
背景
こんにちは!Hanoi Dev Centerでバックエンドエンジニアをしているminhquangです。この記事では、私がAI事業本部のある新規プロダクト開発に参画した際に経験したパフォーマンスチューニングについて話したいと思います。
皆さんはサービスのローンチ(サービスを世の中に初めて出すリリース)をやったことがありますか。サービスローンチするときに、リクエストのスパイクや、ユーザー数の増加によるサーバー負荷増加など、様々な未知な課題が存在します。
私のチームでは数百万人の利用が見込まれるサービスにおいて、18000RPSを実現するべく負荷試験とパフォーマンスチューニングを実施しました。
本記事では、上記のサービス要件を満たすために私たちが取り組んだ負荷試験やパフォーマンスチューニングについて説明しつつ、これらの経験から得られた学びを共有したいと思います。
前提
技術スタック
- サーバー: AWS ECS (Fargate) – Go
- データベース: Aurora Serverless v2, DynamoDB
- サービス間通信: gRPC, Envoy
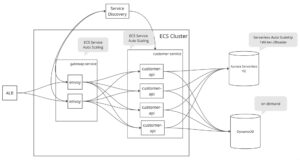
実際の構成はもっと複雑ですが、簡略すると下記の図のようになります。
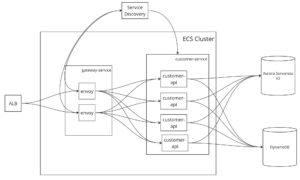
大枠三つのコンポーネントが分かれています。
- gateway-service: ALBからリクエストを受け取って、ルーティングを行うECSサービス。
- customer-service: envoyからルーティングされているリクエストを受け取ってアプリケーションロジックを実行するECSサービス
- data layer: Aurora Serverless V2とDynamoDBを使って、マスターデータやユーザーデータを扱う
負荷試験のゴール
サービスローンチの2ヶ月前にチーム内で下記の目標を設定しました。
- 単体APIは600RPS 負荷達成できること
- クリティカルシナリオで 複数APIが同時に呼ばれて、18000RPS負荷達成できること
※ RPS はサービスへの 1 秒あたりのリクエスト数を意味します。
取り組み① 負荷試験環境の設計
負荷試験 クライアントツール選定
私のチームでは、下記のツールを比較・検討しました。
そして、下記の理由によりk6を採用しました。
- エコシステム(DatadogやGrafana連携)が充実している
- gRPCサポート
- プラグインが豊富にあり、拡張性が高い。(例:可視化ツールの xk6-dashboardというものがある)
- シナリオベース
- 自動生成がしやすさ
のポイントがあるため、チームの欲しいものに近いです。
負荷試験設計時に考慮したポイント
- 本番のようなデータ量をどう準備するか
- 準備したデータに合わせて、リクエストパラメータはどう生成するか
- 負荷試験の環境を作成また終了したらちゃんとデータなど削除されるか
- 前回の実行結果と見比べるための仕組み
- 負荷試験は繰り返し・何回も実行することが必要なので、楽に実行できるか
- 負荷試験の実施環境は開発環境に影響与えないように、環境分離するかどうか
負荷試験基盤の設計
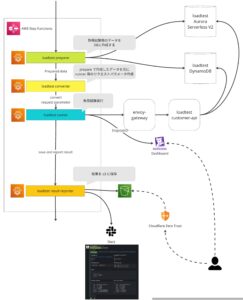
負荷試験の1連のステップについて説明します。
- loadtest-preparer: 実行環境のデータをリセット→試験用大量データの投入をする。(データ量の調整も実行時に指定可能)
- loadtest-converter: 準備したデータを元に、負荷試験シナリオ向けのリクエストパラメーターを生成する。
- loadtest-runner: 負荷試験シナリオを実施する。(メトリクスはDatadogに連携)
- loadtest-result-reporter: 負荷試験シナリオの実行結果をS3にアップロードする。また、Slackでサマリーの結果も投稿する。
上記のステップを1回ボタンをクリックするだけで完結できるように、AWS Step Function (SFN)で実装しました。
また、開発環境から負荷試験専用環境を分離しました。loadtest-customer-apiや loadtest Aurora Serverless V2 や loadtest DynamoDBなどは事前に作成して、負荷試験を実施するときに、ある程度専用環境で走らせて実際の開発環境に影響を与えないことも工夫しました。
負荷状況の可視化
Datadogのk6インテグレーションを用いて、負荷試験結果の可視化を行いました。
私たちのチームがDatadogを採用した理由の1つに、ダッシュボード機能があります。 負荷試験結果のメトリクスのグラフと、サービスの稼働状況やエラー率といったサービスメトリクスを1ページで表現できるので、監視のしやすさを実現することができました。

また、 負荷試験の実行結果をStep FunctionのExecution ID単位で絞られるようにしました。そこで、今回の負荷試験の実行結果や前回の負荷試験の実行結果を比較しやすく、ボトルネックや改善ポイントも見つけやすくなりました。
取り組み② 負荷試験シナリオの自動生成
負荷試験シナリオはユーザが使用する際の一連の操作をシステムに実際に加える負荷をテストすることです。負荷試験シナリオはユーザのアクセスパターンなど下記のような要素を含めます。
- ユーザー数: シナリオを実行する仮想ユーザー数
- RPS: 1秒でどのぐらいリクエストが行うか
- 実行時間: シナリオを実行する長さ
- 負荷変動レート
- ランプアップ: 仮想ユーザー数かつリクエスト数を徐々に増加させる方法
- ランプダウン: 仮想ユーザー数かつリクエスト数を徐々に減少させる方法
- コンスタント: 負荷試験の実行時間で仮想ユーザー数かつリクエスト数が変わらない方法
私たちのサービスにはAPIが数多存在し、色んなアクセスパターンを組み合わせたいので、負荷試験シナリオの実装の工数コストが高いと考えました。たとえば、API数が30個があれば、30個のAPI x 10アクセスパターン= 300個の負荷試験シナリオの実装が必要で、超大変な作業になるはずです。また、私たちのチームではGoをメイン開発言語として採用しているので、できる限りGoで開発できると好ましいのですが、k6の負荷試験シナリオは JavaScriptだけサポートしている問題もあります。
そこでgRPCのproto ファイルでリクエストの定義から自動的に負荷試験のシナリオを自動生成できるように Goの protoc-gen-starの公開パッケージを使ってprotocのプラグインを実装しました。また、テンプレート準備やカスタマイズ実装も色々工夫しました。
導入した結果、JavaScriptで負荷試験シナリオ を実装するのも不要になり、protoファイルの定義に基づいて、全て自動生成できました。集計してみると、978ファイル、68147行のコードの実装工数が削減できて、パフォーマンスチューニングに専念できました。
find . -type f -name '*.pb.*' | wc -l
> 978
find . -type f -name '*.pb.*' | xargs wc -l
> 68147 total
この記事のスコープ外ですが、私たちのチームでコードを自動生成するツールを開発し、30万行以上のコードを自動生成しましたコード生成の工夫の話も面白いので、別の機会で共有したいです。
codegen
protoc-gen-go-bulkstore-dynamo
protoc-gen-go-config
protoc-gen-go-datastore-sql
protoc-gen-go-grpc-admin-role
protoc-gen-go-grpc-client-invoke
protoc-gen-go-grpc-reqs-filename
protoc-gen-go-grpc-scenario
protoc-gen-go-message-log
protoc-gen-go-model
protoc-gen-go-reason-code
protoc-gen-go-validation
私のチームの B_Sardineさんもこの負荷試験の自動生成ツールについてGo Conferenceで発表があったので、このスライドを参考になります。
取り組み③ APIのパフォーマンスチューニング
負荷試験を実施するだけでは何の意味もありません。結果を分析した上で、目標値に届かせるために必要なパフォーマンスチューニングを行いました。 N+1問題など、一般的な改善ポイントも色々ありましたが、この記事では負荷試験を実施したからこそ見つけられた課題と、実際に実施したチューニングについて共有します。
実行計画で期待するIndexが使われない問題
MySQLでは場合によってクエリの実行計画が変わる可能性があります。テーブルの統計情報などに基づいて Optimizerが決めた実行計画によって、開発者が想定した挙動とは異なり、パフォーマンスが著しく落ちるケースがあります。
この課題に対して、私たちのチームではFORCE IDNEXを利用するアプローチをとりました。非推薦の方法ではあるので、できる限りMySQLに任せたい気持ちはありましたが、アクセスパターンについては開発者である私たちが一番詳しいので、やむをえずこのようなアプローチを取りました。
ConnectionPoolingの設定が効率的ではない問題
データベースはアプリケーションと高頻度でやり取りしているので、データベースとアプリケーションの接続の部分で最適できると、アプリケーションロジック変更しなくても一気に全体のパフォーマンスがアップできると分かりました。特にチューニングできるのは Connection Poolです。
Goのdatabase/sql標準パッケージは内部にConnection Poolが実装されています。ただ、標準の状態では、最適化されていないため私たちのユースケースに合わせて設定値を調整する必要がありました。 主に設定変更したのは、下記の4つです。
- DB.SetMaxOpenConns: 同時に開けられるConnectionの数ですが、少ないのも良くないし多くても良くないので、ECS Taskのメモリ利用率やタスク数や データベースのmax_connectionsなどに基づいて設定できます。
- DB.SetMaxIdleConns: 暇なConnectionはどのぐらい保持するかの設定ですが、特にメモリの懸念もないため、DB.SetMaxOpenConnsとの同じ値にしました。もし小さく設定したら、Connection確立コストが増えると思い、パフォーマンス落ちる原因になり得えます。
- DB.SetConnMaxIdleTime & DB.SetConnMaxLifetime: 確立したConnectionはどのくらいまでConnectionを維持するかの設定です。できるだけ長くしたいが、とても長くしたら データベース障害が発生されるときに、不正なConnectionがずっと残ってしまうため、どのぐらいの時間でこの問題許容できるかバランスを取って設定しました。
クラウドプロバイダの設定しているハードリミットに引っかかってしまう問題
AWSサービスといった一般のクラウドサービスは無限に使えないので、何かのハードリミットがあります。
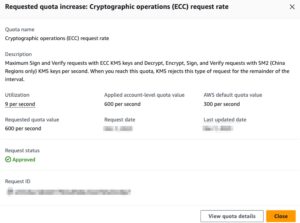
私たちが遭遇したのは、KMSのハードリミットでした。あるAPIでトークン暗号・複合化するためにKMSを利用していましたが、KMSはデフォルトで300RPSのハードリミットが設定されています。そのため、600RPSのシナリオで負荷試験を実施したところ、エラーになってしまいました。解決策は AWS サービスクォータで上限緩和を申請するか、別サービスに移行するかが考えられます。サービス移行の工数が高いので、私のチームでは 上限緩和申請してみたが、すぐ承認してくれました。
取り組み④ サービス構成のチューニング
スケール戦略最適化
サービス全体で受けられる負荷は、上流のコンポーネントが受けられる負荷に依存します。つまり、下流のコンポーネントがいくら高負荷に耐えられるものだとしても、上流のコンポーネントがボトルネックになっていると高いパフォーマンスを発揮できないということになります。
下の図で説明すると、いくらサーバーやDBが高負荷に耐えられる作りになっていても、入口であるGatewayが600RPSまでしか捌けないとなると、サービス全体のパフォーマンスは600RPSが上限になってしまいます。
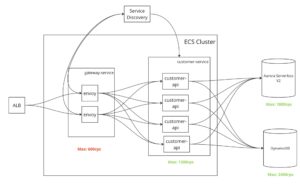
そのため目標値まで負荷の上限を上げるために、適切に各コンポーネントのスケール戦略を考えないといけません。例の図でいうと、1800RPSまで負荷上げるためにgateway-serviceやcustomer-serviceをもっとスケールする必要があります。
また、使用しているサービスの特性によって、取るべきスケール戦略は異なります。私たちのチームの場合は、下記のようにサービスごとにスケール戦略を立てました。
- ECS: 一つのタスクを一定のスペックにして、自動スケールアウトルールを設定しました。
- Aurora Serverless V2: Serverlessなので、すでにスケールアップのルールが適用されている。スケールアウトも考慮したが、検証してみて自動スケールアウトに15分以上かかるので、あまり活用性が見えないので採用しなかった。代わりに固定で Writer-Reader構成にして負荷分散と冗長性も担保できます。
- DynamoDB: バッチで大量バッチ書き込む処理があるのと、利用計画により、on-demandの方がコスト安かったポイントもあったため、 on-demand キャパシティにしました。
ロードバランシング最適化
各コンポーネントがスケールアウトしても負荷がなるべく均等にならないと、スケールアウトする意味がないです。そのため、私たちのチームでは負荷試験でリクエストが分散されているかの可視化を行いました。
私たちのチームも負荷が上がったときにロードバランシングの問題が発生されました。
なぜか 一定のrpsになったら、customer-serviceのECSタスクがスケールできても、リクエストがほぼ落ちてしまって、5割ぐらいのリクエストがエラーになりました。

調べた結果、customer-serviceのタスクがスケールアウトされても、下記の図通りに、Envoyのクラスターにいつも8つのメンバーだけルーティングできて、ECSタスクが12個になっても残りのメンバーではない 4つのECSタスクはリクエストが来られないようでした。
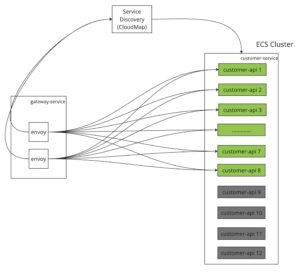
EnvoyはService Discoveryから連携先のcustomer-serviceのECSタスクの情報(DNSなど)を取得して、メンバークラスターを運用し、そのクラスターになるメンバーへリクエストをルーティングする仕組みです。メンバーを管理する方法は 基本的にstrict_dns、logical_dns、xDSサーバーの3つの選択肢があります。
※ Envoyについて詳しく知りたい方は 入門Envoyおすすめです。
strict_dnsやlogical_dnsは設定変えるだけで、試してみたがどっちも効果がなかったです。理由は AWS Service Discoveryが使用するAWS CloudMapのルーティングポリシーで一定の時間に最大8個のエンドポイントしか返されない仕様があります。
MULTIVALUE
If you define a health check for the service and the health check is healthy, Route 53 returns the applicable value for up to eight instances.
For example, suppose that the service includes configurations for one A record and a health check. You use the service to register 10 instances. Route 53 responds to DNS queries with IP addresses for up to eight healthy instances.
WEIGHTED
Route 53 returns the applicable value from one randomly selected instance from among the instances that you registered using the same service
refs: https://docs.aws.amazon.com/ja_jp/cloud-map/latest/api/API_DnsConfig.html
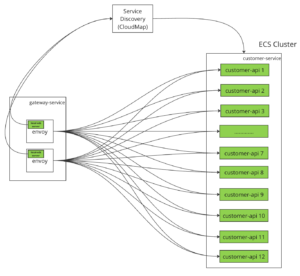
それで、strict_dnsでもlogical_dnsでも全てのECSタスクへ分散できなかったと思い、xDSサーバーの方針を採用しました。xDSサーバーとはディスカバリサービスであり、様々な種類があるが、このサービスで専用の EDS (エンドポイントディスカバリサービス)を作りました。
Envoyクラスターの中に xDSサーバーを立てて、Envoyが決まったAPI Endpointを提供できたら、AWS Service Discoveryと同じ役割なものではあります。xDSサーバーは定期に直接AWS CloudMap APIへ叩いて、ローカルメモリで全てのECSタスクのエンドポイントを保持します。システム構成は下記の図になります。
導入した結果、ECSタスクがスケールアウトされてリクエストちゃんと分散されて監視グラフがよくなりました。図で見る通り、リクエストが増えて、ECSタスクがスケールアウトされて、envoyのクラスターにメンバーも増えました。
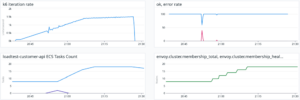
ロードバランシングのグラフも期待通りになりました。目標値の18000 rpsも達成できました。

負荷試験とパフォーマンスチューニングをして得られた学び
- 「推測するな、計測せよ」とRob Pike氏が「Notes on Programming in C」でおっしゃっていましたが、正しくモニタリングできていないと正しく改善できないことを改めて感じます。
- 自動生成ツールと友達になる。つまらないことはツールに任せるべきです。
- 改善を小さくして、フィードバックループを続けて回すべきです。
あとがき
私たちのチームが負荷試験を通してパフォーマンスチューニングを取り組んだことを共有しました。
このサービスローンチしてから数ヶ月で安全安定稼働できて、社内と社外から好評の声がいただきました。
また、今回の取り組みで負荷試験シナリオを自動生成するツールなど、エンジニアが便利だと感じるものが沢山生まれました。これらのツールをOSS化していこうという話も上がっているので、別の機会で共有します。
以上です。