
はじめに
株式会社サイバーエージェントの金光 雄佑です。
ABEMAのYatagarasuという名で呼ばれる推薦システムは、これまで3回に渡るアーキテクチャの見直しがありました。
そして、2022年から2024年までの間を経て、ついに新アーキテクチャへの移行が完了しました。
各世代のアーキテクチャをそれぞれv1~v3として、以下に順を追って説明します。
Versions
v1, 2022
ABEMAの推薦システムはそれまでオンプレミスで稼働していましたが、世間の注目を集める大規模イベント時のトラフィックへの対応に加え、機械学習の学習と推論で必要となるリソースの適切な確保やマネージドサービスによる運用時の恩恵を目的として、基盤をGoogle Cloudへ移行しました。
また、当初は使用する言語をML/DSにとって馴染みのあるPythonに統一する事で、開発効率の向上を目的としました。
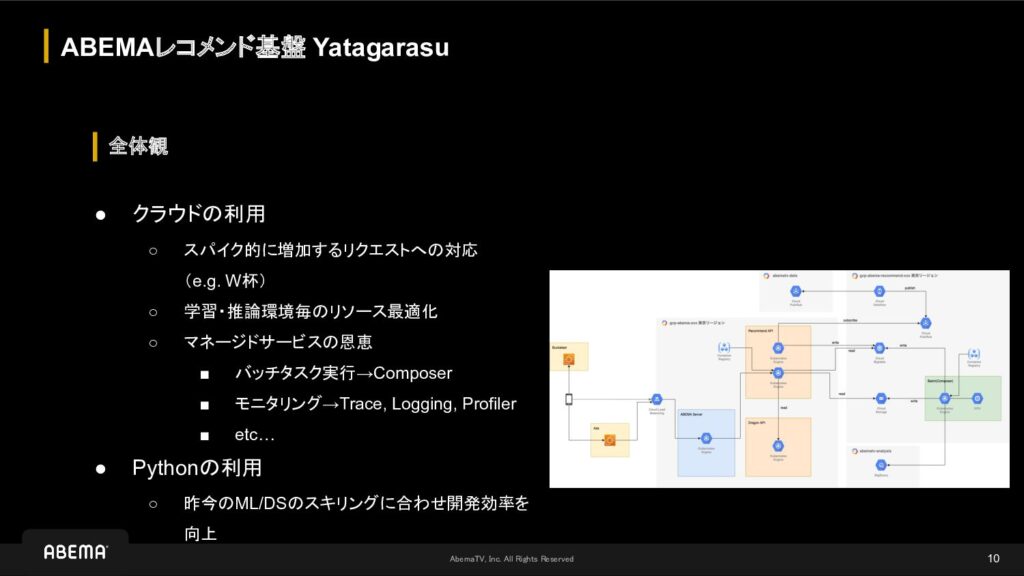
しかし、リリース前の負荷試験の結果、大規模イベント時のトラフィックを想定した場合、予想よりもリソースを必要とし、その分のコストも増加する事が判明しました。
そこで、ユーザーにコンテンツを推薦する処理に対して、並行処理とキャッシュを最適化する為に、その責務を担うマイクロサービスをGoで開発しました。
具体的には、インメモリとMemorystoreによるキャッシュの多層化やsingleflight等で可能な限りオリジンへのリクエストを回避させるようにした結果、最終的にリリースできるレベルにまでは改善する事ができました。
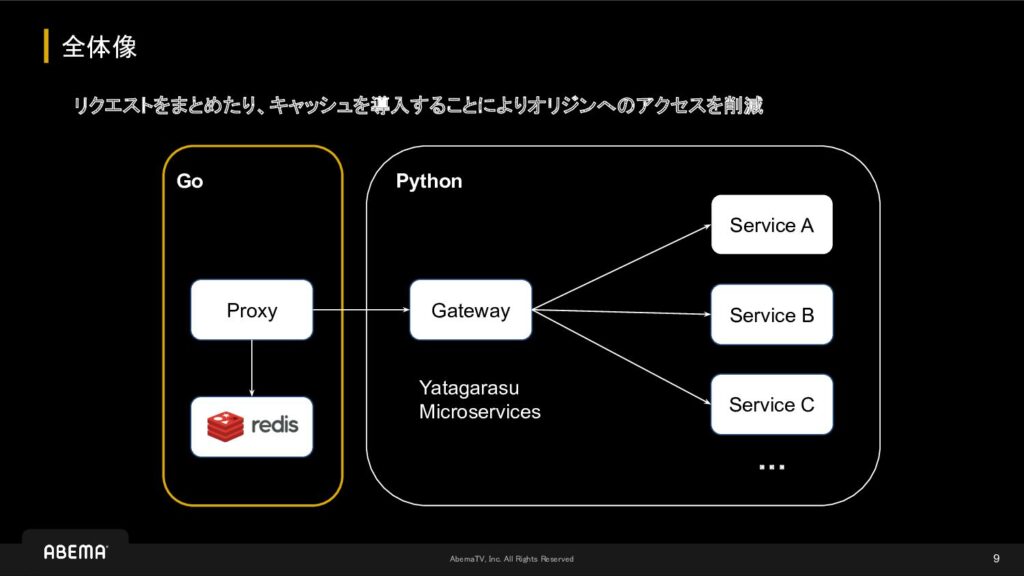
一方、GoのマイクロサービスがPythonのマイクロサービスに依存していたので、オリジンへのリクエスト時にそこのレイテンシが原因となるタイムアウトが頻発していました。
もちろん、Fallbackは導入されているものの、レイテンシの改善は依然として課題でした。
また、きめ細かいパーソナライゼーションを実現できていた訳ではなく、ユーザー毎に共通する特徴量をキャッシュのキーとしていたので、レイテンシの低下を優先して推薦の性能が犠牲になっていました。
v2, 2023
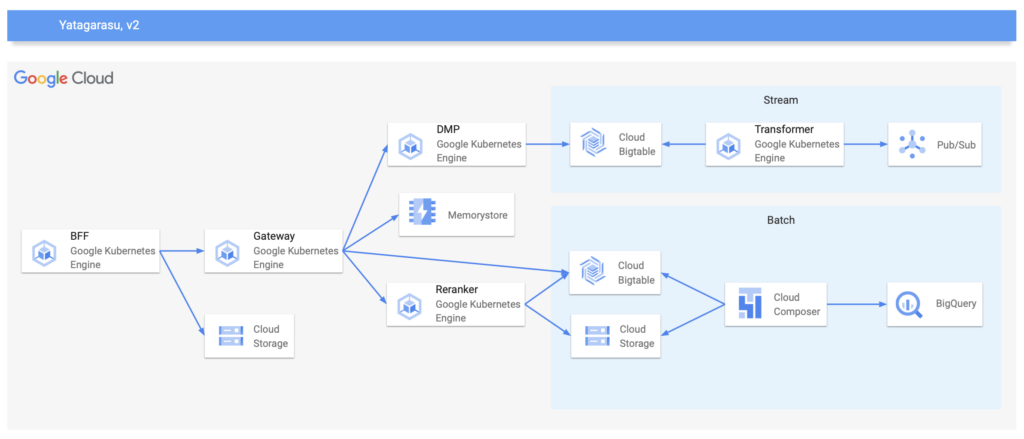
改めてになりますが、各世代のアーキテクチャで共通するYatagarasuの概要を説明します。
リアルタイムなユーザーのリクエストは、BFFを通してGatewayに到達します。
このGatewayでは事前に生成された特徴量や推薦するコンテンツの候補を取得して、次にRerankerがその候補となるコンテンツのRerankingを行った後、ユーザーにコンテンツを推薦します。
よって、この一連の処理を低レイテンシで実現する事が、Yatagarasuにとっての技術的な挑戦になります。
また、CronJobが非同期でFallback用のコンテンツを取得してCloud Storageに書き出し、BFFがそのFallback用のコンテンツを事前にインメモリでキャッシュしておく事で高可用性を担保しています。
ストリーム処理のレイヤーは、特徴量として必要なユーザーの属性や行動に関する情報を一元化して、DMPとしての責務を担います。
このDMP自体は、Dragonという名で呼ばれる別の推薦システムでも使われています。
バッチ処理のレイヤーは、推薦するコンテンツの候補と特徴量の生成、およびRerankerの推論で必要となるモデルの学習を担います。
以上がYatagarasuの概要になりますが、詳細はより複雑になっています。
v1の問題に対して、v2ではGatewayとRerankerの両方にメスを入れました。
前者に関しては、Pythonのマイクロサービスを介さずに、Bigtableに用意しておいた候補をGatewayから取得するように変更しました。
また、v1ではコストの観点からMemorystoreのBasic TierでConsistent Hashingを形成する方法を導入していましたが、一部のキーでホットスポットのノードが発生する可能性があったので、v2ではリードレプリカを有効にしたStandard Tierを採用しました。
後者に関しては、TensorFlow Servingを採用して、Rerankerで使用する言語をPythonからGoに変更しました。
加えて、このタイミングでアルゴリズムもFactorization Machinesに変更しました。
これにより、Rerankingにおけるキャッシュを撤退しましたが、推薦の性能を犠牲にする事なく、レイテンシを改善する事ができました。
また、将来的には検索におけるLearning to Rank等にも応用できるように、インターフェースをシンプルにして、複数のモデルを利用可能な実装にしました。
これにより、推薦時におけるマイクロサービスはGoで統一され、v1でメインとなっていたPythonの介在する余地は少なくなり、低レイテンシと高可用性を実現できました。
v3, 2024
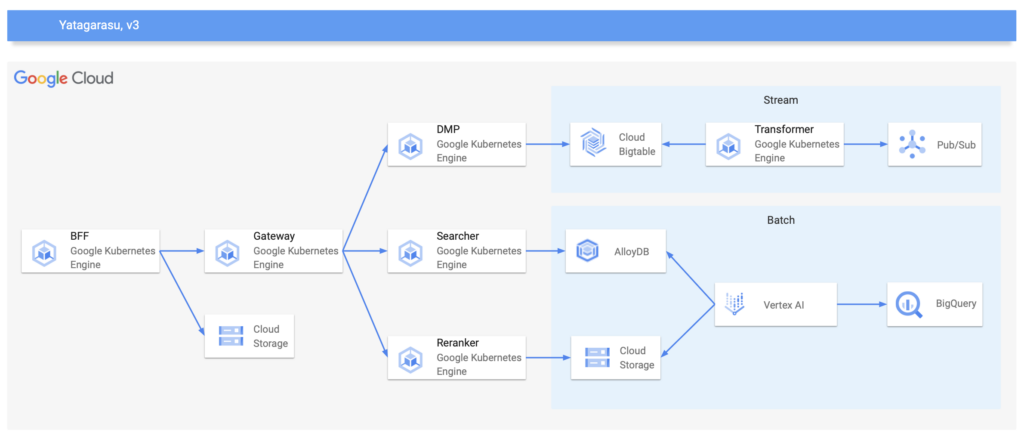
v2によりエンドユーザーに対する信頼性は向上しましたが、バッチ処理のレイヤーはCloud Composerを利用しており、今後チーム内でVertex AIを積極的に使う方針となったので、これを機に再びアーキテクチャの変更を行いました。
v3のVertex AI以外で特出している事としては、Memorystoreの撤退とAlloyDBの採用です。
ABEMAではPrometheusとGrafanaによる可観測性の基盤が整っているので、Yatagarasuにおけるキャッシュのヒット率も計測できます。
例えば、ランキング系の推薦コンテンツはヒット率が高く、視聴履歴系の推薦コンテンツはヒット率が低いといった傾向にあります。
そこで、こうした傾向を踏まえ、メリハリのあるキャッシュ戦略を再考しました。
具体的には、ヒット率が高い推薦コンテンツはインメモリのキャッシュだけを行い、逆にヒット率が低い推薦コンテンツはキャッシュの対象外として初めからオリジンにリクエストする事で、キャッシュで必要となる空間を最適化できました。
結果、Memorystoreを撤退して、コストの削減に繋げる事ができました。
また、これまで候補とコンテンツの特徴量はBigtableで管理していましたが、既にベクトル検索を実現する為にAlloyDBでpgvectorを利用していたので、同様にMatrix Factorizationで計算した結果をAlloyDBにインデックスし、ベクトル検索を担うSearcherから取得するようにしました。
この背景には、ベクトル検索の運用でレイテンシに問題ない事を証明できており、将来的にAlloyDBでより高速なScaNNインデックスが一般提供されるのも決め手でした。
その他にも、このタイミングでこれまで使用していたリソースを整理して、コストの最適化を実現できました。
おわりに
一般的に推薦システムに関しては、アルゴリズムといった理論的な部分に焦点が当たりがちですが、いくら推薦の性能が高くてもシステムとしての信頼性を担保できなければ、ユーザーに価値を提供する事はできません。
特に社会インフラを目指すABEMAではより高いレベルの信頼性を要求され、その中でも推薦システムはホームを中心にプロダクトの重要なコンポーネントを担います。
最後に宣伝になりますが、私達と一緒にABEMAの推薦システムを進化させていただける方を絶賛募集中です!
【メディア事業部】ソフトウェアエンジニア(情報推薦・機械学習)/ ABEMA