
AI事業本部の協業リテールメディアdivでバックエンドエンジニアをしている yas7010 といいます。
今回はチームで Airflow x Cloud Batch による分析の自動化を行う際の技術的トピックをお話ししようと思います。
チームの技術構成
我々のチームでは、小売市場に AI 技術を持ち込むことで、デジタルとリアルを横断した新しい購買体験の提供や社会課題解決にむけたデータ分析基盤を構築しています。
データ分析基盤は Snowflake 上に構築されており、データレイク・データウェアハウス・データマートの3層に分け Cloud Composer (内部的には Airflow というワークフローエンジン)でワークフローを定期実行しています。
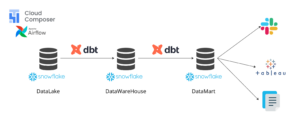
Google Composer x dbt によるデータ変換バッチ
ワークフローエンジンとして Airflow を採用した理由としては、 複数の主要クラウドサービスでフルマネージドサービス(AWS は MWAA、GCP は Cloud Composer)が提供されており、他の小売事業に向けたサービス開発が将来発生した際に、他チームへの技術資産の再展開が容易であると考えたためです。
dbt は近年人気のデータ変換ツールであり、 jinja ベースの SQL の SELECT 文を記述することでテーブルスキーマ更新やリネージ作成などを自動で行うことができます。
我々のチームでは独自の dbt オペレータを作成することで、データの変換処理を下記のような指示で定期実行させています。
with DAG(
dag_id=Path(__file__).stem,
schedule_interval="0 0 * * *", # 毎日 0:00 JST に実行
start_date=datetime.datetime(2024, 1, 1, 0, 0, tzinfo=timezone("Asia/Tokyo")),
) as dag:
(
EmptyOperator(task_id="start")
>> DbtRunOperator(
task_id="dbt_run_my_model_name",
select="my_model_name",
vars={
"imported_date": "{{ logical_date.in_tz('Asia/Tokyo') | ds }}"
},
)
>> EmptyOperator(task_id="end")
)
Cloud Batch を用いた計算処理
AWS の資料から拝借したものになりますが、バッチ処理は定型業務の意図で使われるものと大規模計算の意図で使われるものの2種類が知られており、Airflow は前者の意味合いのバッチ処理としてチーム内で採用されていました。
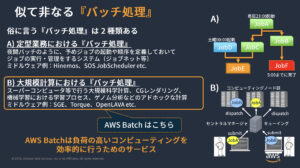 (新しいタブで開く)
(新しいタブで開く)
構築当初はデータを集める提携業務として意味のデータ収集が主な目的であり、Airflow の活用のみで十分でした。
しかし、時間が経つにつれて収集したデータを用いた機械学習や統計による分析の需要が発生し、大規模計算におけるバッチ処理を行う必要性が出てきました。
そのためチームで GCP のマネージドサービスの中から選定を行い、計算資源をタスクごとに柔軟に選定でき、特に実行時間制限がないことを理由に Cloud Batch を選定しました。
今回は Cloud Batch を Airflow 側で利用する際に遭遇した問題と解決策をまとめていきたいと思います。
Airflow 上での Cloud Batch の利用形式
Airflow には公式が提供する Operator が存在しており、それをラップする形で利用しています。
with DAG(
dag_id=Path(__file__).stem,
schedule_interval=None,
start_date=datetime.datetime(2024, 1, 1, 0, 0, tzinfo=timezone("Asia/Tokyo")),
) as dag:
JOB_NAME = "my-sample-analysis"
(
EmptyOperator(task_id="start")
>> MyCloudBatchSubmitJobOperator(
task_id="submit-analysis-job",
job_name=JOB_NAME,
analysis_script=[
"my_analysis_script.py",
"--target-date",
"2023-11-01",
],
dag=dag,
cpu_milli = 2000, # 任意指定
memory_mib = 2048, # 任意指定
machine_type = "e2-standard-4", # 任意指定
)
>> MyCloudBatchDeleteJobOperator(
task_id="delete-analysis-job",
job_name=JOB_NAME,
dag=dag,
)
>> EmptyOperator(task_id="end")
)
MyCloudBatchSubmitJobOperator が Cloud Batch の Job を実行するための Operator、
MyCloudBatchDeleteJobOperator が Job が完了するまで待機し、完了すれば削除する Operator になります。
導入している現在、MyCloudBatchSubmitJobOperator で実行される分析用の Docker イメージは一つに限定しており、チームで利用する分析ライブラリ・共通ロジック・ローカルでの実行環境などをまとめてイメージとして固めています。
“my_analysis_script.py” は GCS に保存されている分析用のスクリプトであり、この Job を実行すると Cloud Batch 上で分析用スクリプトがダウンロードされ分析処理を実行する構造になっています。
自作 CloudBatch Operator の中身
それでは、分析用の MyCloudBatchSubmitJobOperator の内容を見てみましょう。
from airflow.providers.google.cloud.operators.cloud_batch import (
CloudBatchDeleteJobOperator,
CloudBatchSubmitJobOperator,
)
class MyCloudBatchSubmitJobOperator(CloudBatchSubmitJobOperator):
def __init__(
self,
task_id: str,
job_name: str,
analysis_script: Union[str, Path, List[Union[str, Path]]],
dag: DAG,
cpu_milli: int = 2000,
memory_mib: int = 2048,
machine_type: str = "e2-standard-4",
**kwargs,
):
script_args = (
analysis_script if isinstance(analysis_script, list) else [analysis_script]
)
super().__init__(
task_id=task_id,
project_id=Variable.get("PROJECT_ID"),
region="asia-northeast1",
job_name=job_name,
job=_create_my_analysis_job(
[os.fspath(arg) for arg in script_args],
cpu_milli=cpu_milli,
memory_mib=memory_mib,
machine_type=machine_type,
),
dag=dag,
**kwargs,
)
def execute(self, context: Context):
# job_name にユニークな ID を与え、上書きする
job_name = _unique_job_name(self.job_name)
if ti := context.get("task_instance"):
ti.xcom_push(
key=_xcom_job_name_key(self.job_name),
value=job_name,
)
self.job_name = job_name
return super().execute(context)
class MyCloudBatchDeleteJobOperator(CloudBatchDeleteJobOperator):
def __init__(
self,
task_id: str,
job_name: str,
dag: DAG,
trigger_rule: TriggerRule = TriggerRule.ALL_SUCCESS,
**kwargs,
):
super().__init__(
task_id=task_id,
project_id=Variable.get("PROJECT_ID"),
region="asia-northeast1",
job_name=job_name,
dag=dag,
trigger_rule=trigger_rule,
**kwargs,
)
def execute(self, context: Context):
if (ti := context.get("task_instance")) and (
job_name := ti.xcom_pull(key=_xcom_job_name_key(self.job_name))
):
self.job_name = job_name
else:
raise ValueError("Job名が見つかりませんでした。")
return super().execute(context)
def _unique_job_name(job_name: str) -> str:
"""
Job名の決定。
同じのJob名が存在すると、Jobの作成に失敗するので、
Jobの作成依頼時刻を付与して、Job名の重複を回避する。
"""
dt = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
return f"{job_name}-{dt}"[:60]
def _xcom_job_name_key(job_name: str) -> str:
"""
Job名をXComに保存するキー名に変換して返す。
"""
return f"{job_name.replace('-', '_')}_job_name"
def _create_my_analysis_job(
script_args: List[str],
*,
cpu_milli: int = 2000,
memory_mib: int = 2048,
machine_type: str = "e2-standard-4",
):
# 詳細は後述
...
工夫点①: 実行される各 Job にユニークな job_id を与える
公式が提供する CloudBatchDeleteJobOperator と CloudBatchSubmitJobOperator はセットで利用されることが想定されていますが、これは Cloud Batch が重複した job_name を持つジョブを実行できない仕様によります。
そのため Job が成功していようが失敗していようが一度実行した Job を削除する必要があるのですが、失敗した原因を調査するのに不都合なため、Airflow 公式の Operator を改造し job_name にユニークな ID を振るように修正を行いました。
これにより、成功した Job のみ削除し、失敗したジョブは Job 履歴に残すことで失敗の原因の調査をしやすくしています。
工夫点②:Job がアクセスするリソースパスワードの安全な管理
次に、 Cloud Batch 用の Job を実際に作成する部分のコードを見てみます。
def _create_my_analysis_job(
script_args: List[str],
*,
cpu_milli: int = 2000,
memory_mib: int = 2048,
machine_type: str = "e2-standard-4",
):
runnable = batch_v1.Runnable()
runnable.container = batch_v1.Runnable.Container()
runnable.container.image_uri = os.fspath(
Path("asia-docker.pkg.dev")
/ Variable.get("PROJECT_ID")
/ "containers"
/ "my-analysis:latest"
)
runnable.container.entrypoint = "/app/datadog-init"
runnable.container.commands = [
"ddtrace-run",
"python",
"-m",
"my.analysis.automation", # スクリプトを GCS からダウンロードし実行するプログラム
*script_args,
]
runnable.environment.variables = {
key: Variable.get(key)
for key in [
"ENV",
# GCS
"PROJECT_ID",
"BUCKET_NAME",
# Snowflake
"SNOWFLAKE_ACCOUNT",
"SNOWFLAKE_USER",
"SNOWFLAKE_WAREHOUSE",
"SNOWFLAKE_ROLE",
# Datadog
"DD_ENV",
"DD_SERVICE"
]
}
runnable.environment.secret_variables = {
key: f"projects/{Variable.get('PROJECT_ID')}/secrets/airflow-variables-{key}/versions/latest"
for key in [
"SNOWFLAKE_PASSWORD",
"DD_API_KEY",
]
}
task = batch_v1.TaskSpec()
task.runnables = [runnable]
resources = batch_v1.ComputeResource()
resources.cpu_milli = cpu_milli
resources.memory_mib = memory_mib
task.compute_resource = resources
task.max_retry_count = 2
group = batch_v1.TaskGroup()
group.task_count = 1
group.task_spec = task
policy = batch_v1.AllocationPolicy.InstancePolicy()
policy.machine_type = machine_type
instances = batch_v1.AllocationPolicy.InstancePolicyOrTemplate()
instances.policy = policy
allocation_policy = batch_v1.AllocationPolicy()
allocation_policy.instances = [instances]
allocation_policy.service_account = batch_v1.ServiceAccount(
email=Variable.get("MY_ANALYSIS_EXECUTOR_SERVICE_ACCOUNT"),
scopes=[
# GCS (write)
"<https://www.googleapis.com/auth/devstorage.read_write>",
# Secret Manager
"<https://www.googleapis.com/auth/cloud-platform>",
],
)
job = batch_v1.Job()
job.task_groups = [group]
job.allocation_policy = allocation_policy
job.labels = {
"env": Variable.get("CDP_ENV"),
"type": "container",
"service": "my-analysis",
}
job.logs_policy = batch_v1.LogsPolicy()
job.logs_policy.destination = batch_v1.LogsPolicy.Destination.CLOUD_LOGGING
return job
Snowflake や Datadog に接続するためのパスワードを Cloud Logging などに出力させないよう、 SecretManager に保存しています。
この SecretManager からパスワードを取り出すために allocation_policy.service_account の
scopes に "<https://www.googleapis.com/auth/cloud-platform>" が必要なことがわからず、だいぶ苦労しました。
公式チュートリアルの 「Batch を使ってみる 」や 「カスタム サービス アカウントを使用してジョブへのアクセスを制御する」 などを参考に、Job で実行させる Service Account に必要なロールを忘れず追加させておきましょう。
まとめ
いかがだったでしょうか。我々のチームが行なった対応を記事にまとめて見ました。
我々のチームは実際の小売の POS データ・店内の行動データ・広告データなどを収集する段階から、ユーザの行動や効果的なマーケティング戦略を出すための分析に開発の重心が移り初めており、顧客に新しい知見を出せるようデータサイエンティスト・バックエンドエンジニア・そして営業チームで連携し取り組んでいます。