Size Fits Most/Khaki) MG 19.989999771118164 Men 789334DE6DAA80D83AB4ACB6A4BF5AC7 1 ...
*/
append_info: このテーブルは、店舗の商品情報を表しているようです。
具体的なフィールドについて説明すると.....以上でステップ①は終了です。
STEP② プロンプトからGPTにSQLを生成させる
「生成させる」と表現していますが、実はLangChainにテーブル情報からSQLを生成してくれる枠組みが用意されていました。(さすが)
ということで、下記のコードを実行すれば完了です。
import os
from google.cloud import bigquery
from sqlalchemy import *
from sqlalchemy.engine import create_engine
from sqlalchemy.schema import *
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI, OpenAIChat
from langchain.agents import AgentExecutor
from langchain.sql_database import SQLDatabase
db = SQLDatabase.from_uri(sqlalchemy_url)
llm = OpenAIChat(temperature=0, model="gpt-4")
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
agent_executor = create_sql_agent(
llm=llm,
toolkit=toolkit,
verbose=True,
top_k=1000,
)
# run
agent_executor.run("2023年3月17日の商品ごとの売り上げを教えて")
実行すると下記のような結果が出力されます。もちろん運用までには細かなチューニングなどが必要になってきますが、要求に対してSQLを生成してくれるだけでなく、文法のチェックもしてくれてます。
▼出力結果(一部)
> Entering new AgentExecutor chain...
Action: sql_db_list_tables
Action Input: ""
Observation: order_items, takuto_test_table1, user_bet_hourly_and_daily, user_betting_daily, users
Thought:The 'order_items' table seems to be the most relevant one for this question as it might contain information about sales of products. I should check its schema to understand its structure.
Action: sql_db_schema
Action Input: "order_items"
Observation:
CREATE TABLE `order_items` (
`id` INT64,
`order_id` INT64 ...)
/*
3 rows from order_items table:
...
*/
Thought:The 'order_items' table has a 'created_at' column which likely indicates when the order was made. It also has a 'product_id' and 'sale_price' column which are relevant to the question. I will write a query to get the sales of each product on 2023-03-17.
Action: sql_db_query_checker
Action Input: "SELECT product_id, SUM(sale_price) as total_sales FROM order_items WHERE DATE(created_at) = '2023-03-17' GROUP BY product_id LIMIT 1000"
Observation: SELECT product_id, SUM(sale_price) as total_sales FROM order_items WHERE DATE(created_at) = '2023-03-17' GROUP BY product_id LIMIT 1000 ## ←生成されたSQL
Thought:The query syntax is correct. Now I will execute the query to get the sales of each product on 2023-03-17.
Action: sql_db_query
Action Input: "SELECT product_id, SUM(sale_price) as total_sales FROM order_items WHERE DATE(created_at) = '2023-03-17' GROUP BY product_id LIMIT 1000"
Observation: ...
> Finished chain.
最後に
今回は、自社のデータ構造をBigQueryから取得し、それをベースにしたSQLの生成にチャレンジしました。
検証を進める上で
- 生成されたSQLは、データスキャン量への配慮がされていない
- ユーザーがトークンの使用量を考慮せず、大量のリクエストを送ってしまう
などのリスクも見えてきており、社内での実用化までには出力の整形だけでなく運用ルールや細かなチューニングが必要になってきそうです。
また、課題と同時に、総合職の1年目でもモデルを動かしてチャレンジできる手軽さや進化のスピード感が、生成AIの秘めている可能性だと感じました。
今回のチャレンジをきっかけに、生成AIをはじめとした機械学習の効果的な活用事例を創出できるよう、WinTicketおよびCyberAgentを使って、引き続きチャレンジしていこうと思います!
ここまでお読みいただきありがとうございました!