
はじめに
こんにちは!
FANTECH 本部所属の川口です。
我々のチームでは、Google Cloud, AWS, Azure といったクラウドサービスの他、さまざまな XaaS を利用しています。 これらの metrics はそれぞれのサービスで可視化できるようになっている一方、それらを一元管理したいというモチベーションとコストパフォーマンスの観点から Grafana を自前で Cloud Run 上で運用しています。
Grafanaでは、主要なサービスであれば Grafana data sources を用いて簡単に連携することができますが、こちらに存在しない場合は別途どのように連携するかを考慮しなければなりません。
Fastly も、その内の一つで 2024-04 現在 Grafana data sources として公開されていません。この際一つのアプローチとなりうるのが本記事で紹介する手法です。
全体像としては下記のようになります。
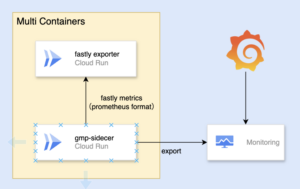
登場するコンポーネントとしては、次のとおりです。
- Cloud Run Fastly exporter
- Cloud Run GMP(Google Cloud Managed Service for Prometheus) サイドカー
- Cloud Monitoring
- Grafana
以降、上記コンポーネントについてお話していきます。
Cloud Run(Fastly exporter)
こちらは、Fastly の各種 metrics を Prometheus 形式で export するものです。
すでに、Fastly の公式にて fastly-exporter が開発がなされており我々はそれを利用しています。
Fastly には、Real-time Analytics API が存在しており、その API を用いて metrics を取得しているようです。
実装は、Go 言語で行われており、Docker コンテナ上でも実行ができるようになっています。
詳細な利用方法については割愛しますが、以下のようにして Prometheus 形式の metrics をエクスポートできていることが確認できます。
$ docker container run -p 8080:8080 ghcr.io/fastly/fastly-exporter:v7.6.1 -token=xxx
level=info component=api.fastly.com service=found service_id=aaa name=aaa version=1
level=info component=api.fastly.com service=found service_id=bbb name=bbb version=2
level=info component=api.fastly.com service=found service_id=ccc name=ccc version=3
$ curl localhost:8080/metrics
# HELP fastly_rt_last_successful_response Unix timestamp of the last successful response received from the real-time stats API.
# TYPE fastly_rt_last_successful_response gauge
fastly_rt_last_successful_response{service_id="aaa",service_name="aaa"} 1.712881797e+09
fastly_rt_last_successful_response{service_id="bbb",service_name="bbb"} 1.712881797e+09
fastly_rt_last_successful_response{service_id="ccc",service_name="ccc"} 1.712881797e+09
# HELP fastly_rt_realtime_api_requests_total Total requests made to the real-time stats API.
# TYPE fastly_rt_realtime_api_requests_total counter
fastly_rt_realtime_api_requests_total{result="no data",service_id="aaa",service_name="aaa"} 1
fastly_rt_realtime_api_requests_total{result="no data",service_id="bbb",service_name="bbb"} 1
fastly_rt_realtime_api_requests_total{result="no data",service_id="ccc",service_name="ccc"} 1
...
こちらを Cloud Run 上で動かすためには以下のような Terraform を書けばよいでしょう。
resource "google_cloud_run_service" "gmp" {
name = "gmp"
location = "asia-northeast1"
metadata {
annotations = {
"run.googleapis.com/ingress" : "internal-and-cloud-load-balancing"
}
}
template {
spec {
service_account_name = google_service_account.main.email
container_concurrency = 1000
containers {
name = "fastly-exporter"
# 別途、fastly-exporter の image を管理しています
image = "asia-docker.pkg.dev/fastly-exporter/fastly-exporter:v7.6.1"
ports {
name = "http1"
container_port = 8080
}
command = []
args = ["-listen=0.0.0.0:8080"]
# API token が必要なため、別途 secret manager 経由で設定しています
env {
name = "FASTLY_API_TOKEN"
value_from {
secret_key_ref {
name = "fastly-api-token"
key = "latest"
}
}
}
resources {
limits = {
"cpu" : "1000m",
"memory" : "512Mi",
}
}
startup_probe {
initial_delay_seconds = 5
timeout_seconds = 1
failure_threshold = 2
period_seconds = 3
http_get {
path = "/metrics"
}
}
liveness_probe {
initial_delay_seconds = 5
timeout_seconds = 1
failure_threshold = 3
period_seconds = 10
http_get {
path = "/metrics"
}
}
}
}
metadata {
annotations = {
"autoscaling.knative.dev/minScale" = "1"
"autoscaling.knative.dev/maxScale" = "1"
"run.googleapis.com/client-name" = "gmp"
}
labels = {
"run.googleapis.com/startupProbeType" = "Custom"
}
}
}
traffic {
percent = 100
latest_revision = true
}
autogenerate_revision_name = true
depends_on = [
google_secret_manager_secret_version.cloud-run-gmp-config-version,
]
}
Cloud Run GMP(Google Cloud Managed Service for Prometheus) サイドカー
ここまでで、Cloud Run を用いて Fastly の Prometheus 形式の metrics を export することができるようになりました。次は、これらの metrics をスクレイピングして、 Cloud Monitoring に report する部分についてお話します。
このような場面では、Cloud Run 用の Google Managed Service for Prometheus サイドカーを利用することが Google で推奨 されています。
※ export をするサービスが Cloud Run ではなく、Kubernetes etc… を用いた環境ではまた推奨方法が変わってきます。詳細は、ドキュメント を参照してください。
Cloud Run ではマルチコンテナサポートが導入されているため、1つのリビジョンに最大10個のコンテナをデプロイでき、簡単にコンテナ間で通信を行うことができるようになっています。 この機能を使って、Google が提供する Run GMP サイドカー を先ほどの手順で作成した Cloud Run にサイドカーとして導入します。
基本的にはサイドカーとして導入するだけですが、この GMP をカスタマイズしたい場合は別途その設定を行う必要性があります。公式では、secret manager 経由で設定をする手法が紹介されており、我々のチームでもそれに準じています。以下のような設定を行なっており、/metrics のポート 8080 から 10秒ごとに metrics をスクレイピングしています。
apiVersion: monitoring.googleapis.com/v1beta
kind: RunMonitoring
spec:
endpoints:
- jobName: fastly-exporter
port: 8080
path: "/metrics"
interval: 10s
この設定ファイルにおける文法は、以下が参考になります。デフォルトでは、/metrics のポート 8080 から 30 秒ごとに metrics をスクレイピングするようです。
https://cloud.google.com/stackdriver/docs/managed-prometheus/cloudrun-sidecar#custom-configuration:~:text=–region%3DREGION-,RunMonitoring spec%3A configuration options,-This section describes
加えてこの文法から想像できるように、同時に複数の endpoint を設定することにより複数の exporter からの metrics を Cloud Monitoring に report することができます。
※ ただし 2024/04 時点の最新 version である v1.1.0 では、複数の endpoint 設定時にバグがありました。そのため我々のチームで bug fix PR をあげそちらの PR が現在 merge されています。おそらく次の version ではこの複数 endpoint に対応できていると思います。また、まだこちらの repository では contribution を受け付けていない そうなので余程のことがない限りは PR を作成することは推奨しません。
先ほど用意した Cloud Run の Terraform に、以下のように追記を行えばよいでしょう。
resource "google_cloud_run_service" "gmp" {
...
template {
spec {
...
containers {
name = "fastly-exporter"
...
}
containers {
name = "gmp"
image = "us-docker.pkg.dev/cloud-ops-agents-artifacts/cloud-run-gmp-sidecar/cloud-run-gmp-sidecar:1.1.0"
command = []
args = []
resources {
limits = {
"cpu" : "1000m",
"memory" : "512Mi",
}
}
# 用意した設定ファイルを secret manager 経由で mount します
volume_mounts {
name = "gmp-config-yaml-volume"
mount_path = "/etc/rungmp/"
}
}
volumes {
name = "gmp-config-yaml-volume"
secret {
secret_name = google_secret_manager_secret.cloud-run-gmp-config.secret_id
items {
key = "latest"
path = "config.yaml"
}
}
}
}
metadata {
annotations = {
...
"run.googleapis.com/container-dependencies" = "{\\"gmp\\":[\\"fastly-exporter\\", \\"mux-exporter\\"]}"
}
...
}
}
...
}
Cloud Monitoring
ここまでで、Fastly の metrics を Cloud Monitoring に report できるようになっているはずです。
Cloud Monitoring では、各種 metrics に対して MQL(Monitoring Query Language)というクエリ言語を用いて分析する方法が今までよく用いられているかと思いますが、PromQL を用いた分析もサポートされています。
従って、以下のようにして GMP で取得した各種 Prometheus 形式の metrics に対して、 Metrics Explorer から確認ができます。
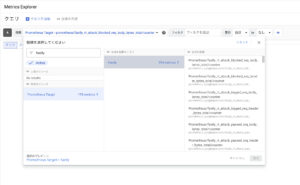
ただし厳密には、Cloud Monitoring で扱える PromQL には差異があるので詳細に関しては ドキュメント を参照ください。
また Prometheus 形式の metrics でなく、各種 Cloud Monitoring metrics に対しても PromQL を利用することができます。詳細は ドキュメント を参照ください。
Grafana
Cloud Monitoring の Metrics Explorer から metrics を確認できていれば、あとは Grafana から Cloud Monitoring の data source を使えば PromQL を用いて簡単にダッシュボードを構築することができます。
以下は、指定された Fastly サービス名に対するキャッシュヒット率を計算するための PromQL を用いたパネルです。
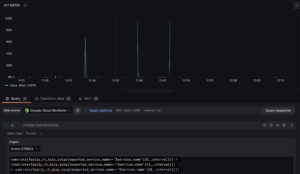
また、ダッシュボードを作成する際のクエリなどには公式でも紹介されている以下のリポジトリが参考になると思います。
https://github.com/mrnetops/fastly-dashboards
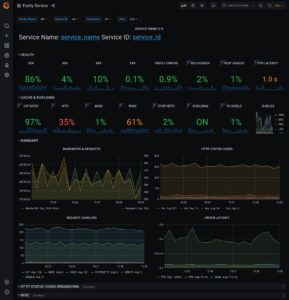
個人的にどのようなダッシュボードを作るのかを考えるのが結構大変だったりするので、重宝しました。以下のようなイケてるダッシュボードが作成できるはずです。(以下の画像は、GitHub 上で公開されているサンプル画像です。)
おわりに
我々のチームで運用している Grafana と Cloud Run サイドカーを用いた Prometheus Metrics の収集方法についてお話しました。
今回は Fastly の metrics 取得に既存の exporter を利用しましたが、そのようなものがない場合はどのようにすればいいかといった exporter 側に焦点をあてたお話はまたの機会にできたらと思います。
最後までご覧いただきありがとうございました!