
グループIT推進本部のデータプロダクトユニット(DPU)でエンジニアをやっている@azazです。DPUではTiDBチームに所属していまして、ここではTiDBの運用、移行のサポート、クエリー最適化のサポート活動などに力を入れています。
大規模データ基盤にまつわるデータベース・ETL・クエリーエンジン・ストリーム処理技術について興味がある方は是非Cyberagentの採用ホームページから大規模データ基盤エンジニア枠で応募してみてください!
流れ
最近注目を集めているMysql互換のNewSQL データベースであるTiDBですが、内部のレートリミッターについて考えたことありますか?本記事ではTiDBで採用されているレートリミッターの仕組みについて3部構成で紹介したいと思います。
- 様々なレートリミッターアルゴリズムの紹介
- 分散システムにおけるレートリミッターの課題
- TiDBのレートリミッターの仕組み
第一部ではAPI レートリミッターの役割から実際に様々なサービス・APIで使用されているレートリミッターアルゴリズムについて共有します。そして第二部では第一部で紹介したアルゴリズムを分散システム環境で使用するときの注意点や課題点に触れ、TiDBの構成上どういう追加条件が発生するのかについて説明します。最後に第三部では第二部で紹介した課題を踏まえてTiDBがRequest Unit (RU)というものを使ってどう解決しているのかについて、ソースコードを読みながら紹介したいと思います。
TiDBのRUとは
TiDBはPD,TiDB,そしてTiKVの三つのコンポーネントにより構成されています。
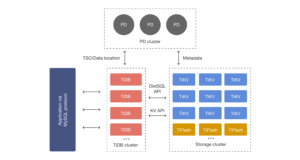
分散システム上で様々なハードウェア・ネットワーク状況下でTiDBのそれぞれのコンポーネントは動いています。こういった構成で一つのリクエストを処理するためにクラスター全体のハードウェア負担(CPU, Memory, IO)を集計した抽象的なRUを使いResource Groupというレートリミッターを設定できます。
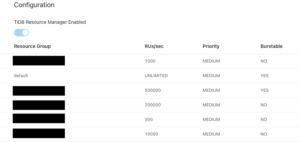
TiDBではResource Groupを作成し、そのResource Groupに対して秒間RUの上限を設けることができます。そしてそれぞれのResource GroupにMysqlユーザーを紐づけることでき、JDBCなどのMysql driverを使ってユーザーでログインし、DBに接続するときに自動的にレートリミッターの制限に沿ってクエリーを実行できます。

クエリーを実行するたびにRUが計算され、クエリーテンプレートごとの合計RU消費数、平均RU使用量などをダッシュボードから確認できます。実質的にオンプレ運用でもデータベースをサーバーレス的な扱いできるようになりました!
API レートリミッターの役割
レートリミッターにはさまざまな役割がありますが、主な利用用途としては以下のようなものが挙げられます:
- 運用しているサービスを保護する
- 公平にサービスを利用できるようにする
- サービス利用体験を向上させる
- サービス運用のコストを抑える
理論上APIは何らかの処理を抽象化したものであって、ユーザー側はサービスの裏側を意識せずにブラックボックスとして扱うことが可能です。しかし、サーバー側は実際のハードウェア・インフラ上に動いているのでハードウェアは有限であるという現実世界の制限に従う必要があります。
サービスが過剰にアクセスされると、CPU稼働率・メモリー使用量・ディスク使用量・ネットワーク帯域使用量全てが上がります。その結果、新たに来るリクエストのレーテンシー上昇の原因になり、APIのユーザー体験が悪化します。
さらに、一部のユーザーが過度にリクエストを送信しサービスに負荷をかけると、他のユーザーのレーテンシーも増加します。これは公平性が欠けていると判断できます。
また、大量のリクエストを捌くためのハードウェア資源を多く占有することになり、運用コストの高騰にも繋がります。
API レートリミッターの計測方法
レートリミッターの実装に入る前にまずリクエストを数える方法について考える必要があります。レートリミッターのリクエスト計測方法によってその挙動が大きく変わるからです。このセクションでは一般的に使用されているレートリミッターについて紹介したいと思います。
Fixed Window Counter
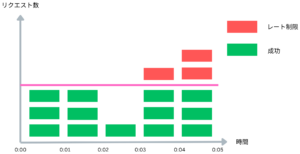
Fixed Window Counter [3] では時間軸を等間隔で分割し各期間で処理できるリクエスト数の上限値を設けます。そしてリクエストが来るたびにカウンターなどに記録して、上限値に到達した場合新しく入ってきたリクエストを拒否します。期間が終わった後カウンターをまた0に初期化する非常に簡単な実装方法です。上記の例では上限値を3と設定しています。
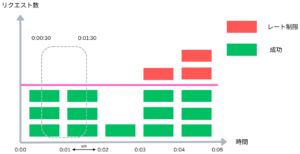
この手法の実装は簡単であるものの、粒度を細かくすると適切にレートリミットしていない状況もあります。上記の図では期間の最初と最後ではなく、0:00 ~ 0:01と 0:01 ~ 0:02の間でリクエスト数は上限値の3以内に収まっているにもかかわらず、0:00:30 ~ 0:01:30の間でサービスは上限値を超えて6件のリクエストを処理しています。
期間をµsなどの単位まで小さくして計測する手段もありますが、ネットワークにアクセスするアプリケーションが数µs単位でリクエストを処理することはあまりないので分数のQPµS (Query per micro seconds)上限値を設けることになります。つまり上記のQPS = 3の例だとQPµS = 0.003になりますがこのような値はプログラムとしては扱いづらいってことです。
Sliding Window Log
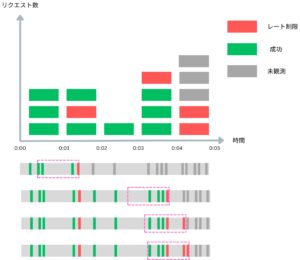
Sliding Window Log [3] はFixed Window Counterの弱点を克服するために「移動窓」という概念を定義し、それをログとして実装しています。リクエストが来るたびにリクエストの到着時間をログに記録し、さらにCounterを設けてログの中にある成功したリクエスト数を記録します。
Counterが上限値に達した場合は、現在時刻からあらかじめ設けた期間(1s,1ms, 1µsなど)を引いた時間より前のリクエストを削除して、削除した個数をまたCounterから引きます。Counterが減少した場合はリクエストを受理し、減少しなかった場合はリクエストを拒否します。TTLと似た仕組みです。
上記の図から確認できますが、ログの範囲内の成功リクエスト数は常に上限値を下回っていますのでこれで先ほど紹介したFixed Window Counterの問題は解消されました。しかし、その分レートリミッターに必要なメモリー量が上がりました。
個人的な感想として、この記事で紹介予定のアルゴリズムの中で一番実装コストと精度の比率が良く、簡単なアプリケーションならメモリー問題は大した問題にはなりません。
Sliding Window Counter
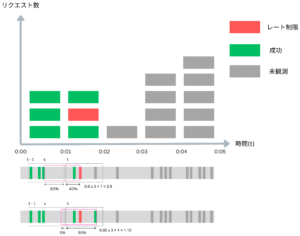
Sliding Window Counter [3] ではSliding Window Log同様「移動窓」という概念はありますが、ログは使用せず、移動窓の中にある成功リクエスト数を数えるカウンターを使用します。リクエストが来るたびに移動窓と移動窓が次の時間軸の区間と重なっている比率を計算して、掛け合わせて、その移動窓で処理できるリクエスト数を計算します。
例えば移動窓が0:00:24から0:01:24になっている場合、0:00から0:01の期間に重なっている比率が60%という計算になります。そして0:00 – 0:01の間で3件のリクエストを処理し、0:01 – 0:02の間は1件処理したため、0.6 * 3 + 1 = 2.8件のリクエストをこの移動窓で処理したことになります。この時点でリクエストを引き受けると移動窓のリクエスト処理数が上限値の3を超えて3.8になるためリクエストは拒否されます。
そして、移動窓が0:57 – 1:57に移動した時点で移動窓のリクエスト処理数は 0.05 * 3 + 1 = 1.15になるためリクエストがまた受け付けられます。
この手法は実際にCloudflareで採用されていたレートリミッターの手法であり、27万個のクライアントから4億件のリクエストを99.997%の精度で正しくレートリミットできたと発表しています。 0.003%の制御できなかったリクエストはバースト性の高いトラフィックの時発生していて、移動窓のn-1期間のリクエストの分布が次のn期間の分布と大きく違う時に発生します。[4]
Token Bucket Algorithm
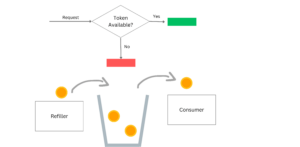
Token Bucket Algorithm [3] ではバケツを使います。バケツにトークンが一定の速度で追加され、トークンがある場合にのみリクエストが処理されます。つまり、バケツにはトークンが最大でどれだけ入るか(Burst size)、トークンがどのくらいの頻度で追加されるか(Refill rate)という2つの主要なパラメータがあります。
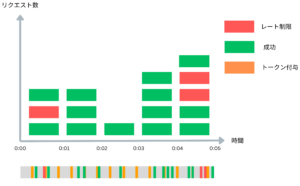
トークンは等間隔でバケツに追加され、リクエストが来たときバケツに十分なトークンがあればリクエストは処理され、必要なトークン数がバケツから削除されます。しかし、バケツに十分なトークンがない場合、リクエストは拒否されます。
このアルゴリズムの利点は、短時間のバーストトラフィックを許可しながら、長期的には一定のレートを維持できることです。しかし、トークンの追加と削除に関連する計算と同期が必要で、特に分散環境では実装が複雑になる可能性があります。また、このアルゴリズムを使用するために必要なBurst RateとRefill Rateのチューニングが必要で、適切な値を算出するには細かい検証を踏む必要があります。
Token Bucket Algorithmの採用事例が数多くあり、人間が考えるレートリミッターの直感とよく合っています。採用事例としてはStripe社のAPI [2] があります。TiDBもレートリミッターにToken Bucket Algorithmを採用していまして、分散環境におけるToken Bucket Algorithmについて本記事の第三部で紹介していきます。[6]
Leaky Bucket Algorithm
Leaky Bucket Algorithm [3] はその名の通り「漏れるバケツ」を比喩し、バケツから一定の速度でリクエストのConsumerがリクエストを消費し、消費し切れなかったトラフィックはバケツに水が溜まるように、キューに溜まっていきます。
キューが満杯になれば後から入ってくるリクエストを全て拒否する仕組みになっています。実際の採用事例としてShopify社 [7] があります。
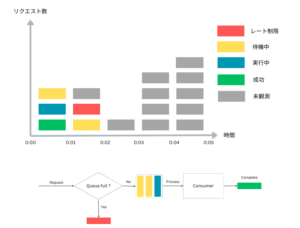
Leaky Bucket Algorithmは特にバース性が高いトラフィックに対する耐性が強く、裁き切れなかったトラフィックは全てメモリーが足りればキューに溜まっていきます。
さらに、バースト性の高いトラフィックを一定間隔で処理することでトラフィックのスパイクがハードウェア資源のスパイクにつながらないようにします。
Token Bucket Algorithmのデメリットとしてはバースト性の高いトラフィックが来る場合一気に大量のトークンが消費され、一気に大量のリクエストを捌くためのCPU、メモリー、IOが使用されることを挙げられますがLeaky Bucketにはこういった問題は発生しません。
デメリットとして一番大きいのはキューの長さ調整です。キューが長すぎるとメモリ使用量が増加し、一方で短すぎるとCPUやメモリーに余裕があるにも関わらず、処理可能なトラフィックが拒否されます。さらに、キューが短すぎるとキューの実装方法と並列処理モデルによりますがキューの先頭と後頭部にmutex競合による競合が発生します。
GCRA (Generic Cell Rate Limiting Algorithm)
Leaky Bucket を抽象化し、論理ベースでリクエストを捌けるかどうかを判断するGCRAもあります。GCRAは、各リクエストが処理されるたびに「理論的な到着時間」(TAT – Theoretical Arrival Time)を計算します。[5] 理論的な到達時間はバケツのConsume Rateと現状溜まっているリクエスト数Queued Requestsから Queued Requests / Consume Rate という式を使って計算できます。
実際の数式は今紹介したものとは若干違いますがイメージとしては物理的なキューを用いずに「リクエストが処理されるまで待つべき時間」を計測し、これが上限値に達した場合リクエストの処理を拒否するというものです。具体的な実装方法としては理論上のキューをカウンターで表すためメモリー効率もLeaky Bucketよりは良くなります。
この手法が実際のサービスに使われている事例は少ないですがredisなどを使った簡単な実装をライブラリー化したプロジェクトもあるため検証するのもありだと思います。
次回
次回は今紹介したアルゴリズムをTiDBのような分散システム上で使用するとき発生する課題について深ぼっていきます!
引用
[1] https://medium.com/geekculture/system-design-design-a-rate-limiter-81d200c9d392
[2] https://stripe.com/blog/rate-limiters
[3] https://blog.bytebytego.com/p/rate-limiting-fundamentals
[4] https://blog.cloudflare.com/counting-things-a-lot-of-different-things
[5] https://brandur.org/rate-limiting
[6] https://github.com/pingcap/tidb/blob/master/docs/design/2022-11-25-global-resource-control.md
[7] https://www.shopify.com/partners/blog/rate-limits
[8] https://docs.pingcap.com/ja/tidbcloud/tidb-architecture