
この記事は CyberAgent Developers Advent Calendar 2023 21日目の記事です。
こんにちは、CyberAgentのシステムセキュリティ推進グループ(以下、SSG)に所属している小笠原です。
本記事では生成AIをセキュリティの業務に導入し運用課題を改善していった取り組みについて共有させて頂きます。
生成AI x セキュリティ
生成AIというテクノロジーはセキュリティ業界でも非常に注目されています。
今年の10月に発表されたガートナーのセキュリティハイプ・サイクルでは、黎明期に「サイバーセキュリティ向け生成AI」が登場しました。
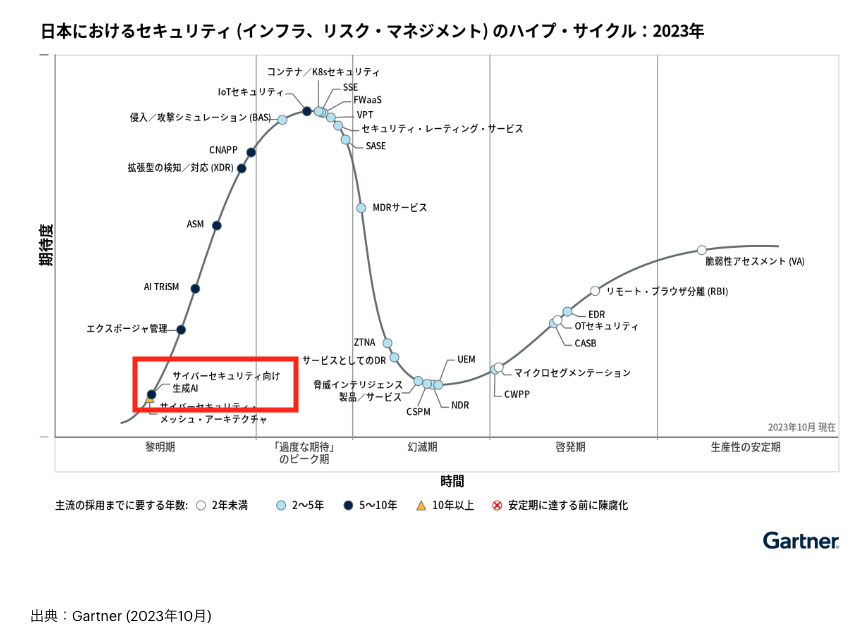
私が所属している技術チームでは、「テクノロジーでセキュリティの課題解決を行う」ことをミッションにしているので、こういった技術を積極的に検証していきたいと考えています。
特に今回は以下の課題に対して生成AIを活用できないかを検証しましたのでご紹介します。
- セキュリティエンジニアの属人化の問題
- セキュリティ対応の品質アップやスピード向上
セキュリティ対応の課題
私達SSGという組織はCyberAgentグループのさまざまな部署、グループ会社からセキュリティの相談を受けたり、セキュリティインシデントの対応支援を行っています。
セキュリティの相談といっても取り扱う領域が幅広く、かつ、それぞれ専門性も高いため、SSG内には各領域のスペシャリストが所属しており、チーム内でコミュニケーションを取りながら対応にあたります。
また、セキュリティ以外にも法律やプライバシーに関するお問合せなんかも来ることがあります。
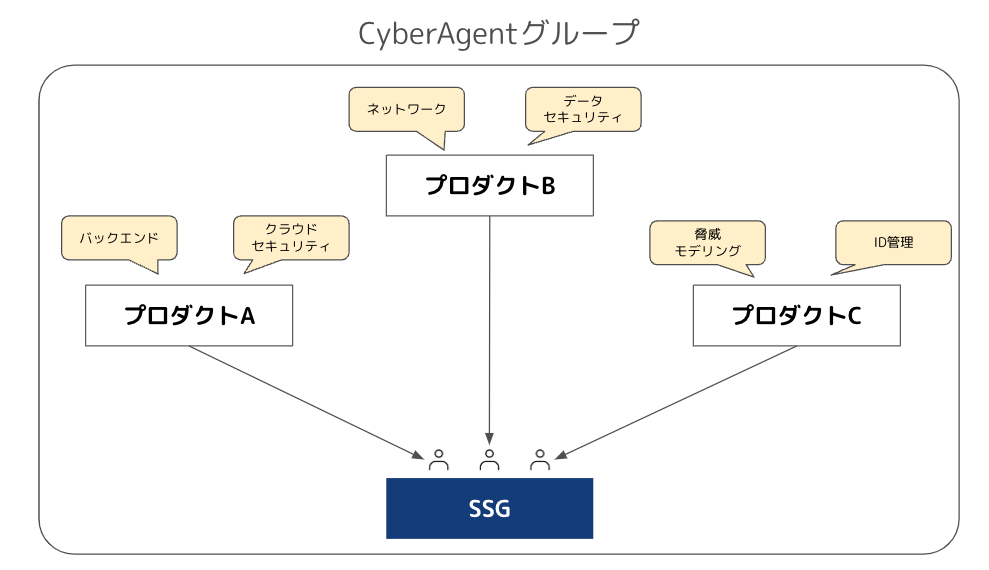
組織内でも役割分担をしているのですが、あまりにも広範囲の分野になるため、しだいに属人化の問題が発生し、現状を全て把握できる人間はいなくなってきました。
担当者の経験にもバラツキが出始めると、対応品質や対応スピードも安定しなくなる可能性があります。最終的にはプロダクト側に誤った対応をしてしまったり、現場が混乱するといった事態は避けなければなりません。
生成AIを導入するプロセス
ChatGPTの登場を筆頭に、専門のデータサイエンティストではないエンジニアでもAI技術が扱いやすくなり一気に広がりを見せました。今年の年始頃から弊社でも各部署から生成AIに関する相談が急増しました。
生成AIを扱う上で機密情報の問題や、敵対的プロンプトなどのセキュリティリスクを考慮しなければなりません。
私達セキュリティの組織もそういったテクノロジーを実際に使って知見をためていこうという流れもあり、まずは、私達が運用している既存のセキュリティソリューションに組み込むところから始めました。
セキュリティのモニタリングツールRISKENに生成AIを導入
今年の4月頭に、私達のチームで開発・運用しているRISKEN(OSS)というクラウドセキュリティの監視システムにOpenAIのAPI機能を組み込みました。
RISKENはセキュリティ関連のデータを継続的に収集し解析を行います。問題が発生した場合には関係者に通知され通知内のリンクからRISKENの詳細画面に遷移することができます。しかし、RISKENの画面では英語のメッセージとデータ解析結果(JSON)を雑に貼り付けたようなUIになっており、非常に見づらくユーザ体験があまりよくありませんでした。(何を伝えたいのかが分かりづらい)
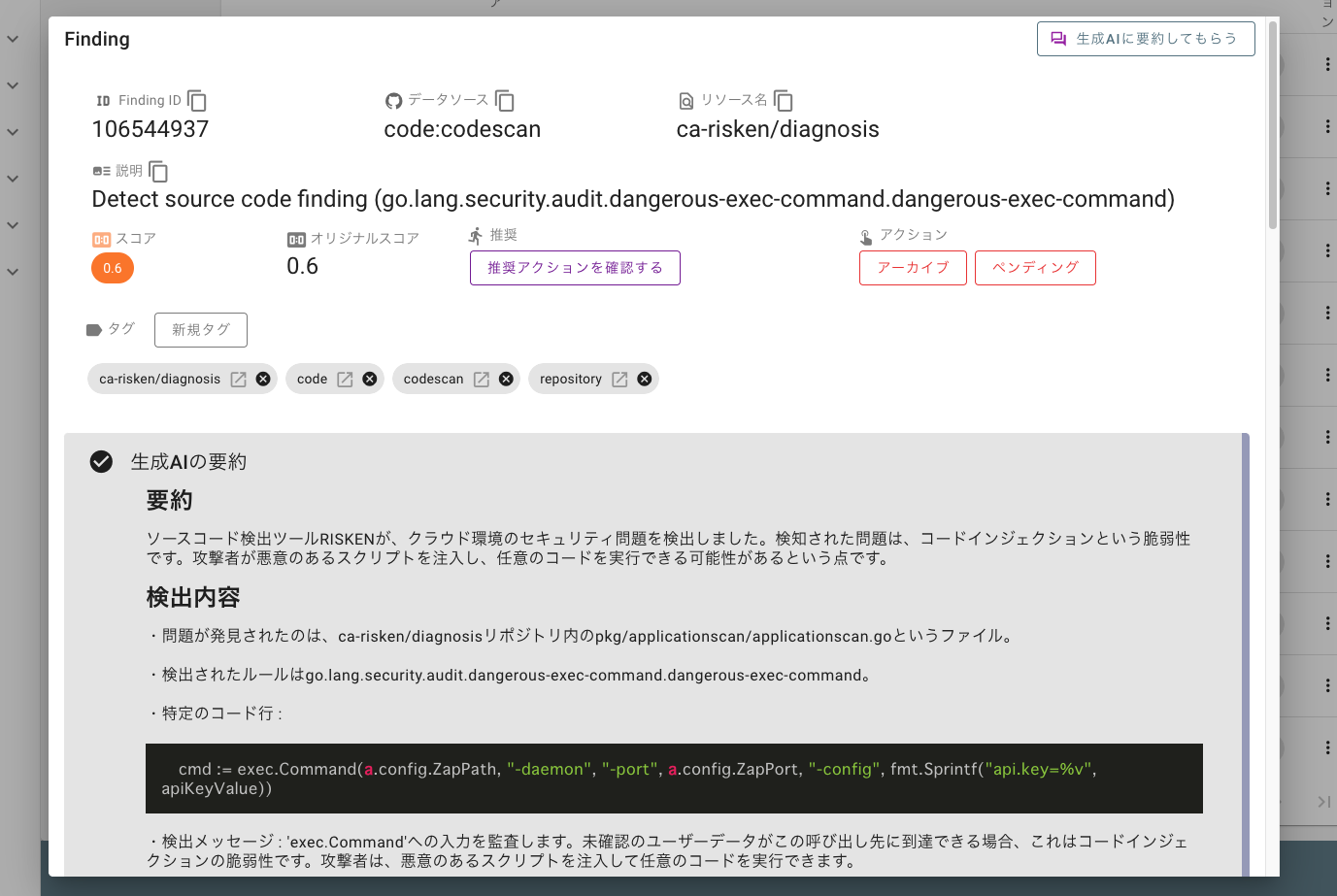
例えばこちらはGitHubのソースコード解析データになりますが、内容を生成AIに要約させることにしました。
- どういった問題なのか?
- 何をしないといけないのか?
- 対応の優先度は高いか?
現場のエンジニアは解析結果の理解が早まり次に何をすべきかを判断できるようになりました。
RISKENの他にも脅威検知の基盤に生成AIに検知内容を解析する仕組みを導入したりと様々なシーンで活用されはじめました。
手応えアリ
RISKEN等の生成AI導入は現場のエンジニアの方々からも非常に高評価の声を頂き、強力なツールだということを実感しました。
また、セキュリティ系ツールの以下の特性ととても相性が良いことがわかりました。
- スキャナーの解析結果はツールによってスキーマがバラバラだがどんな入力値でも生成AIで処理できる
- 出力結果はだいたい英語だが、翻訳も一緒にしてくれる
セキュリティエンジニアの属人化問題
最後に、冒頭の課題でも触れましたが、「属人化」の問題をどう緩和していくかを考えます。
SSGではセキュリティ対応業務の中で以下のようなツールを利用しているので、これらの知見を活かせないかと考えました。
- ドキュメント管理(DocBase)
- 脆弱性診断のチケット管理(JIRA)
- お問合せ対応のタスク管理(ClickUp)
社内のAIセキュリティコンシェルジュ
いわゆるRAG(Retrieval Augmented Generation)を利用した社内のAI Botを作成しました。
セキュリティの質問・相談に対して、社内のガイドラインや過去の対応履歴をコンテキストに含めて回答を生成します。SSGではドキュメントをしっかりと残す文化があるためこの資産を有効活用でき、自分の得意領域ではない経験の浅い分野のトピックに関してサポートしてくれます。
また、RAGはFine-Tuningなどの学習がなくても利用できるため、AIの専門でない私でも実装することができますし、MLOpsの運用コストを抑えられます。
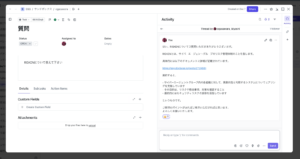
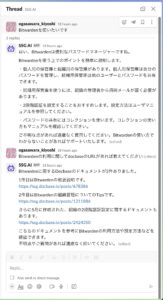
作成したRAGのアプリケーションは3種類のユーザインターフェースを提供します。
- WEBチャット: ChatGPTのようにブラウザでチャットができます。(内部向けにプロンプトをチューニングする機能を追加しました)
- ClickUp: SSGのお問合せはClickUpで管理するケースが多いですが、webhookに対応していて、タスクの内容から生成AIがコメントでアドバイスをしてくれます
- SlackチャットBot: Slackで気軽にチャットができるようにしています(WEBチャット同様、回答はstremingでレンダリングされます)
アーキテクチャ
Amazon Qの登場により、今後はフルスクラッチでこういったRAGのアプリを作成する機会は減るかもしれませんが今回は自分で作ってみました。
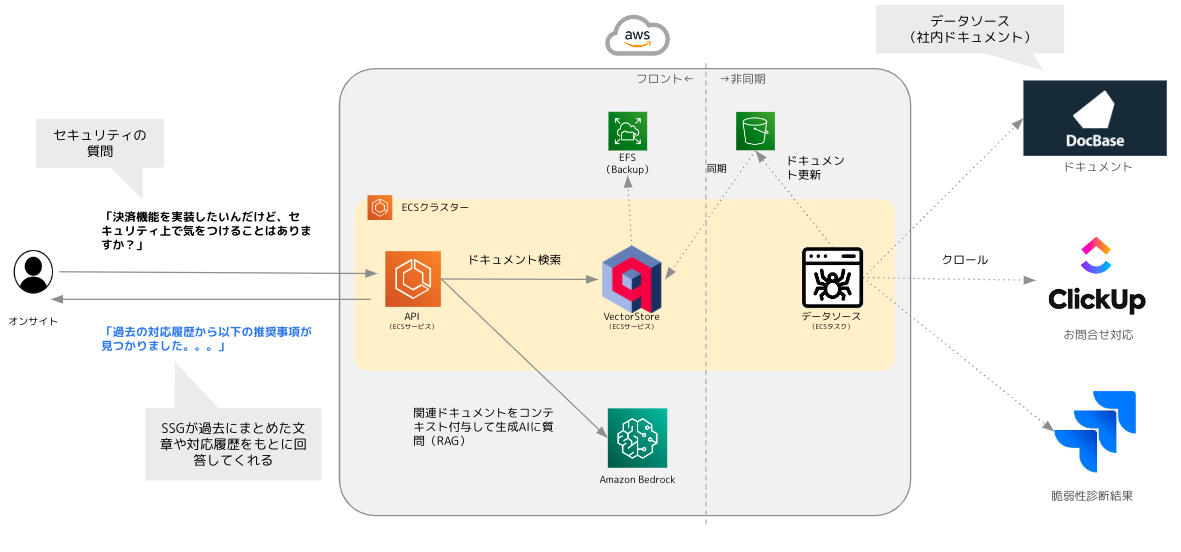
主なコンポーネントは以下になります。
| 項目 | 詳細 |
|---|---|
| APIサービス | WEBチャットや、Slack、ClickUpからのリクエストエンドポイントです。 |
| VectorStoreサービス | ドキュメントを検索するためのVectorStoreコンポーネントです。 |
| DataSourceバッチ | ドキュメントの更新や同期を行うためのバッチ(ECSタスク)です。 |
| Amazon Bedrock | APIを通じて主要な基盤モデルを利用できるフルマネージド型サービスです。生成AIによる回答や、VectorStoreへの保存検索時のEmbedding処理で利用します。 |
この構成に至るまでいくつかの試行錯誤がありました。工夫した点を以下にまとめます。
- 社内のドキュメントを扱うということもあり、可能な限りAWS内に閉じた構成にしました
- 生成AIで使用したモデルは日本語にも対応できるanthropicのClaude2.1モデルを採用しました
自然言語で関連ドキュメントを検索できるVectorStore
自然言語から関連するドキュメントを検索するためにVectorStoreというコンポーネントを構築しています。ベクトルデータでドキュメントを保存・検索することで非常に高速に動作します。
ここは色々試行錯誤があって最終的にQdrantというツールを選択しました。
- OSSのVectorStore(Qdrant Cloudというマネージドサービスもある)
- Rust製で非常に高パフォーマンス
- Qdrant公式がGoのSDKをサポート(バックエンドは全てGo言語なので採用した理由の最も大きい要因)
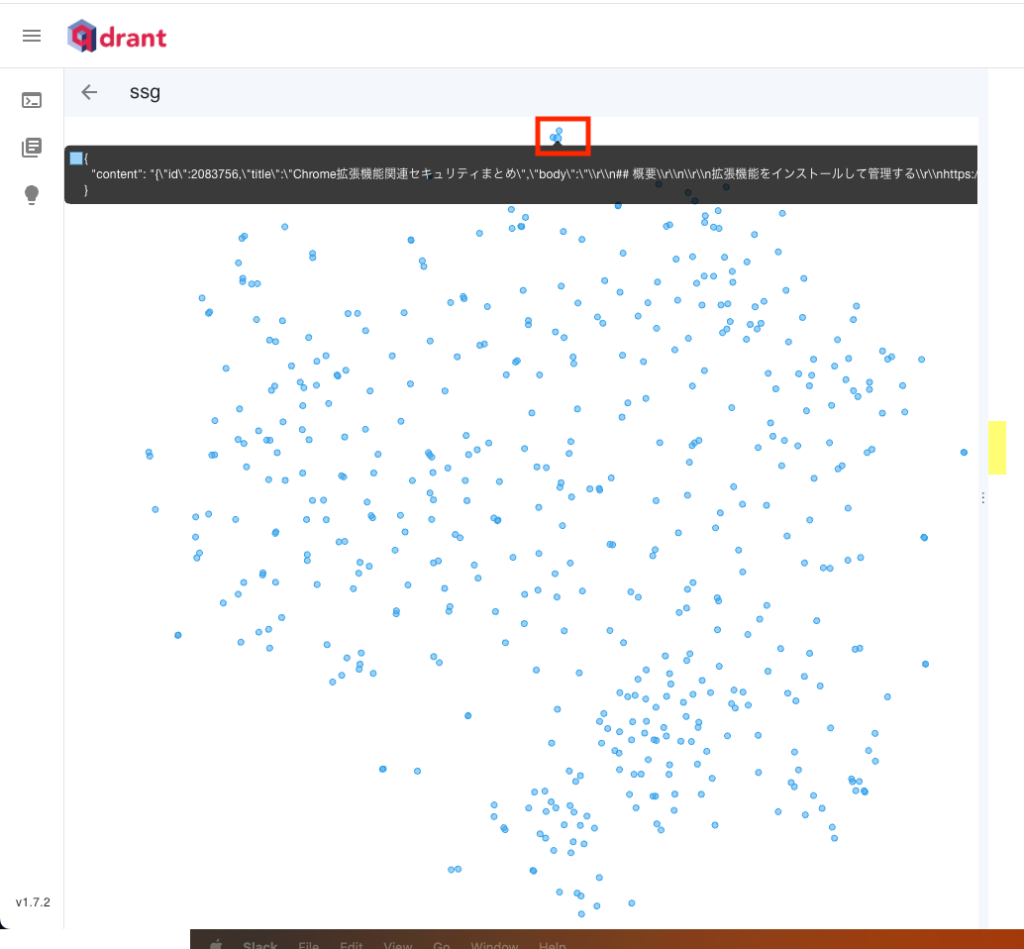
Qdrantコンテナを起動すると保存されたドキュメントのベクトル情報を管理画面で可視化することができます。一つ一つの点(point)がドキュメントデータに対応していて、それぞれ1536次元の座標のような数値データ(ベクトル)を持っています。例えば上記の赤枠をマウスオーバしてみると「Chromeブラウザのセキュリティ」関連のドキュメントが近くに複数個あることが確認できました。(2次元のようにみえますが実際は非常に高次元な世界)
テキストのドキュメントデータの検索においてはコサイン類似度というアルゴリズムを採用しました。コサイン類似度は2つのベクトル間(検索キーワードとドキュメントの内容)の類似度を測定できます。これはベクトルの向きの近さを基準にしており、ベクトルの大きさ(長さ)は考慮しないため、ドキュメント検索のユースケースには最適です(類似度の結果は-1〜1の範囲で返却されるので、あまりに関連性の低いドキュメントは除外することも可能です)。
実際にこのアルゴリズムに変更したところドキュメントの検索性能が大幅に向上しました。
また、実装当初は、Amazon KendraというマネージドなVectorStoreを利用していましたが以下の理由でQdrantに切り替えました
- 非常にコストが高いので検証用では予算オーバー
- 検索結果の関連性が低かった
- ここはQdrantに切り替えて精度が大幅に上がりました
- もしかしたらKendraのお作法にそってなかったり日本語の精度はまだ低いのかもしれません(機能としてはサポート対象の言語)
チューニングと検証のサイクル
今回のアプリケーションは「回答の精度」が非常に重要になります。この品質をどのように評価・測定するかをチームで考え以下のような検証プロセスを回すことにしました。
- ClickUpから過去のお問合せデータ(質問や相談)を抽出→それぞれ生成AIの回答を生成し、リスト化する
- 上記をGoogleスプレッドシートにインポートし、人間の目で回答品質の評価をつける(◯、△、✕)。例えばハルシネーション(事実ではない回答)などがある場合は「✕」にする等。
- 品質の低い回答について原因を分析・特定し、プロンプトやドキュメントソースを修正する
- 上記1〜3を繰り返す
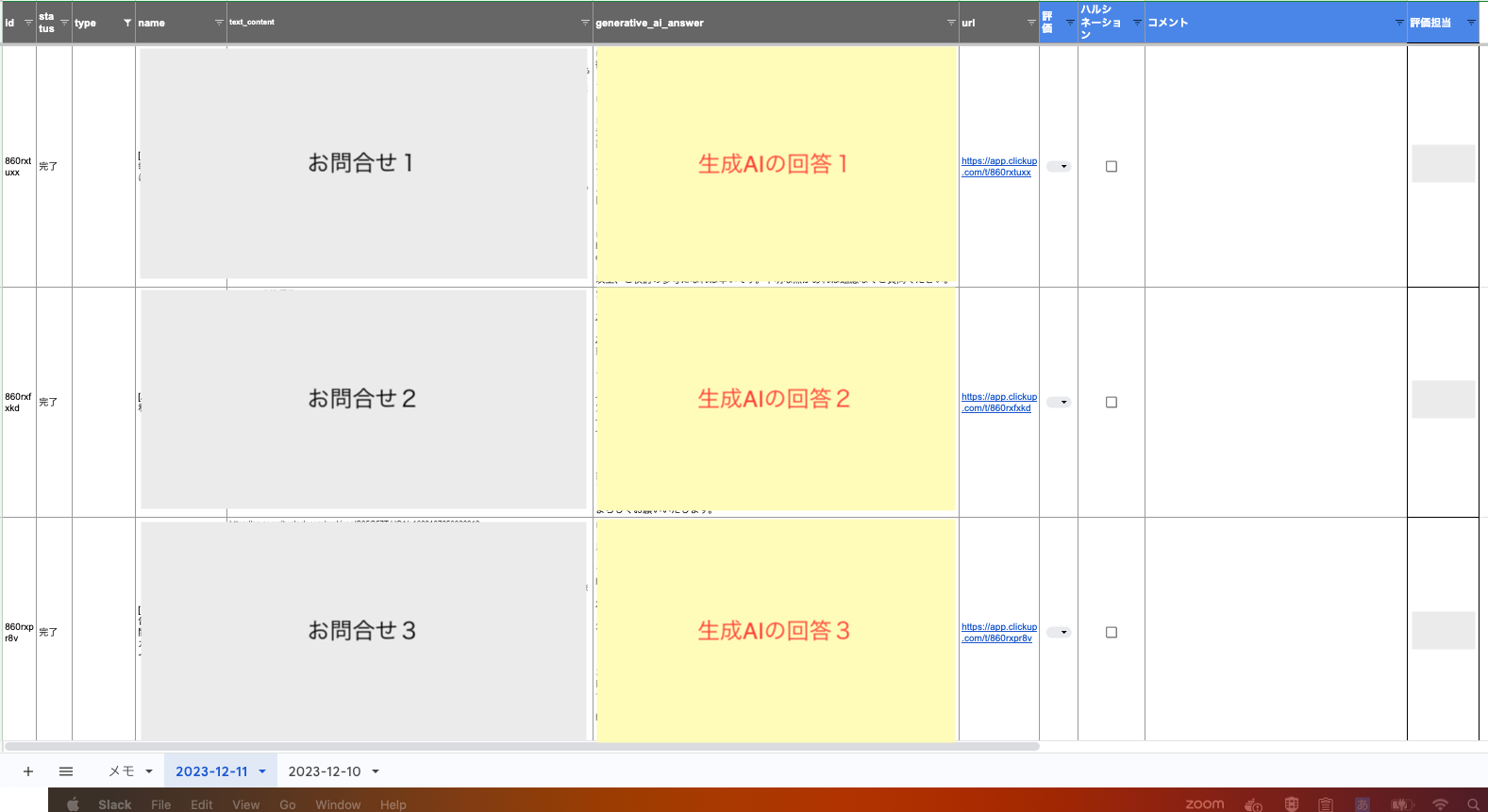
ClickUpの過去のお問合せタスクデータなので、対応履歴を追えば、結論どのような対応をおこなったのか(正解の対応)が確認できるため、検証データとしては非常に使い勝手が良いです。
また、繰り返しテストできるようにデータ抽出から回答生成までをツール化しました。
チューニングのプロセスでは、プロンプトの修正やドキュメントソースの修正が入るので、非エンジニアでも調整できるようWEBチャットのほうで自由に修正できるようにしました。(管理者のみ)
その他の検証観点
このアプリをSSGのチーム内、もしくは社内の人に展開する場合には、上記の他にもいくつかの考慮点が必要になります。
検証サイクルの中で以下のような項目もふまえて評価を行います。

まとめ
今回はセキュリティ業務に生成AIというテクノロジーを導入し、現状の課題を改善できるかを考えていきました。
また、弊社でどのような取り組みを行ったかをいくつか事例を紹介しました。実際に動かしてみると気づくことがいくつもありました。例えば、RAGの特性上どうしてもプロンプト文(input)が長くなってしまい回答のレスポンスが非常に遅くなってしまったり、なかなか期待した回答文が得られずチューニングを何度も繰り返すことになったため予想以上に時間がかかりしました。
しかし、生成AIは非常に強力なツールで、うまくいけば「属人化」というセキュリティエンジニアにとって重大な課題を改善できる可能性があります。
また、Amazon QやKnowledge Bases for Amazon Bedrockなどマネージドなサービスが登場し、ますます実装、運用が楽になっていきそうです。今後の進化が非常に楽しみです。