
こんにちは。 AI事業本部の協業リテールメディアdivでバックエンドエンジニアをしている yassun7010 といいます。
先日、 AI 事業本部の新人研修で「データアプリケーション」の講師を同じチームの 千葉 と担当しました。
今回の記事では、主に私が担当した「データベースの歴史」の章の講義資料を公開し、資料を作成する際に考えていたこと・伝えたかったことを話します。
データベースの歴史
「データベースの歴史」で説明されている内容は、AI事業本部の新卒研修で毎年取り上げられているものです。こういった研修の資料は、同じテーマであっても講師をする人の好みが反映されやすく、今年の資料も先人が作られた昨年の資料を参考にしつつ、私が好きな話題を多く取り入れたものに仕上がりました。
SlideShare でも公開しています。
今年の構成は、データベースを RDS・NoSQL・NewSQL として分け、下記のような構成をとっています。
- 時代ごとに出てきたデータベースの解決した課題
- その後の時代背景として発生した課題
- その解決策としての新しいデータベース
この章のタイトルに「歴史」を入れたのは、このような「時代背景から生じた課題と、それに対する解決策」という構成自体が、「後から見た一つの解釈」というメッセージを出したかったためです。
それでは、私の好みがどのように資料に反映されたのか、いくつかピックアップして紹介していきます。
データベースの必要性
この章の始まりは「そもそも」から始まる問題提起です。

つまり、プログラミング言語でもデータの検索・保存・更新は行えるのに「なぜ、データベースを皆使っているのか?」という疑問から始まります。
#####################
# これではダメなのか? #
#####################
# 配列からデータを格納する
users = [
{"name": "taro", "age": 20},
{"name": "jiro", "age": 18},
{"name": "sabro", "age": 14},
]
# 人の名前からデータを検索(find は自作関数)
assert find(lambda x: x["name"] == "jiro", users) == {"name": "jiro", "age": 18}
assert find(lambda x: x["name"] == "kojiro", users) is None
# 18歳以上の人を検索
assert list(filter(lambda x: x["age"] >= 18, users)) == [
{"name": "taro", "age": 20},
{"name": "jiro", "age": 18},
]
もちろん、我々は必要だからデータベースを用いているわけですが、聴衆に考えながら話を聞いてもらえれるように、「なぜ、わざわざ勉強してまで使うのか」を最初から意識しやすい構成にしました。
また、聴衆が飽きにくいよう構成も工夫しています。
章の最初に出したこの疑問に対する回答を「永続化のため」として一旦話を進めるわけですが、
インメモリデータベースで再び「永続化は必須か?」という疑問が発生するのです。
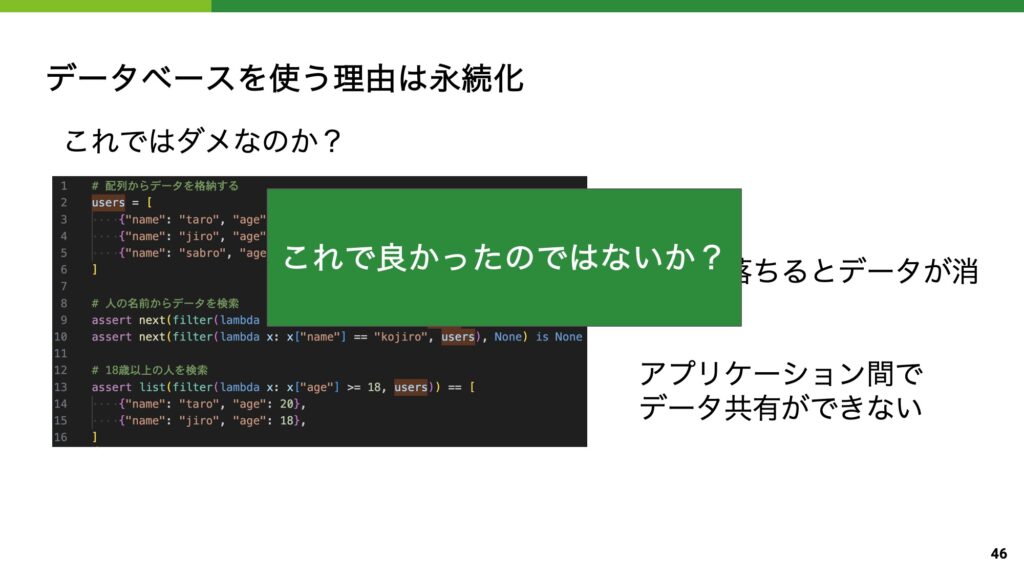
話の前提にも疑問を持つ姿勢と、データベースごとの立ち位置の違いの理解が培われる構成になっています。
標準SQLと実際のデータベース
標準仕様がある分野では、標準仕様に対しての理解も必要だという考えから、標準SQL の話を講義の中に加えました。
個人的には、データベースは標準SQLにどれだけ順守できているかを製品のアピールポイントしている分野であると思っており、データベースが機能開発としては先行しながらも、後発で定まった標準仕様に合わせる場面を多くみてきました。
トランザクションの話では、標準 SQL で定められている内容と実際のデータベースの違いを PostgreSQL や TiDB の公式ドキュメントの記述を追うような形で紹介しました。

SQL は登場から 50 年近くこの分野で支配的な言語であり続けており、これほど普及に成功した要因としては、標準 SQL を順守する姿勢を維持してきた各データベースの開発陣の貢献が大きいと思っています。
データアルゴリズムとの関連性
計算量(ビッグオー)の話や計算アルゴリズムを盛り込んだのも私の好みが反映されたためです。
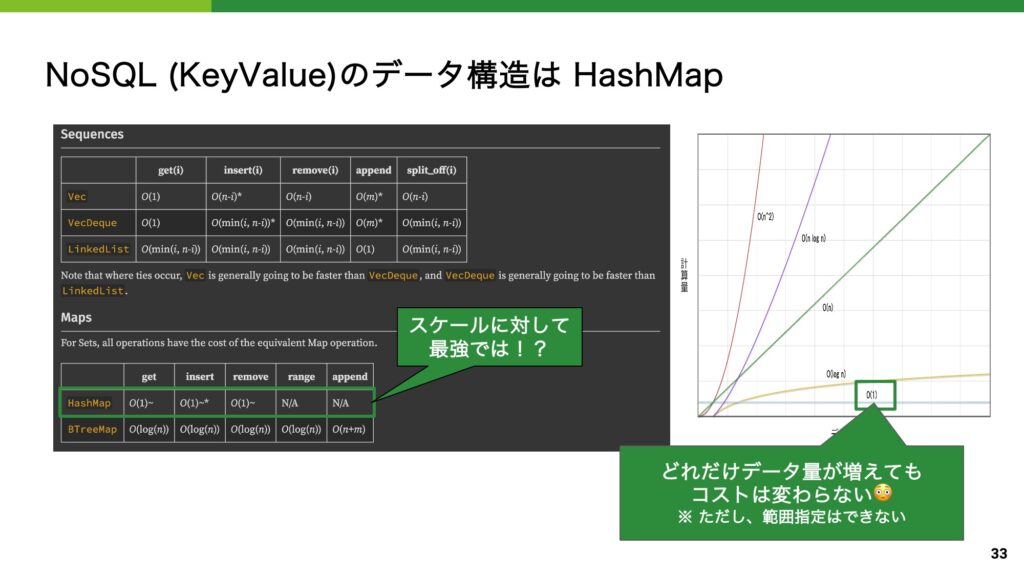
RDS で優等生的な立ち位置を見せた B-Tree が、スケールアウトが要求される時代において遭遇した苦境、代わりに用いられた HashMap という解決策、という形で NoSQL の説明を入れました。
データベースはアルゴリズムの知識が存分に生かされる用途の一つであり、大学で学んだ「授業」と、実際の「製品」との繋がりを感じてもらえるように意識しています。
信頼できない部品を組み合わせて信頼できるシステムを構築
分散型のデータベースの話を調べると特に面白いのが、一部が機能しないことを前提にしたサービスレベルが当たり前の世界になっているということです。
分散型のネットワークは下記のような理由によって、部品に完全な信頼を置いていません。
- ハードウェアの故障(数万台が同時稼働するため)
- ネットワークの遅延・障害
- ハードウェアのタイマの同期ずれ
こういった厳しい仮定を考慮した上で、今の分散システムは稼働しています。
製造業の品質の考え方に「最弱リンク説」などがありますが、ボトルネックを直して全体の性能を上げようという考えではなく、冗長性や自動修復のような仕組みを駆使することで、システム全体として部品単体以上の性能を担保しようという考え方はとても興味深いものです。
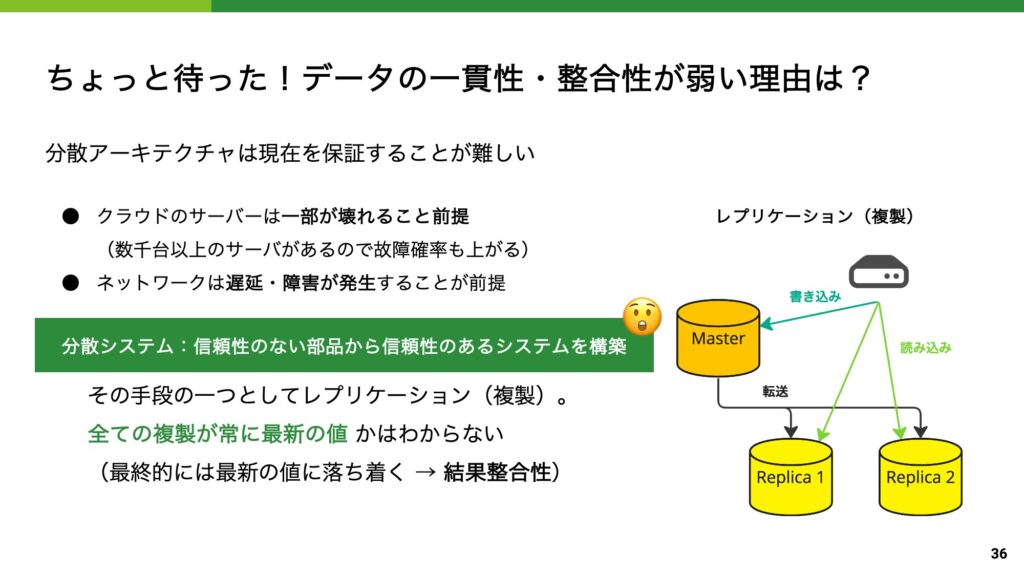
講義の時間が足りなかったので NewSQL の分散トランザクションの話は薄味で終わってしまいましたが、興味がある方は是非勉強してみてください。
既存データベースの進化
さて、この講義内容では各種のデータベースを大別し、古い RDB の弱点と、その課題を克服した新しいデータベースという形で話を整理してきました。
スライドのまとめでは、一通りデータベースの話をした後、最初に紹介した RDB の進化に着目し、話の構成に茶々を入れています。
人間というものは分類をすることによって理解と整理を進めるものですが、実際の製品を追うと綺麗に分類を分けることは難しいものです。
そのことが今回の講義資料を作る過程でよくわかりました。
PostgreSQL の機能アップデートのスライドを見るとわかりますが、 RDB もスライドの中で弱点と言われていた課題を着々と解決していることがわかります。
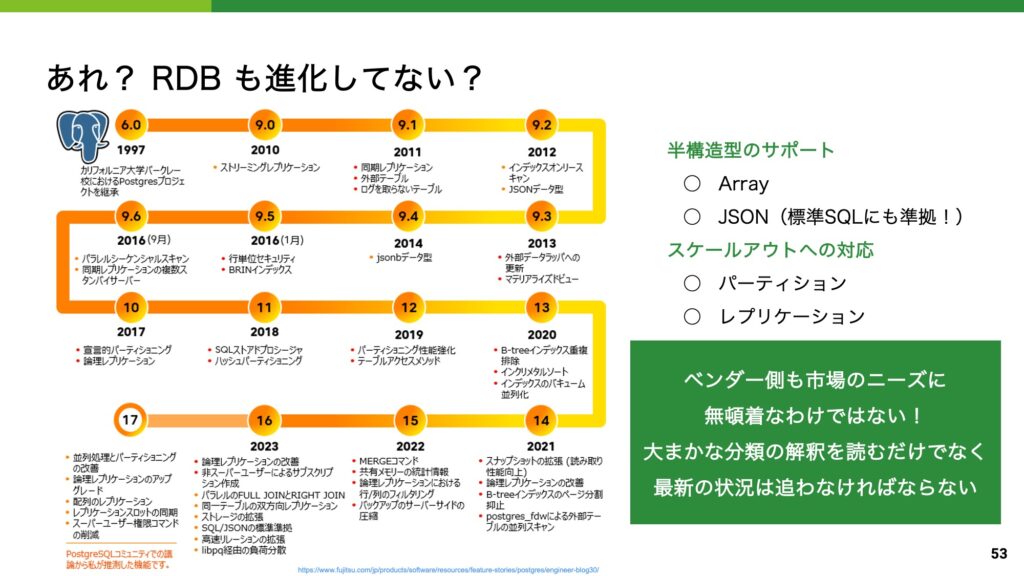
一つの話の流れだけを信じず、複眼的にデータベースの知識を集めていくよう話をまとめました。
ソフトウェアとハードウェア
データベースの歴史を通して紹介したかったことの一つに「ハードウェアの進化」があり、一番最後のスライドに忍ばせました。
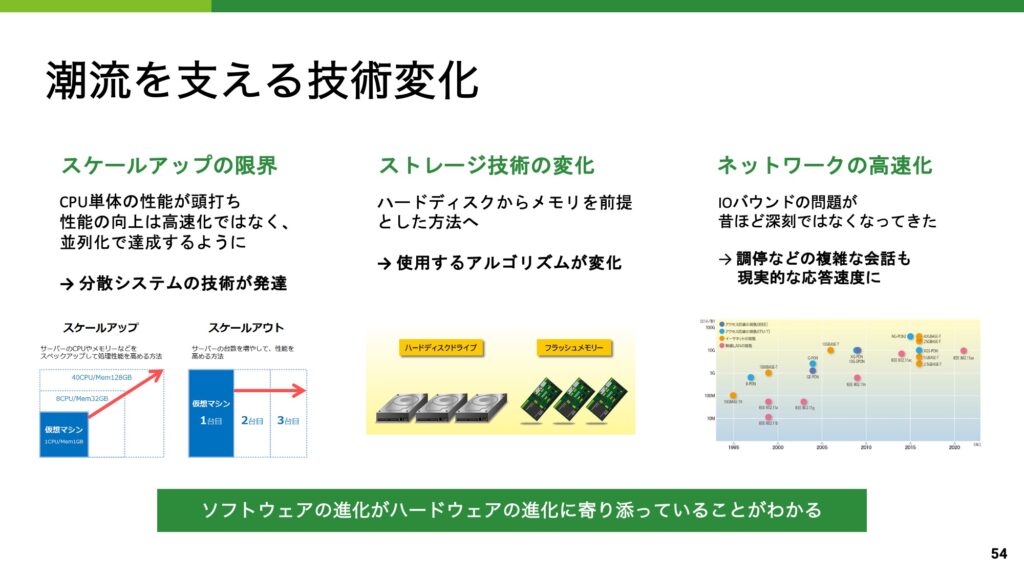
最近の AI の進化には目を見張るものがありますが、そういった技術が可能になった背景としてハードウェアの存在は欠かせません。
データベースにおいても、ハードウェアの進化がデータベースの進化の方向性に大きな影響を与えていることを、講義で感じてもらえたと思います。
(本当は市場の変化も入れたかったのですが、趣旨がぶれてしまいそうだったのでやめました)
技術の変容は一つの目線だけでは語れないものがあるので、そういった他の変化から自分の興味の対象がどう変わるのかも想像できるエンジニアになって欲しいなと思います。
今回の講義資料は、そういった目線の取り方を選んで、一つの「歴史」としてまとめています。
「歴史は解釈の数だけ存在する」ということを、皆さんに感じてもらえる講義資料になっていれば嬉しいです。
おわりに
データウェアハウスで列指向データベースの話をしよう、とか分散トランザクションをもう少し詳しく説明しよう、といった考えはあったのですが、研修時間なども踏まえて短めに抑える事になりました。
私自身にとっても、資料を作成する中で知りたいこと・学びたいことがどんどん増え、まとめ方に苦労しましたが良い勉強になりました。
また、研修生からは下記のようなコメントをいただけたので、今後仕事をしていく上でのインデックスのインプットとして、役に立つ講義資料になったかなと思います。
- 今まで知らなかったような歴史的背景や経緯を全体的に学べた。
- 業務であることを頼まれたときに大体が研修スライドに載っているので立ち返ることができそう
- 元々知らないことや、書籍やインターネットだけでは中々体系的に学ぶことができない事柄を多く学ぶことができた
最後になりますが、我々のチームではデータウェアハウスに Snowflake を用いて、「AI x 小売」のデータ分析基盤の開発に取り組んでいます。
(Snowflake は気に入ったので株を買って応援しています。株価上がれ!)
興味のある方は以下のカジュアル面談のリンクから気軽にお声がけください。
https://hrmos.co/pages/cyberagent-group/jobs/1986666672570519563