
こんにちは、FANTECH本部の前田(@arabian9ts)です。
FANTECH本部では技術発信を強化しているところで、既にいくつか記事を出しています。
- 管理画面にWasm入れてみた
- Cloud Run サイドカーで Fastly の Prometheus Metrics を収集して Grafana で可視化する
- reminder-lintでFeature Flagsの削除漏れを防ぐ
はじめに
私のチームでは、プロダクト開発で新規機能追加や仕様変更の場合に、品質チェック方法を使い分けています。テストは品質向上の手段ではありませんが、リグレッションを検知し、品質を間接的に維持する役割を持っています。
システムやチームの規模が大きくなっても、テストの運用コストを低く保ちつつも、目的とするリグレッションの検知を担保し、価値のあるテストを書き続けるための工夫がこのブログのテーマです。
そもそも、なぜテストコードを書いているか
テスト駆動開発の普及もあり、私のチームでも、テストコードを書く文化が根付いています。
多くの企業がテストコードを書いている時代だと思いますが、チームによっては以下のようなルールが存在するケースもあると思います。
- 新しく実装した機能は、必ずユニットテストが書かれていなければならない。
- テストカバレッジが80%を下回ってはならない。
これらのルールは、プロダクトの品質を担保する上で重要な指標に思えるのですが、間接的に寄与していつつも、テストで品質が上がるとは言い切れないかもしれません。
プロダクトの品質には、想定通りの動作が保証される品質以外に、コードベースの管理上の品質(開発生産性)も含まれるためです。
そのため、なぜテストコードを書くかと問われると、以下のように目的を明確化することができます。
- テストコードがあることで、システムのリグレッションに気づけるようになる。
- 外部ライブラリの挙動を理解するために、テストコードを書いて実際に動かすことで理解できる(学習テスト)。
新しい技術を導入するときは、最初に挙動を理解するための学習テストを行い、その後、そのテストはリグレッションを検知する役割を担うかもしれません。
テストコードが増えてくると
テストコードが増えてくると、簡単な変更でテストが壊れる(FAILする)状況が生まれます。
挙動を変えたのだから、テストがコケるのは好ましいことでは?と思われるかもしれませんが、それはケースバイケースだと考えています。
例えば、ブラックボックステストをイメージしていただけると、In/Outや副作用に関心がないのに内部のユニットテストが壊れやすい状況は、開発生産性を下げることにつながります。
他にも、運用が続いたシステムでは、処理を数カ所変更しただけなのに、テストコードの修正にそれ以上の多くの時間を消費することもあります。
実際に、私のチームでもそういったテストがあり、壊れやすくあって欲しいテストとそうではないテスト、それぞれ観点を明確にした上でテスト手法を選ぶようになりました。
できるだけ少ない運用コストで、目的とするリグレッション検知を達成できるようにテスト手法を設計します。
その活動の中では、先述の通りテストやその量が直接的にプロダクトの品質に作用するわけではないことを踏まえ、コードカバレッジの計測もやめました(数字に囚われてしまう可能性もあるので)。
そして、既存のテストで生産性を低下させている箇所に関しては、テスト手法を変え、既存テストを削除しようとしています。
テストコードを書くことは、開発フロー上非常に重要なステップですが、気づきたいリグレッションに応じて手法を使い分けていくことがさらに重要だと考えます。
テスト手法
一般的に、ユニットテスト、インテグレーションテスト、E2Eテストが有名なテスト手法として上げられます。さらに、ここ数年Goldenテストを活用している事例が増えているようです。
Goldenテストは、出力をファイルに保存しておき、次のテストではファイルの内容から変更がないかをチェックするテスト手法です。
他にも、私のチームでは、サーバーサイドにGoを使用していますが、Goではgolangci-lintやgo vetに則った豊富な静的解析ツールを利用できます。
(今回は取り上げませんが、テストシナリオの自動生成サービスなども盛んになってきました。)
テスト手法の使い分け
私のチームでは、以下の方針でテスト手法を使い分けています。
特に、ビジネスロジックに関しては基本的にはテストコードを書かない(実装者に委ねる)方針となっています。
| DBロジック | ユニットテスト |
| ドメインロジック | ユニットテスト / Goldenテスト(併用) |
| ビジネスロジック | 簡易的なロジックの場合、基本的にロジック自体のユニットテストは書かない。ハンドリング漏れなどはlintでチェックする。 |
| 型の詰め替え処理 | マッピング漏れはlint(exhaustruct)でチェックし、値が正しいかどうかはGoldenテストでチェックする。 |
| APIの挙動 | E2Eテスト |
| APIレスポンス | Goldenテスト |
図で表すと、以下のようにテスト手法を使い分けています。
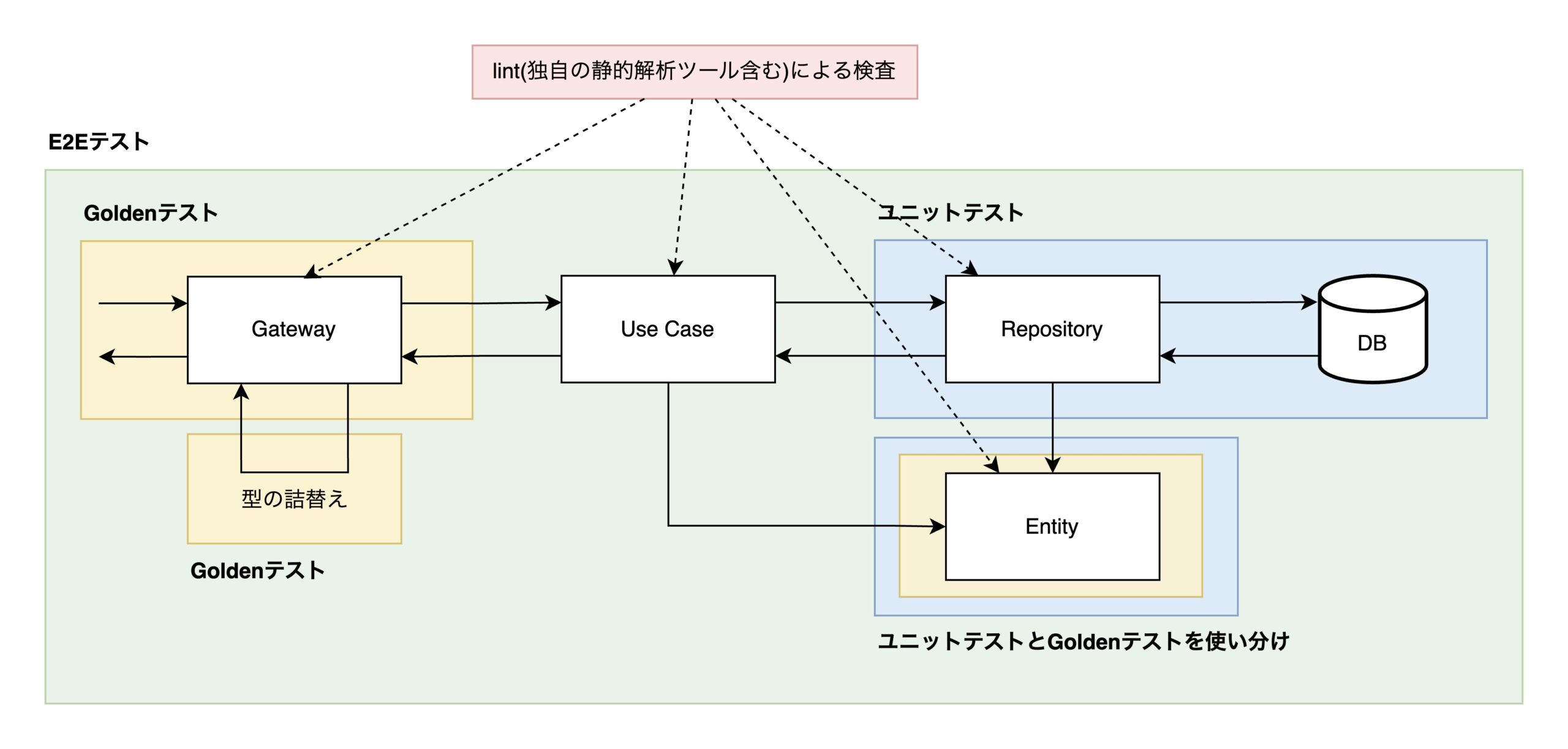
先ほどの、壊れやすくあって欲しいテストがドメインロジックのテストです。
挙動を変えたらテストはFAILして欲しい(テストを変更していないのにPASSすると不安)ので、厳格にチェックします。
逆に、ビジネスロジックは複雑なものを除けば、ある程度の初歩的なミスはlintで防ぐことができます(型の詰め替えのマッピング漏れや列挙漏れなど)。
そのため、実装によっては、E2EなどのブラックボックステストとGoldenテストの組み合わせで事足りるケースが多くなり、変更の多いビジネスロジックではユニットテストを書かないという思い切りの良い判断もできます。
いくつか掻い摘んでご紹介します。
簡易的なビジネスロジックのテスト
例えば、デバイスに合わせたキービジュアルのURLを返すロジックを例にとると、マッピングの漏れは exhaustruct により、switchのcase文の漏れは exhaustive により検知が可能です。
この例はかなり単純ですが、将来的に他のデバイス(テレビなど)が追加される可能性があります。
この場合、テストコードで条件分岐をテストするよりもlintに任せてしまう方が、管理するコード量が増えないことに加え、変更に対しても強い検査が可能です。
とはいえ、In/Outでのリグレッションに備える必要があるため、E2Eなどのテストで正常系シナリオを1パターン、異常系を何パターンか試しておく方針としています(ユニットテストは書かない)。
type Device int32
const (
DeviceUnspecified Device = iota
DevicePC
DeviceSP
)
type GetVideoKeyVisualRequest struct {
VideoID string
Platform string
}
type GetVideoKeyVisualResponse struct {
VideoID string
URL string
Width int32
Height int32
}
func (u *usecase) GetVideoKeyVisual(ctx context.Context, req GetVideoKeyVisualRequest) (GetVideoKeyVisualResponse, error) {
video, err := u.db.Get(ctx, videoID)
if err != nil {
return nil, err
}
resp := GetVideoKeyVisualResponse{VideoID: req.VideoID}
switch platform {
case DeviceUnspecified:
return nil, fmt.Errorf("platform is unspecified")
case DevicePC:
video.URL = video.KeyVisualURL
//video.Width = video.KeyVisual.Width // 画像サイズをレスポンスに詰め忘れる可能性がある
//video.Height = video.KeyVisual.Height
//case DeviceSP: // 列挙が漏れる可能性がある
// video.KeyVisualPortraitURL = keyVisualURL
}
return resp, nil
}
(このコードには1つ罠があり、lintによる検査が漏れる可能性があります。そのリスクと対策については後述します。)
上記のコードは、以下のように書くと、マッピング漏れをlintで検査できるようになります(コーディング規約などでルール化しておくのも良さそうです)。
func (u *usecase) GetVideoKeyVisual(ctx context.Context, req GetVideoKeyVisualRequest) (GetVideoKeyVisualResponse, error) {
video, err := u.db.Get(ctx, videoID)
if err != nil {
return nil, err
}
var resp GetVideoKeyVisualResponse
switch platform {
case DeviceUnspecified:
return nil, fmt.Errorf("platform is unspecified")
case DevicePC:
resp = GetVideoKeyVisualResponse{
VideoID: video.ID,
URL: video.KeyVisualURL,
Width: video.KeyVisual.Width,
Height: video.KeyVisual.Height,
}
case DeviceSP:
resp = GetVideoKeyVisualResponse{
VideoID: video.ID,
URL: video.KeyVisualURL,
Width: video.KeyVisual.Width,
Height: video.KeyVisual.Height,
}
}
return resp, nil
}
型の詰め替えテスト
型の詰め替えは、抽象化レイヤが多いコードベースではよく書く処理ですが、同じ型のメンバが複数ある場合などはミスをしやすいです。
そのため、型の詰替え処理などではユニットテストを書く方針としていますが、その際にGoldenテストを利用する方針としています。
// gateway/user.go
type GatewayUser struct {
ID string // ユーザーID
DisplayName string // 表示名
ProfileImageURL string // プロフィール画像URL
}
// entity/user.go
type User struct {
ID string
DisplayName string
ProfileImageURL string
}
func ConvertUserToGatewayUser(u *User) *GatewayUser {
return &GatewayUser{
ID: u.ID,
DisplayName: u.DisplayName,
ProfileImageURL: u.ProfileImageURL,
}
}
以下は、Goでよく見るテーブルテストコードです。
func TestConvertUserToGatewayUser(t *testing.T) {
tests := []struct {
name string
in *User
want *GatewayUser
}{
{
name: "ok",
in: &User{
ID: "abc",
DisplayName: "user name",
ProfileImageURL: "<https://image.example.com/test/user>",
},
want: &GatewayUser{
ID: "abc",
DisplayName: "user name",
ProfileImageURL: "<https://image.example.com/test/user>",
},
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
got := ConvertUserToGatewayUser(tt.in)
if !reflect.DeepEqual(tt.want, got) {
t.Error("unexpected output")
}
})
}
}
一方、Goldenテストを利用したユニットテストは以下です(goldieを利用)。
func TestConvertUserToGatewayUser(t *testing.T) {
g := goldie.New(
t,
goldie.WithFixtureDir("testdata"),
goldie.WithNameSuffix(".golden.json"),
goldie.WithTestNameForDir(true),
goldie.WithSubTestNameForDir(true),
)
tests := []struct {
name string
in *User
}{
{
name: "with all properties",
in: &User{
ID: "abc",
DisplayName: "user name",
ProfileImageURL: "<https://image.example.com/test/user>",
},
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
got := ConvertUserToGatewayUser(tt.in)
g.AssertJson(t, tt.name, got)
})
}
}
このテストを実行するには、一度Goldenファイルを生成する必要があるため、go testをupdateフラグ付きで実行します。
$ go test ./... -update
すると、Goldenファイルが生成されます。
{
"ID": "abc",
"DisplayName": "user name",
"ProfileImageURL": "<https://image.example.com/test/user>"
}
今度は、 -update フラグをつけずにgo testを実行。
$ go test ./...
これ以降、 ConvertUserToGatewayUser の出力が変更されるとGoldenテストはFAILします。
試しに、Bioを追加すると、以下のように差分が出力されます。
Result did not match the golden fixture. Diff is below:
--- Expected
+++ Actual
@@ -3,3 +3,4 @@
"DisplayName": "user name",
- "ProfileImageURL": "https://image.example.com/test/user"
+ "ProfileImageURL": "https://image.example.com/test/user",
+ "Bio": ""
}
この方式の良いところは、大きな構造体の詰め替え時にwantを都度書く必要がなく、現在の ConvertUserToGatewayUser が何を出力するものなのかが視覚的にわかりやすい点です。
実装者もレビュワーも、視覚的に出力ベースでレビューすることができるため、テストコードのレビューコストが下がります。
以降の ConvertUserToGatewayUser の追加改修では、差分ベースで出力のレビューが可能になるため、より差分が明確になります。
APIのテスト
GoではAPIベースでのテストが書きやすく、私のチームではしばらくgateway層のユニットテストを実装してきました。
ただ、gateway層のユニットテストをしても、モックを利用したテストでは”本当の値”を使ったテストにはならないため、どうしても結合部のテストが欲しくなり、E2Eテストを導入しました。
E2Eテストで重要な点は、外部システムへの影響など例外を除き、できる限りモックを使用せず本当の値を扱うことです(E2Eテストについては、また別記事を書こうと思います)。
テストを書いていないビジネスロジックをカバーできるように、いくつかの異常系と、1つの正常系シナリオをテストします。
私のチームでは scenarigo を利用しているため、以下のようにシナリオを書いています。
title: get video keyVisual
steps:
- title: invalid platform
protocol: http
request:
method: GET
url: '{{vars.baseUrl}}/videos/videoId/keyVisual?platform=invalid'
header:
Content-Type: application/json
Authorization: '{{vars.authorizationHeader}}'
expect:
code: Bad Request
- title: ok(pc)
protocol: http
request:
method: GET
url: '{{vars.baseUrl}}/videos/videoId/keyVisual?platform=pc'
header:
Content-Type: application/json
Authorization: '{{vars.authorizationHeader}}'
expect:
code: OK
body:
- videoId: videoId
- url: '{{assert.notZero}}'
- width: '{{assert.notZero}}'
- height: '{{assert.notZero}}'
E2Eでは本当の値を使用するため、時刻情報など動的に変わるレスポンスが生成されます。
そのため、E2Eの役割はシナリオベースでの挙動テストということになり、細かいフィールド単位のテストを書き切るのは難しいです。
そこで、E2Eとは別に、モックを用いたテストのGoldenテストを追加することで、APIのリグレッションテストを用意しています。
APIだけでE2EとGoldenテストを導入しているため、テストコードがかなり増えているのでは?と思われるかもしれませんが、E2Eはyamlで記述し、Goldenテストは既存テストに簡単に追加できるので、管理するテストコードはそこまで増加していません(シナリオもRESTfulなAPIコールを列挙するだけなので、スモールです)。
一方で、挙動ベースのテストとフィールド単位のテストをブラックボックス的にテストできるようになったため、レスポンスに変更がない範囲のビジネスロジックの変更では、これらのテストは簡単に壊れない状態を実現することができました。
より強固な検査のためのlint開発
先ほどの例で、以下のような定数定義をしていました。
type Device int32
const (
DeviceUnspecified Device = iota
DevicePC
DeviceSP
)
次のような書き間違いをすると、exhaustiveで列挙漏れを検知することができません。
type Device int32
const (
DeviceUnspecified = iota
DevicePC
DeviceSP
)
そのため、私のチームのメンバーが実装した iotyper-lint というlintをPR単位で動かしており、タイプエイリアスされていない定数定義を検知します。
$ go vet -vettool=/path/to/iotyper ./sample.go
sample.go:6:22: iota used without type specification
このように、「テストコード以外でチェック可能なものはテストで書かない」方針に寄せていくために、lintを自分たちのコードスタイルに合わせて実装し、その方針に実装も寄せています。
iotyper-lint は一例であり、他にも検査項目ごとに静的解析ツールを実装しています(以前ご紹介したreminder-lintもその1つです)。
今後、汎用的に利用できるlintはOSSとして公開していきたいと考えています。
運用してみてどうか
既存のビジネスロジックのテストについてはそのままにしていますが、新規に開発する機能については、基本的に上述した方針での実装に切り替えています。この変更による検査漏れや障害発生などは特に発生しておらず、テスト項目によって手法を変えることでメリハリが付いたと思います。 どうしても作業っぽくなってしまう箇所のテストが半自動化されたり、逆にE2Eによってこれまで検知できていなかった問題を事前に検知できるようになったりと、むしろリグレッション検知の網羅性が上がってきているように思います。
もちろん、すべてのビジネスロジックのテストを書かないわけではなく、必要に応じて実装者が判断すれば良いと考えているので、選択肢が増えたと捉えるのが良さそうです。E2EやGoldenテストを含め、外形監視としてテストできることは開発体験としても非常に良く、テストを追加する際の工数も比較的小さく済むため、チームメンバーからも好評でした。
テストの運用コストをできる限り抑えつつも、テストの価値を最大化するための取り組みについてご紹介しました。またこの運用で課題が出てきたら、解決も含めて記事として取り上げていきたいと思います。
誰かの参考になれば幸いです。