
この記事は CyberAgent Developers Advent Calendar 2023 20日目の記事です。
はじめまして。AI事業本部でMLエンジニアをしている稲垣です。
現在は極予測LPという、「AIを活用しランディングページの効果の事前予測を行い、広告効果を最大化する」を目指すプロダクトに携わっています。本プロダクトでは画像やテキストなどマルチモーダルなデータを扱う特性があるため、直近ではVLM(Visoin and Language Model)の検証および研究開発を担当しています。
この記事では、VLMとは何か、その先端研究の紹介、それらの評価について議論しつつ、生成AI全般のビジネス応用の壁についての考えをまとめていきます。
前提知識 : VLMとは?
VLM(Vision and Language Model)とは、画像とテキストを複合して扱うモデル全般を指す言葉です。
VLの概念がそもそも幅広いのでもう少し噛み砕くと、VLは「理解」と「生成」の大きく2つに分けることができます。
- 画像 / テキストを複合した理解
- 画像↔テキスト検索 : 曖昧な単語から近い画像を探せる
- 画像への質問に対して回答を選ぶ etc…
- 画像↔テキストの生成
- 画像から詳細な説明や、状況を理解した上でストーリーを生成
- テキストに忠実な画像の生成 etc…
直近では、画像生成ではDALL・E 3やStable Diffusion, 画像からのテキスト生成ではGPT-4VやGeminiなど、様々な企業がこうしたマルチモーダルなモデルを構築/サービス化しています。
本記事ではこの中でも特に画像からのテキスト生成について、そして生成AIのビジネス応用について焦点を当てていきます。
画像を見て喋るAI、LLaVAの紹介
昨今LLMの発展に伴い、LLMに視覚を与えることができるのではないか?というモチベーションを基に、Image-to-Text(画像からのテキスト生成)の研究が盛んに行われています。GPT-4VやGeminiなどを実際に触って、画像理解力や言語化能力がかなり高いことを実感している方も多いのではないでしょうか。
本セクションでは、ローカルで動かせるImage-to-TextモデルのLLaVAについて、その仕組みを概説していきます。
LLaVAによる画像を加味した対話の例
実際に画像を加味した対話をLLaVAとしている様子を見てみましょう。以下の画像をご覧ください。
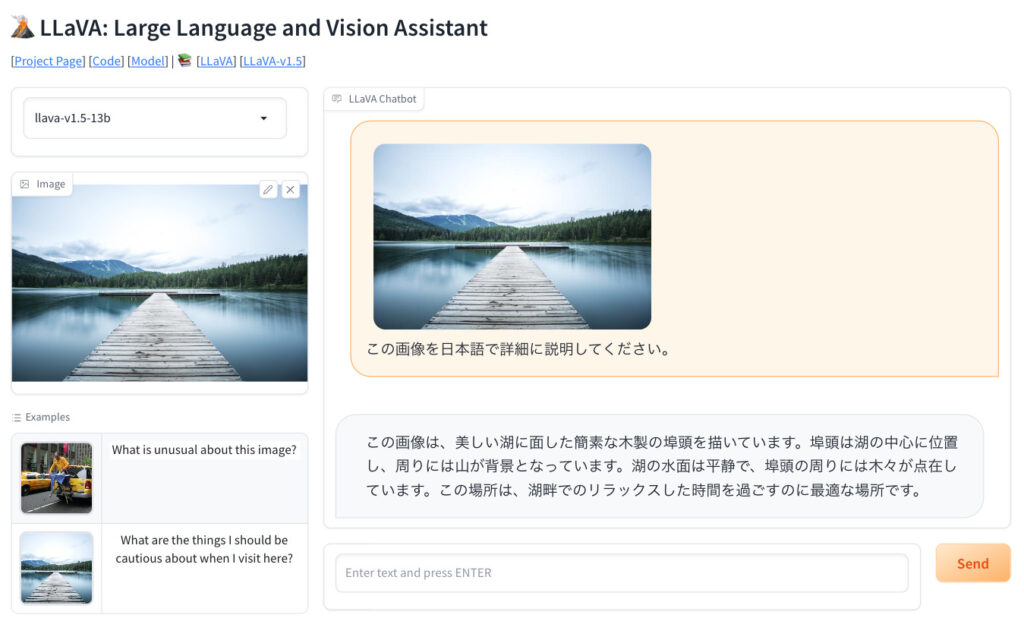
湖の橋の画像と「この画像を日本語で詳細に説明してください。」は筆者が入力したもので、その下の説明がLLaVAの出力です。非常に詳細に説明することができています。
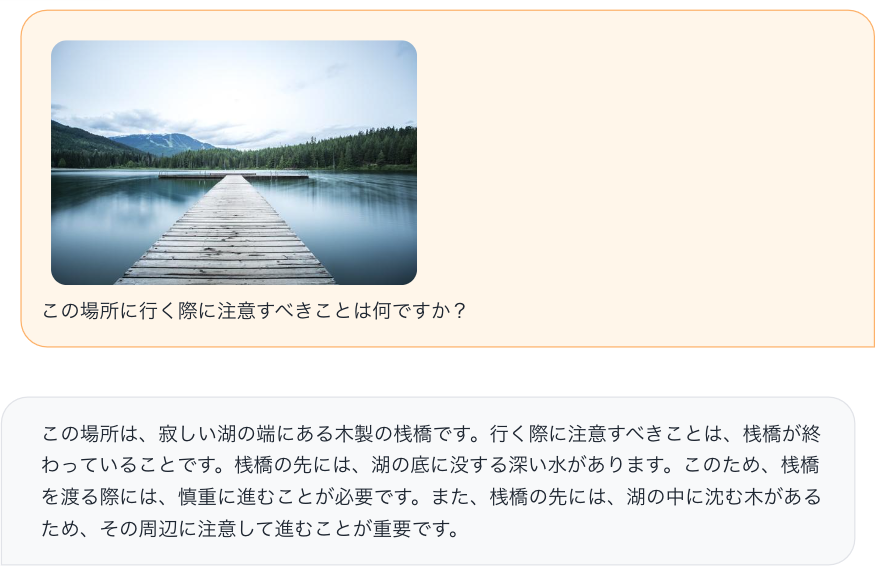
こちらは「注意すべきことを教えてほしい」と聞いてみましたが、それなりに妥当な返答を生成できていそうです。確かに画像をよく理解して回答しているように見えますが、実際どのような仕組みになっているのでしょうか?
※ こちらから好きな画像で簡単に試せます → https://llava-vl.github.io
LLaVAの仕組み
LLaVAは簡単に言うと、LLMに対して画像の特徴も入力できるような構造にして、画像と対応するテキストで学習することで画像の理解とそれを元にした生成を可能にするモデルです。
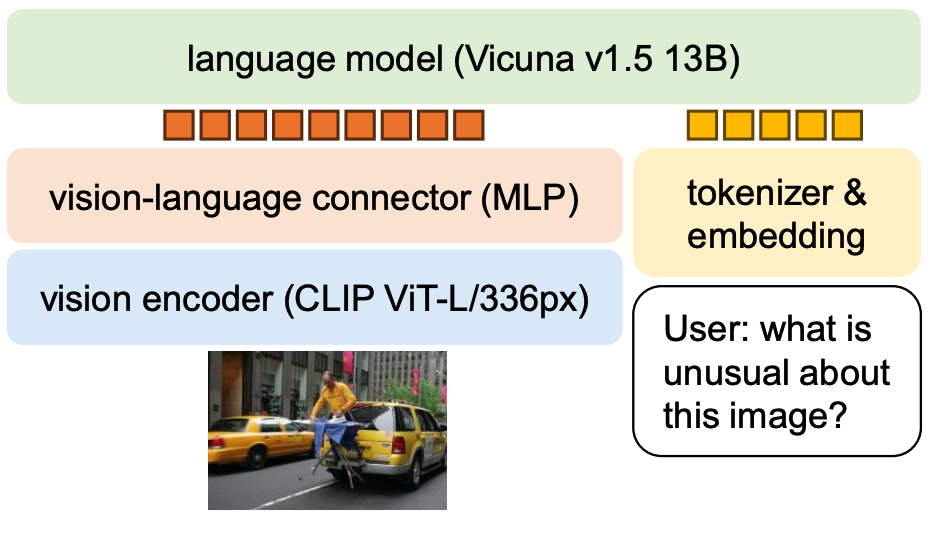
このモデルは大きく分けて①画像を数値に変換するモジュール, ②LLM, ③その間を繋ぐ変換モジュールの計3つで構成されます。llava-v1.5-13bというバージョンでは、①CLIP, ②Vicuna-13B, ③MLPが使用されていますが、それぞれの詳細な仕組みを深く知りたい方は各種文献を参照いただければと思います。
ここでは、画像を扱うことが得意なモジュールを使ってLLMに視覚情報を与えてるんだなという理解で十分です。
LLaVAの評価
評価においてはベンチマークデータという評価用に構築されたデータセットが使用されます。LLaVAでは12個のベンチマークデータを用いて、既存研究を上回る性能を出したことを定量的に測っています。
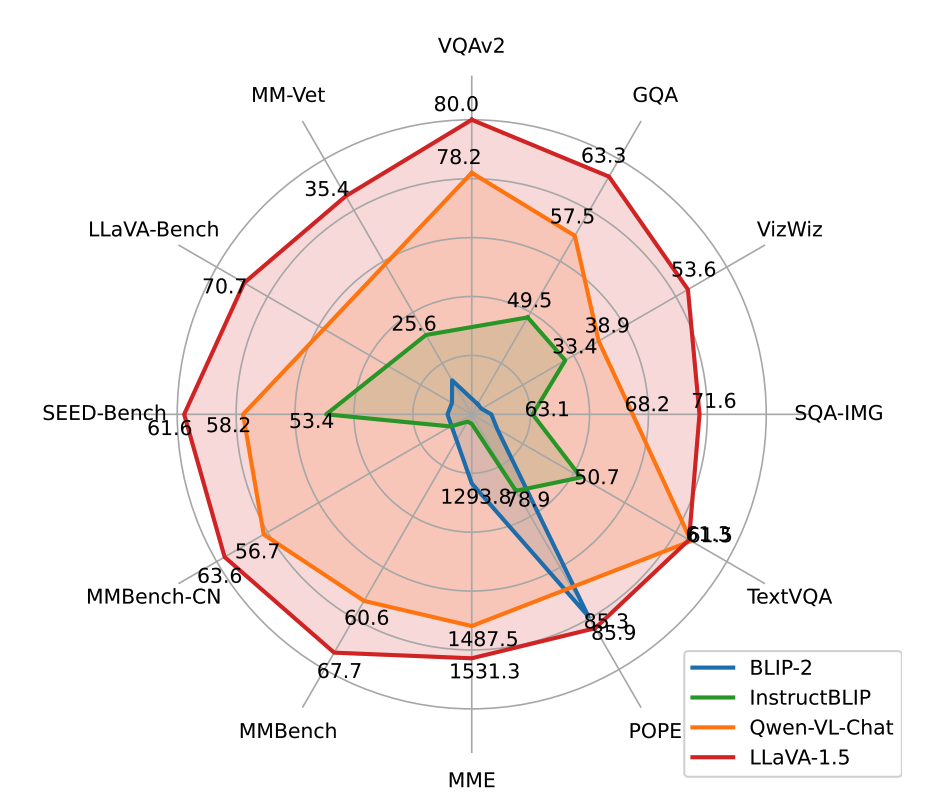
LLaVAが強いことは何となく分かりましたが、実際どのように評価しているのでしょうか?ベンチマークの1つであるMMBenchについて少し見てみましょう。
MMBench
MMBenchでは、画像と質問と選択肢(2~4択)が与えられ、モデルが生成した回答の正確さで評価を行います。以下はMMBenchに含まれるデータの一部です。


これらに正確に答えるためには、画像と質問に対する理解力、そして理解を元に何かを考える推論力が求められることがわかりますね。このような評価においてもLLaVAは高い精度を誇っているという訳です。
以上、Image-to-Textの代表的なモデルであるLLaVAを紹介しました。
このような画像に対する高い理解力と推論力を見ると、様々なビジネス応用がすぐにでも実現しそうですが、実際の活用までにどのような障壁が待ち受けているのでしょうか?
生成AIの評価の現状とビジネス応用の壁
さて、少し思い出していただきたいのですが、皆さんは湖の橋の画像に対するLLaVAの生成例を見てどう思いましたか?
ここで謝らなければならないのですが、筆者は「それなりに妥当な返答を生成できていそう」と言いました。
“それなり”に”妥当な”返答を生成”できていそう” …?
何を持ってして、それなり/妥当/できていそう、という言葉を並べたのかと思った方も多いのではないでしょうか。どのような観点でそう思ったかが曖昧すぎるし客観性に欠けていますよね。
ChatGPT等のサービスも例に漏れず、「なんか良さそうだしすごそう」まで触って実感できる方は多いのですが、そこまでで終わってしまっていませんか? それは「生成AIの出力に対する評価が難しく曖昧なために使いづらい」という点が大きく関係していると考えられます。
なぜベンチマークデータは選択肢の形式が多いのか?
先ほどのLLaVAのセクションではMMBenchによる評価を紹介しましたが、他のベンチマークデータにおいても選択式が主流となっています。ではなぜ選択式になっているのでしょうか?
それは、生成された回答のテキストが正解かを自動で測ることが難しいからです。

例えば、上記の画像で「Q: この画像に写っている人は何を考えているでしょうか? A: 赤い花の華やかな香りにうっとりしている」と用意されたQAペアに対して「このバラめっちゃ良い匂いだと思っている」と回答したとします。少しラフな回答ですが、間違いだとは言い難いですね。
このように、意味は同じだけど違う言い回しをしている場合に、正解かどうかを自動で測ることが極めて困難であるため、あえて自由記述を避けて選択式にしているという現状があります。
※ 余談ですが、LLaVA v1.5の論文では性能が大幅に上昇したことについて、データによる寄与が大きい旨を述べています。
As the initial work of visual instruction tuning, LLaVA has showcased commendable proficiency in visual reasoning capabilities, surpassing even more recent models on diverse benchmarks for real-life visual instructionfollowing tasks, while only falling short on academic benchmarks that typically require short-form answers (e.g. singleword).
…
To address this, we propose to use a single response formatting prompt that clearly indicates the output format, to be appended at the end of VQA questions when promoting short answers: Answer the question using a single word or phrase. We empirically show that when LLM is finetuned with such prompts, LLaVA is able to properly adjust the output format according to the user’s instructions…
(LLaVAは視覚的推論能力において称賛に値する熟練度を示しており、実際の視覚命令追従タスクの多様なベンチマークにおいて、より新しいモデルをも凌駕している一方、一般的に短い形式の回答(例えば単一単語)を必要とする学術的ベンチマークでは、わずかに及ばなかった。
(中略)
これに対処するため、「Answer the question using a single word or phrase.」というような出力形式を明確に示す単一の解答形式プロンプトを使用することを提案する。このようなプロンプトでLLMを微調整することで、LLaVAはユーザーの指示に応じて出力形式を適切に調整できることを実証する。) (Haotian Liu, p.2 訳は引用者による)
つまり、短い生成のみを行う選択式のベンチマークにも対応できるように学習データを調整したということです。様々な回答形式への対応力を上げたわけですね。(もはやベンチマークのハックでは?とも思いますが。。。)
評価の難しさこそ最大の壁?
前述のベンチマークデータのように、「生成AIの評価やリスクの見積もりが難しいために、インパクトは大きそうだがビジネス活用に踏み切れない」という点がビジネス応用の最大の障壁になっているのではないかと感じています。(コストの話もありますが…)
例えば、ユーザーの自由な質問に答えるチャットボットを考えた場合、チャットで送れる文字数/情報の正確さ/ユーザーの不快にならない言い回し/不適切発言の頻度などの評価項目が挙げられます。しかしこれらの項目は自動で評価できるものもあれば人手に頼らざるを得ないものもあり、その設計と評価の実施でかなりのコストを払うことが想像できるため、道のりが遠く見えてしまいます。
※ 日本語言語モデルにおけるベンチマークやLLM評価における留意点などをまとめたわかりやすい記事はこちら
→ 【AI Shift Advent Calendar 2023】大規模言語モデル評価大全
CAにおける生成AIのビジネス応用で重要だったこと
AI事業本部では極予測AIを筆頭に、生成AIの研究開発およびプロダクト導入を積極的に行っています。


では、このように生成AIをプロダクトにうまく応用できているのはなぜでしょうか?
それは、「とにかく試してアウトプットを出す」「ビジネス的なフィードバックをもらいつつPDCAをとにかく早く回す」という文化が大きく関係していると考えています。最初は規模が小さくても構わないので、プロトタイプを作ってフィードバックをもらう。そのフィードバックをもとに評価とリスクの見積もりを並行して考えていく。このスピード感がビジネス応用がうまくいっている1番の要因だと現場目線で日々感じています。
最近では生成AIの発展が早いこともあり、明日には考えてた懸念点を克服したモデルが出るかもしれない状況です。事前のモデルの評価/リスクの見積もりももちろん大事ですが、とにかく動かしてみる精神は今後も大事にしたいポイントです。そのアウトプットがビジネス上インパクトが大きいと示すことさえできれば、コストをかける価値があるかの判断材料にもなり得るということです。
また、論文等におけるベンチマークデータは、あくまで学術的な観点からモデルのある側面を評価しているに過ぎないということを忘れてはいけません。「最高性能の新モデル」という言葉が日々飛び交う昨今だからこそ「どのようなモデルか?何を評価して性能が良いと主張しているのか?どの要素がその性能に寄与しているのか?」ということを理解しインプットし続けること、その上でビジネス上の制約や事業指標の向上を満たすようなモデル選定と評価の設計を状況に応じて適切にできる力がこれからは求められていくと思います。
まとめ
この記事では、VLMの代表的なモデルとその評価方法を紹介し、生成AIの評価の難しさとビジネス応用において重要だと感じることについてまとめました。
「生成AI、可能性はありそうだけどイマイチ具体的な案が詰まらないんだよなぁ…」と思っているそこのあなた。今一度、「事業上の指標との結びつきやその評価」と「生成AIを本当に使う必要があるのか?(コストも含めて)」という視点で見直してみると、新たな発見があるかもしれませんね。
私個人としてもこのような視点を常に忘れずに、今後とも生成AIの研究開発に取り組み、ビジネス応用までの架け橋になりたいと思っています。そして、弊社が日本で一番AIを活用するトップランナーであるという状態を目指し、そこに貢献していきたいと思っています。