
この記事は CyberAgent Developers Advent Calendar 2023 19日目の記事です。
本日はメディア統括本部 Data Science Center の山本が担当します。
サイバーエージェントではAzure OpenAI ServiceやGoogle CloudのVertex AIなど様々なクラウドサービスのプラットフォームを利用したコンテンツ生成のPoC作成やそれを発展させた形での実サービスへの展開を行なっております。
このようなプラットフォームは気軽にやりたいことを試せる点では非常に便利ではあります。
一方、APIリクエストへの即応性やコスト等々の観点で、画像生成や言語生成のモデルを、用意したマシンインスタンスに展開して推論を行いたい状況も存在します。
このとき問題になるのはマシンインスタンスのスペックです。
高性能なGPUが載っていて、CPU、メモリも十分というなら最高なのですが、やはりコストや調達の問題で妥協が必要なこともあるかと思います。
そこそこなマシンスペックでコンテンツ生成を…実はそのようなツールがいくつか存在します。
今回は大規模言語モデル(以下LLMと略記)に焦点を当てて、その推論ツールである llama.cpp を紹介します。
llama.cppとは?
llama.cppとはMeta社のLLMの1つであるLlama-[1,2]モデルの重みを量子化という技術でより低精度の離散値に変換することで推論の高速化を図るツールです。
直感的には、低精度の数値表現に変換することで一度に演算できる数値の数を増やすことで高速化ができるイメージです。
また、.cppと書かれていることからもわかるように推論箇所はC++で書かれています。
そのためAPI (C API)経由で他プログラミング言語から利用することが容易であるという特徴があります。
実際、README.mdから、Python、Go、Node.js、Ruby、Rust、C#/.NET、Scala 3、Clojure、React Native、Javaなどの多様なバインディングがあることがわかります。
余談ですが、レポジトリ名などからLllamaモデルだけ対応していると思われそうですが、他の一部LLMモデルにも対応しています。
LllamaじゃないLLMを何とか手元のパソコンで使いたいという時に、もしかしたらllama.cppが使えるかもしれないですね。
とりあえず llama.cppを試してみる
実は本Advent Calendarの1日目でも llama.cpp が出てきした。
こちらも面白い記事になっていますので併せてご覧いただければと思います。
今回はCPUのみのインスタンスを用いてCyberAgentLM2-7B-Chatの推論をやってみましょう。
設定は以下のとおりです。
- VM: Google Cloud の n2-standard-4 インスタンス (4 vCPU, 2 core, 16 GB memory)
- Image: Ubuntu 22.04 LTS
- Disk: 100GB
- llama.cppのリリース: b1620
llama.cppのビルド
ソースコードをダウンロードしてビルドを行います。
sudo apt -y update
sudo apt -y install build-essential gcc g++ make pkg-config libopenblas-dev python3-pip
# llama.cppのダウンロード
mkdir llama.cpp && curl -L https://github.com/ggerganov/llama.cpp/archive/refs/tags/b1620.tar.gz | tar zx -C llama.cpp --strip-components=1
cd ~/llama.cpp
# ビルド
make -j 4 LLAMA_OPENBLAS=1
# テストもしておきます
make test LLAMA_OPENBLAS=1
# ちょっと行儀よくないやり方 (仮想環境を用意しましょう)
pip3 install -r requirements-hf-to-gguf.txt
CyberAgentLM2-7B-Chatのダウンロード
対象のLLMをダウンロードします。
cd ~/
# モデル格納用のディレクトリ作成
mkdir -p models/hf models/gguf
# cyberagent/calm2-7b-chatのダウンロード
python3 -c 'import huggingface_hub; huggingface_hub.snapshot_download(repo_id="cyberagent/calm2-7b-chat", cache_dir="./models/hf")'
GGUF形式への変換
llama.cppではGGUF形式のファイルを読み込んで推論をするため、モデルファイルの変換が必要になります。
変換用のスクリプトを実行する前に、cyberagent/calm2-7b-chatの場合は Hugging Faceのモデルに変更が必要な箇所があります。
というのは、このモデルのトークナイザ(GPTNeoXTokenizerFast)の設定をそのままの形でGGUF形式に変換することはできないからです。
そのため、トークンとIDの対応関係のみ抽出してGGUF形式に変換できるように、語彙のファイル(vocab.json)を追加します。
まず、Hugging Faceのモデルが格納されているパスに移動します。
cd ~/models/hf/models--cyberagent--calm2-7b-chat/snapshots/f666a1e43500643cb3ff8c988a6ea5b56afe934a
ここで以下のPythonコードを実行します。
from transformers import AutoTokenizer
import json
with open("./config.json", "r") as config_file:
config = json.load(config_file)
tokenizer = AutoTokenizer.from_pretrained("./")
vocab = tokenizer.vocab
# トークナイザの語彙数よりもInput embeddingsのサイズが大きくなっていることがあります。
# そのような場合はトークナイザの語彙を出現しないトークンでかさ増しします。
# これを行わないと次工程のGGUFファイル作成でエラーになります。
# https://huggingface.co/bigscience/bloom/discussions/120
if config["vocab_size"] > tokenizer.vocab_size:
# U+2581 U+2581
META_TOKEN = "▁▁"
for i in range(config["vocab_size"] - tokenizer.vocab_size):
token = "{}{}".format(META_TOKEN, i)
vocab[token] = tokenizer.vocab_size + i
with open("vocab.json", "w") as vocab_file:
json.dump(vocab, vocab_file)
これでvocab.jsonファイルが作成できました。
あとは変換スクリプトを実行してGGUFファイルを作成します。
cd ~/llama.cpp
python3 convert.py --vocabtype bpe --outfile ~/models/gguf/calm2-7b-chat.gguf ~/models/hf/models--cyberagent--calm2-7b-chat/snapshots/f666a1e43500643cb3ff8c988a6ea5b56afe934a
量子化したモデルの作成
推論を高速化させるためにモデルに量子化を施します。
量子化については選択肢がたくさんあるのですが、ここでは決め打ちでq5_k_mを使うことにします。
あと、この処理は少し時間がかかります。
./quantize ~/models/gguf/calm2-7b-chat.gguf ~/models/gguf/calm2-7b-chat-q5_k_m.gguf q5_k_m
推論を試してみる
では、適当なプロンプトを入れて推論させてみましょう。
./main -m ~/models/gguf/calm2-7b-chat-q5_k_m.gguf -n 500 -p "USER: AIによって私達の暮らしはどのように変わりますか?
ASSISTANT: "
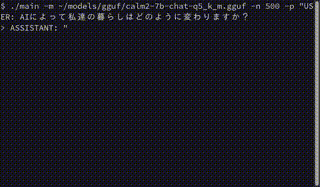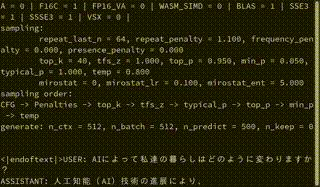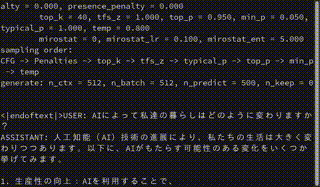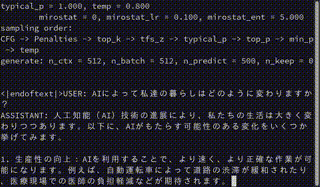
以下は実行画面のキャプチャです。
モデル読み込みこそ時間がかかるものの、テキスト生成についてはCPUのみなのに意外とサクサク出力していると感じるのではないでしょうか?
量子化の設定について
先ほどの実行例では量子化の設定をq5_k_mとしましたが、llama.cppでは様々な選択肢があります。
このオプションは q[①何ビットの量子化なのか?]_[②量子化のやり方]_[③出来上がるモデルのサイズ] といった形式になります。
①②のペアと③の順番で見ていくことにしましょう。
①何ビットの量子化なのか? と ②量子化のやり方
LLMの中身はざっくりいうと(MLフレームワーク文脈での)テンソルの集まりとそれらの演算方法が載っているものになります。
llama.cppでの量子化は、一部のテンソルに対してその要素である数値表現の精度を落とした新たなテンソルを作って組み換えていくような処理になっています。
より正確には、取り出したテンソルのメモリ上での数値表現(配列)に対して、固定長の部分配列をそれぞれ取り出して変換処理を施します。
これによって、部分配列の数値表現が実数値から整数値に変換されるのと、整数値と実数値を相互に変換させるために必要なデータが作成されます。
変換された整数値が何ビットなのかが①に対応します。
ちょっとわかりにくいので、①が8、②が0 (後で説明しますがAbsmax quantizationと呼ばれる量子化手法です)の例を示します。
この場合、llama.cppではテンソルのメモリ上での数値を32個ずつ取り出して量子化を施します。
その結果は以下のような構造体で表されます。
#define QK8_0 32
typedef struct {
ggml_fp16_t d; // delta
int8_t qs[QK8_0]; // quants
} block_q8_0;
qsが元の実数値の配列を変換したものになります。
int8_tなので8ビットに切り詰められていることがわかります。
なお、dは整数値と実数値の相互変換に必要なパラメータです。
このように8ビット量子化といっても付加情報が入るので、例えば16ビットの実数表現のテンソルを8ビット量子化してもぴったり半分のデータサイズにならないことには注意が必要です。
次に②の量子化のやり方について示します。
以下に簡単にまとめておきます。
-
- 0: Absmax quantization
- 元の実数値の配列のうちで最大値を取るものが、変換後の整数値の範囲で最大値を取るように線形変換するもの。
- 1: Zeropoint quantization
- 元の実数値の配列のうちで最大値・最小値を取るものが、変換後の整数値の範囲でそれぞれ最大値・最小値を取るように線形変換するもの。
- k: 非線形量子化の何か (k-quants)
- コードの精査が間に合わず特定できなかったです( ; ; )
ちなみにllama.cppではこのやり方をオススメしているような雰囲気があります。
- コードの精査が間に合わず特定できなかったです( ; ; )
- 0: Absmax quantization
③出来上がるモデルのサイズ
①と②はLLMというよりは機械学習に共通する設定項目でした。
一方、③はLLMのアーキテクチャーに注目して特定の役割があるテンソルについて緩めの量子化にするかどうかを設定するものです。
③がsの場合はなるべく指定どおりのビット数の量子化をかけることでモデルのサイズを小さく(small)する、mやlの場合は特定の条件下ではより大きめのビット数の量子化をかけるのでサイズが中(medium)や大(large)になるみたいな設定です。
例えばLlamaの場合はattn_v.weightの名前が付くテンソルがたくさんありますが、③をmにすると入力層と出力層に近いところにある該当のテンソルは指定より大きめのビット数で量子化されるみたいなイメージです。
ただし、どの条件で緩めるかについてはかなり細かいヒューリステックスが入っています。
実装はget_k_quant_type関数にあるのですが、ややこしい条件分岐があるのでコードの深追いはしないほうがよいかなと思います。
できあがったモデルに対してquantize-statsコマンドを実行して内部のテンソルの数値型を確認したほうがわかりやすいです。
現実的にはどのように設定すればよいのか?
現実的には、量子化の設定を変えてモデルを作成して、推論の応答速度や生成文の品質を確認することになるかと思います。
その上で①②③のどれを積極的に変えるべきかというと①のビット数をオススメします。
k-quantsの実装のPull Requestにいろいろな量子化の設定でのパフォーマンス結果があるのですが、①を変えると、Perplexity(言語生成の性能を測る1指標。基本的に小さいほうがよい)やモデルサイズへの影響が大きく出ています。
そのため、①を最初に変えて、ちょうどよい値の前後に関して③モデルサイズを変更していくのが探索効率としてはよさそうです。
なお、②量子化の方法についてはk固定でよいのではないかなと思います。
先のPull Requestを含めいくつかのllama.cppのベンチマークを確認したのですが、②をkに設定したほうが同じぐらいのモデルサイズであればPerplexityを低く抑えることができているからです(もちろんこれは元のモデルやテストデータ依存になるので余力があれば確認したほうがよりよいです)。
おわりに
本記事ではLLMを量子化することで推論の高速化を測るツールであるllama.cppを紹介しました。
今回はllama.cppの量子化の設定オプションを中心に解説しましたが、ツールの機能としては他にもLoRAによるファインチューニングやWebAPIサーバ構築なども存在していてアプリケーションに繋げやすそうな印象があります。
この辺については日本語や英語での解説ブログがいくつかありますので興味があればご参照ください。
それでは引き続きCyberAgent Developers Advent Calendar 2023をお楽しみください( ^_^)/~~~