
協業リテールメディアdivでデータエンジニアをしている千葉です。
本日は、先日弊社内で実施をしたAI事業本部 新人研修の一部である「データモデリング」について記載をします。
同じく講師として登壇をした yassun7010 も「データベースの歴史」について、ブログとして公開をしているため、合わせて見ていただけると嬉しいです。
※今回の記事作成に合わせて一部加筆修正をしています。
基幹系と情報系

今回の研修では、データモデリングを扱うシステムを
- 基幹系
- 情報系
に分けて説明をしています。
というのも基幹系と情報系では、そもそもデータの扱われ方やシステムの特性が異なります。
基幹系システムではOLTPと呼ばれる処理システムになっており、オンラインでかつリアルタイムにデータを追加更新します。そのため、重要となってくるのが多くのトランザクション(処理数)を正確にさばくことです。代表例としては銀行のATMが挙げられます。お金の入金/出金をあらゆるATM端末から追記、更新をすることになります。
一方、情報系システムではOLAPと呼ばれる処理システムで、人がクエリを発行し、大量のデータを高速に集計する必要があります。また、重要となるのが、人が扱いやすく集計しやすい構造にすることです。代表例としては、BIシステムなどの社内の定型レポートです。
データモデリングの流れ
データモデリングを行うときのフローとしては以下のようなものが一般的かと思います。
今回の研修ではこの流れの概念設計、論理設計について詳しく講義をしました。

概念設計
ERD
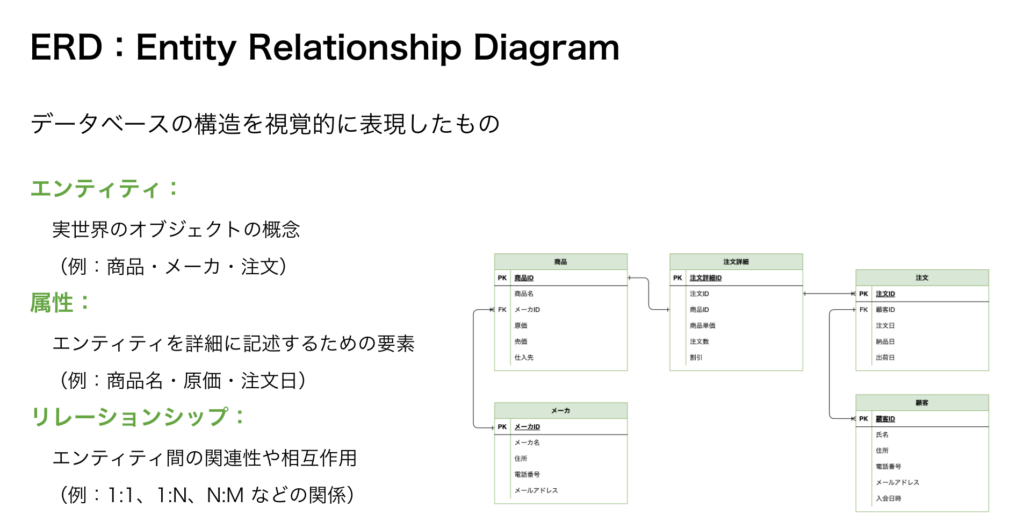
概念設計を行う場合に作成するものとしてERD(ER図)があります。
要件定義内容を基にエンティティという概念に属性という要素を足して、エンティティ間の関係をリレーションシップとして表現をしています。
(下記スライド参照)
実際の業務においても、どういったデータが入っているか、どのようにデータを扱えばいいかの理解をするために一番最初に見る図ではないでしょうか。
(いつも正しい形で整備されているかは別の話ですが・・・)
正規化
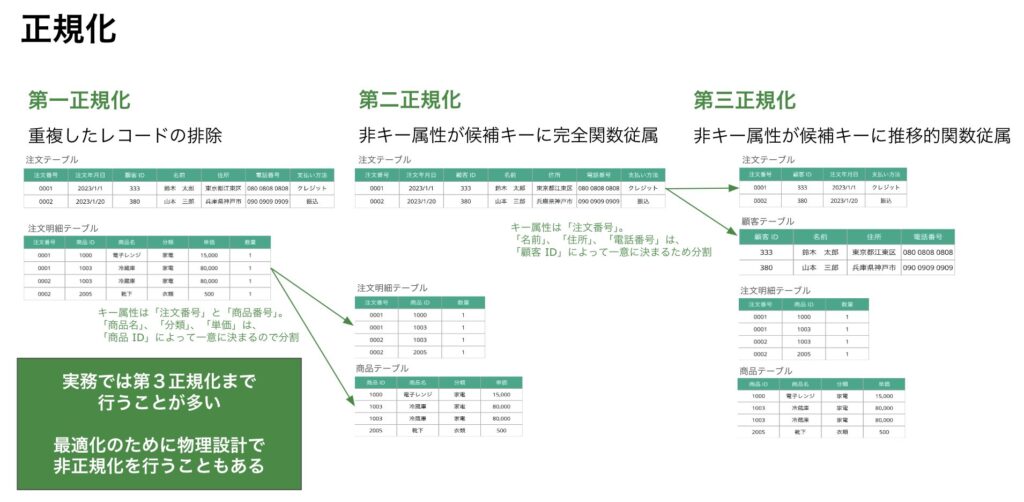
システムから発生したデータの形式がそのままでは人が扱いづらかったり、システムでもパフォーマンスが出ないケースがあります。その状態のデータを人にもシステムにも扱いやすい形にする整理方法として正規化があります。
正規化について簡単に記載しますと
第一正規化:繰り返しデータの排除を行う(重複データの削除、1セルにつき一つの値にする、など)
第二正規化:部分関数従属の切り出しを行う(主キーが複数項目の場合、一部の項目に対してデータが一意になるようにします)
第三正規化:推移的従属性の排除を行う(主キー以外の項目で一意な値に決まる場合別テーブルにします)
今回の研修では第一正規化〜第三正規化までを説明していますが、実際には第五正規化(ボイスコッド正規化)まであります。しかし、よく実務で使用するのは、第三正規化までとなるため第三正規化までを講義内容にしています。
また、実務を考えた際に第三正規化までを行うことが必ずしも正しいわけではありません。場合によっては非正規化状態で止めておく方が後々扱いやすいと言ったケースもあります。例としては、毎回結合するデータで、結合処理のせいでパフォーマンスが著しく劣化する場合、正規化をしない、といったことをします。
データの用語整理
ここで、用語の整理を挟みます。
私の感覚的には、データの分別として、マスタとトランザクションが一般的だと思っているのですが、この表現ではうまく分類できないデータが増えてきております。
(yassun7010 さんと講義資料作成時に議論が盛り上がった内容でもあったりします)
用語としては他にもいろいろな表現があるかと思いますが、上記のマスタ/トランザクションとは別の、リソース/イベントといった分類もあります。マスタ/トランザクションについては、
マスタ:めったに変更しないデータ
トランザクション:頻繁に発生するデータ
といった概念で整理されることが多くあります。しかし、実際の業務においては、その分類で整理できないことも多くあり、どちらに分類されるのが適切かといった議論が発生します。
(使用された歴史も長く、多くの定義があるという問題もありますね)
こういった議論を回避する目的でもリソース/イベントが使われることがあります。リソース/イベントについては
リソース:エンティティの状態を表すもの
イベント:エンティティの何かしらの動作を表すもの
といった概念になります。

データモデリング(論理設計)
イミュータブルデータモデリング

UPDATE, DELETEを極力しないようにすることを目指したモデリング手法となります。
現実的に、UPDATE, DELETEを0にすることは難しいケースが多いため、極力小さくする制約条件として実現を目指します。
大福帳
ここから話すデータモデリングはDWHでよく使用されるデータモデリングとなります。
まずは、大福帳から説明します。
大福帳とは必要なデータを全て1テーブルに集約して持つ形になります。

すべてのデータが一つのテーブルに入っているため、結合せずともデータが扱える点がメリットになります。一方、特定の値の変更(例えば商品のカテゴリ区分が変わった)などに弱いです。
また、データ量の制約が今よりも厳しかった時代では、この形で持てるデータ量には限りがありました。
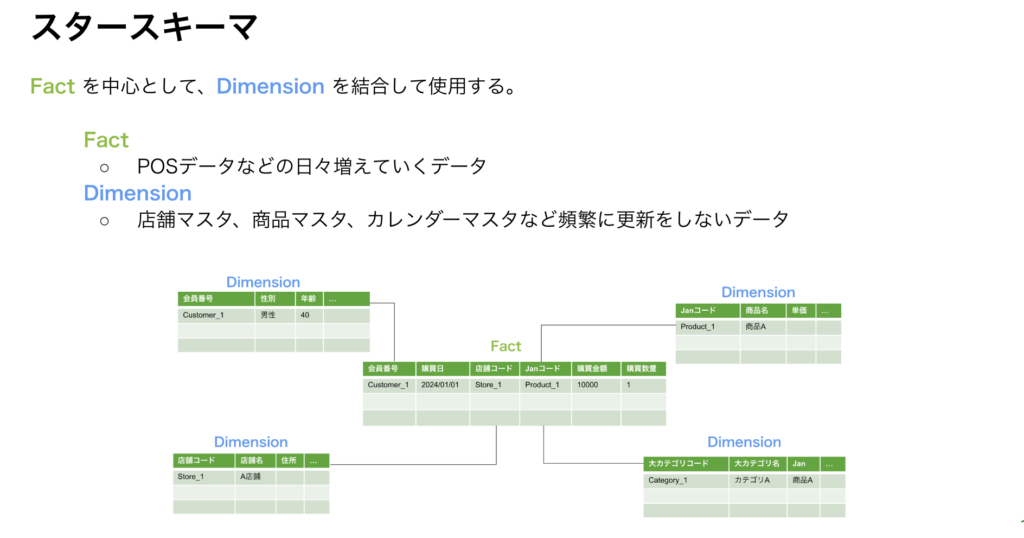
スタースキーマ
続いてスタースキーマです。
ディメンショナルモデリングとして知られており、ポピュラーなモデリング手法と言ってよいでしょう。
主に、Fact(イベント、トランザクションに当たるデータ)にDimension(リソース、マスタ)を結合する形で利用をします。
使用時に各テーブルを結合する必要があるものの、マスタの特定の値に絞ることで大量のデータを扱うことができました。
Data Vault
今回紹介するDWHのモデルの中で、最も新しいモデルがData Vaultになります。
最近では、多くのデータが保持できるようになり、最新のデータだけでなく履歴データを多く保持するようになっています。Data Vaultでは、いつ時点のデータかをメタデータとして保持することで、欲しい時点のデータを結合して過去のデータを扱うようにするモデルとなります。
大量のデータを保持できる様になった今の時代に着目されたモデリングと言えるでしょう。
一方で、構築するためには深いドメイン知識が必要となり、クエリを書く際に多くの結合を記載する必要があります。
(dbtでは、モデル構築のサポートのためのパッケージを提供していたりします)


今回の研修では、新卒に広いインデックスを張ってもらいたいという意図もあり、いろいろな手法について触れてみました。
余談ですが、冒頭に紹介したyassun7010の記事とこの記事の内容を合わせて2時間ちょっとで話したのは、詰め込みすぎたかも…。
今回の研修について、研修生から以下のようなコメントを頂けたので、インデックスを張っていただくという目的は達成できたかと思います。
- 今後使っていく技術に対して頭の中にインデックスを貼ることが出来た
- 各講義で聞いたことのない単語や概念が少なくとも一回以上出てきたため、このタイミングで知っておけてよかった
- 多種多様な講義だったが、全体的にかなりためになる講義でした
新人研修シーズンということもあり、弊社の研修を元にした記事が多く出ていますのでぜひ他の記事も読んでいただければと!
小売業のリテールメディアとして、データの価値を最大限活かした広告プロダクトを作りたい方ご連絡お待ちしています!
https://hrmos.co/pages/cyberagent-group/jobs/1986666672570519563
参考文献